替换博客模板
6
.gitignore
vendored
@@ -1,6 +0,0 @@
|
||||
_site
|
||||
.sass-cache
|
||||
.idea
|
||||
.local
|
||||
.local/*
|
||||
.jekyll-cache
|
||||
3
404.html
@@ -1,3 +0,0 @@
|
||||
<html>
|
||||
<head><meta http-equiv="refresh" content="0;url=/"></head>
|
||||
</html>
|
||||
8
404.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
layout: page
|
||||
title: 404 - Page not found
|
||||
---
|
||||
|
||||
Sorry, we can't find that page that you're looking for. You can try again by going [back to the homepage]({{ site.baseurl }}/).
|
||||
|
||||
[<img src="{{ site.baseurl }}/images/404.jpg" alt="Constructocat by https://github.com/jasoncostello" style="width: 400px;"/>{: .center-image}]({{ site.baseurl }}/)
|
||||
2
LICENSE
@@ -1,6 +1,6 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2019 bit-ranger
|
||||
Copyright (c) 2019 FromEndWorld
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
206
README.md
@@ -1,38 +1,198 @@
|
||||
it is a blog Repositories
|
||||
---
|
||||
##[点我查看中文说明/Click here for Chinese instructions](https://github.com/lemonchann/lemonchann.github.io/blob/master/README_zh_CN.md)
|
||||
LOFFER是个可以帮助你get off from LOFTER的软件(我知道这个pun很烂)。
|
||||
|
||||
# Blog Address
|
||||
这是一个可以通过Fork直接发布在GitHub的Jekyll博客,你不需要编写代码或使用命令行即可获得一个部署在GitHub的博客。
|
||||
|
||||
<https://lemonchann.github.io>
|
||||
## 更新内容
|
||||
|
||||
### 2019-07-25 V0.4.0
|
||||
|
||||
修订目录跳级会坏掉的问题,不算完美解决,但不会坏掉了。
|
||||
|
||||
增加对LaTeX渲染的支持,请见[这篇说明和示例](https://fromendworld.github.io/LOFFER/math-test/)。
|
||||
|
||||
增加置顶功能,只要在一个post的YAML Front Matter(就是文章头部的这段信息)中加入` pinned: true `,这篇文章就可以置顶了。
|
||||
|
||||
另外介绍一个给LOFFER更换主题颜色的手法。LOFFER用了一个开源的颜色表[Open Color](https://yeun.github.io/open-color/),该色表提供的可选颜色有:red, pink, grape, violet, indigo, blue, cyan, teal, green, lime, yellow。
|
||||
|
||||
LOFFER的默认状态是teal,要更换主题颜色,只要打开文件` _sass/_variables.scss `,将文件中所有的teal全部替换成你想要的颜色。例如,查找teal,替换indigo,全部替换,commit,完成!
|
||||
|
||||
|
||||
# Must Modify
|
||||
### 2019-07-20 V0.3.0
|
||||
|
||||
## 1.swiftype
|
||||
新版本增加目录功能,在post的信息中心加入` toc: true `,这篇博文就会显示目录了。
|
||||
|
||||
This service provides the on-site search function.
|
||||
这次没有对config的修改,因此应该可以通过[这个方法](https://github.com/KirstieJane/STEMMRoleModels/wiki/Syncing-your-fork-to-the-original-repository-via-the-browser),给自己提pull request来更新。
|
||||
|
||||
Service address: <https://swiftype.com/>.
|
||||
目录基于[jekyll-toc by allejo](https://github.com/allejo/jekyll-toc)制作。
|
||||
|
||||
Documentation: <https://swiftype.com/documentation/site-search/crawler-quick-start/>
|
||||
目前我试用发现了一点小问题:如果你的标题级数不按套路变化,它就会搞不懂……
|
||||
|
||||
After the setup is complete, you need to modify the `swiftype.searchId` in `_config.yml`.
|
||||
` # 一级标题 `下面必须是` ## 二级标题 `,如果是` ### 三级标题 `它就人工智障了【手动扶额】
|
||||
|
||||
In your swiftype engine, go to `Install Search`, you will find the `swiftype.searchId`.
|
||||
注意:目前目录仅在桌面版显示。
|
||||
|
||||
```html
|
||||
<script type="text/javascript">
|
||||
...
|
||||
...
|
||||
_st('install','swiftype.searchId','2.0.0');
|
||||
</script>
|
||||
```
|
||||
|
||||
## 2.gitment
|
||||
### 2019-06-30 V0.2.0
|
||||
|
||||
This service provides the comment function.
|
||||
新版本进一步优化了一下样式,并且支持了基于GitHub Issues的评论Gitalk(请看下文的配置说明)。
|
||||
|
||||
Service address: <https://github.com/imsun/gitment>.
|
||||
如果你已经fork了LOFFER,想要更新到新版本的话,可以试试[这个方法](https://github.com/KirstieJane/STEMMRoleModels/wiki/Syncing-your-fork-to-the-original-repository-via-the-browser),或者你也可以干脆删掉重来,只要保留自己的大部分config设定和所有的post就好。
|
||||
|
||||
After the setup is complete, you need to modify the `gitment` in `_config.yml`.
|
||||
LOFFER只是容器,你的posts才是博客的核心。
|
||||
|
||||
|
||||
## 注意
|
||||
|
||||
LOFFER是一个**博客模板**,使用GitHub Pages发布个人博客是没有任何问题的。 **但是:**
|
||||
|
||||
- **请勿发布成人向内容**
|
||||
- **不要将大量图片上传到GitHub**
|
||||
|
||||
如有疑问,请阅读[GitHub Pages官方说明](https://pages.github.com/)。
|
||||
|
||||
另外,同人作品更好的发布平台是[AO3](https://archiveofourown.org/),你想你发在AO3还有tag还有kudos还有人看,是吧?
|
||||
|
||||
|
||||
## 如何使用
|
||||
|
||||
首先,这个博客主题适应手机阅读,但是,要使用它建立你自己的博客,你需要上电脑操作。
|
||||
|
||||
### 第一步 Fork到你的GitHub
|
||||
|
||||
请点击[GitHub](https://github.com/),注册一个GitHub账户。我们可以理解Git就是个文件版本管理系统,本身并不需要会代码即可使用。
|
||||
|
||||
现在你看到的LOFFER,是作为一个GitHub上的Repository(代码库)存在的,你可以把这个代码库复制到你自己的GitHub账户中,这个操作叫做Fork。
|
||||
|
||||
点击[LOFFER](https://github.com/FromEndWorld/LOFFER),进入LOFFER的GitHub Repository页面,然后点Fork:
|
||||
|
||||
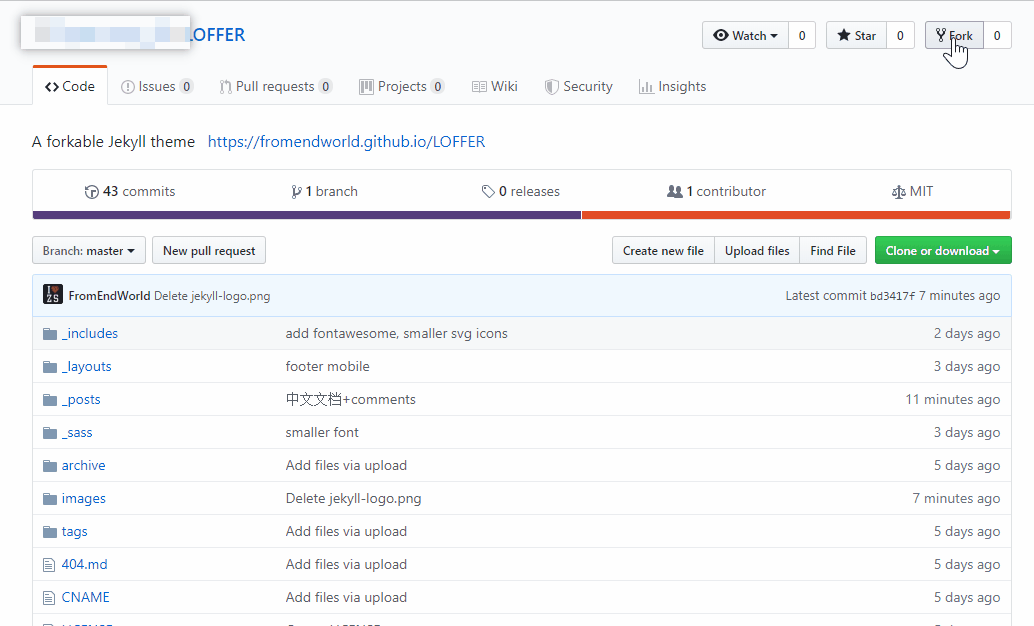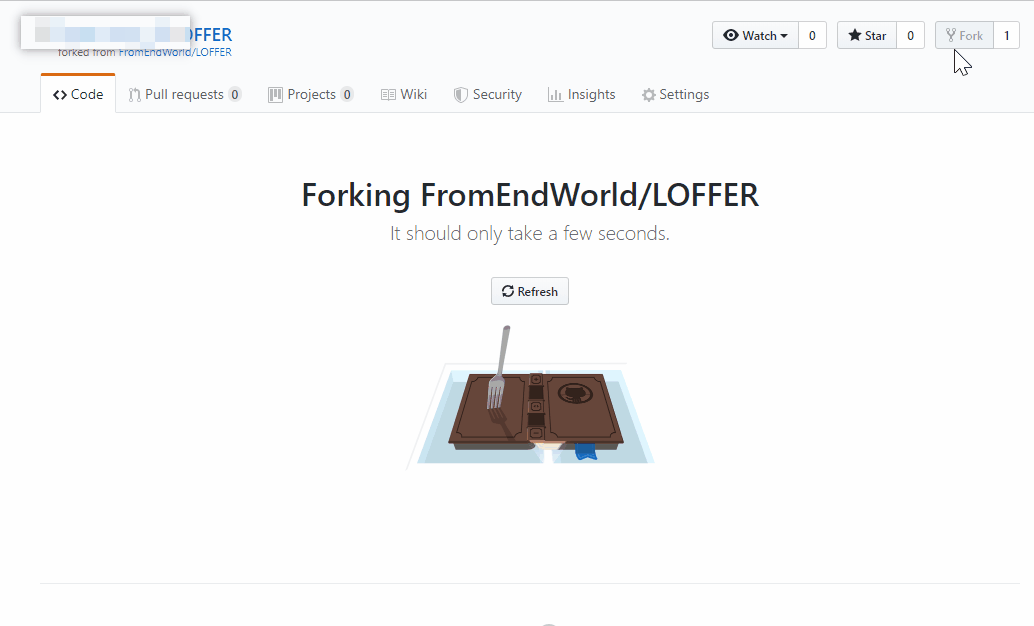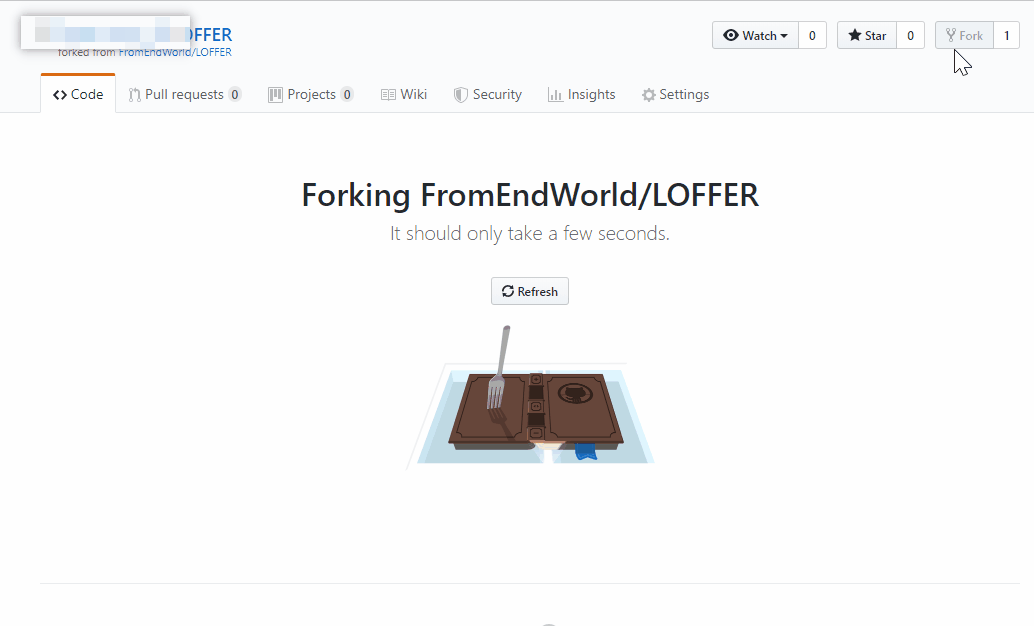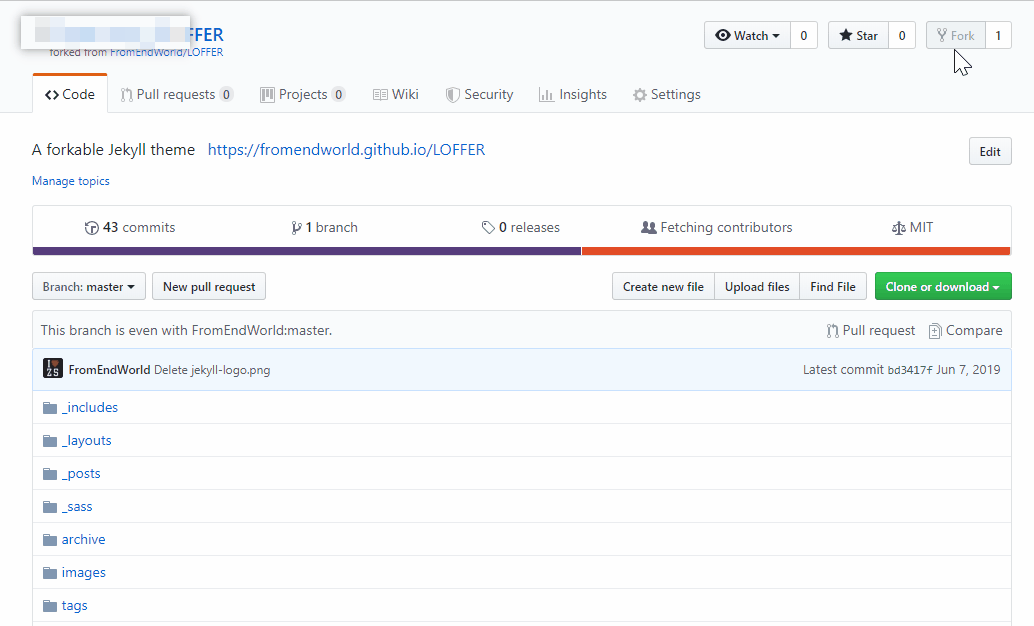
|
||||
|
||||
然后你立刻就可以看到LOFFER再次出现,这次它已经属于你了,这里我建议你重命名它,点击settings,给你的博客起个名字(请尽量使用字母而非中文)。
|
||||
|
||||
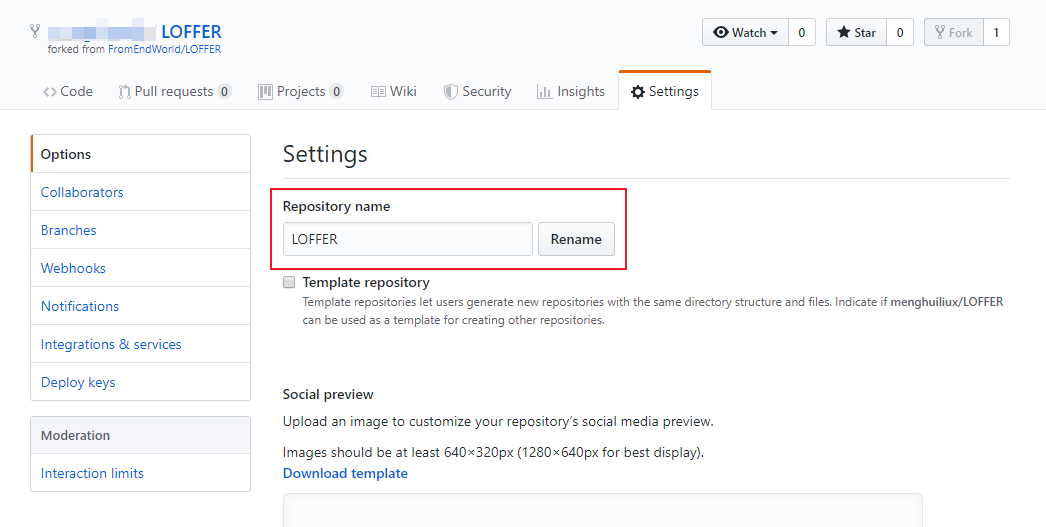
|
||||
|
||||
然后,向下拉页面,你会看到“GitHub Pages”,这是GitHub内置的网站host服务,选择master,如图所示:
|
||||
|
||||
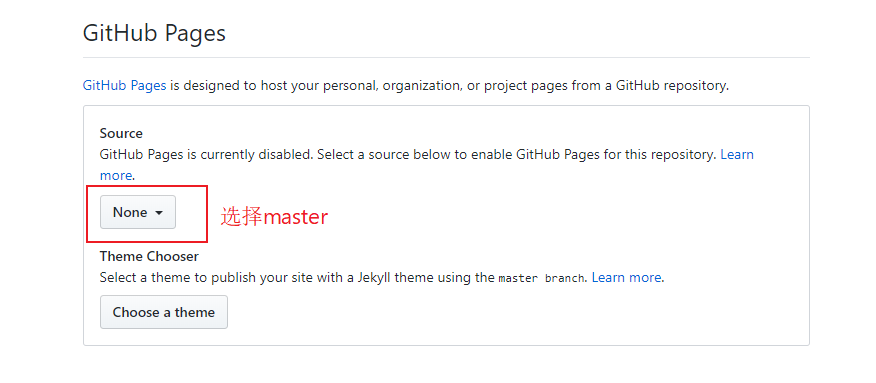
|
||||
|
||||
在几秒钟后,刷新此页面,你通常会看到这个绿色的东西(如果没看到,多等一会),你的网站已经发布成功,点击这个链接,即可查看:
|
||||
|
||||
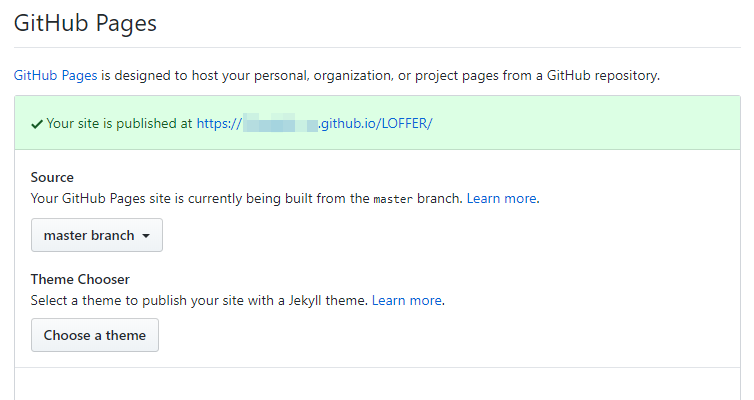
|
||||
|
||||
你可能会看到网站长得很丑,请继续下一步.
|
||||
|
||||
### 第二步 设置站点信息
|
||||
|
||||
在你的博客的GitHub代码库页面里,选择Code,文件列表里选择_config.yml,点击打开,点击右上角笔形图标修改文档。
|
||||
|
||||
修改完成后,点击“Commit changes”。每次修改过代码库并且commit后,GitHub Pages都会自动重新发布网站,只要等上几分钟,再次刷新你的博客页面,就会看到你的修改了。
|
||||
|
||||
还有一点,**LOFFER使用的是MIT协议,大意就是全部开源随意使用,如果你要保留自己博文的权利,请编辑LICENSE文件,写上类似“_posts中的文档作者保留权利”这样的内容。**
|
||||
|
||||
### 第三步 发布博文
|
||||
|
||||
在你的博客的GitHub代码库页面里,点开_posts文件夹,这里面就是你的博客文章。
|
||||
|
||||
这些文章使用的格式是Markdown,文件后缀名是md,这是一种非常简单易用的有格式文本标记语言,你应该已经注意到,在LOFFER自带的示例性博文中有一篇中文的Markdown语法介绍。
|
||||
|
||||
更简单的办法是使用[Typora](https://typora.io/),这是一个全图形化界面,全实时预览的Markdown写作软件,非常轻量,而且免费。
|
||||
|
||||
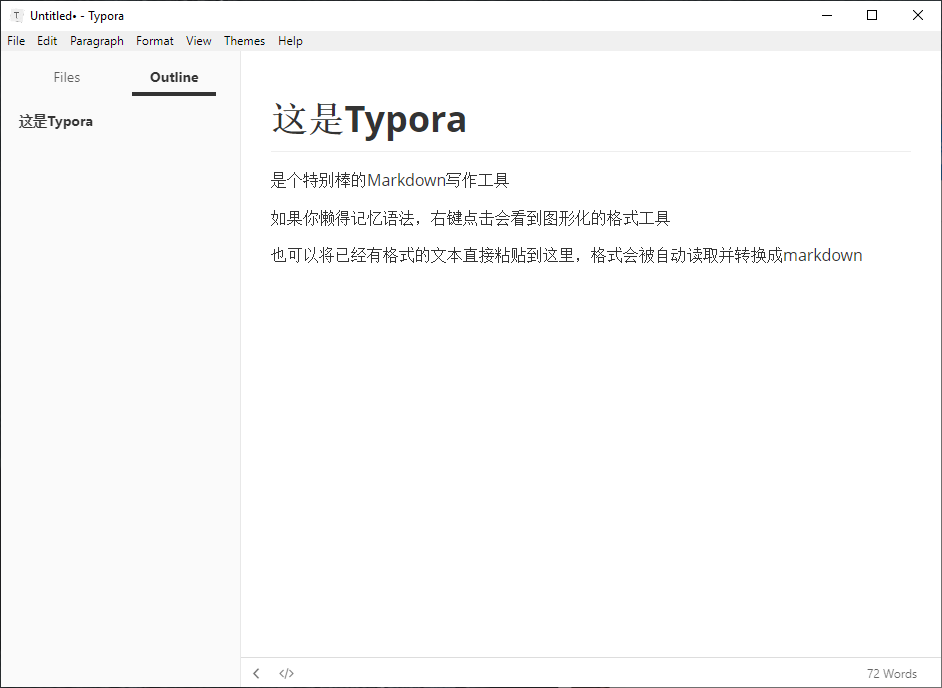
|
||||
|
||||
在发布博文前,你需要在文章的头部添加这样的内容,包括你的文章标题,发布日期,作者名,和tag等。
|
||||
|
||||
---
|
||||
layout: post
|
||||
title: LOFFER文档
|
||||
date: 2019-06-02
|
||||
Author: 来自中世界
|
||||
categories:
|
||||
tags: [sample, document]
|
||||
comments: true
|
||||
---
|
||||
|
||||
完成后,保存为.md文件,文件名是date-标题,例如 2019-06-02-document.md (注意这里的标题会成为这个post的URL,所以推荐使用字母而非中文,它不影响页面上显示的标题),然后上传到_posts文件夹,commit,很快就可以在博客上看到新文章了。
|
||||
|
||||
### 可选:图片怎么办?
|
||||
|
||||
少量图片可以上传到images文件夹,然后在博文中添加。
|
||||
|
||||
但是GitHub用来当做图床有滥用之嫌,如果你的博客以图片为主,建议选择外链图床,例如[sm.ms](https://sm.ms/)就是和很好的选择。
|
||||
|
||||
如果想要寻找更适合自己的图床,敬请Google一下。
|
||||
|
||||
在博文中添加图片的Markdown语法是:``
|
||||
|
||||
### 可选:添加评论区
|
||||
|
||||
#### Disqus
|
||||
|
||||
LOFFER支持Disqus评论,虽然Disqus很丑,但是它是免费的,设置起来又方便,因此大家也就不要嫌弃它。
|
||||
|
||||
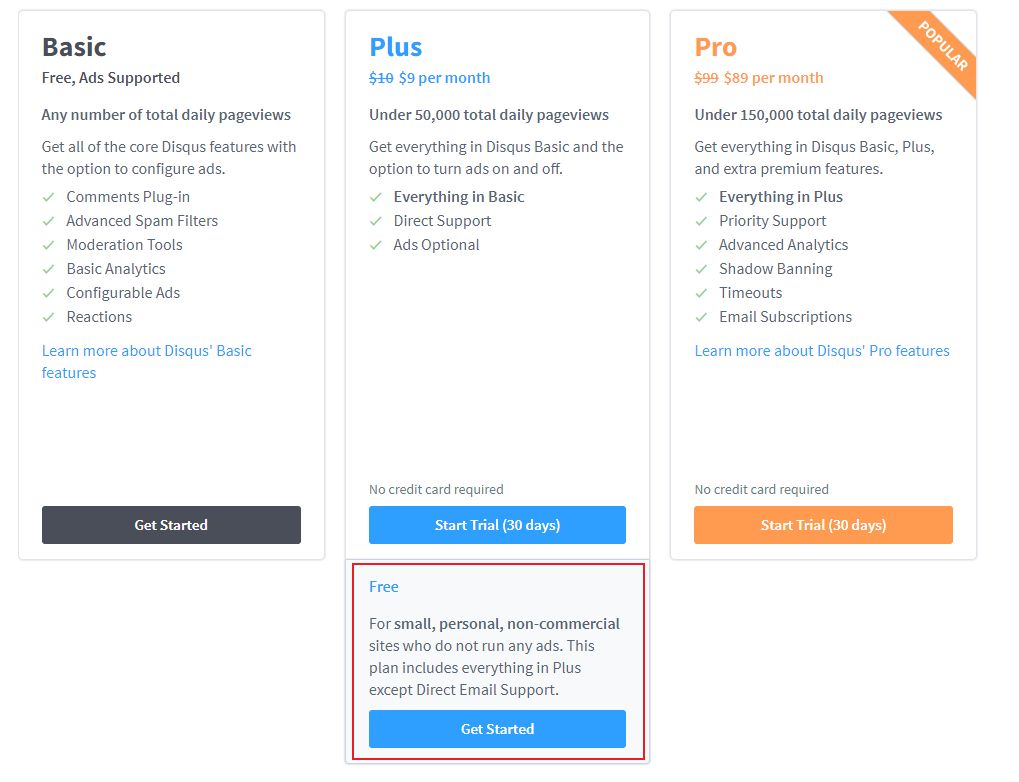
首先,注册一个[Disqus](https://disqus.com/)账户,我们可以选择这个免费方案:
|
||||
|
||||
|
||||
|
||||
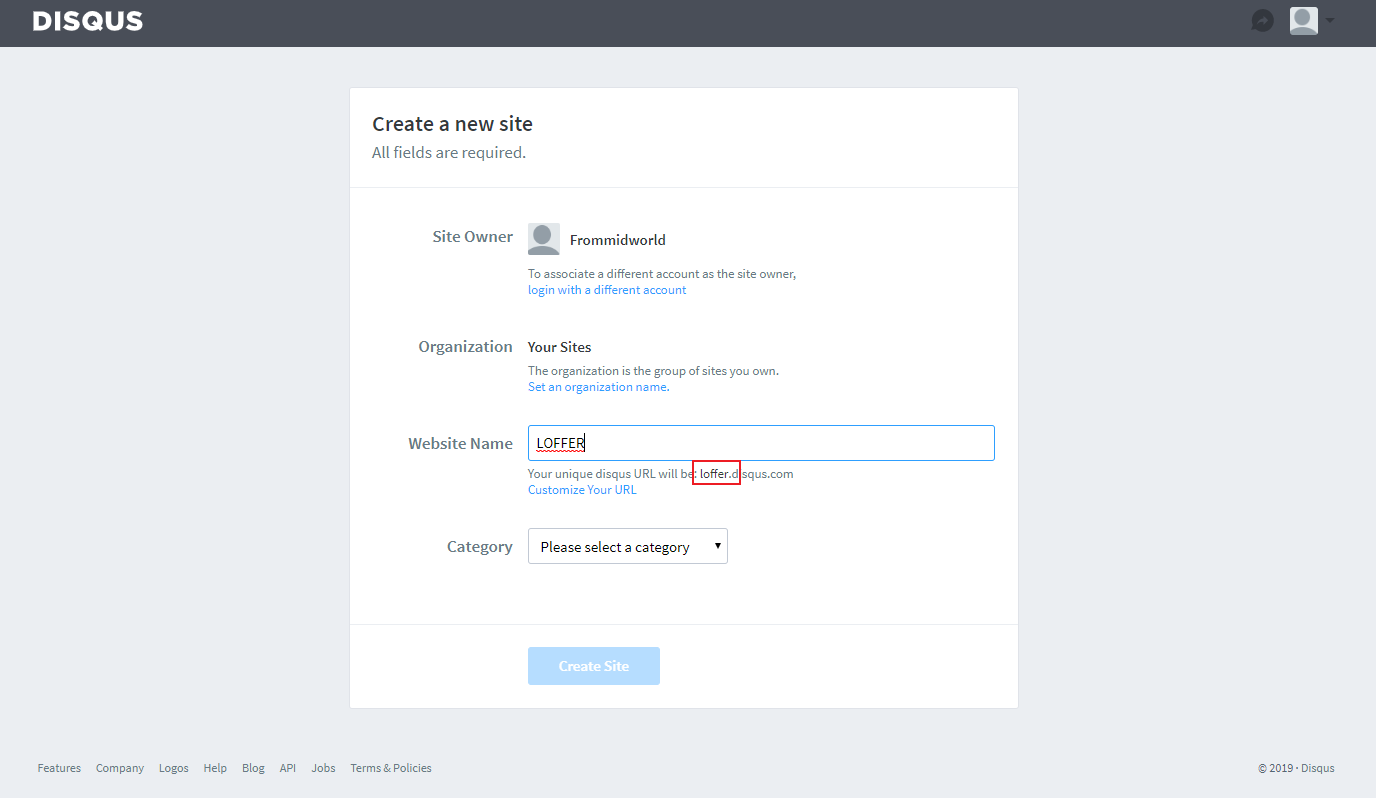
注册成功后,新建一个站点(site),以LOFFER为例设置步骤如下:
|
||||
|
||||
首先站点名LOFFER,生成了shortname是loffer,类型可以随便选。
|
||||
|
||||
|
||||
|
||||
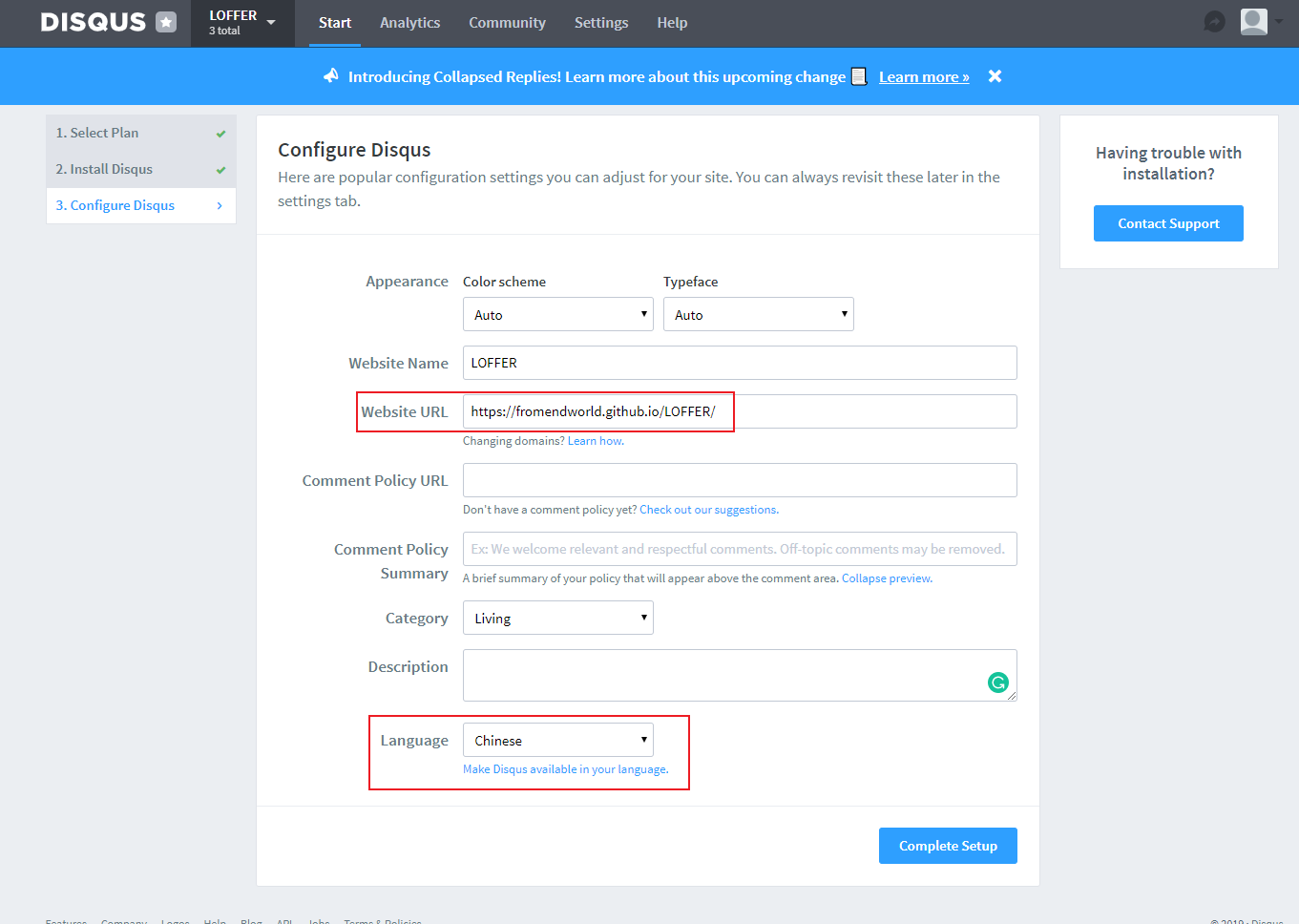
安装时选择Jekyll。
|
||||
|
||||

|
||||
|
||||
最后填入你的博客地址,语言可以选中文,点Complete,即可!
|
||||
|
||||
|
||||
|
||||
然后需要回到你的博客,修改_config.yml文件,在disqus字段填上你的shortname,commit,完成!
|
||||
|
||||
#### Gitalk
|
||||
|
||||
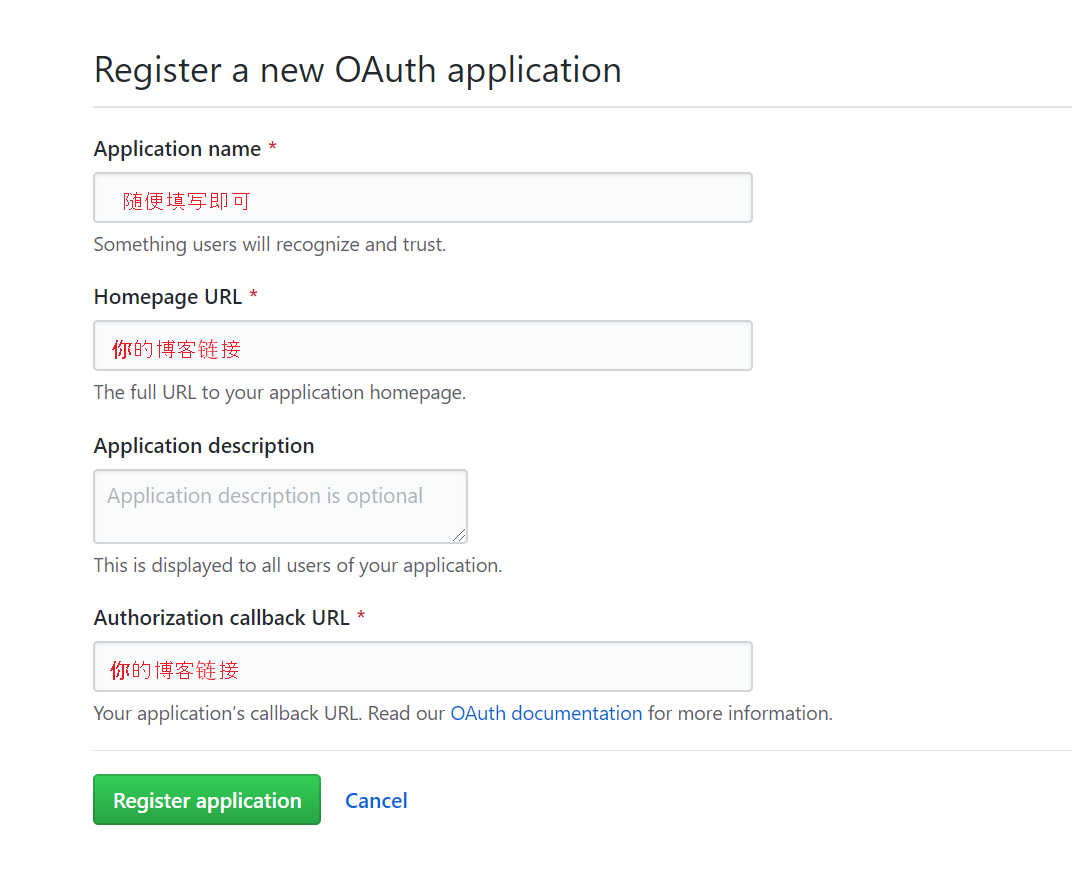
新增内容,LOFFER 0.2.0版本支持Gitalk评论区(在LOFFER示例站中仍然是Disqus,可以在[我的博客](https://himring.top/gitalk/)查看Gitalk的demo),设置方法如下:
|
||||
|
||||
首先,创建一个[OAuth application](https://github.com/settings/applications/new), 设置如图:
|
||||
|
||||
|
||||
|
||||
点Register后就会看到你所需要的两个值,clientID和clientSecret,把它们复制到你的_config.yml文件中相应的字段:
|
||||
|
||||
gitalk:
|
||||
clientID: <你的clientID>
|
||||
clientSecret: <你的clientSecret>
|
||||
repo: <你的repository名称>
|
||||
owner: <你的GitHub用户名>
|
||||
|
||||
然后commit,你的Gitalk评论区就会出现了。对于每一篇文章,都需要你来进入文章页,来初始化评论区,这一操作会在你的repository上创建一个Issue,此后的评论就是对这个Issue的回复。
|
||||
|
||||
你可以进入你的repository的Issue页面,点**Unsubscribe**来避免收到大量相关邮件。
|
||||
|
||||
注意:出于很明显的原因,最好不要同时添加Disqus和Gitalk评论区。
|
||||
|
||||
### 导入LOFTER的内容
|
||||
|
||||
这部分由于LOFTER的导出文件十分~~优秀~~,需要另外解决。
|
||||
|
||||
诸位可以使用[墨问非名太太的脚本](http://underdream.lofter.com/post/38ea7d_1c5d8a983),其中选择Jekyll输出即可。
|
||||
|
||||
我个人也在折腾一个脚本,目前还没有完全debug清楚,不管如何,请先在lofter里导出一下,存在本地也是好的,贴吧可以让2017以前所有内容全部消失,中国互联网,没什么不可能发生的。
|
||||
|
||||
## 致谢
|
||||
|
||||
* [Jekyll](https://github.com/jekyll/jekyll) - 这是本站存在的根基
|
||||
* [Kiko-now](<https://github.com/aweekj/kiko-now>) - 我首先是fork这个主题,然后再其上进行修改汉化,才有了LOFFER
|
||||
* [Font Awesome](<https://fontawesome.com/>) - 社交网络图标来自FontAwesome的免费开源内容
|
||||
|
||||
|
||||
|
||||
## 帮助这个项目
|
||||
|
||||
介绍更多人来使用它,摆脱lofter自由飞翔!
|
||||
|
||||
当然如果单说写同人的话,我还是建议大家都去AO3,但是自家博客自己架也很酷炫,你还可以选择很多其他的forkable Jeykll主题,GitHub上有很多,或者试试其他博客架设工具,例如Hexo,与代码斗其乐无穷。
|
||||
|
||||
最后,回到[LOFFER](https://github.com/FromEndWorld/LOFFER),给我点一个☆吧!
|
||||
|
||||

|
||||
|
||||
@@ -1,33 +0,0 @@
|
||||
# 博客地址
|
||||
|
||||
<https://bit-ranger.github.io/blog/>
|
||||
|
||||
# 必改内容
|
||||
|
||||
## 1.swiftype
|
||||
|
||||
此服务提供站内搜索功能
|
||||
|
||||
服务地址: <https://swiftype.com/>
|
||||
|
||||
文档: <https://swiftype.com/documentation/site-search/crawler-quick-start/>
|
||||
|
||||
设置完毕后,您需要修改 `_config.yml` 中 `swiftype.searchId`。
|
||||
|
||||
在自己的引擎中,进入 `Install Search`, 你将找到 `swiftype.searchId`。
|
||||
|
||||
```html
|
||||
<script type="text/javascript">
|
||||
...
|
||||
...
|
||||
_st('install','swiftype.searchId','2.0.0');
|
||||
</script>
|
||||
```
|
||||
|
||||
## 2.gitment
|
||||
|
||||
此服务提供评论功能
|
||||
|
||||
服务地址:<https://github.com/imsun/gitment>
|
||||
|
||||
设置完毕后, 需要修改 `_config.yml` 中的 `gitment`。
|
||||
170
_config.yml
@@ -1,48 +1,122 @@
|
||||
plugins: [jekyll-paginate]
|
||||
|
||||
permalink: /:categories/:title/
|
||||
|
||||
highlighter: rouge
|
||||
markdown: kramdown
|
||||
kramdown:
|
||||
input: GFM
|
||||
syntax_highlighter: rouge
|
||||
|
||||
|
||||
paginate: 10
|
||||
paginate_path: "page/:num"
|
||||
baseurl: ""
|
||||
|
||||
|
||||
|
||||
defaults:
|
||||
-
|
||||
scope:
|
||||
path: ""
|
||||
type: posts
|
||||
values:
|
||||
layout: post
|
||||
styles : [highlight.css,gitment.css,post.css]
|
||||
scripts : [gitment.js, post.js]
|
||||
|
||||
|
||||
|
||||
title: "lemonchann"
|
||||
email: lemonchann@foxmail.com
|
||||
description: ""
|
||||
github:
|
||||
username: lemonchann
|
||||
#swiftype:
|
||||
#searchId: iXZyPokVfxFaBTvi64Y6
|
||||
#gitment:
|
||||
#repo: blog
|
||||
#client_id: a6fb73b3e790e234bab8
|
||||
#client_secret: cc10aaff53a03d05ab2ee002dbf401dd7627c7a3
|
||||
|
||||
url: "https://lemonchann.github.io"
|
||||
imgrepo: "https://lemonchann.github.io/static/img"
|
||||
|
||||
|
||||
#url: "http://127.0.0.1:4000"
|
||||
#imgrepo: "http://127.0.0.1:4000/static/img"
|
||||
|
||||
#
|
||||
# 这个文档包含了本博客的设定信息,你可以编辑它来个性化自己的博客,
|
||||
#
|
||||
|
||||
# 你的博客名称,请用你想要的博客名替换“LOFFER”,以下修改都可类似处理
|
||||
# 注意,“name: LOFFER”,冒号后面的空格不可以省略。
|
||||
# 井号后面的文字是说明文档,不会被程序读取。
|
||||
name: LOFFER
|
||||
# 描述/签名
|
||||
description: 一个可以fork的博客
|
||||
|
||||
#
|
||||
# 下面的设定都是可选的
|
||||
#
|
||||
|
||||
# 你的博客logo图片URL,建议尺寸不超过300px × 300px
|
||||
avatar: https://raw.githubusercontent.com/FromEndWorld/LOFFER/master/images/logo.png
|
||||
|
||||
# 你的favicon(出现在浏览器tab上)图片URL,建议使用较小(64px × 64px)的图片
|
||||
favicon: https://raw.githubusercontent.com/FromEndWorld/LOFFER/master/images/favicon.png
|
||||
|
||||
|
||||
# 菜单中的按钮
|
||||
navigation:
|
||||
- name: 首页
|
||||
url: /
|
||||
- name: 关于
|
||||
url: /about
|
||||
- name: 归档
|
||||
url: /archive
|
||||
- name: 标签
|
||||
url: /tags
|
||||
|
||||
# 每页的文章数
|
||||
paginate: 8
|
||||
|
||||
# 文章简介的区分标记
|
||||
excerpt_separator: <!-- more -->
|
||||
|
||||
# 你的社交网络链接,它们会作为图标出现在你的网站页脚中,可选填写
|
||||
footer-links:
|
||||
weibo: frommidworld #请输入你的微博个性域名 https://www.weibo.com/<thispart>
|
||||
behance: # https://www.behance.net/<>
|
||||
dribbble: # https://dribbble.com/<>
|
||||
email: fromendworld@outlook.com
|
||||
facebook: #https://www.facebook.com/<>
|
||||
flickr: #https://www.flickr.com/<>
|
||||
github: FromEndWorld/loffer #https://github.com/<>
|
||||
instagram: #https://instagram.com/<>
|
||||
linkedin: #https://www.linkedin.com/in/<>
|
||||
pinterest: #https://www.pinterest.com/<>
|
||||
rss: #随便填点啥RSS就能用了
|
||||
stackoverflow: # http://stackoverflow.com/<>
|
||||
tumblr: # https://<username>.tumblr.com
|
||||
twitter: # https://www.twitter.com/<your_twitter_username>
|
||||
youtube: # channel/<your_long_string> or user/<user-name>
|
||||
|
||||
# 站点页脚的文字
|
||||
footer-text: Copyright (c) 2019 来自中世界
|
||||
|
||||
# 评论,注意,请不要同时添加多种不同的评论区
|
||||
|
||||
# 输入Disqus shortname,即可添加评论区
|
||||
disqus: loffer #shortname
|
||||
|
||||
# 输入Gitalk相关设定,即可添加评论区
|
||||
gitalk:
|
||||
clientID:
|
||||
clientSecret:
|
||||
repo:
|
||||
owner:
|
||||
|
||||
# 输入Google Analytics web tracking code
|
||||
google_analytics:
|
||||
|
||||
# 输入你的网站域名(如果你没有添加自己的域名,而是直接用GitHub pages分配的域名的话可以省略)
|
||||
url:
|
||||
|
||||
# 添加你的博客的二级域名,一般来说是你的repository名
|
||||
# 如果你的博客的URL是:(http://yourusername.github.io/repository-name)
|
||||
# 那么就写成 "/repository-name"
|
||||
baseurl: /LOFFER
|
||||
|
||||
|
||||
#
|
||||
# !! 以下所有设置都不需要更改 !!
|
||||
#
|
||||
|
||||
permalink: /:title/
|
||||
paginate_path: /page:num/
|
||||
|
||||
# The release of Jekyll Now that you're using
|
||||
version: v1.2.0
|
||||
|
||||
# Jekyll 3 now only supports Kramdown for Markdown
|
||||
kramdown:
|
||||
# Use GitHub flavored markdown, including triple backtick fenced code blocks
|
||||
input: GFM
|
||||
# Jekyll 3 and GitHub Pages now only support rouge for syntax highlighting
|
||||
syntax_highlighter: rouge
|
||||
syntax_highlighter_opts:
|
||||
# Use existing pygments syntax highlighting css
|
||||
css_class: 'highlight'
|
||||
|
||||
# Set the Sass partials directory, as we're using @imports
|
||||
sass:
|
||||
style: :expanded # You might prefer to minify using :compressed
|
||||
|
||||
# Use the following plug-ins
|
||||
plugins:
|
||||
- jekyll-sitemap # Create a sitemap using the official Jekyll sitemap gem
|
||||
- jekyll-feed # Create an Atom feed using the official Jekyll feed gem
|
||||
- jekyll-paginate
|
||||
|
||||
# Exclude these files from your production _site
|
||||
exclude:
|
||||
- Gemfile
|
||||
- Gemfile.lock
|
||||
- LICENSE
|
||||
- README.md
|
||||
- CNAME
|
||||
|
||||
|
||||
16
_includes/analytics.html
Normal file
@@ -0,0 +1,16 @@
|
||||
{% if site.google_analytics %}
|
||||
<!-- Google Analytics -->
|
||||
<script>
|
||||
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
|
||||
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
|
||||
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
|
||||
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
|
||||
|
||||
ga('create', '{{ site.google_analytics }}', 'auto');
|
||||
ga('send', 'pageview', {
|
||||
'page': '{{ site.baseurl }}{{ page.url }}',
|
||||
'title': '{{ page.title | replace: "'", "\\'" }}'
|
||||
});
|
||||
</script>
|
||||
<!-- End Google Analytics -->
|
||||
{% endif %}
|
||||
17
_includes/disqus.html
Normal file
@@ -0,0 +1,17 @@
|
||||
{% if site.disqus %}
|
||||
<div class="comments">
|
||||
<div id="disqus_thread"></div>
|
||||
<script type="text/javascript">
|
||||
|
||||
var disqus_shortname = '{{ site.disqus }}';
|
||||
|
||||
(function() {
|
||||
var dsq = document.createElement('script'); dsq.type = 'text/javascript'; dsq.async = true;
|
||||
dsq.src = '//' + disqus_shortname + '.disqus.com/embed.js';
|
||||
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(dsq);
|
||||
})();
|
||||
|
||||
</script>
|
||||
<noscript>Please enable JavaScript to view the <a href="http://disqus.com/?ref_noscript">comments powered by Disqus.</a></noscript>
|
||||
</div>
|
||||
{% endif %}
|
||||
15
_includes/fonts.html
Normal file
@@ -0,0 +1,15 @@
|
||||
<!-- Async font loading -->
|
||||
<script>
|
||||
window.WebFontConfig = {
|
||||
custom: {
|
||||
families: ['Spoqa Han Sans:100,300,400,700'],
|
||||
urls: ['https://spoqa.github.io/spoqa-han-sans/css/SpoqaHanSans-kr.css']
|
||||
},
|
||||
timeout: 60000
|
||||
};
|
||||
(function(d) {
|
||||
var wf = d.createElement('script'), s = d.scripts[0];
|
||||
wf.src = 'https://ajax.googleapis.com/ajax/libs/webfont/1.5.18/webfont.js';
|
||||
s.parentNode.insertBefore(wf, s);
|
||||
})(document);
|
||||
</script>
|
||||
@@ -1,15 +1,5 @@
|
||||
<footer class="footnote footnote-tiffany">
|
||||
<div class="container">
|
||||
<a class="foot-item" href="mailto:{{ site.email }}" target="_blank"><span class="octicon octicon-mail"></span></a>
|
||||
<a class="foot-item" href="https://github.com/{{ site.github.username }}" target="_blank"><span class="octicon octicon-mark-github"></span></a>
|
||||
<a class="foot-item" href="{{ '/feed.xml' | prepend: site.baseurl | prepend: site.url }}" target="_blank"><span class="octicon octicon-rss"></span></a>
|
||||
<a class="foot-item" href="{{ '/link/' | prepend: site.baseurl | prepend: site.url }}"><span class="octicon octicon-link-external"></span></a>
|
||||
|
||||
<a href="https://github.com/bit-ranger"><span class="word-keep">© bit-ranger</span></a>
|
||||
</div>
|
||||
</footer>
|
||||
<script type="text/javascript" src="https://cdn.bootcss.com/jquery/1.11.3/jquery.min.js"></script>
|
||||
<script type="text/javascript" src="https://cdn.bootcss.com/bootstrap/3.3.0/js/bootstrap.min.js"></script>
|
||||
<script type="text/javascript" src="{{'/static/js/script.js' | prepend:site.baseurl | prepend: site.url }}"></script>
|
||||
{% for script in page.scripts %}<script type="text/javascript" src="{{'/static/js/' | append:script | prepend:site.baseurl | prepend: site.url }}"></script>
|
||||
{%endfor%}
|
||||
{% include svg-icons.html %}
|
||||
|
||||
{% if site.footer-text %}
|
||||
<p>{{ site.footer-text }}</p>
|
||||
{% endif %}
|
||||
21
_includes/gitalk.html
Normal file
@@ -0,0 +1,21 @@
|
||||
{% if site.gitalk.clientID %}
|
||||
<div class="comments">
|
||||
<div id="gitalk-container"></div>
|
||||
<script>
|
||||
const gitalk = new Gitalk({
|
||||
clientID: "{{ site.gitalk.clientID }}",
|
||||
clientSecret: "{{ site.gitalk.clientSecret }}",
|
||||
repo: "{{ site.gitalk.repo }}",
|
||||
owner: "{{ site.gitalk.owner }}",
|
||||
admin: ["{{ site.gitalk.owner }}"],
|
||||
id: window.location.pathname, // Ensure uniqueness and length less than 50
|
||||
distractionFreeMode: false, // Facebook-like distraction free mode
|
||||
title: "{{ page.title }}",
|
||||
language: "zh-CN",
|
||||
|
||||
})
|
||||
|
||||
gitalk.render('gitalk-container')
|
||||
</script>
|
||||
</div>
|
||||
{% endif %}
|
||||
@@ -1,19 +1,28 @@
|
||||
<head>
|
||||
<title>{% if page.title %}{{ page.title }}{% else %}{{ site.title }}{% endif %}</title>
|
||||
<meta charset="utf-8" />
|
||||
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1" />
|
||||
<meta name="keywords" content="{{ page.title }}, {% for category in page.categories %}{{ category }},{% endfor %} {% for tag in page.tags %}{{ tag }},{% endfor %} {{ site.title }}" />
|
||||
<meta name="description" content="{{ page.title }}, {% for category in page.categories %}{{ category }},{% endfor %} {% for tag in page.tags %}{{ tag }},{% endfor %} {% if page.excerpt %}{{ page.excerpt | strip_html | strip_newlines | truncate: 160 }}{% else %}{{ site.description }}{% endif %}" />
|
||||
<meta name="theme-color" content="#2CA6CB"/>
|
||||
<link rel="shortcut icon" type="image/x-icon" media="screen" href="{{ '/favicon.ico' | prepend: site.baseurl | prepend: site.url}}" />
|
||||
<link rel="canonical" href="{{ page.url | replace:'index.html','' | prepend: site.baseurl | prepend: site.url }}" />
|
||||
<link rel="alternate" type="application/rss+xml" title="{{ site.title }}" href="{{ '/feed.xml' | prepend: site.baseurl | prepend: site.url }}" />
|
||||
<title>{% if page.title %}{{ page.title }} – {% endif %}{{ site.name }} – {{ site.description }}</title>
|
||||
|
||||
<link rel="stylesheet" href="https://cdn.bootcss.com/bootstrap/3.3.0/css/bootstrap.min.css"/>
|
||||
<link rel="stylesheet" href="https://cdn.bootcss.com/octicons/3.5.0/octicons.min.css" >
|
||||
<link rel="stylesheet" type="text/css" href="{{ '/static/css/style.css' | prepend: site.baseurl | prepend: site.url}}" />
|
||||
{% for style in page.styles %}<link rel="stylesheet" type="text/css" href="{{ '/static/css/' | append: style | prepend: site.baseurl | prepend: site.url}}" />
|
||||
{%endfor%}
|
||||
{% include meta.html %}
|
||||
{% include fonts.html %}
|
||||
|
||||
<!--[if lt IE 9]>
|
||||
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
|
||||
<![endif]-->
|
||||
|
||||
<link rel="stylesheet" type="text/css" href="{{ site.baseurl }}/style.css" />
|
||||
<link rel="alternate" type="application/rss+xml" title="{{ site.name }} - {{ site.description }}" href="{{ site.baseurl }}/feed.xml" />
|
||||
<link rel="shortcut icon" href="{{ site.favicon }}">
|
||||
<script src="https://cdn.jsdelivr.net/npm/gitalk@1/dist/gitalk.min.js"></script>
|
||||
<script src="https://kit.fontawesome.com/56f7faf3f4.js"></script>
|
||||
<script src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML" type="text/javascript"></script>
|
||||
<script type="text/x-mathjax-config">
|
||||
MathJax.Hub.Config({
|
||||
tex2jax: {
|
||||
skipTags: ['script', 'noscript', 'style', 'textarea', 'pre'],
|
||||
inlineMath: [['$','$']]
|
||||
}
|
||||
});
|
||||
</script>
|
||||
|
||||
<!-- Created with Jekyll Now - http://github.com/barryclark/jekyll-now -->
|
||||
|
||||
</head>
|
||||
|
||||
@@ -1,34 +0,0 @@
|
||||
<header>
|
||||
<nav class="navbar navbar-tiffany rectangle" role="navigation">
|
||||
<div class="container">
|
||||
<div class="navbar-header">
|
||||
<button type="button" class="navbar-toggle" data-toggle="collapse" data-target=".navbar-collapse">
|
||||
<span class="icon-bar"></span>
|
||||
<span class="icon-bar"></span>
|
||||
<span class="icon-bar"></span>
|
||||
</button>
|
||||
<a class="navbar-brand" href="{{ site.baseurl | prepend: site.url }}/">{{ site.title }}</a>
|
||||
<p class="navbar-text">{{ site.description }}</p>
|
||||
</div>
|
||||
<div class="collapse navbar-collapse">
|
||||
<ul class="nav navbar-nav navbar-right">
|
||||
{% if page.url == "/index.html" %}
|
||||
<li class="active">{% else %}
|
||||
<li>{% endif %}
|
||||
<a href="{{ site.baseurl | prepend: site.url }}/" class="word-keep"><span class="octicon octicon-book"></span></span> Blog</a>
|
||||
</li>
|
||||
{% for p in site.pages %}{% if p.isNavItem %}
|
||||
{% if p.url == page.url %}
|
||||
<li class="active">{% else %}
|
||||
<li>{% endif %}
|
||||
<a href="{{ p.url | prepend: site.baseurl | prepend: site.url }}" class="word-keep"><span class="octicon {{ p.icon }}"></span> {{ p.title }}</a>
|
||||
</li>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
<li><a href="#stq=" class="search-button"><span class="octicon octicon-search"></span></a></li>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
</header>
|
||||
|
||||
18
_includes/meta.html
Normal file
@@ -0,0 +1,18 @@
|
||||
<meta charset="utf-8" />
|
||||
<meta content='text/html; charset=utf-8' http-equiv='Content-Type'>
|
||||
<meta http-equiv='X-UA-Compatible' content='IE=edge'>
|
||||
<meta name='viewport' content='width=device-width, initial-scale=1.0, maximum-scale=1.0'>
|
||||
|
||||
{% if page.excerpt %}
|
||||
<meta name="description" content="{{ page.excerpt| strip_html }}" />
|
||||
<meta property="og:description" content="{{ page.excerpt| strip_html }}" />
|
||||
{% else %}
|
||||
<meta name="description" content="{{ site.description }}">
|
||||
<meta property="og:description" content="{{ site.description }}" />
|
||||
{% endif %}
|
||||
<meta name="author" content="{{ site.name }}" />
|
||||
|
||||
{% if page.title %}
|
||||
<meta property="og:title" content="{{ page.title }}" />
|
||||
<meta property="twitter:title" content="{{ page.title }}" />
|
||||
{% endif %}
|
||||
29
_includes/nav.html
Normal file
@@ -0,0 +1,29 @@
|
||||
<div class="wrapper-sidebar">
|
||||
<header class="sidebar clearfix">
|
||||
<div class="site-info">
|
||||
{% if site.avatar %}
|
||||
<a href="{{ site.baseurl }}/" class="site-avatar"><img src="{{ site.avatar }}" /></a>
|
||||
{% endif %}
|
||||
<h1 class="site-name"><a href="{{ site.baseurl }}/">{{ site.name }}</a></h1>
|
||||
<p class="site-description">{{ site.description }}</p>
|
||||
</div>
|
||||
</header>
|
||||
|
||||
<div class="navlist">
|
||||
<nav>
|
||||
{% for nav in site.navigation %}
|
||||
{% if nav.url contains 'http://' or nav.url contains 'https://' %}
|
||||
<a href="{{ nav.url }}">{{ nav.name }}</a>
|
||||
{% else %}
|
||||
<a href="{{ site.baseurl }}{{ nav.url }}">{{ nav.name }}</a>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
</nav>
|
||||
</div>
|
||||
|
||||
<div class="wrapper-footer-desktop">
|
||||
<footer class="footer">
|
||||
{% include footer.html %}
|
||||
</footer>
|
||||
</div>
|
||||
</div>
|
||||
64
_includes/svg-icons.html
Normal file
@@ -0,0 +1,64 @@
|
||||
<!-- Refer to https://codepen.io/ruandre/pen/howFi -->
|
||||
<ul class="svg-icon">
|
||||
|
||||
{% if site.footer-links.weibo %}
|
||||
<li><a href="https://www.weibo.com/{{ site.footer-links.weibo }}" class="icon-1 weibo" title="Weibo"><svg viewBox="0 0 512 512"><path d="M407 177.6c7.6-24-13.4-46.8-37.4-41.7-22 4.8-28.8-28.1-7.1-32.8 50.1-10.9 92.3 37.1 76.5 84.8-6.8 21.2-38.8 10.8-32-10.3zM214.8 446.7C108.5 446.7 0 395.3 0 310.4c0-44.3 28-95.4 76.3-143.7C176 67 279.5 65.8 249.9 161c-4 13.1 12.3 5.7 12.3 6 79.5-33.6 140.5-16.8 114 51.4-3.7 9.4 1.1 10.9 8.3 13.1 135.7 42.3 34.8 215.2-169.7 215.2zm143.7-146.3c-5.4-55.7-78.5-94-163.4-85.7-84.8 8.6-148.8 60.3-143.4 116s78.5 94 163.4 85.7c84.8-8.6 148.8-60.3 143.4-116zM347.9 35.1c-25.9 5.6-16.8 43.7 8.3 38.3 72.3-15.2 134.8 52.8 111.7 124-7.4 24.2 29.1 37 37.4 12 31.9-99.8-55.1-195.9-157.4-174.3zm-78.5 311c-17.1 38.8-66.8 60-109.1 46.3-40.8-13.1-58-53.4-40.3-89.7 17.7-35.4 63.1-55.4 103.4-45.1 42 10.8 63.1 50.2 46 88.5zm-86.3-30c-12.9-5.4-30 .3-38 12.9-8.3 12.9-4.3 28 8.6 34 13.1 6 30.8.3 39.1-12.9 8-13.1 3.7-28.3-9.7-34zm32.6-13.4c-5.1-1.7-11.4.6-14.3 5.4-2.9 5.1-1.4 10.6 3.7 12.9 5.1 2 11.7-.3 14.6-5.4 2.8-5.2 1.1-10.9-4-12.9z"></svg></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.behance %}
|
||||
<li><a href="https://www.behance.net/{{ site.footer-links.behance }}" class="icon-3 behance" title="Behance"><svg viewBox="0 0 512 512"><path d="M232 237.2c31.8-15.2 48.4-38.2 48.4-74 0-70.6-52.6-87.8-113.3-87.8H0v354.4h171.8c64.4 0 124.9-30.9 124.9-102.9 0-44.5-21.1-77.4-64.7-89.7zM77.9 135.9H151c28.1 0 53.4 7.9 53.4 40.5 0 30.1-19.7 42.2-47.5 42.2h-79v-82.7zm83.3 233.7H77.9V272h84.9c34.3 0 56 14.3 56 50.6 0 35.8-25.9 47-57.6 47zm358.5-240.7H376V94h143.7v34.9zM576 305.2c0-75.9-44.4-139.2-124.9-139.2-78.2 0-131.3 58.8-131.3 135.8 0 79.9 50.3 134.7 131.3 134.7 61.3 0 101-27.6 120.1-86.3H509c-6.7 21.9-34.3 33.5-55.7 33.5-41.3 0-63-24.2-63-65.3h185.1c.3-4.2.6-8.7.6-13.2zM390.4 274c2.3-33.7 24.7-54.8 58.5-54.8 35.4 0 53.2 20.8 56.2 54.8H390.4z"/></svg><!--[if lt IE 9]><em>Behance</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.dribbble %}
|
||||
<li><a href="https://dribbble.com/{{ site.footer-links.dribbble }}" class="icon-7 dribbble" title="Dribbble"><svg viewBox="0 0 512 512"><path d="M256 8C119.252 8 8 119.252 8 256s111.252 248 248 248 248-111.252 248-248S392.748 8 256 8zm163.97 114.366c29.503 36.046 47.369 81.957 47.835 131.955-6.984-1.477-77.018-15.682-147.502-6.818-5.752-14.041-11.181-26.393-18.617-41.614 78.321-31.977 113.818-77.482 118.284-83.523zM396.421 97.87c-3.81 5.427-35.697 48.286-111.021 76.519-34.712-63.776-73.185-116.168-79.04-124.008 67.176-16.193 137.966 1.27 190.061 47.489zm-230.48-33.25c5.585 7.659 43.438 60.116 78.537 122.509-99.087 26.313-186.36 25.934-195.834 25.809C62.38 147.205 106.678 92.573 165.941 64.62zM44.17 256.323c0-2.166.043-4.322.108-6.473 9.268.19 111.92 1.513 217.706-30.146 6.064 11.868 11.857 23.915 17.174 35.949-76.599 21.575-146.194 83.527-180.531 142.306C64.794 360.405 44.17 310.73 44.17 256.323zm81.807 167.113c22.127-45.233 82.178-103.622 167.579-132.756 29.74 77.283 42.039 142.053 45.189 160.638-68.112 29.013-150.015 21.053-212.768-27.882zm248.38 8.489c-2.171-12.886-13.446-74.897-41.152-151.033 66.38-10.626 124.7 6.768 131.947 9.055-9.442 58.941-43.273 109.844-90.795 141.978z"/></svg><!--[if lt IE 9]><em>Dribbble</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.email %}
|
||||
<li><a href="mailto:{{ site.footer-links.email }}" class="icon-8 email" title="Email"><svg viewBox="0 0 512 512"><path d="M502.3 190.8c3.9-3.1 9.7-.2 9.7 4.7V400c0 26.5-21.5 48-48 48H48c-26.5 0-48-21.5-48-48V195.6c0-5 5.7-7.8 9.7-4.7 22.4 17.4 52.1 39.5 154.1 113.6 21.1 15.4 56.7 47.8 92.2 47.6 35.7.3 72-32.8 92.3-47.6 102-74.1 131.6-96.3 154-113.7zM256 320c23.2.4 56.6-29.2 73.4-41.4 132.7-96.3 142.8-104.7 173.4-128.7 5.8-4.5 9.2-11.5 9.2-18.9v-19c0-26.5-21.5-48-48-48H48C21.5 64 0 85.5 0 112v19c0 7.4 3.4 14.3 9.2 18.9 30.6 23.9 40.7 32.4 173.4 128.7 16.8 12.2 50.2 41.8 73.4 41.4z"/></svg><!--[if lt IE 9]><em>Email</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.facebook %}
|
||||
<li><a href="https://www.facebook.com/{{ site.footer-links.facebook }}" class="icon-10 facebook" title="Facebook"><svg viewBox="0 0 512 512"><path d="M211.9 197.4h-36.7v59.9h36.7V433.1h70.5V256.5h49.2l5.2-59.1h-54.4c0 0 0-22.1 0-33.7 0-13.9 2.8-19.5 16.3-19.5 10.9 0 38.2 0 38.2 0V82.9c0 0-40.2 0-48.8 0 -52.5 0-76.1 23.1-76.1 67.3C211.9 188.8 211.9 197.4 211.9 197.4z"/></svg><!--[if lt IE 9]><em>Facebook</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.flickr %}
|
||||
<li><a href="https://www.flickr.com/{{ site.footer-links.flickr }}" class="icon-11 flickr" title="Flickr"><svg viewBox="0 0 512 512"><path d="M400 32H48C21.5 32 0 53.5 0 80v352c0 26.5 21.5 48 48 48h352c26.5 0 48-21.5 48-48V80c0-26.5-21.5-48-48-48zM144.5 319c-35.1 0-63.5-28.4-63.5-63.5s28.4-63.5 63.5-63.5 63.5 28.4 63.5 63.5-28.4 63.5-63.5 63.5zm159 0c-35.1 0-63.5-28.4-63.5-63.5s28.4-63.5 63.5-63.5 63.5 28.4 63.5 63.5-28.4 63.5-63.5 63.5z"/></svg><!--[if lt IE 9]><em>Flickr</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.github %}
|
||||
<li><a href="https://github.com/{{ site.footer-links.github }}" class="icon-13 github" title="GitHub"><svg viewBox="0 0 512 512"><path d="M165.9 397.4c0 2-2.3 3.6-5.2 3.6-3.3.3-5.6-1.3-5.6-3.6 0-2 2.3-3.6 5.2-3.6 3-.3 5.6 1.3 5.6 3.6zm-31.1-4.5c-.7 2 1.3 4.3 4.3 4.9 2.6 1 5.6 0 6.2-2s-1.3-4.3-4.3-5.2c-2.6-.7-5.5.3-6.2 2.3zm44.2-1.7c-2.9.7-4.9 2.6-4.6 4.9.3 2 2.9 3.3 5.9 2.6 2.9-.7 4.9-2.6 4.6-4.6-.3-1.9-3-3.2-5.9-2.9zM244.8 8C106.1 8 0 113.3 0 252c0 110.9 69.8 205.8 169.5 239.2 12.8 2.3 17.3-5.6 17.3-12.1 0-6.2-.3-40.4-.3-61.4 0 0-70 15-84.7-29.8 0 0-11.4-29.1-27.8-36.6 0 0-22.9-15.7 1.6-15.4 0 0 24.9 2 38.6 25.8 21.9 38.6 58.6 27.5 72.9 20.9 2.3-16 8.8-27.1 16-33.7-55.9-6.2-112.3-14.3-112.3-110.5 0-27.5 7.6-41.3 23.6-58.9-2.6-6.5-11.1-33.3 2.6-67.9 20.9-6.5 69 27 69 27 20-5.6 41.5-8.5 62.8-8.5s42.8 2.9 62.8 8.5c0 0 48.1-33.6 69-27 13.7 34.7 5.2 61.4 2.6 67.9 16 17.7 25.8 31.5 25.8 58.9 0 96.5-58.9 104.2-114.8 110.5 9.2 7.9 17 22.9 17 46.4 0 33.7-.3 75.4-.3 83.6 0 6.5 4.6 14.4 17.3 12.1C428.2 457.8 496 362.9 496 252 496 113.3 383.5 8 244.8 8zM97.2 352.9c-1.3 1-1 3.3.7 5.2 1.6 1.6 3.9 2.3 5.2 1 1.3-1 1-3.3-.7-5.2-1.6-1.6-3.9-2.3-5.2-1zm-10.8-8.1c-.7 1.3.3 2.9 2.3 3.9 1.6 1 3.6.7 4.3-.7.7-1.3-.3-2.9-2.3-3.9-2-.6-3.6-.3-4.3.7zm32.4 35.6c-1.6 1.3-1 4.3 1.3 6.2 2.3 2.3 5.2 2.6 6.5 1 1.3-1.3.7-4.3-1.3-6.2-2.2-2.3-5.2-2.6-6.5-1zm-11.4-14.7c-1.6 1-1.6 3.6 0 5.9 1.6 2.3 4.3 3.3 5.6 2.3 1.6-1.3 1.6-3.9 0-6.2-1.4-2.3-4-3.3-5.6-2z"/></svg><!--[if lt IE 9]><em>GitHub</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.instagram %}
|
||||
<li><a href="https://instagram.com/{{ site.footer-links.instagram }}" class="icon-15 instagram" title="Instagram"><svg viewBox="0 0 512 512"><g><path d="M224.1 141c-63.6 0-114.9 51.3-114.9 114.9s51.3 114.9 114.9 114.9S339 319.5 339 255.9 287.7 141 224.1 141zm0 189.6c-41.1 0-74.7-33.5-74.7-74.7s33.5-74.7 74.7-74.7 74.7 33.5 74.7 74.7-33.6 74.7-74.7 74.7zm146.4-194.3c0 14.9-12 26.8-26.8 26.8-14.9 0-26.8-12-26.8-26.8s12-26.8 26.8-26.8 26.8 12 26.8 26.8zm76.1 27.2c-1.7-35.9-9.9-67.7-36.2-93.9-26.2-26.2-58-34.4-93.9-36.2-37-2.1-147.9-2.1-184.9 0-35.8 1.7-67.6 9.9-93.9 36.1s-34.4 58-36.2 93.9c-2.1 37-2.1 147.9 0 184.9 1.7 35.9 9.9 67.7 36.2 93.9s58 34.4 93.9 36.2c37 2.1 147.9 2.1 184.9 0 35.9-1.7 67.7-9.9 93.9-36.2 26.2-26.2 34.4-58 36.2-93.9 2.1-37 2.1-147.8 0-184.8zM398.8 388c-7.8 19.6-22.9 34.7-42.6 42.6-29.5 11.7-99.5 9-132.1 9s-102.7 2.6-132.1-9c-19.6-7.8-34.7-22.9-42.6-42.6-11.7-29.5-9-99.5-9-132.1s-2.6-102.7 9-132.1c7.8-19.6 22.9-34.7 42.6-42.6 29.5-11.7 99.5-9 132.1-9s102.7-2.6 132.1 9c19.6 7.8 34.7 22.9 42.6 42.6 11.7 29.5 9 99.5 9 132.1s2.7 102.7-9 132.1z"/><circle cx="351.5" cy="160.5" r="21.5"/></g></svg><!--[if lt IE 9]><em>Instagram</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.linkedin %}
|
||||
<li><a href="https://www.linkedin.com/in/{{ site.footer-links.linkedin }}" class="icon-17 linkedin" title="LinkedIn"><svg viewBox="0 0 512 512"><path d="M416 32H31.9C14.3 32 0 46.5 0 64.3v383.4C0 465.5 14.3 480 31.9 480H416c17.6 0 32-14.5 32-32.3V64.3c0-17.8-14.4-32.3-32-32.3zM135.4 416H69V202.2h66.5V416zm-33.2-243c-21.3 0-38.5-17.3-38.5-38.5S80.9 96 102.2 96c21.2 0 38.5 17.3 38.5 38.5 0 21.3-17.2 38.5-38.5 38.5zm282.1 243h-66.4V312c0-24.8-.5-56.7-34.5-56.7-34.6 0-39.9 27-39.9 54.9V416h-66.4V202.2h63.7v29.2h.9c8.9-16.8 30.6-34.5 62.9-34.5 67.2 0 79.7 44.3 79.7 101.9V416z"/></svg><!--[if lt IE 9]><em>LinkedIn</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.pinterest %}
|
||||
<li><a href="https://www.pinterest.com/{{ site.footer-links.pinterest }}" class="icon-20 pinterest" title="Pinterest"><svg viewBox="0 0 512 512"><path d="M496 256c0 137-111 248-248 248-25.6 0-50.2-3.9-73.4-11.1 10.1-16.5 25.2-43.5 30.8-65 3-11.6 15.4-59 15.4-59 8.1 15.4 31.7 28.5 56.8 28.5 74.8 0 128.7-68.8 128.7-154.3 0-81.9-66.9-143.2-152.9-143.2-107 0-163.9 71.8-163.9 150.1 0 36.4 19.4 81.7 50.3 96.1 4.7 2.2 7.2 1.2 8.3-3.3.8-3.4 5-20.3 6.9-28.1.6-2.5.3-4.7-1.7-7.1-10.1-12.5-18.3-35.3-18.3-56.6 0-54.7 41.4-107.6 112-107.6 60.9 0 103.6 41.5 103.6 100.9 0 67.1-33.9 113.6-78 113.6-24.3 0-42.6-20.1-36.7-44.8 7-29.5 20.5-61.3 20.5-82.6 0-19-10.2-34.9-31.4-34.9-24.9 0-44.9 25.7-44.9 60.2 0 22 7.4 36.8 7.4 36.8s-24.5 103.8-29 123.2c-5 21.4-3 51.6-.9 71.2C65.4 450.9 0 361.1 0 256 0 119 111 8 248 8s248 111 248 248z"/></svg><!--[if lt IE 9]><em>Pinterest</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.rss %}
|
||||
<li><a href="{{ site.baseurl }}/feed.xml" class="icon-21 rss" title="RSS"><svg viewBox="0 0 512 512"><path d="M400 32H48C21.49 32 0 53.49 0 80v352c0 26.51 21.49 48 48 48h352c26.51 0 48-21.49 48-48V80c0-26.51-21.49-48-48-48zM112 416c-26.51 0-48-21.49-48-48s21.49-48 48-48 48 21.49 48 48-21.49 48-48 48zm157.533 0h-34.335c-6.011 0-11.051-4.636-11.442-10.634-5.214-80.05-69.243-143.92-149.123-149.123-5.997-.39-10.633-5.431-10.633-11.441v-34.335c0-6.535 5.468-11.777 11.994-11.425 110.546 5.974 198.997 94.536 204.964 204.964.352 6.526-4.89 11.994-11.425 11.994zm103.027 0h-34.334c-6.161 0-11.175-4.882-11.427-11.038-5.598-136.535-115.204-246.161-251.76-251.76C68.882 152.949 64 147.935 64 141.774V107.44c0-6.454 5.338-11.664 11.787-11.432 167.83 6.025 302.21 141.191 308.205 308.205.232 6.449-4.978 11.787-11.432 11.787z"/></svg><!--[if lt IE 9]><em>RSS</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.stackoverflow %}
|
||||
<li><a href="http://stackoverflow.com/{{ site.footer-links.stackoverflow }}" class="icon-23 stackoverflow" title="StackOverflow"><svg viewBox="0 0 512 512"><path d="M290.7 311L95 269.7 86.8 309l195.7 41zm51-87L188.2 95.7l-25.5 30.8 153.5 128.3zm-31.2 39.7L129.2 179l-16.7 36.5L293.7 300zM262 32l-32 24 119.3 160.3 32-24zm20.5 328h-200v39.7h200zm39.7 80H42.7V320h-40v160h359.5V320h-40z"/></svg><!--[if lt IE 9]><em>StackOverflow</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.tumblr %}
|
||||
<li><a href="https://{{ site.footer-links.tumblr }}.tumblr.com" class="icon-25 tumblr" title="Tumblr"><svg viewBox="0 0 512 512"><path d="M309.8 480.3c-13.6 14.5-50 31.7-97.4 31.7-120.8 0-147-88.8-147-140.6v-144H17.9c-5.5 0-10-4.5-10-10v-68c0-7.2 4.5-13.6 11.3-16 62-21.8 81.5-76 84.3-117.1.8-11 6.5-16.3 16.1-16.3h70.9c5.5 0 10 4.5 10 10v115.2h83c5.5 0 10 4.4 10 9.9v81.7c0 5.5-4.5 10-10 10h-83.4V360c0 34.2 23.7 53.6 68 35.8 4.8-1.9 9-3.2 12.7-2.2 3.5.9 5.8 3.4 7.4 7.9l22 64.3c1.8 5 3.3 10.6-.4 14.5z"/></svg><!--[if lt IE 9]><em>Tumblr</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.twitter %}
|
||||
<li><a href="https://www.twitter.com/{{ site.footer-links.twitter }}" class="icon-26 twitter" title="Twitter"><svg viewBox="0 0 512 512"><path d="M459.37 151.716c.325 4.548.325 9.097.325 13.645 0 138.72-105.583 298.558-298.558 298.558-59.452 0-114.68-17.219-161.137-47.106 8.447.974 16.568 1.299 25.34 1.299 49.055 0 94.213-16.568 130.274-44.832-46.132-.975-84.792-31.188-98.112-72.772 6.498.974 12.995 1.624 19.818 1.624 9.421 0 18.843-1.3 27.614-3.573-48.081-9.747-84.143-51.98-84.143-102.985v-1.299c13.969 7.797 30.214 12.67 47.431 13.319-28.264-18.843-46.781-51.005-46.781-87.391 0-19.492 5.197-37.36 14.294-52.954 51.655 63.675 129.3 105.258 216.365 109.807-1.624-7.797-2.599-15.918-2.599-24.04 0-57.828 46.782-104.934 104.934-104.934 30.213 0 57.502 12.67 76.67 33.137 23.715-4.548 46.456-13.32 66.599-25.34-7.798 24.366-24.366 44.833-46.132 57.827 21.117-2.273 41.584-8.122 60.426-16.243-14.292 20.791-32.161 39.308-52.628 54.253z"/></svg><!--[if lt IE 9]><em>Twitter</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
{% if site.footer-links.youtube %}
|
||||
<li><a href="https://youtube.com/{{ site.footer-links.youtube }}" class="icon-28 youtube" title="YouTube"><svg viewBox="0 0 512 512"><path d="M549.655 124.083c-6.281-23.65-24.787-42.276-48.284-48.597C458.781 64 288 64 288 64S117.22 64 74.629 75.486c-23.497 6.322-42.003 24.947-48.284 48.597-11.412 42.867-11.412 132.305-11.412 132.305s0 89.438 11.412 132.305c6.281 23.65 24.787 41.5 48.284 47.821C117.22 448 288 448 288 448s170.78 0 213.371-11.486c23.497-6.321 42.003-24.171 48.284-47.821 11.412-42.867 11.412-132.305 11.412-132.305s0-89.438-11.412-132.305zm-317.51 213.508V175.185l142.739 81.205-142.739 81.201z"/></svg><!--[if lt IE 9]><em>YouTube</em><![endif]--></a></li>
|
||||
{% endif %}
|
||||
|
||||
</ul>
|
||||
104
_includes/toc.html
Normal file
@@ -0,0 +1,104 @@
|
||||
{% capture tocWorkspace %}
|
||||
{% comment %}
|
||||
Version 1.0.8
|
||||
https://github.com/allejo/jekyll-toc
|
||||
|
||||
"...like all things liquid - where there's a will, and ~36 hours to spare, there's usually a/some way" ~jaybe
|
||||
|
||||
Usage:
|
||||
{% include toc.html html=content sanitize=true class="inline_toc" id="my_toc" h_min=2 h_max=3 %}
|
||||
|
||||
Parameters:
|
||||
* html (string) - the HTML of compiled markdown generated by kramdown in Jekyll
|
||||
|
||||
Optional Parameters:
|
||||
* sanitize (bool) : false - when set to true, the headers will be stripped of any HTML in the TOC
|
||||
* class (string) : '' - a CSS class assigned to the TOC
|
||||
* id (string) : '' - an ID to assigned to the TOC
|
||||
* h_min (int) : 1 - the minimum TOC header level to use; any header lower than this value will be ignored
|
||||
* h_max (int) : 6 - the maximum TOC header level to use; any header greater than this value will be ignored
|
||||
* ordered (bool) : false - when set to true, an ordered list will be outputted instead of an unordered list
|
||||
* item_class (string) : '' - add custom class(es) for each list item; has support for '%level%' placeholder, which is the current heading level
|
||||
* baseurl (string) : '' - add a base url to the TOC links for when your TOC is on another page than the actual content
|
||||
* anchor_class (string) : '' - add custom class(es) for each anchor element
|
||||
|
||||
Output:
|
||||
An ordered or unordered list representing the table of contents of a markdown block. This snippet will only
|
||||
generate the table of contents and will NOT output the markdown given to it
|
||||
{% endcomment %}
|
||||
|
||||
{% capture my_toc %}{% endcapture %}
|
||||
{% assign orderedList = include.ordered | default: false %}
|
||||
{% assign minHeader = include.h_min | default: 1 %}
|
||||
{% assign maxHeader = include.h_max | default: 6 %}
|
||||
{% assign nodes = include.html | split: '<h' %}
|
||||
{% assign firstHeader = true %}
|
||||
|
||||
{% capture listModifier %}{% if orderedList %}1.{% else %}-{% endif %}{% endcapture %}
|
||||
|
||||
{% for node in nodes %}
|
||||
{% if node == "" %}
|
||||
{% continue %}
|
||||
{% endif %}
|
||||
|
||||
{% assign lastHeaderLevel = headerLevel %}
|
||||
{% assign headerLevel = node | replace: '"', '' | slice: 0, 1 | times: 1 %}
|
||||
|
||||
{% if headerLevel < minHeader or headerLevel > maxHeader %}
|
||||
{% continue %}
|
||||
{% endif %}
|
||||
|
||||
{% if firstHeader %}
|
||||
{% assign firstHeader = false %}
|
||||
{% assign minHeader = headerLevel %}
|
||||
{% endif %}
|
||||
|
||||
{% assign lastIndent = indentAmount %}
|
||||
{% assign indentAmount = headerLevel | minus: minHeader | add: 1 %}
|
||||
{% if lastHeaderLevel and lastHeaderLevel == headerLevel %}
|
||||
{% assign indentAmount = lastIndent %}
|
||||
{% elsif lastIndent and lastIndent < indentAmount %}
|
||||
{% assign indentAmount = lastIndent | plus: 1 %}
|
||||
{% endif %}
|
||||
|
||||
{% assign _workspace = node | split: '</h' %}
|
||||
|
||||
{% assign _idWorkspace = _workspace[0] | split: 'id="' %}
|
||||
{% assign _idWorkspace = _idWorkspace[1] | split: '"' %}
|
||||
{% assign html_id = _idWorkspace[0] %}
|
||||
|
||||
{% assign _classWorkspace = _workspace[0] | split: 'class="' %}
|
||||
{% assign _classWorkspace = _classWorkspace[1] | split: '"' %}
|
||||
{% assign html_class = _classWorkspace[0] %}
|
||||
|
||||
{% if html_class contains "no_toc" %}
|
||||
{% continue %}
|
||||
{% endif %}
|
||||
|
||||
{% capture _hAttrToStrip %}{{ _workspace[0] | split: '>' | first }}>{% endcapture %}
|
||||
{% assign header = _workspace[0] | replace: _hAttrToStrip, '' %}
|
||||
|
||||
{% assign space = '' %}
|
||||
{% for i in (1..indentAmount) %}
|
||||
{% assign space = space | prepend: ' ' %}
|
||||
{% endfor %}
|
||||
|
||||
{% unless include.item_class == blank %}
|
||||
{% capture listItemClass %}{:.{{ include.item_class | replace: '%level%', headerLevel }}}{% endcapture %}
|
||||
{% endunless %}
|
||||
|
||||
{% capture heading_body %}{% if include.sanitize %}{{ header | strip_html }}{% else %}{{ header }}{% endif %}{% endcapture %}
|
||||
{% capture my_toc %}{{ my_toc }}
|
||||
{{ space }}{{ listModifier }} {{ listItemClass }} [{{ heading_body | replace: "|", "\|" }}]({% if include.baseurl %}{{ include.baseurl }}{% endif %}#{{ html_id }}){% if include.anchor_class %}{:.{{ include.anchor_class }}}{% endif %}{% endcapture %}
|
||||
{% endfor %}
|
||||
|
||||
{% if include.class %}
|
||||
{% capture my_toc %}{:.{{ include.class }}}
|
||||
{{ my_toc | lstrip }}{% endcapture %}
|
||||
{% endif %}
|
||||
|
||||
{% if include.id %}
|
||||
{% capture my_toc %}{: #{{ include.id }}}
|
||||
{{ my_toc | lstrip }}{% endcapture %}
|
||||
{% endif %}
|
||||
{% endcapture %}{% assign tocWorkspace = '' %}{{ my_toc | markdownify | strip }}
|
||||
@@ -1,25 +1,34 @@
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
{% include head.html %}
|
||||
<body>
|
||||
{% include nav.html %}
|
||||
|
||||
{% include head.html %}
|
||||
{% if page.toc==true %}
|
||||
<aside class="toc">
|
||||
{% include toc.html html=content %}
|
||||
</aside>
|
||||
{% endif %}
|
||||
|
||||
<body>
|
||||
|
||||
{% include header.html %}
|
||||
|
||||
<div class="main">
|
||||
<div class="container">
|
||||
<div id="main" role="main" class="wrapper-content">
|
||||
<div class="container">
|
||||
{{ content }}
|
||||
</div>
|
||||
</div>
|
||||
<div class="page-scrollTop" data-toggle="tooltip" data-placement="top" title="Top">
|
||||
<a href="javascript:void(0);">
|
||||
<div class="arrow"></div>
|
||||
<div class="stick"></div>
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
{% include footer.html %}
|
||||
{% include analytics.html %}
|
||||
</body>
|
||||
|
||||
{% if page.toc==true %}
|
||||
<script>
|
||||
document.getElementById("main").classList.add("withtoc");
|
||||
</script>
|
||||
{% endif %}
|
||||
|
||||
<div class="wrapper-footer-mobile">
|
||||
<footer class="footer">
|
||||
{% include footer.html %}
|
||||
</footer>
|
||||
|
||||
|
||||
</body>
|
||||
</html>
|
||||
|
||||
@@ -1,16 +1,12 @@
|
||||
---
|
||||
layout: default
|
||||
---
|
||||
<div class="row">
|
||||
<div class="content">
|
||||
<div class="sheet">
|
||||
<header>
|
||||
<h1>{{ page.title }}</h1>
|
||||
</header>
|
||||
<hr>
|
||||
<article>
|
||||
{{ content }}
|
||||
</article>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<article class="page">
|
||||
|
||||
<h1>{{ page.title }}</h1>
|
||||
|
||||
<div class="entry">
|
||||
{{ content }}
|
||||
</div>
|
||||
</article>
|
||||
|
||||
@@ -1,103 +1,47 @@
|
||||
---
|
||||
layout: default
|
||||
---
|
||||
<div class="row">
|
||||
<div class="content col-lg-9">
|
||||
<div class="sheet post">
|
||||
<header>
|
||||
<h2>{{ page.title }}</h2>
|
||||
<p class="post-meta">
|
||||
<span class="octicon octicon-clock"></span> {{ page.date | date: "%b %-d, %Y" }}{% if page.author %} • {{ page.author }}{% endif %}{% if page.meta %} • {{ page.meta }}{% endif %}
|
||||
</p>
|
||||
<p class="post-tag">
|
||||
<span>{% for cat in page.categories %}<a href="{{ '/category' | prepend: site.baseurl | prepend: site.url }}/#{{ cat }}"><span class="octicon octicon-list-unordered"></span> {{ cat }}</a>{% endfor %}</span>
|
||||
<span>{% for tag in page.tags %}
|
||||
<a class="word-keep" href="{{ '/tags' | prepend: site.baseurl | prepend: site.url }}/#{{ tag }}"><span class="octicon octicon-tag"></span> {{ tag }}</a>
|
||||
{% endfor %}
|
||||
</span>
|
||||
</p>
|
||||
</header>
|
||||
<hr class="boundary">
|
||||
<article>
|
||||
{{content}}
|
||||
</article>
|
||||
<hr class="boundary">
|
||||
<div id="post-share" class="bdsharebuttonbox">
|
||||
<a href="#" class="bds_more" data-cmd="more"></a>
|
||||
<a href="#" class="bds_tsina" data-cmd="tsina" title="分享到新浪微博"></a>
|
||||
<a href="#" class="bds_weixin" data-cmd="weixin" title="分享到微信"></a>
|
||||
<a href="#" class="bds_douban" data-cmd="douban" title="分享到豆瓣网"></a>
|
||||
<a href="#" class="bds_fbook" data-cmd="fbook" title="分享到Facebook"></a>
|
||||
<a href="#" class="bds_copy" data-cmd="copy" title="分享到复制网址"></a>
|
||||
</div>
|
||||
</div>
|
||||
<div class="pad-min"></div>
|
||||
<div id="post-comment" class="sheet post hidden">
|
||||
<div id="disqus_thread"></div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="content-navigation col-lg-3">
|
||||
<div class="shadow-bottom-center" >
|
||||
<div class="content-navigation-toc">
|
||||
<div class="content-navigation-header">
|
||||
<span class="octicon octicon-list-unordered"></span> Toc
|
||||
</div>
|
||||
<div class="content-navigation-list toc"></div>
|
||||
</div>
|
||||
<div class="content-navigation-tag">
|
||||
<div class="content-navigation-header">
|
||||
<span class="octicon octicon-list-unordered"></span> Tags
|
||||
</div>
|
||||
<div class="content-navigation-list">
|
||||
<ul>
|
||||
{% for tag in page.tags %}
|
||||
<li>
|
||||
<a href="{{ '/tags' | prepend: site.baseurl | prepend: site.url }}#{{ tag }}"><span class="octicon octicon-tag"></span> {{ tag }}</a>
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
<div class="content-navigation-related">
|
||||
<div class="content-navigation-header">
|
||||
<span class="octicon octicon-list-unordered"></span> Related
|
||||
</div>
|
||||
<div class="content-navigation-list">
|
||||
<ul>
|
||||
{% assign postsAfterFilter = '-' | split: "-" %}
|
||||
|
||||
{% for p in site.posts %}
|
||||
{%if p.url != page.url %}
|
||||
{% assign commonTagCount = 0 %}
|
||||
<article class="posts">
|
||||
<h1>{{ page.title }}</h1>
|
||||
|
||||
{% for tag in p.tags %}
|
||||
{% if page.tags contains tag %}
|
||||
{% assign commonTagCount = commonTagCount | plus: 1 %}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
<div clsss="meta">
|
||||
<span class="date">
|
||||
{{ page.date | date: "%Y-%m-%d" }}
|
||||
</span>
|
||||
|
||||
{% for cat in p.categories %}
|
||||
{% if page.categories contains cat %}
|
||||
{% assign commonTagCount = commonTagCount | plus: 1 %}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
<ul class="tag">
|
||||
{% for tag in page.tags %}
|
||||
<li>
|
||||
<a href="{{ site.url }}{{ site.baseurl }}/tags#{{ tag }}">
|
||||
{{ tag }}
|
||||
</a>
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
{% if commonTagCount > 0 %}
|
||||
{% assign postsAfterFilter = postsAfterFilter | push: p %}
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
<div class="entry">
|
||||
{{ content }}
|
||||
</div>
|
||||
|
||||
{% if postsAfterFilter.size > 0 %}
|
||||
{% for p in postsAfterFilter limit: 15 %}
|
||||
<li>
|
||||
<a href="{{ p.url | prepend: site.baseurl | prepend: site.url }}">{{ p.title }}</a>
|
||||
</li>
|
||||
{% endfor %}
|
||||
{% endif %}
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
{% include disqus.html %}
|
||||
{% include gitalk.html %}
|
||||
</article>
|
||||
|
||||
<div class="pagination">
|
||||
{% if page.previous.url %}
|
||||
<span class="prev" >
|
||||
<a href="{{ site.url }}{{ site.baseurl }}{{ page.previous.url }}">
|
||||
← 上一篇
|
||||
</a>
|
||||
</span>
|
||||
{% endif %}
|
||||
{% if page.next.url %}
|
||||
<span class="next" >
|
||||
<a href="{{ site.url }}{{ site.baseurl }}{{ page.next.url }}">
|
||||
下一篇 →
|
||||
</a>
|
||||
</span>
|
||||
{% endif %}
|
||||
</div>
|
||||
260
_posts/2013-07-16-chinese-markdown-cheatsheet.md
Normal file
@@ -0,0 +1,260 @@
|
||||
---
|
||||
layout: post
|
||||
title: Markdown语法简介
|
||||
date: 2013-07-16
|
||||
Author: Shengbin
|
||||
tags: [sample, markdown]
|
||||
comments: true
|
||||
toc: true
|
||||
---
|
||||
|
||||
本中文版Markdown语法简介来自博客 <https://blog.shengbin.me/posts/markdown-syntax>
|
||||
|
||||
Markdown语法的完整介绍在这里:<http://daringfireball.net/projects/markdown/syntax>。下面整理的这些为了方便写博客时参考。
|
||||
|
||||
## 分段与分行
|
||||
|
||||
以一个或多个空行来隔开段落;以两个或多个空格来段内换行。
|
||||
|
||||
## 标题
|
||||
|
||||
```
|
||||
This is an H1
|
||||
=============
|
||||
|
||||
This is an H2
|
||||
-------------
|
||||
|
||||
# This is an H1
|
||||
|
||||
## This is an H2
|
||||
|
||||
###### This is an H6
|
||||
|
||||
```
|
||||
|
||||
## 引用
|
||||
|
||||
在每一行前面写一个`>`:
|
||||
|
||||
```
|
||||
> This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet,
|
||||
> consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
|
||||
> Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
|
||||
>
|
||||
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse
|
||||
> id sem consectetuer libero luctus adipiscing.
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
> This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
|
||||
>
|
||||
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing.
|
||||
|
||||
或者在每一段前面写一个`>`:
|
||||
|
||||
```
|
||||
> This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet,
|
||||
consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
|
||||
Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
|
||||
|
||||
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse
|
||||
id sem consectetuer libero luctus adipiscing.
|
||||
|
||||
```
|
||||
|
||||
## 多重引用
|
||||
|
||||
```
|
||||
> This is the first level of quoting.
|
||||
>
|
||||
> > This is nested blockquote.
|
||||
>
|
||||
> Back to the first level.
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
> This is the first level of quoting.
|
||||
>
|
||||
> > This is nested blockquote.
|
||||
>
|
||||
> Back to the first level.
|
||||
|
||||
## 列表
|
||||
|
||||
列表项占一行,以*、+、-开头即可:
|
||||
|
||||
```
|
||||
* Red
|
||||
* Green
|
||||
* Blue
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
- Red
|
||||
- Green
|
||||
- Blue
|
||||
|
||||
有序列表只需要将上述标记符换成数字加句点。而且顺序由书写顺序决定,与数字无关,但数字需要从1开始。例如:
|
||||
|
||||
```
|
||||
1\. Bird
|
||||
3. McHale
|
||||
2. Parish
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
1. Bird
|
||||
2. McHale
|
||||
3. Parish
|
||||
|
||||
每一个列表项可以多行:
|
||||
|
||||
```
|
||||
* Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
|
||||
Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi,
|
||||
viverra nec, fringilla in, laoreet vitae, risus.
|
||||
* Donec sit amet nisl. Aliquam semper ipsum sit amet velit.
|
||||
Suspendisse id sem consectetuer libero luctus adipiscing.
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
- Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
|
||||
- Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing.
|
||||
|
||||
## 代码块
|
||||
|
||||
每一行前面缩进四个或以上个空格,就认为是开始了一段代码块。代码块内原样输出。
|
||||
|
||||
```
|
||||
This is a normal paragraph:
|
||||
|
||||
This is a code block.
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
This is a normal paragraph:
|
||||
|
||||
```
|
||||
This is a code block.
|
||||
|
||||
```
|
||||
|
||||
## 横线
|
||||
|
||||
三个或更多个`*`、`-`(它们之间可以有空格)会产生横线:
|
||||
|
||||
```
|
||||
* * *
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
* * * * *
|
||||
|
||||
## 链接
|
||||
|
||||
内嵌链接:
|
||||
|
||||
```
|
||||
I get 10 times more traffic from [Google](http://google.com/ "Google")
|
||||
than from [Yahoo](http://search.yahoo.com/ "Yahoo Search") or
|
||||
[MSN](http://search.msn.com/ "MSN Search").
|
||||
|
||||
```
|
||||
|
||||
或参考文献式链接(缺省的链接标记认为与文本一致):
|
||||
|
||||
```
|
||||
I get 10 times more traffic from [Google] [1] than from
|
||||
[Yahoo] [2] or [MSN] [3].
|
||||
|
||||
[1]: http://google.com/ "Google"
|
||||
[2]: http://search.yahoo.com/ "Yahoo Search"
|
||||
[3]: http://search.msn.com/ "MSN Search"
|
||||
|
||||
I get 10 times more traffic from [Google][] than from
|
||||
[Yahoo][] or [MSN][].
|
||||
|
||||
[google]: http://google.com/ "Google"
|
||||
[yahoo]: http://search.yahoo.com/ "Yahoo Search"
|
||||
[msn]: http://search.msn.com/ "MSN Search"
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
I get 10 times more traffic from [Google](http://google.com/ "Google") than from [Yahoo](http://search.yahoo.com/ "Yahoo Search") or [MSN](http://search.msn.com/ "MSN Search").
|
||||
|
||||
如果直接以链接地址作为链接文本,可以用如下快捷写法:
|
||||
|
||||
```
|
||||
<http://www.shengbin.me> 效果:
|
||||
|
||||
```
|
||||
|
||||
[http://www.shengbin.me](http://www.shengbin.me/)
|
||||
|
||||
## 强调
|
||||
|
||||
单个`*`或`_`产生斜体,两个(`**`、`__`)则产生粗体。例如:
|
||||
|
||||
```
|
||||
*like* _this_
|
||||
|
||||
**like** **this**
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
*like* *this*
|
||||
|
||||
**like** **this**
|
||||
|
||||
## 内嵌代码
|
||||
|
||||
```
|
||||
code: `echo hello`
|
||||
|
||||
```
|
||||
|
||||
效果:
|
||||
|
||||
code: `echo hello`
|
||||
|
||||
## 图片
|
||||
|
||||
图片与链接类似,只需在文本前面加上感叹号`!`即可。图片位置和大小无法通过Markdown来指定。
|
||||
|
||||
## 转义字符
|
||||
|
||||
以下特殊字符需要用`\`转义得到。
|
||||
|
||||
```
|
||||
\ backslash
|
||||
` backtick
|
||||
* asterisk
|
||||
_ underscore
|
||||
{} curly braces
|
||||
[] square brackets
|
||||
() parentheses
|
||||
# hash mark
|
||||
+ plus sign
|
||||
- minus sign (hyphen)
|
||||
. dot
|
||||
! exclamation mark
|
||||
```
|
||||
@@ -1,43 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 为什么要用补码表示负数
|
||||
tags: 补码 computer
|
||||
categories: common
|
||||
---
|
||||
|
||||
抛开二进制不谈,我们先来看看10进制
|
||||
|
||||
假设世界上没有负号且数字最大只有3位,我们要把 `0~999` 分成两部分,一部分表示负数,一部分表示正数,而且不影响他们的运算规律,应当如何去做?
|
||||
|
||||
首先,最大的负数加上一等于零,那么用999表示最大的负数再合适不过,现在需要正负数各一半,那么正数部分应当为 `0 ~ 499`,负数部分应当为 `500~999`,我们暂时把这些表示负数的数字成为`对照数字`。
|
||||
|
||||
验证一下,`18 - 5 = 18 + 995 = 1013 = 13`
|
||||
|
||||
有没有一种计算方法可以方便地找出`-5`与`995`的关系呢?
|
||||
|
||||
有,那就是`999 - 5 + 1`
|
||||
|
||||
---
|
||||
|
||||
将这个规律推及到二进制中
|
||||
|
||||
假设二进制数只有8位,那么8个1代表最大的负数,将这些数分为正负各一半,那么正数部分应该为 `0 ~ 01111111`,负数部分应当为 `10000000 ~ 11111111`。
|
||||
|
||||
验证一下,`00010010 - 00000101 = 00010010 + 11111011 = 00001101`
|
||||
|
||||
与十进制同理,`-00000101`的对照数字可以用相同方法计算出来,`11111111 - 00000101 + 1`
|
||||
|
||||
等等,我们发现了一个特性,这真是一个神奇的特性!
|
||||
|
||||
`11111111 - 00000101` 等于`00000101` 按位取反!
|
||||
|
||||
现在,我们已经总结出了一点经验,在二进制中,负数的对照数字等于它的数值位按位取反再加一。
|
||||
|
||||
对于一个二进制负数来说,它是有符号的,因此他的第一位为符号位,剩余的为数值位,那么完整的表述就是负数的对照数字为`符号位不变,数值位按位取反再加一`,这个对照数字就是`补码`。
|
||||
|
||||
---
|
||||
|
||||
最后回答一下标题中的问题,显而易见,使用补码的好处就是,可以用加法来计算减法,从而简化电路设计。
|
||||
|
||||
|
||||
|
||||
@@ -1,135 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Java IO
|
||||
tags: Java IO
|
||||
categories: Java
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
![io][io]
|
||||
|
||||
# IO流的分类
|
||||
|
||||
根据处理数据类型的不同分为:字符流和字节流
|
||||
|
||||
根据数据流向不同分为:输入流和输出流
|
||||
|
||||
## 字符流和字节流
|
||||
|
||||
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。 字节流和字符流的区别:
|
||||
|
||||
* 读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
|
||||
|
||||
* 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
|
||||
|
||||
结论:只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
|
||||
|
||||
|
||||
## 输入流和输出流
|
||||
|
||||
对输入流只能进行读操作,对输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
|
||||
|
||||
# 字节流
|
||||
|
||||
## 输入
|
||||
|
||||
|
||||
* `InputStream` 是所有的输入字节流的父类,它是一个抽象类。
|
||||
|
||||
* `ByteArrayInputStream`、<br/>`StringBufferInputStream`、<br/>`FileInputStream` 是三种基本的介质流,它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。`PipedInputStream` 是从与其它线程共用的管道中读取数据
|
||||
|
||||
|
||||
* `ObjectInputStream` 和所有`FilterInputStream` 的子类都是装饰流(装饰器模式的主角)
|
||||
|
||||
## 输出
|
||||
|
||||
|
||||
* `OutputStream` 是所有的输出字节流的父类,它是一个抽象类。
|
||||
|
||||
* `ByteArrayOutputStream`、<br/>`FileOutputStream` 是两种基本的介质流,它们分别向Byte 数组、和本地文件中写入数据。`PipedOutputStream` 是向与其它线程共用的管道中写入数据,
|
||||
|
||||
* `ObjectOutputStream` 和所有`FilterOutputStream` 的子类都是装饰流。
|
||||
|
||||
## 配对
|
||||
|
||||
![io-match][io-match]
|
||||
|
||||
图中蓝色的为主要的对应部分,红色的部分就是不对应部分。紫色的虚线部分代表这些流一般要搭配使用。
|
||||
|
||||
|
||||
* `LineNumberInputStream` 主要完成从流中读取数据时,会得到相应的行号,至于什么时候分行、在哪里分行是由改类主动确定的,并不是在原始中有这样一个行号。在输出部分没有对应的部分,我们完全可以自己建立一个LineNumberOutputStream,在最初写入时会有一个基准的行号,以后每次遇到换行时会在下一行添加一个行号,看起来也是可以的。好像更不入流了。
|
||||
|
||||
* `PushbackInputStream` 的功能是查看最后一个字节,不满意就放回流中。主要用在编译器的语法、词法分析部分。输出部分的BufferedOutputStream 几乎实现相近的功能。(预读,可以将读取内容的一部分放回流的开头,下回重读)
|
||||
|
||||
* `StringBufferInputStream` 已经被Deprecated,本身就不应该出现在InputStream 部分,主要因为String 应该属于字符流的范围。已经被废弃了,当然输出部分也没有必要需要它了!还允许它存在只是为了保持版本的向下兼容而已。
|
||||
|
||||
* `SequenceInputStream` 可以认为是一个工具类,将两个或者多个输入流当成一个输入流依次读取。完全可以从IO 包中去除,还完全不影响IO 包的结构,却让其更“纯洁”――纯洁的Decorator 模式。
|
||||
|
||||
* `PrintStream` 也可以认为是一个辅助工具。主要可以向其他输出流,或者FileInputStream 写入数据,本身内部实现还是带缓冲的。本质上是对其它流的综合运用的一个工具而已。一样可以踢出IO 包!System.out 和System.out 就是PrintStream 的实例!
|
||||
|
||||
# 字符流
|
||||
|
||||
## 输入
|
||||
|
||||
|
||||
* `Reader` 是所有的输入字符流的父类,它是一个抽象类。
|
||||
|
||||
* `CharReader`、`StringReader` 是两种基本的介质流,它们分别将Char 数组、String中读取数据。`PipedReader`是从与其它线程共用的管道中读取数据。
|
||||
|
||||
* `BufferedReader` 很明显就是一个装饰器,它和其子类负责装饰其它Reader 对象。
|
||||
|
||||
* `FilterReader` 是所有自定义具体装饰流的父类,其子类PushbackReader 对Reader 对象进行装饰,会增加一个行号。
|
||||
|
||||
* `InputStreamReader` 是一个连接字节流和字符流的桥梁,它将字节流转变为字符流(`转换流`)。`FileReader` 可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream`转变为Reader 的方法。
|
||||
|
||||
## 输出
|
||||
|
||||
|
||||
* `Writer` 是所有的输出字符流的父类,它是一个抽象类。
|
||||
|
||||
* `CharArrayWriter`、`StringWriter` 是两种基本的介质流,它们分别向Char 数组、String 中写入数据。PipedWriter 是向与其它线程共用的管道中写入数据,
|
||||
|
||||
* `BufferedWriter` 是一个装饰器为Writer 提供缓冲功能。
|
||||
|
||||
* `PrintWriter` 和`PrintStream` 极其类似,功能和使用也非常相似。
|
||||
|
||||
* `OutputStreamWriter` 是OutputStream 到Writer 转换的桥梁(`转换流`),它的子类`FileWriter` 其实就是一个实现此功能的具体类。
|
||||
|
||||
## 配对
|
||||
|
||||
![io-match-2][io-match-2]
|
||||
|
||||
|
||||
# RandomAccessFile
|
||||
|
||||
该类并不是流体系中的一员,其封装了字节流,同时还封装了一个缓冲区(字符数组),通过内部的指针来操作字符数组中的数据。 该对象特点:
|
||||
|
||||
|
||||
* 该对象只能操作文件,所以构造函数接收两种类型的参数:a.字符串文件路径;b.File对象。
|
||||
|
||||
* 该对象既可以对文件进行读操作,也能进行写操作,在进行对象实例化时可指定操作模式(r,rw)
|
||||
|
||||
**注意**:该对象在实例化时,如果要操作的文件不存在,会自动创建;如果文件存在,写数据未指定位置,会从头开始写,即覆盖原有的内容。 可以用于多线程下载或多个线程同时写数据到文件。
|
||||
|
||||
|
||||
# 管道
|
||||
|
||||
Java的I/O库提供了一个称做链接(Chaining)的机制,可以将一个流处理器跟另一个流处理器首尾相接,以其中之一的输出为输入,形成一个 流管道的链接。
|
||||
|
||||
例如,`DataInputStream`流处理器可以把`FileInputStream`流对象的输出当作输入,将Byte类型的数据转换成Java的原始类型和String类型的数据。
|
||||
|
||||
# 设计模式
|
||||
|
||||
Java I/O库的两个设计模式:
|
||||
|
||||
|
||||
* `装饰者模式`:也叫**包装器模式**,在由InputStream,OutputStream,Reader和Writer代表的等级结构内部,有一些流处理器可以 对另一些流处理器起到装饰作用,形成新的,具有改善了的功能的流处理器。装饰者模式是Java I/O库的整体设计模式。
|
||||
|
||||
* `适配器模式`:在由InputStream,OutputStream,Reader和Writer代表的等级结构内部,有一些流处理器是对其它类型的流源的适配。
|
||||
|
||||
[io]: {{"/i0.jpg" | prepend: site.imgrepo }}
|
||||
[io-match]: {{"/io-match.jpg" | prepend: site.imgrepo }}
|
||||
[io-match-2]: {{"/io-match-2.jpg" | prepend: site.imgrepo }}
|
||||
@@ -1,138 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux打印
|
||||
tags: Linux 打印
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
# echo
|
||||
|
||||
echo是Shell的一个内部指令,用于在屏幕上打印出指定的字符串。
|
||||
|
||||
## 参数
|
||||
|
||||
`-n` 不要在最后自动换行
|
||||
|
||||
`-e` 若字符串中出现以下字符,则特别加以处理,而不会将它当成一般
|
||||
|
||||
文字输出:
|
||||
>` \a` 发出警告声;
|
||||
>
|
||||
>` \b` 删除前一个字符;
|
||||
>
|
||||
>` \c` 最后不加上换行符号;
|
||||
>
|
||||
>` \f` 换行但光标仍旧停留在原来的位置;
|
||||
>
|
||||
>` \n` 换行且光标移至行首;
|
||||
>
|
||||
>` \r` 光标移至行首,但不换行;
|
||||
>
|
||||
>` \t` 插入tab;
|
||||
>
|
||||
>` \v` 与\f相同;
|
||||
>
|
||||
>` \\` 插入\字符;
|
||||
>
|
||||
>` \nnn` 插入nnn(八进制)所代表的ASCII字符;
|
||||
|
||||
`–help` 显示帮助
|
||||
|
||||
`–version` 显示版本信息
|
||||
|
||||
## 原样输出字符串
|
||||
|
||||
若需要原样输出字符串(不进行转义),请使用单引号
|
||||
|
||||
echo '$name\"'
|
||||
|
||||
## 显示命令执行结果
|
||||
|
||||
echo `date`
|
||||
|
||||
# printf
|
||||
|
||||
printf 命令用于格式化输出, 是echo命令的增强版。它是C语言printf()库函数的一个有限的变形,并且在语法上有些不同。
|
||||
|
||||
注意:printf 由 POSIX 标准所定义,移植性要比 echo 好。
|
||||
|
||||
printf 不像 echo 那样会自动换行,必须显式添加换行符(\n)。
|
||||
|
||||
$printf "Hello, Shell\n"
|
||||
Hello, Shell
|
||||
$
|
||||
|
||||
printf 命令的语法
|
||||
|
||||
`printf format-string [arguments...]`
|
||||
|
||||
format-string 为格式控制字符串,arguments 为参数列表。
|
||||
|
||||
这里仅说明与C语言printf()函数的不同:
|
||||
|
||||
* printf 命令不用加括号
|
||||
|
||||
* format-string 可以没有引号,但最好加上,单引号双引号均可。
|
||||
|
||||
* 参数多于格式控制符(%)时,format-string 可以重用,可以将所有参数都转换。
|
||||
|
||||
* arguments 使用空格分隔,不用逗号。
|
||||
|
||||
注意,根据POSIX标准,浮点格式%e、%E、%f、%g与%G是“不需要被支持”。这是因为awk支持浮点预算,且有它自己的printf语句。这样Shell程序中需要将浮点数值进行格式化的打印时,可使用小型的awk程序实现。然而,内建于bash、ksh93和zsh中的printf命令都支持浮点格式。
|
||||
|
||||
## 参数
|
||||
|
||||
`--help`:在线帮助;
|
||||
|
||||
`--version`:显示版本信息。
|
||||
|
||||
## 格式替代符
|
||||
|
||||
`%b` 相对应的参数被视为含有要被处理的转义序列之字符串。
|
||||
|
||||
`%c` ASCII字符。显示相对应参数的第一个字符
|
||||
|
||||
`%d`, `%i` 十进制整数
|
||||
|
||||
`%e`, `%E`, `%f` 浮点格式
|
||||
|
||||
`%g` `%e`或`%f`转换,看哪一个较短,则删除结尾的零
|
||||
|
||||
`%G` `%E`或`%f`转换,看哪一个较短,则删除结尾的零
|
||||
|
||||
`%o` 不带正负号的八进制值
|
||||
|
||||
`%s` 字符串
|
||||
|
||||
`%u` 不带正负号的十进制值
|
||||
|
||||
`%x` 不带正负号的十六进制值,使用a至f表示10至15 %X 不带正负号的十六进制值,使用A至F表示10至15
|
||||
|
||||
`%%` 字面意义的%
|
||||
|
||||
## 转义
|
||||
|
||||
`\a` 警告字符,通常为ASCII的BEL字符
|
||||
|
||||
`\b` 后退
|
||||
|
||||
|
||||
`\c` 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略
|
||||
|
||||
`\f` 换页(formfeed)
|
||||
|
||||
`\n` 换行
|
||||
|
||||
`\r` 回车(Carriage return)
|
||||
|
||||
`\t` 水平制表符
|
||||
|
||||
`\v` 垂直制表符
|
||||
|
||||
`\\` 一个字面上的反斜杠字符
|
||||
|
||||
`\ddd` 表示1到3位数八进制值的字符,仅在格式字符串中有效 \0ddd 表示1到3位的八进制值字符
|
||||
@@ -1,267 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: VIM
|
||||
tags: VIM Linux
|
||||
categories: special
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
## 1.切换模式
|
||||
|
||||
`i` → Insert 模式,在光标前插入
|
||||
|
||||
`ESC` → 回到 Normal 模式,Normal 模式下,所有键都是功能键
|
||||
|
||||
`:help <command>` → 显示相关命令的帮助。你也可以就输入 :help 而不跟命令。(退出帮助需要输入:q)
|
||||
|
||||
## 2.存盘 & 退出
|
||||
|
||||
`:e file` → 打开一个文件
|
||||
|
||||
`:w` → 存盘
|
||||
|
||||
`:saveas file` → 另存为
|
||||
|
||||
`:x`, `ZZ` 或 `:wq` → 保存并退出 (:x 表示仅在需要时保存,ZZ不需要输入冒号并回车)
|
||||
|
||||
`:q!` → 退出不保存
|
||||
|
||||
`:qa!` 强行退出所有的正在编辑的文件,就算别的文件有更改。
|
||||
|
||||
`:bn` 和 `:bp` → 你可以同时打开很多文件,使用这两个命令来切换下一个或上一个文件。(`:n`到下一个文件)
|
||||
|
||||
## 3.插入
|
||||
|
||||
`a` → 在光标后插入
|
||||
|
||||
`o` → 在当前行后插入一个新行
|
||||
|
||||
`O` → 在当前行前插入一个新行
|
||||
|
||||
`cw` → 替换从光标所在位置后到一个单词结尾的字符
|
||||
|
||||
## 4.删除
|
||||
|
||||
`x` → 删当前光标所在的一个字符。
|
||||
|
||||
`dd` → 删除当前行,并把删除的行存到剪贴板里
|
||||
|
||||
`d` → 删除,常用于组合
|
||||
|
||||
## 5.拷贝 & 粘贴
|
||||
|
||||
`yy` → 拷贝当前行当行于 ddP
|
||||
|
||||
`p` → 粘贴(小写后)
|
||||
|
||||
`P` → 粘贴(大写前)
|
||||
|
||||
`y` → 拷贝,常用于组合
|
||||
|
||||
>vim有12个粘贴板,分别是`0 1 2 ... 9 a " +`用`:reg`命令可以查看各个粘贴板里的内容,在vim中简单用`y`只是复制到`"`粘贴板里,同样用`p`粘贴的也是这个粘贴板里的内容。
|
||||
>
|
||||
>* `"Ny` 指定`N`粘贴板复制(主意引号)
|
||||
>
|
||||
>* `+` 粘贴板是系统粘贴板,`"+y`复制,`"+p`粘贴
|
||||
|
||||
|
||||
## 6.定位
|
||||
|
||||
`hjkl` (←↓↑→)
|
||||
|
||||
### 6.1 行内定位
|
||||
|
||||
`0` → 数字零,到行头
|
||||
|
||||
`^` → 到本行第一个不是blank字符的位置(所谓blank字符就是空格,tab,换行,回车等)
|
||||
|
||||
`$` → 到本行行尾
|
||||
|
||||
`g_` → 到本行最后一个不是blank字符的位置。
|
||||
|
||||
`fa` → 到本行下一个为`a`的字符处
|
||||
|
||||
`Fa` → 到本行上一个为`a`的字符处
|
||||
|
||||
`ta` → 到`a`前的第一个字符
|
||||
|
||||
`Ta` → 到`a`后的第一个字符
|
||||
|
||||
### 6.2 行间定位
|
||||
|
||||
`NG` → 到第 `N` 行 (命令中的G是大写的)
|
||||
|
||||
`:N` → 到第 `N` 行
|
||||
|
||||
`gg` → 到第一行。(相当于1G,或 :1)
|
||||
|
||||
`G` → 到最后一行。
|
||||
|
||||
### 6.3 全文定位
|
||||
|
||||
`w` → 到下一个单词的开头。(默认单词形式)
|
||||
|
||||
`e` → 到当前单词的结尾。(默认单词形式)
|
||||
|
||||
`W` → 到下一个单词的开头。(包含空格`?`)
|
||||
|
||||
`E` → 到当前单词的结尾。(包含空格`?`)
|
||||
|
||||
`%` → 到匹配的括号处,包括 `( { [` (需要把光标先移到括号上)
|
||||
|
||||
`*` → 到`下一个`匹配单词
|
||||
|
||||
`# ` → 到`上一个`匹配单词
|
||||
|
||||
`/pattern` → 搜索 `pattern` 的字符串(需要回车,如果搜索出多个匹配,可按`n`键到下一个)
|
||||
|
||||
## 7.Undo & Redo
|
||||
|
||||
`u` → undo
|
||||
|
||||
`<Ctrl-r>`→ redo
|
||||
|
||||
## 8.重复
|
||||
|
||||
`.` → (小数点) 可以重复`上一次`的命令
|
||||
|
||||
`N <command>` → 重复某个命令`N次`,command可以为`.`
|
||||
|
||||
>使用`.`时,若上一次的命令为`N <command>`,则原样执行`N <command>`
|
||||
>
|
||||
>使用`N <command>`时,若`command`为`.`,则`N`会覆盖`.`自带的次数
|
||||
|
||||
## 9.组合
|
||||
|
||||
* `<start><command><end>`
|
||||
|
||||
>例如
|
||||
>
|
||||
>`0y$` → 从行头拷贝到行尾
|
||||
>
|
||||
>`ye` → 从当前位置拷贝到本单词的最后一个字符
|
||||
>
|
||||
>`y2/foo` → 拷贝2个foo之间的内容
|
||||
|
||||
## 10.区域选择
|
||||
|
||||
`<action>Na<object>` 包括object
|
||||
|
||||
`<action>Ni<object>` 不包括object
|
||||
|
||||
* `action` 可以是任何的命令,如 d (删除), y (拷贝), v (可以视模式选择)。
|
||||
|
||||
* `object` 可能是: `w` 一个单词, `W` 一个以空格为分隔的单词, `s` 一个句字, `p` 一个段落;也可以是成对出现的字符:`" ' ) } ]`
|
||||
|
||||
* `N` 表示选取第N层,不写默认为1
|
||||
|
||||
|
||||
## 11.自动提示
|
||||
|
||||
`<Ctrl-n>` 或 `<Ctrl-p>`
|
||||
|
||||
## 12.宏录制
|
||||
|
||||
`qa` → 把操作记录在寄存器 `a`
|
||||
|
||||
`q` → 停止录制
|
||||
|
||||
`@a` → replay`a`寄存器中的宏。
|
||||
|
||||
`@@` → replay最新录制的宏。
|
||||
|
||||
>示例:
|
||||
>
|
||||
>在一个只有一行且这一行只有“1”的文本中,键入如下命令:
|
||||
>
|
||||
>`qaYp<C-a>q`
|
||||
>
|
||||
>`qa` 开始录制
|
||||
>
|
||||
>`Yp` 复制行.
|
||||
>
|
||||
>`<Ctrl-a>` 增加1.
|
||||
>
|
||||
>`q` 停止录制.
|
||||
|
||||
这个宏的作用是:复制上一行并增加1
|
||||
|
||||
测试:
|
||||
|
||||
@a → 在1下面写下 2
|
||||
|
||||
@@ → 在2 正面写下3
|
||||
|
||||
现在做 100@@ 会创建新的100行,并把数据增加到 103.
|
||||
|
||||
## 13.可视化选择
|
||||
|
||||
`v` 可视
|
||||
|
||||
`V` 可视行
|
||||
|
||||
`<Ctrl-v>` 可视块
|
||||
|
||||
选择了可视化范围后,可做如下操作:
|
||||
|
||||
>* `J` → 把所有的行连接起来(变成一行)
|
||||
>
|
||||
>* `<` → 左缩进
|
||||
>
|
||||
>* `>` → 右缩进
|
||||
>
|
||||
>* `=` → 自动缩进
|
||||
|
||||
在所有被选择的行后加上点东西:
|
||||
|
||||
`<Ctrl-v>`
|
||||
|
||||
选中行
|
||||
|
||||
`$` 到行最后(不加将在每行行首编辑)
|
||||
|
||||
`A` 块操作中进入插入模式
|
||||
|
||||
输入
|
||||
|
||||
`ESC`
|
||||
|
||||
## 14.分屏
|
||||
|
||||
`split` → 创建分屏
|
||||
|
||||
`vsplit` → 创建垂直分屏
|
||||
|
||||
`<Ctrl-w>方向` → 方向可以是 hjkl 或 ←↓↑→,用来切换分屏。
|
||||
|
||||
`<Ctrl-w>_ ` → 最大化尺寸
|
||||
|
||||
`<Ctrl-w>|` → 垂直分屏最大化尺寸
|
||||
|
||||
`<Ctrl-w>+` → 增加尺寸
|
||||
|
||||
`<Ctrl-w>-` → 减小尺寸
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 其他
|
||||
|
||||
帮助文档 → `:help usr_02.txt`
|
||||
|
||||
gvim 启动设置(显示行号,配色,代码高亮):
|
||||
|
||||
>编辑安装目录下`_vimrc`文件
|
||||
>
|
||||
>添加如下代码
|
||||
>
|
||||
>set nu!
|
||||
>
|
||||
>colorscheme desert
|
||||
>
|
||||
>syntax enable
|
||||
>
|
||||
>syntax on
|
||||
@@ -1,405 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux目录与文件
|
||||
tags: Linux 命令
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
>`.`
|
||||
>
|
||||
>代表此层目录
|
||||
>
|
||||
>`..`
|
||||
>
|
||||
>代表上一层目录
|
||||
>
|
||||
>`-`
|
||||
>
|
||||
>代表前一个工作目录
|
||||
>
|
||||
>`~`
|
||||
>
|
||||
>代表『目前使用者身份』所在的家目录
|
||||
>
|
||||
>`~account`
|
||||
>
|
||||
>代表 account 这个使用者的家目录(account是个帐号名称)
|
||||
|
||||
---
|
||||
|
||||
## `cd `
|
||||
|
||||
**变换目录**
|
||||
|
||||
---
|
||||
|
||||
## `pwd`
|
||||
|
||||
**显示目前所在的目录**
|
||||
|
||||
[root@www ~]# `pwd [-Pl]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-P`:显示出真实的路径,而非使用连结 (link) 路径。
|
||||
|
||||
`-l ` : 显示逻辑路径(默认)
|
||||
|
||||
---
|
||||
|
||||
## `mkdir`
|
||||
|
||||
**创建新目录**
|
||||
|
||||
[root@www ~]# `mkdir [-mp]` 目录名称
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-m` :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~
|
||||
|
||||
`-p` :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
|
||||
|
||||
---
|
||||
|
||||
## `rmdir`
|
||||
|
||||
**删除『空』的目录**
|
||||
|
||||
[root@www ~]# `rmdir [-p]` 目录名称
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-p` :连同上一级『空的』目录也一起删除
|
||||
|
||||
---
|
||||
|
||||
## `$PATH`
|
||||
|
||||
**环境变量**
|
||||
|
||||
不同身份使用者默认的PATH不同,默认能够随意运行的命令也不同(如root与vbird);
|
||||
|
||||
PATH是可以修改的,所以一般使用者还是可以透过修改PATH来运行某些位於/sbin或/usr/sbin下的命令来查询;
|
||||
|
||||
使用绝对路径或相对路径直接指定某个命令的档名来运行,会比搜寻PATH来的正确;
|
||||
|
||||
命令应该要放置到正确的目录下,运行才会比较方便;本目录(.)最好不要放到PATH当中。
|
||||
|
||||
---
|
||||
|
||||
## `ls`
|
||||
|
||||
**查看文件与目录**
|
||||
|
||||
[root@linux ~]# `ls [-aAdfFhilRS]` 目录名称
|
||||
|
||||
[root@linux ~]# `ls [--color={none,auto,always}]` 目录名称
|
||||
|
||||
[root@linux ~]# `ls [--full-time]` 目录名称
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来~
|
||||
|
||||
`-A` :全部的档案,连同隐藏档,但不包括 . 与 .. 这两个目录,一起列出来~
|
||||
|
||||
`-d` :仅列出目录本身,而不是列出目录内的档案数据
|
||||
|
||||
`-f` :直接列出结果,而不进行排序 (ls 预设会以档名排序!)
|
||||
|
||||
`-F` :根据档案、目录等信息,给予附加数据结构
|
||||
|
||||
>例如: `*`:代表可执行档; `/`:代表目录; `=`:代表 socket 档案; `|`:代表 FIFO 档案
|
||||
|
||||
`-h` :将档案容量以人类较易读的方式(例如 GB, KB 等等)列出来
|
||||
|
||||
`-i` :列出 inode 位置,而非列出档案属性
|
||||
|
||||
`-l` :长数据串行出,包含档案的属性等等数据;
|
||||
|
||||
`-n` :列出 UID 与 GID 而非使用者与群组的名称
|
||||
|
||||
`-r` :将排序结果反向输出
|
||||
|
||||
`-R` :连同子目录内容一起列出来;
|
||||
|
||||
`-S` :以档案容量大小排序!
|
||||
|
||||
`-t` :依时间排序
|
||||
|
||||
`--color=never` :不要依据档案特性给予颜色显示;
|
||||
|
||||
`--color=always` :显示颜色
|
||||
|
||||
`--color=auto` :让系统自行依据设定来判断是否给予颜色
|
||||
|
||||
`--full-time` :以完整时间模式 (包含年、月、日、时、分) 输出
|
||||
|
||||
`--time={atime,ctime}` :输出 access 时间或 改变权限属性时间 (ctime) 而非内容变更时间 (modification time)
|
||||
|
||||
---
|
||||
|
||||
## `cp`
|
||||
|
||||
**复制文件或目录**
|
||||
|
||||
[root@www ~]# `cp [-adfilprsu]` 来源档(source) 目标档(destination)
|
||||
|
||||
[root@www ~]# `cp [options]` source1 source2 source3 .... directory
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a ` :相当於 -pdr 的意思,至於 pdr 请参考下列说明;(常用)
|
||||
|
||||
`-d` :若来源档为连结档的属性(link file),则复制连结档属性而非文件本身;
|
||||
|
||||
`-f` :为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
|
||||
|
||||
`-i` :若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
|
||||
|
||||
`-l` :进行硬式连结(hard link)的连结档创建,而非复制文件本身;
|
||||
|
||||
`-p` :连同文件的属性一起复制过去,而非使用默认属性(备份常用);
|
||||
|
||||
`-r` :递回持续复制,用於目录的复制行为;(常用)
|
||||
|
||||
`-s` :复制成为符号连结档 (symbolic link),亦即『捷径』文件;
|
||||
|
||||
`-u` :若 destination 比 source 旧才升级 destination !
|
||||
|
||||
最后需要注意的,如果来源档有两个以上,则最后一个目的档一定要是『目录』才行!
|
||||
|
||||
---
|
||||
|
||||
## `rm`
|
||||
|
||||
**移除文件或目录**
|
||||
|
||||
[root@www ~]# `rm [-fir]` 文件或目录
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-f` :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
|
||||
|
||||
`-i` :互动模式,在删除前会询问使用者是否动作
|
||||
|
||||
`-r` :递回删除啊!最常用在目录的删除了!这是非常危险的选项!!!
|
||||
|
||||
---
|
||||
|
||||
## `mv`
|
||||
|
||||
**移动文件与目录,或更名**
|
||||
|
||||
[root@www ~]# `mv [-fiu]` source destination
|
||||
|
||||
[root@www ~]# `mv [options]` source1 source2 source3 .... directory
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-f` :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
|
||||
|
||||
`-i` :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
|
||||
|
||||
`-u` :若目标文件已经存在,且 source 比较新,才会升级 (update)
|
||||
|
||||
---
|
||||
|
||||
## `basename`,`dirname`
|
||||
|
||||
**取得路径的文件名称与目录名称**
|
||||
|
||||
[root@www ~]# `basename` /etc/sysconfig/network
|
||||
|
||||
network <== 很简单!就取得最后的档名~
|
||||
|
||||
[root@www ~]# `dirname` /etc/sysconfig/network
|
||||
|
||||
/etc/sysconfig <== 取得的变成目录名了!
|
||||
|
||||
---
|
||||
|
||||
## `cat`
|
||||
|
||||
**查看文件**
|
||||
|
||||
[root@www ~]# `cat [-AbEnTv]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-A` :相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
|
||||
|
||||
`-b` :列出行号,仅针对非空白行做行号显示,空白行不标行号!
|
||||
|
||||
`-E` :将结尾的断行字节 $ 显示出来;
|
||||
|
||||
`-n` :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
|
||||
|
||||
`-T` :将 [tab] 按键以 ^I 显示出来;
|
||||
|
||||
`-v` :列出一些看不出来的特殊字符
|
||||
|
||||
## `tac`
|
||||
|
||||
**反向显示**
|
||||
|
||||
---
|
||||
|
||||
## `nl`
|
||||
|
||||
**添加行号显示**
|
||||
|
||||
[root@www ~]# `nl [-bnw]` 文件
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-b` :指定行号指定的方式,主要有两种:
|
||||
|
||||
> `-b a` :表示不论是否为空行,也同样列出行号(类似 cat -n);
|
||||
>
|
||||
> `-b t` :如果有空行,空的那一行不要列出行号(默认值);
|
||||
|
||||
|
||||
|
||||
`-n` :列出行号表示的方法,主要有三种:
|
||||
|
||||
> `-n ln` :行号在萤幕的最左方显示;
|
||||
>
|
||||
> `-n rn` :行号在自己栏位的最右方显示,且不加 0 ;
|
||||
>
|
||||
> `-n rz` :行号在自己栏位的最右方显示,且加 0 ;
|
||||
|
||||
|
||||
|
||||
`-w` :行号栏位的占用的位数。
|
||||
|
||||
---
|
||||
|
||||
## `more`
|
||||
|
||||
**一页一页翻动**
|
||||
|
||||
[root@www ~]# `more` /etc/man.config
|
||||
|
||||
在more查看文件时可在最底行输入:
|
||||
|
||||
空白键 (`space`):代表向下翻一页;
|
||||
|
||||
`Enter` :代表向下翻『一行』;
|
||||
|
||||
`/`字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字;
|
||||
|
||||
`:f` :立刻显示出档名以及目前显示的行数;
|
||||
|
||||
`q` :代表立刻离开 more ,不再显示该文件内容。
|
||||
|
||||
`b` 或 `[ctrl]-b` :代表往回翻页,不过这动作只对文件有用,对管线无用。
|
||||
|
||||
---
|
||||
|
||||
## `less`
|
||||
|
||||
**一页一页翻动**
|
||||
|
||||
[root@www ~]# `less` /etc/man.config
|
||||
|
||||
在more查看文件时可在最底行输入:
|
||||
|
||||
空白键(`space`) :向下翻动一页;
|
||||
|
||||
[`pagedown`]:向下翻动一页;
|
||||
|
||||
[`pageup`] :向上翻动一页;
|
||||
|
||||
`/`字串 :向下搜寻『字串』的功能;
|
||||
|
||||
`?`字串 :向上搜寻『字串』的功能;
|
||||
|
||||
`n` :重复前一个搜寻 (与 / 或 ? 有关!)
|
||||
|
||||
`N` :反向的重复前一个搜寻 (与 / 或 ? 有关!)
|
||||
|
||||
`q` :离开 less 这个程序;
|
||||
|
||||
---
|
||||
|
||||
## `head`
|
||||
|
||||
**取出前面几行**
|
||||
|
||||
[root@www ~]# `head [-n number]` 文件
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-n` :后面接数字,代表显示几行的意思
|
||||
|
||||
---
|
||||
|
||||
## `tail`
|
||||
|
||||
**取出后面几行**
|
||||
|
||||
[root@www ~]# `tail [-n number]` 文件
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-n` :后面接数字,代表显示几行的意思
|
||||
|
||||
`-f` :表示持续侦测后面所接的档名,要等到按下[ctrl]-c才会结束tail的侦测
|
||||
|
||||
---
|
||||
|
||||
## `od`
|
||||
|
||||
**非纯文字档**
|
||||
|
||||
[root@www ~]# `od [-t TYPE]` 文件
|
||||
|
||||
选项或参数:
|
||||
|
||||
`-t` :后面可以接各种『类型 (TYPE)』的输出,例如:
|
||||
|
||||
>`a` :利用默认的字节来输出;
|
||||
>
|
||||
>`c` :使用 ASCII 字节来输出
|
||||
>
|
||||
>`d`[size] :利用十进位(decimal)来输出数据,每个整数占用 size bytes
|
||||
>
|
||||
>`f`[size] :利用浮点数值(floating)来输出数据,每个数占用 size bytes
|
||||
>
|
||||
>`o`[size] :利用八进位(octal)来输出数据,每个整数占用 size bytes
|
||||
>
|
||||
>`x`[size] :利用十六进位(hexadecimal)来输出数据,每个整数占用 size bytes
|
||||
|
||||
---
|
||||
|
||||
## `touch`
|
||||
|
||||
**修改文件时间或建置新档**
|
||||
|
||||
[root@www ~]# `touch [-acdmt]` 文件
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :仅修订 access time;
|
||||
|
||||
`-c` :仅修改文件的时间,若该文件不存在则不创建新文件;
|
||||
|
||||
`-d` :后面可以接欲修订的日期而不用目前的日期,也可以使用 --date="日期或时间"
|
||||
|
||||
`-m` :仅修改 mtime ;
|
||||
|
||||
`-t` :后面可以接欲修订的时间而不用目前的时间,格式为[YYMMDDhhmm]
|
||||
|
||||
---
|
||||
|
||||
## `file`
|
||||
|
||||
**查看文件类型**
|
||||
|
||||
[root@www ~]# `file` 文件
|
||||
|
||||
@@ -1,185 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux权限管理
|
||||
tags: Linux 命令
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
## `chmod`
|
||||
|
||||
**改变权限**
|
||||
|
||||
*数字法*
|
||||
|
||||
root@www ~]# `chmod [-R] xyz` 文件或目录
|
||||
|
||||
选项与参数:
|
||||
|
||||
`xyz` : 就是刚刚提到的数字类型的权限属性,为 rwx 属性数值的相加。
|
||||
|
||||
`-R` : 进行递归(recursive)的持续变更,亦即连同次目录下的所有文件都会变更
|
||||
|
||||
*符号法*
|
||||
|
||||
chmod
|
||||
|
||||
ugoa
|
||||
|
||||
+(加入) -(除去) =(设定)
|
||||
|
||||
rwx
|
||||
|
||||
文件或目录
|
||||
|
||||
>例:
|
||||
>
|
||||
>[root@www ~]# chmod u=rwx,go=rx .bashrc
|
||||
>
|
||||
>\# 注意!那个 u=rwx,go=rx 是连在一起的,中间并没有任何空格!
|
||||
|
||||
---
|
||||
|
||||
## `chgrp `
|
||||
|
||||
|
||||
**改变所属群组**
|
||||
|
||||
chgrp [root@www ~]# `chgrp [-R] filename ...`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-R` : 进行递归(recursive)的持续变更,亦即连同次目录下的所有文件、目录 都更新成为这个群组之意。常常用在变更某一目录内所有的文件之情况。
|
||||
|
||||
---
|
||||
|
||||
## `chown`
|
||||
|
||||
**改变文件拥有者**
|
||||
|
||||
[root@www ~]# `chown [-R]` 账号名称 文件或目录
|
||||
|
||||
[root@www ~]# `chown [-R]` 账号名称:组名 文件或目录
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-R` : 进行递归(recursive)的持续变更,亦即连同次目录下的所有文件都变更
|
||||
|
||||
---
|
||||
|
||||
## `chattr`
|
||||
|
||||
**配置文件隐藏属性**
|
||||
|
||||
[root@www ~]# `chattr [+-=][ASacdistu]` 文件或目录名称
|
||||
|
||||
选项与参数:
|
||||
|
||||
`+` :添加某一个特殊参数,其他原本存在参数则不动。
|
||||
|
||||
`-` :移除某一个特殊参数,其他原本存在参数则不动。
|
||||
|
||||
`=` :配置一定,且仅有后面接的参数
|
||||
|
||||
>`A` :当配置了 A 这个属性时,若你有存取此文件(或目录)时,他的存取时间 atime将不会被修改,可避免I/O较慢的机器过度的存取磁碟。这对速度较慢的计算机有帮助。
|
||||
|
||||
`S` :一般文件是非同步写入磁碟的(原理请参考第五章sync的说明),如果加上 S 这个属性时,当你进行任何文件的修改,该更动会『同步』写入磁碟中。
|
||||
|
||||
`a` :当配置 a 之后,这个文件将只能添加数据,而不能删除也不能修改数据,只有root才能配置这个属性。
|
||||
|
||||
`c` :这个属性配置之后,将会自动的将此文件『压缩』,在读取的时候将会自动解压缩,但是在储存的时候,将会先进行压缩后再储存(看来对於大文件似乎蛮有用的!)
|
||||
|
||||
`d` :当 dump 程序被运行的时候,配置 d 属性将可使该文件(或目录)不会被 dump 备份
|
||||
|
||||
`i` :这个 i 可就很厉害了!他可以让一个文件『不能被删除、改名、配置连结也无法写入或新增数据!』对於系统安全性有相当大的助益!只有 root 能配置此属性
|
||||
|
||||
`s` :当文件配置了 s 属性时,如果这个文件被删除,他将会被完全的移除出这个硬盘空间,所以如果误删了,完全无法救回来了喔!
|
||||
|
||||
`u` :与 s 相反的,当使用 u 来配置文件时,如果该文件被删除了,则数据内容其实还存在磁碟中,可以使用来救援该文件喔!
|
||||
|
||||
注意:属性配置常见的是 a 与 i 的配置值,而且很多配置值必须要身为 root 才能配置
|
||||
|
||||
---
|
||||
|
||||
## `lsattr`
|
||||
|
||||
**显示文件隐藏属性**
|
||||
|
||||
[root@www ~]# `lsattr [-adR]` 文件或目录
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :将隐藏档的属性也秀出来;
|
||||
|
||||
`-d` :如果接的是目录,仅列出目录本身的属性而非目录内的档名;
|
||||
|
||||
`-R` :连同子目录的数据也一并列出来!
|
||||
|
||||
---
|
||||
|
||||
## `umask`
|
||||
|
||||
**被排除的权限默认值**
|
||||
|
||||
*目前使用者在创建文件或目录时候的被排除的权限默认值*
|
||||
|
||||
[root@www ~]# `umask` 显示`数字`型态的权限配置分数
|
||||
|
||||
0022 <==与一般权限有关的是后面三个数字,表示在777中被排除的权限,即该目录中新增文件或目录的默认权限为755,又因为新增文件默认不具有x权限,所以该目录中新增目录的默认权限为755,文件的默认权限为644
|
||||
|
||||
[root@www ~]# `umask -S` 以`符号`类型的方式来显示出权限
|
||||
|
||||
u=rwx,g=rx,o=rx
|
||||
|
||||
[root@www ~]# `umask 002` `指定`权限配置分数
|
||||
|
||||
`!` 异或运算可排除权限
|
||||
|
||||
---
|
||||
|
||||
## 文件特殊权限
|
||||
|
||||
**`SUID`**
|
||||
|
||||
>`1` SUID 权限仅对二进位程序(binary program)有效;(对目录无效)
|
||||
|
||||
>`2` 运行者对於该程序需要具有 x 权限;
|
||||
|
||||
>`3` 运行者将具有该程序拥有者 (owner) 的权限,该权限仅在运行该程序的过程中有效 (run-time)
|
||||
|
||||
>例如:/etc/shadow只有root能够访问,但是普通用户对于passwd有s权限,passwd的owner是root,所以普通用户可以在运行passwd时暂时获得root权限对/etc/shadow进行操作。
|
||||
|
||||
`!` SUID权限指的是文件权限中owner部分x权限的特殊版
|
||||
|
||||
`! chmod 4---` 可以赋予SUID权限,所属用户的x位将变成s, 若不具备x权限,s将变成S
|
||||
|
||||
**`SGID`**
|
||||
|
||||
*当为文件时*
|
||||
|
||||
>`1` SGID 仅对二进位程序有用;
|
||||
>
|
||||
>`2` 运行者对於该程序需具有x 权限;
|
||||
>
|
||||
>`3` 运行者在运行的过程中将会获得该程序群组(group)的权限,该权限仅在运行该程序的过程中有效 (run-time) --- 基本同SUID
|
||||
|
||||
*当为目录时*
|
||||
|
||||
>`1` 使用者若对於此目录具有 r 与 x 的权限时,该使用者能够进入此目录;
|
||||
>
|
||||
>`2` 使用者在此目录下的有效群组(effective group)将会变成该目录所属的群组;用途:若使用者在此目录下具有 w 的权限(可以新建文件),则使用者所创建的新文件的群组与此目录所属的群组相同。
|
||||
|
||||
`!` SGID权限指的是文件或目录权限中group部分x权限的特殊版
|
||||
`! chmod 2---` 可以赋予SGID权限,所属组的x位将变成s, 若不具备x权限,s将变成S
|
||||
|
||||
**`SBIT`**
|
||||
|
||||
·SBIT权限仅对目录有效;(对文件无效)
|
||||
|
||||
·使用者对於此目录需要具有 w, x 权限;
|
||||
|
||||
·当使用者在该目录下创建文件或目录时,仅有自己与 root 才有权力删除该文件
|
||||
|
||||
`! chmod 1---` 可以赋予SBIT权限,其他的x位将变成t
|
||||
@@ -1,545 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux进程管理
|
||||
tags: Linux 进程管理
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
## `&`
|
||||
|
||||
|
||||
**将命令放在后台运行**
|
||||
|
||||
command &
|
||||
|
||||
此时将会产生1个任务编号与一个PID,命令执行完成后将会在前台出现提示
|
||||
|
||||
>后台执行的任务如果存在信息输出,最好将其写入到文件,否则将会在前台显示,影响操作
|
||||
|
||||
---
|
||||
|
||||
## `[ctrl]-z`
|
||||
|
||||
**将命令放在后台暂停**
|
||||
|
||||
此时将会产生1个任务编号及其命令
|
||||
|
||||
---
|
||||
|
||||
## `jobs`
|
||||
|
||||
**查看后台任务状态**
|
||||
|
||||
[root@www ~]# `jobs [-lrs]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-l` :除了列出 job number 与命令串之外,同时列出 PID 的号码;
|
||||
|
||||
`-r` :仅列出正在背景 run 的工作;
|
||||
|
||||
`-s` :仅列出正在背景当中暂停 (stop) 的工作。
|
||||
|
||||
>`+` 代表最近被放到背景的工作号码, `-` 代表最近最后第二个被放置到背景中的工作号码,其余没有符号
|
||||
|
||||
---
|
||||
|
||||
## `fg`
|
||||
|
||||
**将后台任务放到前台**
|
||||
|
||||
[root@www ~]# `fg %jobnumber`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`%jobnumber` :jobnumber 为任务号码(数字),那个 % 是可有可无的!
|
||||
|
||||
---
|
||||
|
||||
## `bg`
|
||||
|
||||
**将后台暂停的任务变为运行中**
|
||||
|
||||
[root@www ~]# `bg %jobnumber`
|
||||
|
||||
---
|
||||
|
||||
## `kill`
|
||||
|
||||
**移除任务**
|
||||
|
||||
[root@www ~]# `kill -signal %jobnumber`
|
||||
|
||||
[root@www ~]# `kill -l`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-l` :这个是 L 的小写,列出目前 kill 能够使用的讯号 (signal) 有哪些
|
||||
|
||||
`signal` :代表给予后面接的那个工作什么样的指示罗!用 man 7 signal 可知:
|
||||
|
||||
> `-1` :重新读取一次参数的配置档 (类似 reload);
|
||||
>
|
||||
> `-2` :代表与由键盘输入 [ctrl]-c 同样的动作;
|
||||
>
|
||||
> `-9` :立刻强制删除一个工作;
|
||||
>
|
||||
> `-15`:以正常的程序方式终止一项工作。与 -9 是不一样的。
|
||||
|
||||
---
|
||||
|
||||
## `nohup`
|
||||
|
||||
**离线任务**
|
||||
|
||||
>`!特别说明` 前面的几个命令中所谓的"背景”,都是指终端机背景(不会被ctrl+c中断),并非系统背景,一旦退出终端,任务立即终止。`nohup`可以在退出终端后继续执行任务。
|
||||
|
||||
[root@www ~]# `nohup` [命令与参数] <==在终端机前台中工作
|
||||
|
||||
[root@www ~]# `nohup` [命令与参数] & <==在终端机后台中工作
|
||||
|
||||
---
|
||||
|
||||
## `pstree`
|
||||
|
||||
**显示进程树**
|
||||
|
||||
[root@www ~]# `pstree [-A|U] [-up]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-A` :各程序树之间的连接以 ASCII 字节来连接;
|
||||
|
||||
`-U` :各程序树之间的连接以万国码的字节来连接。在某些终端介面下可能会有错误;
|
||||
|
||||
`-p` :并同时列出每个 process 的 PID;
|
||||
|
||||
`-u` :并同时列出每个 process 的所属帐号名称。
|
||||
|
||||
---
|
||||
|
||||
## `ps`
|
||||
|
||||
**将某个时间点的程序运行情况撷取下来**
|
||||
|
||||
[root@www ~]# `ps aux` <==观察系统所有的程序数据
|
||||
|
||||
[root@www ~]# `ps -lA` <==也是能够观察所有系统的数据
|
||||
|
||||
[root@www ~]# `ps axjf` <==连同部分程序树状态
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-A` :所有的 process 均显示出来,与 -e 具有同样的效用;
|
||||
|
||||
`-a` :不与 terminal 有关的所有 process ;
|
||||
|
||||
`-u` :有效使用者 (effective user) 相关的 process ;
|
||||
|
||||
`x` :通常与 a 这个参数一起使用,可列出较完整资讯。
|
||||
|
||||
输出格式规划:
|
||||
|
||||
`l` :较长、较详细的将该 PID 的的资讯列出;
|
||||
|
||||
`j` :工作的格式 (jobs format)
|
||||
|
||||
`-f` :做一个更为完整的输出。
|
||||
|
||||
---
|
||||
|
||||
### `ps -l`
|
||||
|
||||
**仅观察自己的 bash 相关程序**
|
||||
|
||||
`F`:代表这个程序旗标 (process flags),说明这个程序的总结权限,常见号码有:
|
||||
|
||||
>若为 `4` 表示此程序的权限为 root ;
|
||||
>
|
||||
>若为 `1` 则表示此子程序仅进行复制(fork)而没有实际运行(exec)。
|
||||
|
||||
`S`:代表这个程序的状态 (STAT),主要的状态有:
|
||||
|
||||
>`R` (Running):该程序正在运行中;
|
||||
>
|
||||
>`S` (Sleep):该程序目前正在睡眠状态(idle),但可以被唤醒(signal)。
|
||||
>
|
||||
>`D` :不可被唤醒的睡眠状态,通常这支程序可能在等待 I/O 的情况(ex>列印)
|
||||
>
|
||||
>`T` :停止状态(stop),可能是在工作控制(背景暂停)或除错 (traced) 状态;
|
||||
>
|
||||
>`Z` (Zombie):僵尸状态,程序已经终止但却无法被移除至内存外。
|
||||
|
||||
`UID/PID/PPID`:代表此程序被该 UID 所拥有/程序的 PID 号码/此程序的父程序 PID 号码
|
||||
|
||||
`C`:代表 CPU 使用率,单位为百分比
|
||||
|
||||
`PRI/NI`:Priority/Nice 的缩写,代表此程序被 CPU 所运行的优先顺序,数值越小代表该程序越快被 CPU 运行
|
||||
|
||||
`ADDR/SZ/WCHAN`:都与内存有关,ADDR 是 kernel function,指出该程序在内存的哪个部分,如果是个 running 的程序,一般就会显示『 - 』 / SZ 代表此程序用掉多少内存 / WCHAN 表示目前程序是否运行中,同样的, 若为 - 表示正在运行中。
|
||||
|
||||
`TTY`:登陆者的终端机位置,若为远程登陆则使用动态终端介面 (pts/n);
|
||||
|
||||
`TIME`:使用掉的 CPU 时间,注意,是此程序实际花费 CPU 运行的时间,而不是系统时间;
|
||||
|
||||
`CMD`:就是 command 的缩写,造成此程序的触发程序之命令为何
|
||||
|
||||
---
|
||||
|
||||
### `ps aux`
|
||||
|
||||
**观察系统所有程序**
|
||||
|
||||
`USER`:该 process 属於那个使用者帐号的?
|
||||
|
||||
`PID` :该 process 的程序识别码。
|
||||
|
||||
`%CPU`:该 process 使用掉的 CPU 资源百分比;
|
||||
|
||||
`%MEM`:该 process 所占用的实体内存百分比;
|
||||
|
||||
`VSZ` :该 process 使用掉的虚拟内存量 (Kbytes)
|
||||
|
||||
`RSS` :该 process 占用的固定的内存量 (Kbytes)
|
||||
|
||||
`TTY` :该 process 是在那个终端机上面运行,若与终端机无关则显示 ?,另外, tty1-tty6 是本机上面的登陆者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。
|
||||
|
||||
`STAT`:该程序目前的状态,状态显示与 ps -l 的 S 旗标相同 (R/S/T/Z)
|
||||
|
||||
`START`:该 process 被触发启动的时间;
|
||||
|
||||
`TIME` :该 process 实际使用 CPU 运行的时间。
|
||||
|
||||
`COMMAND`:该程序的实际命令为何?
|
||||
|
||||
>ps结果后接 `<defunct>` 表示为僵尸程序
|
||||
|
||||
---
|
||||
|
||||
## `top`
|
||||
|
||||
**动态观察程序的变化**
|
||||
|
||||
[root@www ~]# `top [-d 数字] | top [-bnp]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-d` :后面可以接秒数,就是整个程序画面升级的秒数。默认是 5 秒;
|
||||
|
||||
`-b` :以批量的方式运行 top ,还有更多的参数可以使用,通常会搭配数据流重导向来将批量的结果输出成为文件。
|
||||
|
||||
`-n` :与 -b 搭配,意义是,需要进行几次 top 的输出结果。
|
||||
|
||||
`-p` :指定某些个 PID 来进行观察监测。
|
||||
|
||||
在 top 运行过程当中可以使用的按键命令:
|
||||
|
||||
`?` :显示在 top 当中可以输入的按键命令;
|
||||
|
||||
`P`:以 CPU 的使用资源排序显示;
|
||||
|
||||
`M` :以 Memory 的使用资源排序显示;
|
||||
|
||||
`N` :以 PID 来排序喔!
|
||||
|
||||
`T` :由该 Process 使用的 CPU 时间累积 (TIME+) 排序。
|
||||
|
||||
`k` :给予某个 PID 一个讯号 (signal)
|
||||
|
||||
`r` :给予某个 PID 重新制订一个 nice 值。
|
||||
|
||||
`q` :离开 top 软件的按键。
|
||||
|
||||
---
|
||||
|
||||
**`echo $$`** ( 查看bash的pid)
|
||||
|
||||
---
|
||||
|
||||
## `signal`
|
||||
|
||||
| 代号 | 名称 | 内容 |
|
||||
|:----:|:----:|:----|
|
||||
| 1 | SIGHUP | 启动被终止的程序,可让该 PID 重新读取配置,类似重新启动 |
|
||||
| 2 | SIGINT | 相当於用键盘输入 [ctrl]-c 来中断一个程序 |
|
||||
| 9 | SIGKILL | 强制中断一个程序,尚未完成的部分可能会有遗留物|
|
||||
| 15 | SIGTERM | 正常结束程序,如果该程序已经发生问题,signal将失效 |
|
||||
| 17 | SIGSTOP | 相当於用键盘输入 [ctrl]-z 来暂停一个程序 |
|
||||
|
||||
---
|
||||
|
||||
## `kill`
|
||||
|
||||
**杀死进程**
|
||||
|
||||
[root@www ~]# `kill PID`
|
||||
|
||||
`!特别说明`:kill后面直接加数字表示杀死进程,这与上面的移除任务用法是不同的
|
||||
|
||||
---
|
||||
|
||||
## `killall`
|
||||
|
||||
**按程序启动命令杀死进程**
|
||||
|
||||
[root@www ~]# ` killall [-iIe] [command name]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-i` :interactive 互动的意思,删除时,会出现提示
|
||||
|
||||
`-e` :exact 准确的意思,后面接的 command name要与运行中程序的启动命令一致,但整个完整的命令不能超过 15 个字节(若程序启动时使用了参数,则程序名与后面接的参数作为整体)
|
||||
|
||||
`-I` :命令名称(可能含参数)忽略大小写。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## `nice`
|
||||
|
||||
**指定nice值启动新程序**
|
||||
|
||||
[root@www ~]# `nice [-n 数字] command`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-n` :后面接一个数值,数值的范围 -20 ~ 19。
|
||||
|
||||
---
|
||||
|
||||
## `renice`
|
||||
|
||||
**重设指定程序的nice值**
|
||||
|
||||
[root@www ~]# `renice [number] PID`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`PID` :某个程序的 ID
|
||||
|
||||
---
|
||||
|
||||
## `free`
|
||||
|
||||
**观察内存使用情况**
|
||||
|
||||
[root@www ~]# `free [-b|-k|-m|-g] [-t]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
默认单位为 Kbytes,可以使用 `-b`(bytes),`-m`(Mbytes),`-k`(Kbytes),`-g`(Gbytes) 来显示单位
|
||||
|
||||
`-t` :显示实体内存与 swap 的总量。
|
||||
|
||||
---
|
||||
|
||||
## `uname`
|
||||
|
||||
**查看系统核心信息**
|
||||
|
||||
[root@www ~]# `uname [-asrmpi]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :所有系统相关的资讯,包括底下的数据都会被列出来;
|
||||
|
||||
`-s` :系统核心名称
|
||||
|
||||
`-r` :核心的版本
|
||||
|
||||
`-m` :本系统的硬件名称,例如 i686 或 x86_64 等;
|
||||
|
||||
`-p` :CPU 的类型,与 -m 类似,只是显示的是 CPU 的类型!
|
||||
|
||||
`-i` :硬件的平台 (ix86)
|
||||
|
||||
---
|
||||
|
||||
## `uptime`
|
||||
|
||||
**观察系统启动时间与工作负载**
|
||||
|
||||
|
||||
---
|
||||
|
||||
## `netstat`
|
||||
|
||||
**追踪网络与Socket**
|
||||
|
||||
[root@www ~]# `netstat -[atunlp]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :将目前系统上所有的连线、监听、Socket 数据都列出来
|
||||
|
||||
`-t` :列出 tcp 网络封包的数据
|
||||
|
||||
`-u` :列出 udp 网络封包的数据
|
||||
|
||||
`-n` :不以程序的服务名称,以端口号 (port number) 来显示;
|
||||
|
||||
`-l` :列出目前正在网络监听 (listen) 的服务;
|
||||
|
||||
`-p` :列出该网络服务的程序 PID
|
||||
|
||||
|
||||
网络参数
|
||||
|
||||
`Proto` :网络的封包协议,主要分为 TCP 与 UDP 封包,相关数据请参考服务器篇;
|
||||
|
||||
`Recv-Q`:非由使用者程序连结到此 socket 的复制的总 bytes 数;
|
||||
|
||||
`Send-Q`:非由远程主机传送过来的 acknowledged 总 bytes 数;
|
||||
|
||||
`Local Address` :本地端的 IP:port 情况
|
||||
|
||||
`Foreign Address`:远程主机的 IP:port 情况
|
||||
|
||||
`State` :连线状态,主要有创建(ESTABLISED)及监听(LISTEN);
|
||||
|
||||
本机程序
|
||||
|
||||
`Proto` :一般就是 unix 啦;
|
||||
|
||||
`RefCnt`:连接到此 socket 的程序数量;
|
||||
|
||||
`Flags` :连线的旗标;
|
||||
|
||||
`Type` :socket 存取的类型。主要有确认连线的 STREAM 与不需确认的 DGRAM 两种;
|
||||
|
||||
`State` :若为 CONNECTED 表示多个程序之间已经连线创建。
|
||||
|
||||
`Path` :连接到此 socket 的相关程序的路径!或者是相关数据输出的路径。
|
||||
|
||||
---
|
||||
|
||||
## `dmesg`
|
||||
|
||||
**查看核心产生的信息**
|
||||
|
||||
---
|
||||
|
||||
## `vmstat`
|
||||
|
||||
**侦测系统资源变化**
|
||||
|
||||
[root@www ~]# `vmstat [-a] [间隔时间] [总次数]]` <==CPU/内存等资讯
|
||||
|
||||
[root@www ~]# ` vmstat [-fs]` <==内存相关
|
||||
|
||||
[root@www ~]# `vmstat [-S 单位]` <==配置显示数据的单位
|
||||
|
||||
[root@www ~]# `vmstat [-d]` <==与磁碟有关
|
||||
|
||||
[root@www ~]# `vmstat [-p 分割槽]` <==与磁碟有关
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :使用 inactive/active(活跃与否) 取代 buffer/cache 的内存输出资讯;
|
||||
|
||||
`-f` :启动到目前为止,系统复制 (fork) 的程序数;
|
||||
|
||||
`-s` :将一些事件 (启动至目前为止) 导致的内存变化情况列表说明;
|
||||
|
||||
`-S` :后面可以接单位,让显示的数据有单位。例如 K/M 取代 bytes 的容量;
|
||||
|
||||
`-d` :列出磁碟的读写总量统计表
|
||||
|
||||
`-p` :后面列出分割槽,可显示该分割槽的读写总量统计表
|
||||
|
||||
>内存栏位 (`procs`) 的项目分别为:
|
||||
|
||||
>>`r` :等待运行中的程序数量;`b`:不可被唤醒的程序数量。这两个项目越多,代表系统越忙碌 (因为系统太忙,所以很多程序就无法被运行或一直在等待而无法被唤醒之故)。
|
||||
|
||||
>内存栏位 (`memory`) 项目分别为:
|
||||
|
||||
>>`swpd`:虚拟内存被使用的容量; `free`:未被使用的内存容量; `buff`:用於缓冲内存; `cache`:用於高速缓存。 这部份则与 `free` 是相同的。
|
||||
|
||||
>内存置换空间 (`swap`) 的项目分别为:
|
||||
|
||||
>>`si`:由磁碟中将程序取出的量; `so`:由於内存不足而将没用到的程序写入到磁碟的 `swap` 的容量。 如果 si/so 的数值太大,表示内存内的数据常常得在磁碟与主内存之间传来传去,系统效能会很差!
|
||||
|
||||
>磁碟读写 (`io`) 的项目分别为:
|
||||
|
||||
>>`bi`:由磁碟写入的区块数量; `bo`:写入到磁碟去的区块数量。如果这部份的值越高,代表系统的 I/O 非常忙碌!
|
||||
|
||||
>系统 (`system`) 的项目分别为:
|
||||
|
||||
>>`in`:每秒被中断的程序次数; `cs`:每秒钟进行的事件切换次数;这两个数值越大,代表系统与周边设备的沟通非常频繁! 这些周边设备当然包括磁碟、网络卡、时间钟等。
|
||||
|
||||
>`CPU` 的项目分别为:
|
||||
|
||||
>>`us`:非核心层的 CPU 使用状态; `sy`:核心层所使用的 CPU 状态; `id`:闲置的状态; `wa`:等待 I/O 所耗费的 CPU 状态; `st`:被虚拟机器 (virtual machine) 所盗用的 CPU 使用状态 (2.6.11 以后才支持)。
|
||||
|
||||
---
|
||||
|
||||
## `fuser`
|
||||
|
||||
**查看使用指定的文件或文件系统的进程**
|
||||
|
||||
[root@www ~]# `fuser [-umv] [-k [i] [-signal]]` file/dir
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-u` :除了程序的 PID 之外,同时列出该程序的拥有者;
|
||||
|
||||
`-m` :后面接的那个档名会主动的上提到该文件系统的最顶层,对 umount 不成功很有效!
|
||||
|
||||
`-v` :可以列出每个文件与程序还有命令的完整相关性!
|
||||
|
||||
`-k` :找出使用该文件/目录的 PID ,并试图以 SIGKILL 这个讯号给予该 PID;
|
||||
|
||||
`-i` :必须与 -k 配合,在删除 PID 之前会先询问使用者意愿!
|
||||
|
||||
`-signal`:例如 -1 -15 等等,若不加的话,默认是 SIGKILL (-9) 罗!
|
||||
|
||||
>权限:
|
||||
|
||||
`c` :此程序在当前的目录下(非次目录);
|
||||
|
||||
`e` :可被触发为运行状态;
|
||||
|
||||
`f` :是一个被开启的文件;
|
||||
|
||||
`r` :代表顶层目录 (root directory);
|
||||
|
||||
`F` :该文件被开启了,不过在等待回应中;
|
||||
|
||||
`m` :可能为分享的动态函式库;
|
||||
|
||||
---
|
||||
|
||||
## `lsof`
|
||||
|
||||
**列出由程序开启的文件**
|
||||
|
||||
[root@www ~]# `lsof [-aUu] [+d]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-a` :多项数据需要『同时成立』才显示出结果时!(内连接`?`)
|
||||
|
||||
`-U` :仅列出 Unix like 系统的 socket 文件类型;
|
||||
|
||||
`-u` :后面接 username,列出该使用者相关程序所开启的文件;
|
||||
|
||||
`+d` :后面接目录,即找出某个目录底下已经被开启的文件!
|
||||
|
||||
---
|
||||
|
||||
## `pidof`
|
||||
|
||||
**找出某个正在的运行程序的pid**
|
||||
|
||||
[root@www ~]# `pidof [-sx] program_name...`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-s` :仅列出一个 PID 而不列出所有的 PID
|
||||
|
||||
`-x` :同时列出该 program name 可能的 PPID 那个程序的 PID
|
||||
|
||||
@@ -1,147 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux启动流程
|
||||
tags: Linux boot
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||

|
||||
|
||||
# 1.加载内核
|
||||
|
||||
操作系统接管硬件以后,首先读入`/boot `目录下的内核文件。
|
||||
|
||||
# 2.启动初始化进程
|
||||
|
||||
内核文件加载以后,就开始运行第一个程序`/sbin/init`,它的作用是初始化系统环境。
|
||||
|
||||
# 3.确定运行级别
|
||||
|
||||
许多程序需要开机启动。它们在Windows叫做"服务"(service),在Linux就叫做"守护进程"(daemon)。
|
||||
|
||||
init进程的一大任务,就是去运行这些开机启动的程序。但是,不同的场合需要启动不同的程序,比如用作服务器时,需要启动Apache,用作桌面就不需要。Linux允许为不同的场合,分配不同的开机启动程序,这就叫做"`运行级别`"(runlevel)。也就是说,启动时根据"运行级别",确定要运行哪些程序。
|
||||
|
||||
Linux预置七种运行级别(0-6)。
|
||||
|
||||
* 0是关机,
|
||||
|
||||
* 1是单用户模式(也就是维护模式),
|
||||
|
||||
* 6是重启。
|
||||
|
||||
* 运行级别2-5,各个发行版不太一样,对于Debian来说,都是同样的多用户模式(也就是正常模式)。
|
||||
|
||||
init进程首先读取文件 /etc/inittab,它是运行级别的设置文件。第一行内容:
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
initdefault的值是2,表明系统启动时的运行级别为2。
|
||||
|
||||
每个运行级别在/etc目录下面,都有一个对应的子目录,指定要加载的程序。
|
||||
|
||||
/etc/rc0.d
|
||||
/etc/rc1.d
|
||||
/etc/rc2.d
|
||||
/etc/rc3.d
|
||||
/etc/rc4.d
|
||||
/etc/rc5.d
|
||||
/etc/rc6.d
|
||||
|
||||
"rc"表示run command(运行程序),"d"表示directory(目录) 。
|
||||
|
||||
/etc/rc2.d中指定的程序:
|
||||
|
||||
$ ls /etc/rc2.d
|
||||
README
|
||||
S01motd
|
||||
S13rpcbind
|
||||
S14nfs-common
|
||||
S16binfmt-support
|
||||
S16rsyslog
|
||||
S16sudo
|
||||
S17apache2
|
||||
S18acpid
|
||||
...
|
||||
|
||||
除了第一个文件README以外,其他文件名都是"字母S+两位数字+程序名"的形式。
|
||||
|
||||
* 字母`S`表示Start,也就是启动的意思(启动脚本的运行参数为start),如果这个位置是字母`K`,就代表Kill(关闭),即如果从其他运行级别切换过来,需要关闭的程序(启动脚本的运行参数为stop)。
|
||||
|
||||
* 后面的两位数字表示处理顺序,数字越小越早处理,所以第一个启动的程序是motd,然后是rpcbing、nfs......数字相同时,则按照程序名的字母顺序启动,所以rsyslog会先于sudo启动。
|
||||
|
||||
# 4.加载开机启动顺序
|
||||
|
||||
七种预设的"运行级别"各自有一个目录,存放需要开机启动的程序。如果多个"运行级别"需要启动同一个程序,那么这个程序的启动脚本,就会在每一个目录里都有一个拷贝。这样会造成管理上的困扰:如果要修改启动脚本,岂不是每个目录都要改一遍?
|
||||
|
||||
Linux的解决办法,就是七个 /etc/rcN.d 目录里列出的程序,都设为`链接文件`,指向另外一个目录 /etc/init.d ,真正的启动脚本都统一放在这个目录中。init进程逐一加载开机启动程序,其实就是运行这个目录里的启动脚本。
|
||||
|
||||
这样做的另一个好处,就是如果你要手动关闭或重启某个进程,直接到目录 /etc/init.d 中寻找启动脚本即可。
|
||||
|
||||
比如,我要重启Apache服务器,就运行下面的命令:
|
||||
|
||||
$ sudo /etc/init.d/apache2 restart
|
||||
|
||||
/etc/init.d 这个目录名最后一个字母d,是directory的意思,表示这是一个目录,用来与程序 /etc/init 区分。
|
||||
|
||||
# 5.用户登陆
|
||||
|
||||
用户的登录方式有三种:
|
||||
|
||||
* 命令行登录
|
||||
|
||||
init进程调用getty程序(意为get teletype),让用户输入用户名和密码。输入完成后,再调用login程序,核对密码(Debian还会再多运行一个身份核对程序/etc/pam.d/login)。如果密码正确,就从文件 /etc/passwd 读取该用户指定的shell,然后启动这个shell。
|
||||
|
||||
* ssh登录
|
||||
|
||||
系统调用sshd程序(Debian还会再运行/etc/pam.d/ssh ),取代getty和login,然后启动shell。
|
||||
|
||||
* 图形界面登录
|
||||
|
||||
init进程调用显示管理器,Gnome图形界面对应的显示管理器为gdm(GNOME Display Manager),然后用户输入用户名和密码。如果密码正确,就读取/etc/gdm3/Xsession,启动用户的会话。
|
||||
|
||||
# 6.进入 login shell
|
||||
|
||||
Debian默认的shell是Bash,它会读入一系列的配置文件,不同的登陆方式加载不同的配置文件
|
||||
|
||||
* 命令行登录:首先读入 /etc/profile,这是对所有用户都有效的配置;然后`依次`寻找下面三个文件,这是针对当前用户的配置。
|
||||
|
||||
~/.bash_profile
|
||||
~/.bash_login
|
||||
~/.profile
|
||||
|
||||
`*`需要注意的是,这三个文件只要有一个存在,就不再读入后面的文件了。
|
||||
|
||||
* ssh登录:与命令行登录完全相同。
|
||||
|
||||
* 图形界面登录:只加载 /etc/profile 和 ~/.profile。~/.bash_profile 不管有没有,都不会运行。
|
||||
|
||||
# 7.打开 non-login shell
|
||||
|
||||
进入 login shell完成后,Linux的启动过程就算结束了。
|
||||
|
||||
用户进入操作系统以后,常常会再手动开启一个shell。这个shell就叫做 non-login shell,意思是它不同于登录时出现的那个shell,不读取 /etc/profile 和 ~/.profile 等配置文件。
|
||||
|
||||
non-login shell 是用户最常接触的shell,它会读入用户自己的bash配置文件 ~/.bashrc。大多数时候,我们对于bash的定制,都是写在这个文件里面的。
|
||||
|
||||
`*` 如果不启动 non-login shell , ~/.bashrc 照样会运行,文件 ~/.profile 中存在下面的代码
|
||||
|
||||
~~~
|
||||
if [ -n "$BASH_VERSION" ]; then
|
||||
if [ -f "$HOME/.bashrc" ]; then
|
||||
. "$HOME/.bashrc"
|
||||
fi
|
||||
fi
|
||||
~~~
|
||||
|
||||
因此,只要运行~/.profile文件,~/.bashrc文件就会连带运行,但是如果存在~/.bash_profile文件,那么有可能不会运行~/.profile文件。解决办法是把下面代码写入 ~/.bash_profile,让 ~/.profile 始终能够运行。
|
||||
|
||||
|
||||
~~~
|
||||
if [ -f ~/.profile ]; then
|
||||
. ~/.profile
|
||||
fi
|
||||
~~~
|
||||
@@ -1,62 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: IP 类型
|
||||
tags: IP computer
|
||||
categories: network
|
||||
published: true
|
||||
---
|
||||
|
||||
|
||||
# 分类
|
||||
|
||||
![ip][ip]
|
||||
|
||||
IP通过地址开头判断类型,将以 `0`,`10`,`110` 开头的地址分为ABC三类
|
||||
|
||||
将ip转换成十进制后
|
||||
|
||||
A类地址第一个字节在 `0 - 127` 之间,
|
||||
|
||||
B类地址第一个字节在 `128 - 191` 之间
|
||||
|
||||
C类地址第一个字节在 `192 - 223` 之间
|
||||
|
||||
然后剩下的位被分为网络号与主机号,主机有两个特殊的值:
|
||||
|
||||
主机号全部为`0`的ip代表一个网段
|
||||
|
||||
主机号全部为`1`的ip代表广播地址,应用程序可以通过这个ip将信息发送到该网段下的所有主机
|
||||
|
||||
|
||||
|
||||
# 子网掩码
|
||||
|
||||
IP寻址时还需用到子网掩码,子网掩码与IP等长,由连续的1组成
|
||||
|
||||
ip中被子网掩码掩去(对ip进行与运算)的部分将被视为网络号,剩余部分将被视为主机号
|
||||
|
||||
如需要划分5个子网,其二进制为`101`,这将在ip中占去`3`位,3位可以划分出6(`2 ^ 3 - 2`)个子网满足5个子网的要求
|
||||
|
||||
一个byte中占去前3位后为`11100000`,该子网掩码十进制为`224`
|
||||
|
||||
|
||||
|
||||
# 私有地址
|
||||
|
||||
tcp/ip协议中,专门保留了三个IP地址区域作为私有地址,其地址范围如下:
|
||||
|
||||
10.0.0.0/8:10.0.0.0~10.255.255.255
|
||||
|
||||
172.16.0.0/12:172.16.0.0~172.31.255.255
|
||||
|
||||
192.168.0.0/16:192.168.0.0~192.168.255.255
|
||||
|
||||
ip后面的斜线和数字,表示ip的中网络号所占的位数
|
||||
|
||||
例如172.16.0.0/12表示将前12位全部作为网络号,效果等同于子网掩码 255.240.0.0
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[ip]: {{"/ip.jpg" | prepend: site.imgrepo }}
|
||||
@@ -1,24 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 防止重复提交的几种办法
|
||||
tags: resubmit
|
||||
categories: web
|
||||
published: true
|
||||
---
|
||||
|
||||
## 重定向
|
||||
提交操作完成后,将请求重定向到一个只读操作,此后无论客户端如何刷新页面,发送的都是只读操作的请求。
|
||||
|
||||
## 副作用
|
||||
页面初始化时生成随机码,提交操作后删除随机码,然后在服务端进行判断,如果请求中随机码为空,则认为重复提交。
|
||||
|
||||
## 令牌
|
||||
生成form页面之前在session中保存一个随机生成的token,并写入到form中的隐藏域。
|
||||
|
||||
然后在提交时进行判断:如果token与session中的相同,则为首次提交,此时删除session中的token,否则一律为非正常提交。
|
||||
|
||||
## UI
|
||||
提交后禁用提交按钮
|
||||
|
||||
## 数据库
|
||||
数据库添加约束,禁止重复数据
|
||||
@@ -1,92 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Tomcat Https 配置
|
||||
tags: tomcat Http Https ssl Java
|
||||
categories: Java
|
||||
published: false
|
||||
---
|
||||
|
||||
#### `1`.生成秘钥库
|
||||
|
||||
~~~bash
|
||||
keytool
|
||||
–genkey
|
||||
–keyalg 算法(通常用RSA)
|
||||
–dname "cn=服务器名,
|
||||
ou=组织单位名,
|
||||
o=组织名,
|
||||
l=城市名,
|
||||
st=省/市/自治区,
|
||||
c=国家双字母代码"
|
||||
-alias 别名(非必选项)
|
||||
-keypass 密码
|
||||
-keystore 秘钥库文件名
|
||||
-storepass 密码
|
||||
-validity 有效天数
|
||||
~~~
|
||||
|
||||
#### `2`.生成浏览器证书文件
|
||||
|
||||
~~~bash
|
||||
keytool
|
||||
-export
|
||||
-keystore 秘钥库文件名
|
||||
-alias 秘钥库别名(非必选项)
|
||||
-storepass 秘钥库密码
|
||||
-file 证书文件名
|
||||
~~~
|
||||
|
||||
#### `3`.生成私钥文件
|
||||
|
||||
~~~bash
|
||||
keytool
|
||||
-importkeystore
|
||||
-srckeystore 秘钥库文件名
|
||||
-deststoretype PKCS12
|
||||
-destkeystore p12文件名
|
||||
|
||||
openssl
|
||||
pkcs12
|
||||
-in p12文件名
|
||||
-out pem文件名
|
||||
-nodes
|
||||
~~~
|
||||
|
||||
#### `4`.Tomcat配置
|
||||
|
||||
打开 %CATALINA_HOME%/conf/server.xml
|
||||
|
||||
解开注释或添加代码(443为https默认端口,不会在URL中显示)
|
||||
|
||||
~~~bash
|
||||
<Connector port="443" protocol="HTTP/1.1" SSLEnabled="true"
|
||||
maxThreads="150" scheme="https" secure="true"
|
||||
clientAuth="false" sslProtocol="TLS"
|
||||
SSLCertificateFile="证书文件名"
|
||||
SSLCertificateKeyFile="pem文件名"/>
|
||||
~~~
|
||||
|
||||
#### `5`.强制https访问
|
||||
|
||||
打开 %CATALINA_HOME%/conf/web.xml
|
||||
|
||||
添加代码
|
||||
|
||||
~~~xml
|
||||
<!-- SSL -->
|
||||
<login-config>
|
||||
<!-- Authorization setting for SSL -->
|
||||
<auth-method>CLIENT-CERT</auth-method>
|
||||
<realm-name>Client Cert Users-only Area</realm-name>
|
||||
</login-config>
|
||||
<security-constraint>
|
||||
<!-- Authorization setting for SSL -->
|
||||
<web-resource-collection >
|
||||
<web-resource-name >SSL</web-resource-name>
|
||||
<url-pattern>/*</url-pattern>
|
||||
</web-resource-collection>
|
||||
<user-data-constraint>
|
||||
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
|
||||
</user-data-constraint>
|
||||
</security-constraint>
|
||||
~~~
|
||||
@@ -1,29 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 可重入锁
|
||||
tags: Java Concurrent Lock
|
||||
categories: Java
|
||||
---
|
||||
|
||||
Java 中的锁是可重入的,当线程试图获得它自己占有的锁时,请求会成功。
|
||||
|
||||
这样使用`synchronized`并不会造成死锁
|
||||
|
||||
~~~java
|
||||
public synchronized void test(){
|
||||
//do something
|
||||
synchronized(this) {
|
||||
//do something
|
||||
synchronized (this){
|
||||
//do something
|
||||
synchronized (this){
|
||||
//do something
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
这是因为java线程是基于 “每线程(per-thread)”,而不是基于“每调用的(per-invocation)” 的,也就是说java为每个线程分配一个锁,而不是为每次调用分配一个锁。
|
||||
|
||||
重入的实现是通过为每个锁关联一个请求计数和一个占有它的线程。当请求计数器为0时,这个锁可以被认为是未占用的,当一个线程请求一个未占用的锁时,JVM记录锁的拥有者,并把锁的请求计数加1,如果同一个线程再次请求这个锁时,请求计数器就会增加,当该线程退出`syncronized`块时,计数器减1,当计数器为0时,锁被释放。
|
||||
@@ -1,322 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 算法小汇
|
||||
tags: 三色旗 汉诺塔 斐波那契数列 骑士周游 算法 algorithm
|
||||
categories: algorithm
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
# 三色旗
|
||||
|
||||
问题描述:一条绳子上悬挂了一组旗帜,旗帜分为三种颜色,现在需要把旗帜按顺序将相同的颜色的放在一起,没有旗帜的临时存放点,只能在绳子上操作,每次只能交换两个旗帜
|
||||
|
||||
例如:原本旗帜的顺序为`rwbrbwwrbwbrbwrbrw`需要变成`bbbbbbwwwwwwrrrrrr`
|
||||
|
||||
解决思路:遍历元素,如果元素该放到左边就与左边交换,该放到右边就与右边交换,左右边界动态调整,剩余的正好属于中间
|
||||
|
||||
~~~java
|
||||
public class Tricolour {
|
||||
|
||||
private final static String leftColor = "b";
|
||||
private final static String rightColor = "r";
|
||||
|
||||
public void tricolour(Object[] src){
|
||||
//中间区域的左端点
|
||||
int mli = 0;
|
||||
//中间区域的右端点
|
||||
int mri = src.length-1;
|
||||
//遍历元素,从mli开始到mri结束,mli与mri会动态调整,但是i比mli变化快
|
||||
for (int i = mli; i <= mri; i++) {
|
||||
//如果当前元素属于左边
|
||||
if(isPartOfLeft(src[i])){
|
||||
//将当前元素换与中间区域左端点元素互换
|
||||
swap(src,mli,i);
|
||||
//mli位的元素是经过处理的,一定不是红色,所以不需要再分析i位新元素
|
||||
//左端点右移
|
||||
mli++;
|
||||
}
|
||||
//如果当前元素属于右边
|
||||
else if(isPartOfRight(src[i])){
|
||||
//从中间区域的右端点开始向左扫描元素
|
||||
while (mri > i) {
|
||||
//如果扫描到的元素属于右边,右端点左移,继续向左扫描,否则停止扫描
|
||||
if(isPartOfRight(src[mri])){
|
||||
mri--;
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
}
|
||||
//将当前元素交换到中间区域右端点
|
||||
swap(src,mri,i);
|
||||
//右端点左移
|
||||
mri--;
|
||||
//mri位的元素可能是蓝色的,需要再分析i位新元素
|
||||
i--;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
private boolean isPartOfLeft(Object item){
|
||||
return leftColor.equals(item);
|
||||
}
|
||||
|
||||
private boolean isPartOfRight(Object item){
|
||||
return rightColor.equals(item);
|
||||
}
|
||||
|
||||
private void swap(Object[] src, int fst, int snd){
|
||||
Object tmp = src[fst];
|
||||
src[fst] = src[snd];
|
||||
src[snd] = tmp;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
String[] flags =
|
||||
new String[]{"r","b","w","w","b","r","r","w","b","b","r","w","b"};
|
||||
new Tricolour().tricolour(flags);
|
||||
for (String flag : flags) {
|
||||
System.out.printf("%s,",flag);
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# 汉诺塔
|
||||
|
||||
~~~java
|
||||
public class Hanoi {
|
||||
|
||||
private void move(int n, char a, char b, char c){
|
||||
if(n == 1){
|
||||
System.out.printf("盘%d由%s移动到%s\n",n,a,c);
|
||||
} else{
|
||||
move(n-1,a,c,b);
|
||||
System.out.printf("盘%d由%s移动到%s\n",n,a,c);
|
||||
move(n-1,b,a,c);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
new Hanoi().move(5, 'A','B','C');
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# 斐波那契数列
|
||||
|
||||
~~~java
|
||||
public class Fibonacci {
|
||||
|
||||
private int[] src ;
|
||||
|
||||
public int fibonacci(int n){
|
||||
if(src == null){
|
||||
src = new int[n+1];
|
||||
}
|
||||
if(n == 0 || n==1){
|
||||
src[n] = n;
|
||||
return n;
|
||||
}
|
||||
src[n] = fibonacci(n-1) + fibonacci(n-2);
|
||||
return src[n];
|
||||
}
|
||||
|
||||
public int fibonacci2(int n){
|
||||
if(src == null){
|
||||
src = new int[n+1];
|
||||
}
|
||||
src[0] = 0;
|
||||
src[1] = 1;
|
||||
for (int i = 2; i < src.length; i++) {
|
||||
src[i] = src[i-1] + src[i-2];
|
||||
}
|
||||
return src[n];
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Fibonacci fib = new Fibonacci();
|
||||
int n = fib.fibonacci(20);
|
||||
System.out.println(n);
|
||||
for (int i : fib.src) {
|
||||
System.out.println(i);
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# 骑士周游
|
||||
|
||||
骑士只能按照如图所示的方法前进,且每个格子只能路过一次,现在指定一个起点,判断骑士能否走完整个棋盘.
|
||||
|
||||
思路:对任意一个骑士所在的位置,找出其所有可用的出口,若无可用出口则周游失败,再对每个出口找出其可用的子出口,然后骑士移动至子出口最少的出口处,重复以上过程.
|
||||
|
||||

|
||||
|
||||
~~~java
|
||||
import java.awt.Point;
|
||||
import static java.lang.System.out;
|
||||
|
||||
public class KnightTour {
|
||||
|
||||
// 对应骑士可走的八個方向
|
||||
private final static Point[] relatives = new Point[]{
|
||||
new Point(-2,1),
|
||||
new Point(-1,2),
|
||||
new Point(1,2),
|
||||
new Point(2,1),
|
||||
new Point(2,-1),
|
||||
new Point(1,-2),
|
||||
new Point(-1,-2),
|
||||
new Point(-2,-1)
|
||||
};
|
||||
|
||||
private final static int direct = 8;
|
||||
|
||||
public KnightTour(int sideLen){
|
||||
this.sideLen = sideLen;
|
||||
board = new int[sideLen][sideLen];
|
||||
}
|
||||
|
||||
private int sideLen;
|
||||
|
||||
private int[][] board;
|
||||
|
||||
public boolean travel(int startX, int startY) {
|
||||
|
||||
// 当前出口的位置集
|
||||
Point[] nexts;
|
||||
|
||||
// 记录每个出口的可用出口个数
|
||||
int[] exits;
|
||||
|
||||
//当前位置
|
||||
Point current = new Point(startX, startY);
|
||||
|
||||
board[current.x][current.y] = 1;
|
||||
|
||||
//当前步的编号
|
||||
for(int m = 2; m <= Math.pow(board.length, 2); m++) {
|
||||
|
||||
//清空每个出口的可用出口数
|
||||
nexts = new Point[direct];
|
||||
exits = new int[direct];
|
||||
|
||||
int count = 0;
|
||||
// 试探八个方向
|
||||
for(int k = 0; k < direct; k++) {
|
||||
int tmpX = current.x + relatives[k].x;
|
||||
int tmpY = current.y + relatives[k].y;
|
||||
|
||||
// 如果这个方向可走,记录下来
|
||||
if(accessable(tmpX, tmpY)) {
|
||||
nexts[count] = new Point(tmpX,tmpY);
|
||||
// 可走的方向加一個
|
||||
count++;
|
||||
}
|
||||
}
|
||||
|
||||
//可用出口数最少的出口在exits中的索引
|
||||
int minI = 0;
|
||||
if(count == 0) {
|
||||
return false;
|
||||
} else {
|
||||
// 记录每个出口的可用出口数
|
||||
for(int l = 0; l < count; l++) {
|
||||
for(int k = 0; k < direct; k++) {
|
||||
int tmpX = nexts[l].x + relatives[k].x;
|
||||
int tmpY = nexts[l].y + relatives[k].y;
|
||||
if(accessable(tmpX, tmpY)){
|
||||
exits[l]++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 从可走的方向中寻找最少出路的方向
|
||||
int tmp = exits[0];
|
||||
for(int l = 1; l < count; l++) {
|
||||
if(exits[l] < tmp) {
|
||||
tmp = exits[l];
|
||||
minI = l;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 走最少出路的方向
|
||||
current = new Point(nexts[minI]);
|
||||
board[current.x][current.y] = m;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
private boolean accessable(int x, int y){
|
||||
return x >= 0 && y >= 0 && x < sideLen && y < sideLen && board[x][y] == 0;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
int sideLen = 9;
|
||||
KnightTour knight = new KnightTour(sideLen);
|
||||
|
||||
if(knight.travel(4,2)) {
|
||||
out.println("游历完成!");
|
||||
} else {
|
||||
out.println("游历失败!");
|
||||
}
|
||||
|
||||
for(int y = 0; y < sideLen; y++) {
|
||||
for(int x = 0; x < sideLen; x++) {
|
||||
out.printf("%3d ", knight.board[x][y]);
|
||||
}
|
||||
out.println();
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# 帕斯卡三角
|
||||
|
||||
~~~java
|
||||
public class Pascal extends JFrame{
|
||||
|
||||
private final int maxRow;
|
||||
|
||||
Pascal(int maxRow){
|
||||
setBackground(Color.white);
|
||||
setTitle("帕斯卡三角");
|
||||
setSize(520, 350);
|
||||
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
|
||||
setVisible(true);
|
||||
this.maxRow = maxRow;
|
||||
}
|
||||
|
||||
/**
|
||||
* 获取值
|
||||
* @param row 行号 从0开始
|
||||
* @param col 列号 从0开始
|
||||
* @return
|
||||
*/
|
||||
private int value(int row,int col){
|
||||
int v = 1;
|
||||
for (int i = 1; i < col; i++) {
|
||||
v = v * (row - i + 1) / i;
|
||||
}
|
||||
return v;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void paint(Graphics g) {
|
||||
int r, c;
|
||||
for(r = 0; r <= maxRow; r++) {
|
||||
for(c = 0; c <= r; c++){
|
||||
g.drawString(String.valueOf(value(r, c)), (maxRow - r) * 20 + c * 40, r * 20 + 50);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
new Pascal(12);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
@@ -1,246 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Custom Fileupload
|
||||
tags: fileupload Java Http
|
||||
categories: web
|
||||
published: true
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
本文的目的是简要说明如何编写一个文件上传组件,使他的功能类似 [commons-fileupload][commons-fileupload], 并在结尾处提供了完整代码的获取方式。
|
||||
|
||||
# HTTP
|
||||
本文讨论的是基于 HTTP 协议的文件上传,下面先来看看 HTTP 请求的真面目。
|
||||
|
||||
首先,用 JavaSe 类库中的 Socket 搭建一个超简单的服务器,这个服务器只有一个功能,就是完整地打印整个 HTTP 请求体。
|
||||
|
||||
~~~java
|
||||
public class Server {
|
||||
|
||||
private ServerSocket serverSocket;
|
||||
|
||||
public Server() throws IOException{
|
||||
serverSocket = new ServerSocket(8080);
|
||||
}
|
||||
|
||||
public void show() throws IOException{
|
||||
while(true){
|
||||
Socket socket = serverSocket.accept();
|
||||
byte[] buf = new byte[1024];
|
||||
InputStream is = socket.getInputStream();
|
||||
OutputStream os = new ByteArrayOutputStream();
|
||||
int n = 0;
|
||||
while ((n = is.read(buf)) > -1){
|
||||
os.write(buf,0,n);
|
||||
}
|
||||
os.close();
|
||||
is.close();
|
||||
socket.close();
|
||||
|
||||
System.out.println(os);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
new Server().show();
|
||||
}
|
||||
|
||||
}
|
||||
~~~
|
||||
|
||||
将服务器运行起来之后,在浏览器中输入地址:`http://localhost:8080`
|
||||
|
||||
在我的机器上,显示如下内容,可以看到,这个一个get请求
|
||||
|
||||
![http-get][http-get]
|
||||
|
||||
下面利用一个 html 的 form表单提交 post 请求
|
||||
|
||||
~~~html
|
||||
<form action="http://localhost:8080" method="post" enctype="multipart/form-data">
|
||||
<input type="text" name="time" value="1970-01-01"/>
|
||||
<input type="file" name="file"/>
|
||||
<input type="submit"/>
|
||||
</form>
|
||||
~~~
|
||||
|
||||
在我的机器上,显示如下内容
|
||||
|
||||
![http-post][http-post]
|
||||
|
||||
注意图中被红色框起来的部分,第一个红框指示了本次请求中,用来分隔不同元素的分隔线。
|
||||
|
||||
每个元素将以此分隔线作为第一行,后面紧跟对元素的描述,描述与内容用空行分隔。
|
||||
|
||||
分隔线的后面加两个小短横代表整个请求体结束,即**EOF**。
|
||||
|
||||
我们需要做的工作,就是利用分隔线,从请求体中分离出每个元素,分析HTTP请求头的工作可以交给Servlet。
|
||||
|
||||
# 分析
|
||||
|
||||
那么,如何分离呢?
|
||||
|
||||
java中的 `InputStream` 只能读取一次,所以我们想要方便地分析一个流,最直接的办法就是将其缓存下来。
|
||||
|
||||
RandomAccessFile 或许能够满足需求,RandomAccessFile 可以提供一个指针用于在文件中的随意移动,然而需要读写本地文件的方案不会是最优方案。
|
||||
|
||||
先将整个流读一遍将内容缓存到内存中? 这种方案在多个客户端同时提交大文件时一定是不可靠的。
|
||||
|
||||
最理想的方案可能是,我只需要读一遍 `InputStream` , 读完后将得到一个有序列表,列表中存放每个元素对象。
|
||||
|
||||
很明显,JavaSe的流没有提供这个功能
|
||||
|
||||
我们知道从 `InputStreeam` 中获取内容需要使用 `read` 方法,返回 `-1` 表示读到了流的末尾,如果我们增强一下`read`的功能,让其在读到每个元素末尾的时候返回 `-1`,这样不就可以分离出每个元素了吗,至于判断是否到了整个流的末尾,自有办法。
|
||||
|
||||
|
||||
# 设计
|
||||
|
||||
如何增强`read`方法呢?
|
||||
|
||||
`read`方法要在读到元素末尾时返回`-1` , 一定需要先对已读取的内容进行分析,判断是否元素末尾。
|
||||
|
||||
我的做法是,内部维护一个buffer,`read`方法在读取时先将字节写入到这个buffer中,然后分析其中是否存在分隔线,然后将buffer中可用的元素复制到客户端提供的buffer。
|
||||
|
||||
这个内部维护的buffer并不总是满的,其中的字节来自read方法的原始功能,所以我们需要一个变量来记录buffer中有效字节的末尾位置 `tail`。
|
||||
|
||||
我们还需要一个变量 `pos` 来标记buffer中是否存在分隔线,pos的值即为分隔线的开头在buffer中的位置,如果buffer中不存在分隔线pos的值将为-1。
|
||||
|
||||
但是问题没这个简单,分隔线在buffer中存在状态有两种情况:
|
||||
|
||||
情况A,分隔线完好地存在于buffer中,图中的bundary即为分隔线
|
||||
|
||||
![boundary-A][boundary-A]
|
||||
|
||||
情况B,分隔线的一部分存在于buffer中
|
||||
|
||||
![boundary-B][boundary-B]
|
||||
|
||||
在B情况下,`boundary`有多少字节存在于buffer中是不确定的,而且依靠这些不完整的字节根本无法判断他是否属于boundary开头。
|
||||
|
||||
例如,buffer中没有发现boundary,但是buffer末尾的3个字节与boundary开头相同,这种情况可能只是巧合,boundary并没有被截断。
|
||||
|
||||
对于这个问题,有一个解决办法,我们不必检查到buffer末尾,而是在buffer末尾留一个关健区`pad`。
|
||||
|
||||
这个关健区中很有可能存在被截断boundary,每次检查到`pad`开头时立即收手,此位置之前的数据可以确保没有boundary,在下次填充buffer时,将这个关健区中的数据复制到buffer开头再处理。很显然,关健区`pad`长度应该等于boundary,如图:
|
||||
|
||||
![pad][pad]
|
||||
|
||||
# 关键代码
|
||||
|
||||
**在buffer中检查boundary**
|
||||
|
||||
~~~java
|
||||
private int findSeparator() {
|
||||
int first;
|
||||
int match = 0;
|
||||
//若buffer中head至tail之间的字节数小于boundaryLength,那么maxpos将小于head,循环将不会运行,返回值为-1
|
||||
int maxpos = tail - boundaryLength;
|
||||
for (first = head; first <= maxpos && match != boundaryLength; first++) {
|
||||
first = findByte(boundary[0], first);
|
||||
if (first == -1 || first > maxpos) {
|
||||
return -1;
|
||||
}
|
||||
for (match = 1; match < boundaryLength; match++) {
|
||||
if (buffer[first + match] != boundary[match]) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (match == boundaryLength) {
|
||||
return first - 1;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
~~~
|
||||
|
||||
|
||||
**填充buffer**
|
||||
|
||||
~~~java
|
||||
private int makeAvailable() throws IOException {
|
||||
//该方法在available返回0时才会被调用,若pos!=-1那pos==head,表示boundary处于head位,可用字节数为0
|
||||
if (pos != -1) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 将pad位之后的数据移动到buffer开头
|
||||
total += tail - head - pad;
|
||||
System.arraycopy(buffer, tail - pad, buffer, 0, pad);
|
||||
|
||||
// 将buffer填满
|
||||
head = 0;
|
||||
tail = pad;
|
||||
//循环读取数据,直至将buffer填满,在此过程中,每次读取都将检索buffer中是否存在boundary,无论存在与否,都将即时返回可用数据量
|
||||
for (;;) {
|
||||
int bytesRead = input.read(buffer, tail, bufSize - tail);
|
||||
if (bytesRead == -1) {
|
||||
//理论上因为会对buffer不断进行检索,读到boundary时就会return 0,read方法将返回 -1,
|
||||
//所以不会读到input末尾,如果运行到了这里,表示发生了错误.
|
||||
final String msg = "Stream ended unexpectedly";
|
||||
throw new RuntimeException(msg);
|
||||
}
|
||||
if (notifier != null) {
|
||||
notifier.noteBytesRead(bytesRead);
|
||||
}
|
||||
tail += bytesRead;
|
||||
findSeparator();
|
||||
//若buffer中的数据量小于keepRegion(boundaryLength),av将必定等于0,循环将继续,直至数据量大于或等于keepRegion(boundaryLength).
|
||||
//此时将检索buffer中是否包含boundary,若包含,将返回boundary所在位置pos之前的数据量,若不包含,将返回pad位之前的数据量
|
||||
int av = available();
|
||||
|
||||
if (av > 0 || pos != -1) {
|
||||
return av;
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
**强化后的read方法**
|
||||
|
||||
~~~java
|
||||
@Override
|
||||
public int read(byte[] b, int off, int len) throws IOException {
|
||||
if (closed) {
|
||||
throw new RuntimeException("the stream is closed");
|
||||
}
|
||||
if (len == 0) {
|
||||
return 0;
|
||||
}
|
||||
int res = available();
|
||||
if (res == 0) {
|
||||
res = makeAvailable();
|
||||
if (res == 0) {
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
res = Math.min(res, len);
|
||||
System.arraycopy(buffer, head, b, off, res);
|
||||
head += res;
|
||||
total += res;
|
||||
return res;
|
||||
}
|
||||
~~~
|
||||
|
||||
# 源码获取
|
||||
|
||||
我已经按照这套想法完整地实现了文件上传组件
|
||||
|
||||
有兴趣的朋友可以从我的Gighub获取源码 [点我获取][github]
|
||||
|
||||
使用方法:[点我查看][use]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[http-get]: {{"/http-get.png" | prepend: site.imgrepo }}
|
||||
[http-post]: {{"/http-post.png" | prepend: site.imgrepo }}
|
||||
[boundary-A]: {{"/boundary-A.png" | prepend: site.imgrepo }}
|
||||
[boundary-B]: {{"/boundary-B.png" | prepend: site.imgrepo }}
|
||||
[pad]: {{"/boundary-C.png" | prepend: site.imgrepo }}
|
||||
[github]: https://github.com/dubuyuye/fileupload/releases
|
||||
[use]: https://github.com/dubuyuye/fileupload
|
||||
[commons-fileupload]: https://github.com/apache/commons-fileupload
|
||||
@@ -1,687 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Flex
|
||||
tags: Flex ActionScript script
|
||||
categories: front-end
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
# 产品
|
||||
|
||||
1. Adobe® Flex™ SDK
|
||||
|
||||
2. Adobe® Flex™ Builder™
|
||||
|
||||
3. Adobe® Flex™ Data Services
|
||||
|
||||
4. Adobe® Flex™ Charting
|
||||
|
||||
|
||||
# Flex基础
|
||||
|
||||
## 应用程序模型
|
||||
|
||||
用容器(如Box)控件(如Button)来描述用户的操作界面
|
||||
|
||||
## MVC模型
|
||||
|
||||
1. 模型/Model 组件封装了数据和与数据相关的行为。
|
||||
|
||||
2. 视图/View 组件定义了应用程序的用户界面。
|
||||
|
||||
3. 控制器/Controller 组件则负责处理程序中的数据连接。
|
||||
|
||||
## Flex 编程模型
|
||||
|
||||
Flex 包含了**Flex 类库**、**MXML** 和**ActionScript** 编程语言,以及**Flex 编译器**和**调试器**。
|
||||
|
||||
>MXML 和 ActionScript 编程语言都提供了访问Flex 类库的能力。
|
||||
|
||||
通常的做法是:使用MXML 去定义用户界面的元素,使用ActionScript 去定义客户端的逻辑并进行控制。
|
||||
|
||||
Flex 类库包括了**Flex 组件**、**管理器**和**行为**。
|
||||
|
||||
|
||||
## Flex 元素
|
||||
|
||||
* Flex framework
|
||||
|
||||
* MXML
|
||||
|
||||
* ActionScript 3.0
|
||||
|
||||
* CSS
|
||||
|
||||
* 图形资源
|
||||
|
||||
* 数据
|
||||
|
||||
|
||||
~~~xml
|
||||
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="absolute">
|
||||
<mx:Panel>
|
||||
<mx:TextArea text="Say hello to Flex!" />
|
||||
<mx:Button label="Close" />
|
||||
</mx:Panel>
|
||||
</mx:Application>
|
||||
|
||||
~~~
|
||||
|
||||
## 发布方式
|
||||
|
||||
1. 客户端模式,即应用程序只运行在客户端上而不需要服务器资源。
|
||||
|
||||
2. 使用简单的RPC 访问服务器数据,即使用HTTPService(HTTP GET 或POST 请求)和WebService(通过使用SOAP)。
|
||||
|
||||
3. Flex Data Services 模式,可以提供更为高级的特性,如数据同步、安全增强等等。
|
||||
|
||||
|
||||
|
||||
# 界面布局
|
||||
|
||||
样式
|
||||
|
||||
~~~xml
|
||||
<mx:Style>
|
||||
{
|
||||
fontSize: 36px;
|
||||
fontWeight: bold;
|
||||
}
|
||||
</mx:Style>
|
||||
|
||||
~~~
|
||||
外部样式
|
||||
|
||||
~~~xml
|
||||
<mx:Style source="styles.css"/>
|
||||
|
||||
~~~
|
||||
|
||||
## 控制应用程序的外观
|
||||
|
||||
1. 大小/Sizes,即组件或应用程序的高度和宽度。
|
||||
|
||||
2. 样式/Styles,即一组特性,如字体、排列方式、颜
|
||||
色等。它们都是通过层叠样式( CSS)来进行设置的。
|
||||
|
||||
3. 皮肤/Skins,即可以进行改变的组件视觉元素。
|
||||
|
||||
4. 行为/Behaviors,即Flex 组件在视觉或听觉效果方面的变化。
|
||||
|
||||
5. 视图状态/View state 可以让你通过修改它的基础内容,来改变组件或程序的内容和外观。
|
||||
|
||||
6. 变换/Transitions 可以让你定义屏幕上发生改变的视图状态。
|
||||
|
||||
|
||||
## 受约束的布局
|
||||
|
||||
受约束的布局可以确保用户界面中的组件在程序窗
|
||||
|
||||
口大小发生变化时,也能自动地作出调节。备注:可以通过使用嵌套的布局容器/nested layout container 来实现相同的目的
|
||||
|
||||
创建受约束的布局,你必须将容器的布局属性设置为绝对方式( `layout="absolute"`)备注:帆布容器/canvas container 并不需要进行layout=”absolute”的属性设置,因为它默认是绝对布局方式。
|
||||
|
||||
在Flex 中,所有的约束都是被设置为与**容器**的相对距离,它们不可能被设置为相对于其它控件
|
||||
|
||||
**控件**
|
||||
|
||||
ComboBox,List,HorizontalList。
|
||||
|
||||
|
||||
|
||||
# 事件与行为
|
||||
|
||||
外部ActionScript
|
||||
|
||||
~~~xml
|
||||
<mx:Script source="myFunctions.as" />
|
||||
|
||||
~~~
|
||||
|
||||
被事件触发的行为
|
||||
|
||||
mxml中的组件被赋予id后,在as中将可以直接作为对象进就行操作,如例子中的`vBox`
|
||||
|
||||
~~~xml
|
||||
var locales:ArrayCollection = new ArrayCollection([{label:"en_us", data:"en_us"},{label:"zh_cn", data:"zh_cn"}]);
|
||||
|
||||
var child:ComboBox = new ComboBox();
|
||||
child.dataProvider=locales;
|
||||
vBox.addChild(child);
|
||||
|
||||
~~~
|
||||
|
||||
也可以在as中为事件绑定行为
|
||||
|
||||
~~~xml
|
||||
//change事件绑定
|
||||
localeComboBox.addEventListener(ListEvent.CHANGE,localeComboxChangeHandler);
|
||||
|
||||
~~~
|
||||
|
||||
## 多态页面
|
||||
|
||||
用ViewStack 组件、创建单独的MXML 文件、或者使用视图状态
|
||||
|
||||
## 创建行为
|
||||
|
||||
~~~xml
|
||||
<mx:Glow id="buttonGlow" color="0x99FF66" alphaFrom="1.0" alphaTo="0.3" duration="1500"/>
|
||||
<mx:Button x="40" y="60" label="View" id="myButton" mo
|
||||
useUpEffect="{buttonGlow}" />
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
|
||||
|
||||
# 连接数据
|
||||
|
||||
数据源,url获取xml类型数据
|
||||
|
||||
flex 不直接连接数据库,而是用数据服务组件获取xml数据
|
||||
|
||||
~~~xml
|
||||
<mx:HTTPService id="simpleData" url="..."/>
|
||||
|
||||
~~~
|
||||
|
||||
数据绑定,并非简单的引用,dataProvider与simpleData.lastResult.products.items是同步变化的
|
||||
|
||||
~~~xml
|
||||
<mx:DataGrid dataProvider="{simpleData.lastResult.products.items}" >
|
||||
<mx:columns>
|
||||
<mx:DataGridColumn headerText="resources" dataField="resources" />
|
||||
</mx:columns>
|
||||
</mx:DataGrid>
|
||||
|
||||
~~~
|
||||
|
||||
事件绑定
|
||||
|
||||
~~~xml
|
||||
<mx:Button label="load" click="simpleData.send();"/>
|
||||
|
||||
~~~
|
||||
|
||||
## 连接数据服务器
|
||||
|
||||
1. WebService 提供对使用SOAP 的web 服务器的访问。
|
||||
|
||||
2. HTTPService 提供对返回数据的HTTP URLs 的访问。
|
||||
|
||||
3. RemoteObject 通过使用AML 协议提供对Java 对象(Java Beans、EJBs、POJOs)的访问。该选项目前仅适用于Flex Data Services 或Macromedia ColdFusion MX 7.0.2.
|
||||
|
||||
|
||||
## 安全性
|
||||
|
||||
1. swf与数据源必须同域
|
||||
|
||||
2. 可以使用代理访问远程数据源,但是swf必须与代理服务器同域
|
||||
|
||||
3. 安装`crossdomain.xml`(跨域策略/cross-domain policy)文件在数据源的宿主Web 服务器上。
|
||||
crossdomain.xml 文件允许位于其它域中的SWF 文件对数据源的访问。
|
||||
|
||||
|
||||
|
||||
|
||||
# 图表组件
|
||||
|
||||
* 区域形图表/Area charts
|
||||
|
||||
* 气泡形图表/Bubble charts
|
||||
|
||||
* 烛形图表/Candlestick charts
|
||||
|
||||
* 柱形图表/Column charts
|
||||
|
||||
* 高低开合形图表/HighLowOpenClose charts
|
||||
|
||||
* 线形图表/Line charts
|
||||
|
||||
* 饼形图表/Pie charts
|
||||
|
||||
* 标绘形图表/Plot charts
|
||||
|
||||
* 扩展CartesianChart 控件来创建定制的图表
|
||||
|
||||
>使用`dataProvider` 属性定义图表的数据
|
||||
|
||||
# MXML
|
||||
|
||||
MXM 相关的技术标准有
|
||||
|
||||
1. XML 标准。XML 文档使用标签去决定结构化信息的内容,以及它们之间的关系。
|
||||
|
||||
2. 事件模型标准。Flex 事件模型是文档对象模型/Document Object Model (DOM)第三级事件的一个子集,该模型是由World Wide Web Consortium(W3C)起草制定。
|
||||
|
||||
3. Web 服务标准Flex 提供与服务器交互的MXML 标签,遵循了Web 服务描述语言/Web Services
|
||||
Description Language(WSDL)的规则。具体包括了简单对象访问协议/Simple Object Access Pr
|
||||
otocol(SOAP)和超文本传送协议/Hypertext Transfer Protocol(HTTP)。
|
||||
|
||||
4. Java 标准
|
||||
|
||||
Flex 提供了与服务器端Java 对象交互的MXML 标签,包括plain old Java objects(POJOs),Java
|
||||
|
||||
Beans 和企业级/Enterprise JavaBeans(EJBs)。
|
||||
|
||||
5. HTTP 标准
|
||||
|
||||
Flex 提供了相应的MXML 标签去支持标准的HTTP GET 和POST 请求,以及对HTTP 返回数据的处理。
|
||||
|
||||
6. 图形标准
|
||||
|
||||
Flex 还提供了相应的MXML 标签去使用JPEG,GIF 和PNG 图象。Flex 还能够将SWF 文件和Scala
|
||||
ble Vector Graphics(SVG)文件导入到应用程序中。
|
||||
|
||||
7. 层叠样式表标准MXML 样式的定义和使用遵循了W3C Cascading Style Sheets (CSS)标准。
|
||||
|
||||
|
||||
|
||||
# ActionScript
|
||||
|
||||
ActionScript 3.0 的特性完全实现了ECMAScript for XML (E4X)。
|
||||
在flex中使用ActionScript
|
||||
|
||||
1. 在`<mx:Script>`标签中插入ActionScript 代码块。
|
||||
|
||||
2. 调用存储在**system_classes** 目录结构中的全局ActionScript 功能函数。
|
||||
|
||||
3. 引用**user_classes **中的外部类和包来处理更为复杂的任务。
|
||||
|
||||
4. 使用标准的Flex 组件。
|
||||
|
||||
5. 使用ActionScript 类扩展已有的组件。
|
||||
|
||||
6. 使用ActionScript 创建新的组件。
|
||||
|
||||
7. 在Flash 创建环境中创建新的组件( SWC 文件)。
|
||||
|
||||
|
||||
# XML
|
||||
|
||||
## 创建xml对象
|
||||
|
||||
* 字面量方式,AS可以自动识别,如果加上引号就不是XML类型而是String类型了
|
||||
|
||||
~~~xml
|
||||
var textXmlObj:XML = <test><element>text</element></test>;
|
||||
|
||||
~~~
|
||||
|
||||
* XML字面量中可以加入动态内容
|
||||
|
||||
~~~xml
|
||||
var text_node:String = "text";
|
||||
var textXmlObj:XML = <test><element>{text_node}</element></test>;
|
||||
|
||||
~~~
|
||||
|
||||
* 通过XML类创建实例
|
||||
|
||||
~~~xml
|
||||
var myText:String = "text";
|
||||
var str:String = "<test><element>"+ myText + "</element></test>";
|
||||
var textXmlObj:XML = new XML(str);
|
||||
|
||||
~~~
|
||||
|
||||
* 从外部加载XML对象
|
||||
|
||||
~~~xml
|
||||
<mx:HTTPService id="simpleData" url="simpleData.xml" useProxy="false" result="test(event);"/>
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
## 处理XML对象
|
||||
|
||||
~~~xml
|
||||
<items>
|
||||
<item index="0">
|
||||
<name>Mobile Phone</name>
|
||||
<price>$199</price>
|
||||
</item>
|
||||
<item index="1">
|
||||
<name>Car Charger</name>
|
||||
<price>$34</price>
|
||||
</item>
|
||||
</items>
|
||||
|
||||
~~~
|
||||
|
||||
使用**`E4X`**简化对XML的操作
|
||||
|
||||
~~~xml
|
||||
<mx:HTTPService id="simpleData" url="simpleData.xml" useProxy="false" result="test(event);" resultFormat="e4x"/>
|
||||
|
||||
~~~
|
||||
|
||||
### 查询
|
||||
|
||||
使用`.`操作符查询节点
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item
|
||||
|
||||
~~~
|
||||
使用`[]`访问指定索引的节点,**将无法检测到数据变化**,根节点被忽略
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item[0]
|
||||
|
||||
~~~
|
||||
使用`..`访问所有指定名称的节点,忽略上下级关系
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult..name
|
||||
|
||||
~~~
|
||||
使用`@`访问节点属性
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item[0].@index
|
||||
|
||||
~~~
|
||||
过滤节点(`<`与`>`无法在mxml中使用,需要转义)
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item.(price==34)
|
||||
|
||||
~~~
|
||||
过滤属性
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item.(@index==0)
|
||||
|
||||
~~~
|
||||
修改获取的数据(不改变xml源对象)
|
||||
|
||||
~~~xml
|
||||
simpleData.lastResult.item.(price=998)}
|
||||
|
||||
~~~
|
||||
HttpService对象在加载外部XML后会自动把它转换成ArrayCollection对象
|
||||
|
||||
如果需要属性结构如(Tree组件),需要在HTTPService对象中加上resultFormat="e4x"以XML的格式读取进来而不要转换为ArrayCollection
|
||||
|
||||
### 修改
|
||||
|
||||
>如果绑定的xml数据发生的变化,如何将变化传递到引用?目前发现似乎是自动的,有待研究。
|
||||
|
||||
|
||||
~~~xml
|
||||
var myxml:XML = <books>
|
||||
<book name="flex tutorial">
|
||||
<price>30</price>
|
||||
<author>adobe</author>
|
||||
</book>
|
||||
</books>
|
||||
|
||||
~~~
|
||||
添加节点,insert指定子节点位置插入,append添加到子节点末尾,prepend插入到子节点开头
|
||||
|
||||
~~~xml
|
||||
myxml.insertChildAfter(myxml.book[0],<newbook name="After"/>);
|
||||
myxml.insertChildBefore(myxml.book[0],<newbook name="Before"/>);
|
||||
myxml.appendChild(<newbook name="Append"/>);
|
||||
myxml.prependChild(<newbook name="Prepend"/>);
|
||||
|
||||
~~~
|
||||
添加属性
|
||||
|
||||
~~~xml
|
||||
myxml.book[0].@date="2008";
|
||||
|
||||
~~~
|
||||
修改xml对象,此处增加`<author>`标签content为奥多比
|
||||
|
||||
~~~xml
|
||||
myxml.book[0].author="奥多比";
|
||||
|
||||
~~~
|
||||
删除节点,属性,content
|
||||
|
||||
~~~xml
|
||||
delete myxml.book[0].@name;
|
||||
delete myxml.book[0].author;
|
||||
delete myxml.book[0].price.text()[0];
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
|
||||
# 备忘
|
||||
|
||||
IDEA 编译出错 **java.net.SocketTimeoutException: Accept timed out**
|
||||
>[Stack Overflow](http://stackoverflow.com/questions/11016571/intellij-idea-11-flex-compilation-issue)
|
||||
>
|
||||
>1. Go to **Settings** > **Compiler** > **Flex Compiler**
|
||||
>
|
||||
>2. Choose **Mxmlc/compx** instead of the default **Built-in compiler shell**
|
||||
>
|
||||
>3. Compile your application
|
||||
|
||||
# 整合SpringMVC
|
||||
|
||||
Flex要想与Spring进行配合使用,需要一个附加的组件BlazeDS。BlazeDS可以将Flex前端的通信内容(amf 格式 Action Message format,一种flex定义的通信规则)转换为java的相关类和对象。
|
||||
|
||||
请求处理的简单流程是,flex客户端向服务器发送Request请求,服务器根据Web.xml中的映射,找到Spring配置文档中与flex相关的配置,这个配置就是`MessageBroker`,MessageBroker是Spring容器根据flex的`services-config.xml`文件生成的,在services-config.xml中指定了消息通道,Spring将请求交给这个通道(一般是默认通道),通道根据`remoting-config.xml`中配置的remoting-service和Adapter将flex的amf转换为java的实例信息。如果需要安全或者消息订阅(jms)还需要提供`messaging-config.xml`和`proxy-config.xml`配置文件。
|
||||
|
||||
结合使用Spring和BlazeDS必须对MessageBroker进行配置。从flex客户端发来的Http 消息(messages)通过Spring的DispatcherServlet(在web.xml中配置)传递给Spring管理的MessageBroker(在Spring的配置文档中指明)。如果使用Spring管理的MessageBroker就不必配置BlazeDS的`MessageBrokerServlet`(在web.xml文档中指明)了。
|
||||
|
||||
## 依赖
|
||||
|
||||
~~~xml
|
||||
<properties>
|
||||
<spring.version>3.0.1.RELEASE</spring.version>
|
||||
<flex.version>4.6</flex.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework</groupId>
|
||||
<artifactId>spring-webmvc</artifactId>
|
||||
<version>${spring.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.flex</groupId>
|
||||
<artifactId>org.springframework.flex</artifactId>
|
||||
<version>1.0.3.RELEASE</version>
|
||||
</dependency>
|
||||
|
||||
<!-- flex library -->
|
||||
|
||||
<dependency>
|
||||
<groupId>com.adobe.flex</groupId>
|
||||
<artifactId>messaging-common</artifactId>
|
||||
<version>${flex.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.adobe.flex</groupId>
|
||||
<artifactId>messaging-core</artifactId>
|
||||
<version>${flex.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.adobe.flex</groupId>
|
||||
<artifactId>messaging-remoting</artifactId>
|
||||
<version>${flex.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>backport-util-concurrent</groupId>
|
||||
<artifactId>backport-util-concurrent</artifactId>
|
||||
<version>3.1</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>cglib</groupId>
|
||||
<artifactId>cglib</artifactId>
|
||||
<version>2.2.2</version>
|
||||
</dependency>
|
||||
</dependencies
|
||||
|
||||
~~~
|
||||
|
||||
## 配置web.xml
|
||||
|
||||
~~~xml
|
||||
<servlet>
|
||||
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
|
||||
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
|
||||
<init-param>
|
||||
<param-name>contextConfigLocation</param-name>
|
||||
<param-value>
|
||||
classpath:applicationContext.xml
|
||||
</param-value>
|
||||
</init-param>
|
||||
<load-on-startup>1</load-on-startup>
|
||||
</servlet>
|
||||
|
||||
<!-- MessageBroker Servlet flex mapping-->
|
||||
<servlet-mapping>
|
||||
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
|
||||
<url-pattern>/messagebroker/*</url-pattern>
|
||||
</servlet-mapping>
|
||||
|
||||
~~~
|
||||
|
||||
Flex通过`AMF`通道的形式进行通信的,所谓的AMF通道就是指一种编码形式。MessageBroker可以将Flex格式的请求转换成具体的java的调用,并将反馈回的内容(response)编码成Flex能够识别的对象(amf)。
|
||||
|
||||
## Srping容器
|
||||
|
||||
使用了默认位置的配置文件
|
||||
|
||||
~~~xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<beans xmlns="http://www.springframework.org/schema/beans"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xmlns:flex="http://www.springframework.org/schema/flex"
|
||||
xmlns:context="http://www.springframework.org/schema/context"
|
||||
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
|
||||
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
|
||||
http://www.springframework.org/schema/flex http://www.springframework.org/schema/flex/spring-flex-1.0.xsd">
|
||||
|
||||
<!-- 使用默认位置的配置文件/WEB-INF/flex/services-config.xml-->
|
||||
<flex:message-broker/>
|
||||
</bean>
|
||||
</beans>
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
## 通道
|
||||
|
||||
在BlazeDS的配置文件services-config.xml中定义的通道必须与相应的映射相对应。
|
||||
|
||||
~~~xml
|
||||
<channels>
|
||||
<channel-definition id="my-amf" class="mx.messaging.channels.AMFChannel">
|
||||
<!-- {context.root}之后的messagebroker必须与ServletMapping相同 -->
|
||||
<endpoint url="http://{server.name}:{server.port}/{context.root}/messagebroker/amf"
|
||||
class="flex.messaging.endpoints.AMFEndpoint"/>
|
||||
</channel-definition>
|
||||
</channels>
|
||||
|
||||
~~~
|
||||
|
||||
## 配置远程服务
|
||||
|
||||
这里有列举了两种发布方式,任选一种即可。
|
||||
|
||||
①创建使用注解发布的服务
|
||||
|
||||
~~~java
|
||||
package top.rainynight.flex2spring;
|
||||
|
||||
import org.springframework.flex.remoting.RemotingDestination;
|
||||
import org.springframework.flex.remoting.RemotingInclude;
|
||||
import org.springframework.stereotype.Component;
|
||||
|
||||
@Component
|
||||
@RemotingDestination
|
||||
public class AnnotationRPC {
|
||||
|
||||
public String read(String id) {
|
||||
return "annotation works";
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
~~~
|
||||
②创建使用xml发布的服务
|
||||
|
||||
~~~java
|
||||
package top.rainynight.flex2spring;
|
||||
|
||||
/**
|
||||
* Created by sllx on 2015-03-16.
|
||||
*/
|
||||
public class XmlConfRPC {
|
||||
public String read(String id) {
|
||||
return "xml works";
|
||||
}
|
||||
}
|
||||
|
||||
~~~
|
||||
发布配置发布方式任选一种即可
|
||||
|
||||
~~~xml
|
||||
<context:component-scan base-package="top"/>
|
||||
|
||||
<bean id="xmlConfRPC" class="top.rainynight.flex2spring.XmlConfRPC">
|
||||
<flex:remoting-destination/>
|
||||
</bean>
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
## flex使用默认channel
|
||||
flex配置编译参数
|
||||
|
||||
~~~
|
||||
-services "pathToWebappRoot/WEB-INF/flex/services-config.xml" -locale en_US
|
||||
|
||||
~~~
|
||||
|
||||
## 测试
|
||||
|
||||
~~~xml
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<s:Application xmlns:fx="http://ns.adobe.com/mxml/2009"
|
||||
xmlns:s="library://ns.adobe.com/flex/spark"
|
||||
xmlns:mx="library://ns.adobe.com/flex/mx" minWidth="955" minHeight="600" applicationComplete="applicationCompleteHandler(event)">
|
||||
<fx:Script>
|
||||
<![CDATA[
|
||||
import mx.controls.Alert;
|
||||
import mx.events.FlexEvent;
|
||||
import mx.messaging.events.MessageAckEvent;
|
||||
import mx.rpc.events.FaultEvent;
|
||||
import mx.rpc.events.ResultEvent;
|
||||
|
||||
|
||||
protected function resultHandler(event:ResultEvent):void
|
||||
{
|
||||
Alert.show(event.result.toString(),"result");
|
||||
}
|
||||
|
||||
protected function faultHandler(event:FaultEvent):void
|
||||
{
|
||||
Alert.show(event.message.toString() ,"error");
|
||||
}
|
||||
|
||||
protected function applicationCompleteHandler(event:FlexEvent):void
|
||||
{
|
||||
ro.read("1");
|
||||
}
|
||||
|
||||
]]>
|
||||
</fx:Script>
|
||||
<fx:Declarations>
|
||||
<s:RemoteObject destination="annotationRPC" id="ro" result="resultHandler(event)" fault="faultHandler(event)" />
|
||||
</fx:Declarations>
|
||||
</s:Application>
|
||||
|
||||
|
||||
~~~
|
||||
@@ -1,166 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Linux计划任务
|
||||
tags: 计划任务 Linux
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
## `at`
|
||||
|
||||
at 是个可以处理**仅运行一次**就结束计划任务的命令,不过要运行 at 时, 必须要有 atd 这个服务的支持才行。
|
||||
|
||||
[root@www ~]# `/etc/init.d/atd restart`
|
||||
|
||||
使用 at 这个命令来产生所要运行的任务,并将任务以文件的方式写入 `/var/spool/at` 目录内,该任务便能被 atd 服务运行
|
||||
|
||||
>对at进行权限控制
|
||||
>
|
||||
>* 先找寻 `/etc/at.allow` 这个文件,写在这个文件中的使用者才**能**使用 at ,没有在这个文件中的使用者则不能使用 at (即使没有写在 at.deny 当中);
|
||||
>
|
||||
>* 如果 /etc/at.allow 不存在,就寻找 `/etc/at.deny` 这个文件,写在这个 at.deny 的使用者**不能**使用 at ,而没有在这个 at.deny 文件中的使用者,就可以使用 at 咯;
|
||||
>
|
||||
>* 如果两个文件都不存在,那么只有 root 可以使用 at 命令。
|
||||
|
||||
[root@www ~]# `at [-mldv] TIME`
|
||||
|
||||
[root@www ~]# `at -c 任务号码`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-m` :当 at 的任务完成后,即使没有输出信息,亦以 email 通知使用者该任务已完成。
|
||||
|
||||
`-l` :at -l 相当於 `atq`,列出目前系统上面的所有该使用者的 at 任务;
|
||||
|
||||
`-d` :at -d 相当於 `atrm` ,可以取消一个在 at 排程中的任务;
|
||||
|
||||
`-v` :可以使用较明显的时间格式列出 at 排程中的任务列表;
|
||||
|
||||
`-c` :可以列出后面接的该项工作的实际命令内容。
|
||||
|
||||
>TIME:时间格式,这里可以定义出『什么时候要进行 at 这项工作』的时间,格式有:
|
||||
>
|
||||
>* `HH:MM`
|
||||
>
|
||||
> ex> 04:00
|
||||
>
|
||||
> 在今日的 HH:MM 时刻进行,若该时刻已超过,则明天的 HH:MM 进行此工作。
|
||||
>
|
||||
>* `HH:MM YYYY-MM-DD`
|
||||
>
|
||||
> ex> 04:00 2009-03-17
|
||||
>
|
||||
> 强制在某年某月某日的某时刻进行!
|
||||
>
|
||||
>* `HH:MM[am|pm] [Month] [Date]`
|
||||
>
|
||||
> ex> 04pm March 17
|
||||
>
|
||||
> 强制在某年某月某日的某时刻进行!
|
||||
>
|
||||
>* `HH:MM[am|pm] + number [minutes|hours|days|weeks]`
|
||||
>
|
||||
> ex> now + 5 minutes ex> 04pm + 3 days
|
||||
>
|
||||
> 在某个时间点『再加几个时间后』才进行。
|
||||
|
||||
`!`at命令会进入atshell环境,使用绝对路径输入指令不易出现问题
|
||||
|
||||
`!`at 的运行与终端机环境无关,想要查看io结果,需要指定终端`echo "Hello" > /dev/tty1`
|
||||
|
||||
`!`at 的运行独立于bash,所以at任务可以离线运行
|
||||
|
||||
**`batch`**:系统有空(负载低于0.8 )时才进行背景任务,用法与at完全相同,本质上是是at命令加一些控制参数
|
||||
|
||||
|
||||
|
||||
## `crontab`
|
||||
|
||||
crontab 这个命令所配置的工作将会循环的**一直进行**下去, 可编辑 /etc/crontab 来支持,让 crontab 生效的服务是 `crond`
|
||||
|
||||
[root@www ~]# ·`/etc/init.d/crond restart`
|
||||
|
||||
当使用者使用 crontab 这个命令来创建工作排程之后,该项工作就会被纪录到 `/var/spool/cron/`目录内
|
||||
|
||||
cron 运行的每一项工作都会被纪录到 `/var/log/cron` 内
|
||||
|
||||
>权限控制(与at相同,默认保留/etc/cron.deny )
|
||||
>
|
||||
>* `/etc/cron.allow`:将可以使用 crontab 的帐号写入其中,若不在这个文件内的使用者则不可使用 crontab;
|
||||
>
|
||||
>* `/etc/cron.deny`:将不可以使用 crontab 的帐号写入其中,若未记录到这个文件当中的使用者,就可以使用 crontab
|
||||
|
||||
[root@www ~]# `crontab [-u username] [-l|-e|-r]`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-u` :只有 root 才能进行这个任务,亦即帮其他使用者创建/移除 crontab 工作排程;
|
||||
|
||||
`-e` :编辑 crontab 的工作内容
|
||||
|
||||
`-l` :查阅 crontab 的工作内容
|
||||
|
||||
`-r` :移除所有的 crontab 的工作内容,若仅要移除一项,请用 -e 去编辑。
|
||||
|
||||
[dmtsai@www ~]$ `crontab -e`
|
||||
|
||||
>`0 12 * * * <command>`
|
||||
>
|
||||
>`分 时 日 月 周 <命令串>`
|
||||
|
||||
特殊字符
|
||||
|
||||
`*`代表任何时刻都接受的意思
|
||||
|
||||
`,`代表分隔时段的意思
|
||||
|
||||
`-`代表一段时间范围内
|
||||
|
||||
`/n`代表每间隔n单位
|
||||
|
||||
系统计划任务(不受crontab -e命令管理)
|
||||
编辑`/etc/crontab`文件,该文件每1分钟被检查一次
|
||||
|
||||
|
||||
## `anacron`
|
||||
|
||||
侦测系统未进行的 crontab 任务(例如 crontab 设置在周末运行,但是周末关机了)
|
||||
|
||||
[root@www ~]# `anacron [-sfn] [job]..`
|
||||
|
||||
[root@www ~]# `anacron -u [job]..`
|
||||
|
||||
选项与参数:
|
||||
|
||||
`-s` :开始一连续的运行各项工作 (job),会依据时间记录档的数据判断是否进行;
|
||||
|
||||
`-f` :强制进行,而不去判断时间记录档的时间戳记;
|
||||
|
||||
`-n` :立刻进行未进行的任务,而不延迟 (delay) 等待时间;
|
||||
|
||||
`-u` :仅升级时间记录档的时间戳记,不进行任何工作。
|
||||
|
||||
`job` :由 **/etc/anacrontab** 定义的各项工作名称。
|
||||
|
||||
配置文件位于`/etc/anacrontab`
|
||||
|
||||
>[root@www ~]# cat /etc/anacrontab
|
||||
>
|
||||
>SHELL=/bin/sh
|
||||
>
|
||||
>PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||
>
|
||||
>MAILTO=root
|
||||
|
||||
>1 65 cron.daily run-parts /etc/cron.daily
|
||||
>
|
||||
>7 70 cron.weekly run-parts /etc/cron.weekly
|
||||
>
|
||||
>30 75 cron.monthly run-parts /etc/cron.monthly
|
||||
|
||||
天数 延迟时间(分) 工作名称定义 实际要进行的命令串
|
||||
|
||||
任务文件位于`/var/spool/anacron/`
|
||||
@@ -1,82 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 超类中的泛型
|
||||
tags: generic type Java
|
||||
categories: java
|
||||
published: false
|
||||
---
|
||||
|
||||
为了减少工作量,开发者往往喜欢将相同的特性放入超类,通过继承实现代码共享
|
||||
|
||||
例如web项目中常见的`BaseDao<T>`,并使用泛型对参数与返回值类型进行约束
|
||||
|
||||
某些情况下,我们可能需要获得真实的类型参数,也就是`T`的真实类型
|
||||
|
||||
首先,沿着继承链向上追溯,找到传入类型参数的位置,并获取存储类型参数的对象
|
||||
|
||||
~~~java
|
||||
private static ParameterizedType getParameterizedType(Class<?> clazz){
|
||||
Type st = clazz.getGenericSuperclass();
|
||||
if(st == null){
|
||||
return null;
|
||||
}
|
||||
if(st instanceof ParameterizedType){
|
||||
ParameterizedType pt = (ParameterizedType)st;
|
||||
return pt;
|
||||
} else{
|
||||
return getParameterizedType(clazz.getSuperclass());
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
类的参数数量是不定的,如 `Map<K,V>` 定义了两个,`List<T>` 只定义了一个,所以类型参数是个列表,获取真实类型时需要指定要取哪一个
|
||||
|
||||
~~~java
|
||||
private static Class<?> getClass(ParameterizedType pt, int index){
|
||||
Type param = pt.getActualTypeArguments()[index];
|
||||
if(param instanceof Class){
|
||||
return (Class<?>)param;
|
||||
} else {
|
||||
return null;
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
通常情况下,到这里已经可以取到真实类型了,但是上面的代码忽略了一些不正常情况
|
||||
|
||||
**情况一:**
|
||||
|
||||
超类定义了多个参数,而子类中是分批传参的,此时从继承链上最近的位置获得的参数列表是不全的
|
||||
|
||||
~~~java
|
||||
class Generic<K,V>{}
|
||||
class SubGeneric<V> extends Generic<String,V>{}
|
||||
class Acturl extends SubGeneric<String>{}
|
||||
~~~
|
||||
|
||||
**情况二:**
|
||||
|
||||
在继承链中的某个位置传入了类型参数,然后又定义了一个新的参数,此时从继承链上最近的位置获取的参数列表和顶层类的参数已经没有关系了
|
||||
|
||||
~~~ java
|
||||
class Generic<K>{}
|
||||
class SubGeneric<S> extends Generic<String>{}
|
||||
class Acturl extends SubGeneric<Integer>{}
|
||||
~~~
|
||||
|
||||
**情况三:**
|
||||
|
||||
这是情况一与情况二的混合版,而且参数`V`的位置都变了
|
||||
|
||||
~~~ java
|
||||
class Generic<K,V>{}
|
||||
class SubGeneric<V,S> extends Generic<String,V>{}
|
||||
class Acturl extends SubGeneric<Integer,String>{}
|
||||
~~~
|
||||
|
||||
|
||||
这些问题有空再研究
|
||||
|
||||
~~~java
|
||||
//TODO
|
||||
~~~
|
||||
@@ -1,126 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: SSH
|
||||
tags: Linux 命令 SSH
|
||||
categories: Linux
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
## 登陆
|
||||
|
||||
**`-p`指定主机的端口**
|
||||
|
||||
`$ ssh -p port user@host`
|
||||
|
||||
**默认端口为22**
|
||||
|
||||
`$ ssh user@host`
|
||||
|
||||
**默认使用本机用户名**
|
||||
|
||||
`$ ssh host`
|
||||
|
||||
## 过程
|
||||
|
||||
1. 远程主机接收到用户的登陆请求,把自己的公钥发给用户
|
||||
|
||||
2. 用户使用这个公钥,将密码加密后发回来
|
||||
|
||||
3. 远程主机用自己的私钥,解密登陆密码,如果密码正确,就同意用户登陆
|
||||
|
||||
>此处如果有攻击者截取了用户请求,再将自己的公钥发送给用户,然后就可以用自己的私钥解密出用户的私密信息,这就是`中间人攻击`
|
||||
>
|
||||
>应对的方法:用户首次连接远程主机时,远程主机将发送一段128位长的公钥指纹,用户需要自行与远程主机网站发布的公钥指纹进行对比以判断真伪,当用户信任了此公钥后,它将被保存在`$HOME/.ssh/known_hosts`中,下次连接时无需再次确认。
|
||||
|
||||
<br>
|
||||
|
||||
## 公钥登陆
|
||||
|
||||
原理:用户将自己的`公钥`保存在远程主机上,登录时,远程主机向用户发送一段随机码,用户用自己的`私钥`签名后,在发回远程主机,远程主机用实现保存的`公钥`进行验证,如果成功,表示用户的身份正确,无需输入密码
|
||||
|
||||
1. 用户生成一对自己的密钥
|
||||
|
||||
2. 将用户的`公钥`内容添加到 `$HOME/.ssh/authorized_keys`中(可以用`ssh-copy-id user@host`进行该操作)
|
||||
|
||||
3. 重启ssh服务 `/etc/init.d/ssh restart`
|
||||
|
||||
>公钥登陆相关配置 /etc/ssh/sshd_config
|
||||
>
|
||||
>RSAAuthentication yes
|
||||
>
|
||||
>PubkeyAuthentication yes
|
||||
>
|
||||
>AuthorizedKeysFile .ssh/authorized_keys
|
||||
|
||||
|
||||
## 远程操作
|
||||
|
||||
1. 直接操作 `$ ssh user@host command`
|
||||
|
||||
2. 用户和远程主机之间,建立命令和数据的传输通道
|
||||
|
||||
>将当前目录下的src文件,复制到远程主机的$HOME目录
|
||||
>
|
||||
>`$ tar czv src | ssh user@host "tar xz"`
|
||||
>
|
||||
>将远程主机$HOME目录下面的src文件,复制到用户的当前目录
|
||||
>
|
||||
>`$ ssh user@host "tar cz src" | tar xzv`
|
||||
|
||||
|
||||
## 绑定本地端口
|
||||
|
||||
`ssh -D port user@host`
|
||||
|
||||
`-D` 指定与远程host建立隧道的本地端口
|
||||
|
||||
|
||||
## 本地端口转发
|
||||
|
||||
假定`localhost`是本地主机,`remotehost`是远程主机,这两台主机之间无法连通。但是,另外还有一台`boardhost`,可以同时与前面两台主机互连。
|
||||
|
||||
在本机键入如下命令
|
||||
|
||||
`$ ssh -L localPort:remotehost:remotePort boardhost`
|
||||
|
||||
`L`参数一共接受三个值,分别是"`本地端口:目标主机:目标主机端口`"
|
||||
|
||||
该命令的意思是指定SSH绑定本地端口`localPort`,然后指定`boardhost`将所有的数据,转发到目标主机`remotehost`的`remotePort`端口
|
||||
|
||||
>remotehost是boardhost 的相对地址(或绝对地址),因为数据其实是由boardhost 传输到remotehost中的,与localhost无关
|
||||
|
||||
这样一来`localhost`与`remotehost`之间将形成私密隧道,访问`localPort`就等于访问`remotePort`
|
||||
|
||||
|
||||
## 远程端口转发
|
||||
|
||||
假定`hostA`是本地主机,`hostB`是远程主机,这两台主机之间无法连通,而且,`boardhost`是一台内网主机,即`boardhost`可以访问`hostA`,但是`hostA`无法访问`boardhost`
|
||||
|
||||
在`boardhost`键入如下命令
|
||||
|
||||
`$ ssh -R portA:hostB:portB hostA`
|
||||
|
||||
`R`参数也是接受三个值,分别是"`远程主机端口:目标主机:目标主机端口`"。这条命令的意思,就是让`hostA`监听它自己的`portA`端口,然后将所有数据经由`boardhost`,转发到`hostB`的`portB`端口。
|
||||
|
||||
对`boardhost`来说`hostA`是远程机器,在`boardhost`机器上指定`hostA`监听某个端口,称为远程端口转发
|
||||
|
||||
>远程端口转发的前提条件是,`hostA`和`boardhost`两台主机都有sshd和ssh客户端,其原理就是:一开始由`hostA`充当`Server`,`boardhost`充当`Client`,`boardhost`发起请求建立一个连接;连接建立完成后,`hostA`就可以使用这个连接将充当`Clinet`,将数据转发至`boardhost`充当的`Server`;`boardhost`接收到数据后又需要充当`Client`将数据转发到`hostB`
|
||||
|
||||
## 其他参数
|
||||
|
||||
`N`参数,表示只连接远程主机,不打开远程shell;
|
||||
|
||||
`T`参数,表示不为这个连接分配TTY。
|
||||
|
||||
这个两个参数可以放在一起用,代表这个SSH连接只用来传数据,不执行远程操作。
|
||||
|
||||
`$ ssh -NT -D port user@host`
|
||||
|
||||
`f`参数,表示SSH连接成功后,转入后台运行。这样一来,就可以在不中断SSH连接的情况下,在本地shell中执行其他操作。
|
||||
|
||||
`$ ssh -f -D port user@host`
|
||||
|
||||
要关闭这个后台连接,就只有用kill命令去杀掉进程。
|
||||
@@ -1,541 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Java虚拟机
|
||||
tags: JVM Java
|
||||
categories: Java
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
# 一、走近JAVA
|
||||
|
||||
## 第一章、走近JAVA
|
||||
|
||||
java技术体系
|
||||
|
||||
![java][java]
|
||||
|
||||
### 1.1 jdk1.7的主要特性
|
||||
|
||||
G1收集器
|
||||
|
||||
JSR-292对非JAVA语言的调用支持
|
||||
|
||||
ARM指令集`?`
|
||||
|
||||
Sparc指令集`?`
|
||||
|
||||
**新语法**:原生二进制(0b开头),switch支持字符串,"<>"操作符,异常处理改进,简化变长参数方法调用,面向资源的try-catch-finally
|
||||
|
||||
**多核并行**:java.util.concurrent.forkjoin
|
||||
|
||||
openJdk子项目Sumatra:为java提供使用GPU、APU运算能力的工具
|
||||
|
||||
java并行框架:hadoop MapReduce
|
||||
|
||||
Scala,Erlang,Clojure天生具备并行计算能力
|
||||
|
||||
### 1.2 虚拟机历史
|
||||
|
||||
classic/exact vm → hotspot vm(sun jdk 与 open jdk 共同的虚拟机) → oracle 收购 bea与sun 拥有JRockit VM 与 Hotspot VM
|
||||
|
||||
jit编译器 → OSR 栈上替换(on-stack replace)
|
||||
|
||||
jsr : Java Specification Requests java规范请求
|
||||
|
||||
### 1.3 Open Service Gateway Initiative(OSGI)
|
||||
|
||||
一种java模块化标准《深入理解OSGI:Equinox原理,应用与最佳实践》
|
||||
|
||||
混合语言:运行于java平台上的其他语言:Clojure,JRuby/Rails,Groovy
|
||||
|
||||
|
||||
# 二、自动内存管理机制
|
||||
|
||||
## 第二章、java内存区域与内存溢出异常
|
||||
|
||||
### 2.1 运行时数据区
|
||||
|
||||
![runtime][runtime]
|
||||
|
||||
#### 2.1.1 程序计数器
|
||||
|
||||
程序计数器是一块比较小的内存空间,可以看成是当前线程所执行的字节码的行号指示器,字节码解释器通过改变计数器的值来选取指令。
|
||||
|
||||
java多线程通过轮流切换实现,每个线程都需要有一个独立的计数器,这类内存称为"线程私有"的内存。这是java虚拟机唯一没有规定任何OutOfMemoryError情况的区域。`线程私有`。
|
||||
|
||||
#### 2.1.2 java虚拟机栈
|
||||
|
||||
每个方法对应一个栈帧,存储局部变量表、操作数栈、动态链接、方法出口等,每个方法的执行对应着一个栈帧在虚拟机中的入栈与出栈。`线程私有`。
|
||||
|
||||
局部变量表存放了编译期可知的各种基本数据类型、对象引用(reference类型,不等同于对象本身)、returnAddress类型
|
||||
|
||||
long,double占两个局部变量空间,其余占一个,局部变量表所需空间在编译时确定,运行期不会改变。
|
||||
|
||||
#### 2.1.3本地方法栈
|
||||
|
||||
与java虚拟机栈作用类似,区别是虚拟机栈执行java方法,本地方法栈执行native方法。`线程私有`。
|
||||
|
||||
>**以上三个线程私有的内存区域,随线程而生,随线程而灭,无需考虑垃圾回收**
|
||||
|
||||
#### 2.1.4 java堆
|
||||
|
||||
最大的空间,`所有线程共享`,用于存放对象实例(数组也是对象),GC管理的主要区域,GC基本采用分代收集算法(新生代,老年代,永久代(方法区))。
|
||||
|
||||
java堆只需要逻辑连续,不要求物理连续
|
||||
|
||||
#### 2.1.5 方法区
|
||||
|
||||
`所有线程共享`,存储类信息、常量、静态变量、字段描述,方法描述,即时编译器编译后的代码等。Hotspot中称为永久代。
|
||||
|
||||
#### 2.1.6 运行时常量池
|
||||
|
||||
是`方法区`的一部分,class文件中包含类的版本,字段,方法,接口,常量池等。运行时常量池具备动态性,class常量池反之。
|
||||
|
||||
#### 2.1.7 直接内存
|
||||
|
||||
使用nativie函数分配堆外内存,然后在堆中通过DirectoryByteBuffer对象作为这块内存的引用。
|
||||
|
||||
不会受到java堆大小的限制,会受到本机总内存以及处理器寻址空间的限制。
|
||||
|
||||
### 2.2 HotSpot虚拟机对象探秘
|
||||
|
||||
#### 2.2.1 对象的创建
|
||||
|
||||
(1)检查能否在常量池定位到一个类的符号引用,
|
||||
|
||||
(2)检查这个类是否已被加载、解析和初始化过,如果没有,执行相应加载过程
|
||||
|
||||
(3)从java堆中分配确定大小的内存,有两种分配方式:指针碰撞与空闲列表,取决于垃圾收集器是否带有压缩整理功能
|
||||
|
||||
(4)分配空间的线程安全:同步或者本地线程分配缓冲,是否使用TLAB:-XX:+/-UseTLAB
|
||||
|
||||
(5)分配完成后,空间初始化为零值,设置对象头信息
|
||||
|
||||
(6)执行<init>(构造方法),字段赋值
|
||||
|
||||
#### 2.2.2 对象的内存布局:对象头,实例数据,对齐填充
|
||||
|
||||
(1)**对象头**包括两部分信息:
|
||||
|
||||
第一部分:存储对象自身的运行时数据,如 hashcode,GC分代年龄,锁状态标识,线程持有的锁,偏向线程ID,偏向时间戳等
|
||||
|
||||
第二部分:类型指针,即对象指向它的类元数据的指针,虚拟机以此确定对象是哪个类的实例,数组长度(if)
|
||||
|
||||
(2)**实例数据**:类中字段的内容,默认分配策略总是将相同宽度的字段分配到一起,所以子类较窄的变量可能插入父类变量的空隙中
|
||||
|
||||
(3)**对齐填充**:不是必然存在的,仅仅起到占位符的作用,因为对象大小以及对象头的大小必须是8字节的整数倍
|
||||
|
||||
#### 2.2.3 对象的访问定位
|
||||
|
||||
**句柄** (reference指向句柄池,句柄池指向实例数据和类型数据),稳定
|
||||
|
||||
![handle][handle]
|
||||
|
||||
**直接指针** (reference指向实例数据,实例数据中存放类型数据指针),速度快,少一次指针定位
|
||||
|
||||
![point][point]
|
||||
|
||||
HotSpot使用直接指针
|
||||
|
||||
确式内存管理:虚拟机可以知道内存中某个位置的具体数据是什么类型。这样做可以摒弃句柄池而使用直接指针。HotSpot使用OopMap数据结构实现。
|
||||
|
||||
### 2.3 OutOfMemoryError异常
|
||||
|
||||
程序计数器不会发生,其他内存区域都有可能发生
|
||||
|
||||
>-Xms10M -Xmx10M 设置java堆的大小
|
||||
>
|
||||
>-Xmn2g 设置新生代大小,java堆总大小=新生代+老年代
|
||||
>
|
||||
>-Xss 设置栈容量
|
||||
>
|
||||
>-verbose:gc 显示gc信息
|
||||
>
|
||||
>-XX:+HeapDumpOnOutOfMemoryError 出现内存溢出异常时Dump出当前的内存堆转储快照
|
||||
>
|
||||
>-XX:PermSize -XX:MaxPermSize 限制方法区大小
|
||||
>
|
||||
>-XX:MaxDirectMemorySize 指定直接内存容量,默认为java堆最大值
|
||||
|
||||
#### 2.3.1 java堆溢出
|
||||
|
||||
java.lang.OutOfMemoryError: Java heap space 堆过小,或大量应该被清理的对象依旧被保持(内存泄露)
|
||||
|
||||
#### 2.3.2 虚拟机栈和本地方法栈溢出
|
||||
|
||||
如果栈深度大于允许最大深度—StackOverFlowError 定义大量局部变量(如递归),栈最少104k(jdk1.7.0_51)
|
||||
|
||||
如果扩展栈时无法申请到足够的空间—OutOfMemoryError:unable to create new native thread
|
||||
|
||||
因为每个线程都有独立的栈,所以在多线程环境下,每个线程的栈越大越容易发生内存溢出。
|
||||
|
||||
若不允许更换64位虚拟机(32位Win每个进程最多2GB内存),或者减少线程数量,那么减小最大堆或者减小最大栈反而能换取更多线程。
|
||||
|
||||
#### 2.3.3 方法区和运行时常量池溢出
|
||||
|
||||
java.lang.OutOfMemoryError: PermGen space 方法区过小、过多的动态代理或使用大量第三方jar文件,造成class文件过多,方法过多。
|
||||
|
||||
String.intern()是一个native方法,如果字符串常量池中已经包含一个equal此String对象的字符串,则返回常量池中的这个对象;否则,将此String对象包含的字符串添加到常量池中,并返回此常量池中对象的引用。(jdk1.6中,intern会将首次出现的String复制一个新的实例至常量池;而jdk1.7中会在常量池中记录首次出现的实例引用,不会复制)
|
||||
|
||||
groovy等jvm平台的动态语言会持续创建类来实现语言的动态性,极易发生该类型的溢出;包含大量jsp的应用、基于OSGI的应用也容易发生该溢出。
|
||||
|
||||
#### 2.3.4 本机直接内存溢出
|
||||
|
||||
HeapDump中看不到明显的异常,NIO可能引发这种异常
|
||||
|
||||
## 第三章、垃圾收集器与内存分配策略
|
||||
|
||||
### 3.1 对象已死吗?
|
||||
|
||||
#### 3.1.1 引用计数算法
|
||||
|
||||
给对象添加一个引用计数器,每产生一个对该对象的引用,计数器+1;引用失效时,计数器-1,计数器为0时,表示对象不可用.
|
||||
|
||||
但是主流的java虚拟机没有使用引用计数算法,主要因为它很难解决对象之间相互循环引用的问题。
|
||||
|
||||
#### 3.1.2 可达性分析算法
|
||||
|
||||
通过一系列“GC Roots”作为起始点向下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,证明此对象不可用.
|
||||
|
||||
java,C# ,List都是通过可达性分析来判断对象是否存活的.
|
||||
|
||||
在java语言中,可作为GC Roots的对象包括以下几种:
|
||||
|
||||
虚拟机栈(栈帧中的本地变量表)中引用的对象,
|
||||
|
||||
方法区中类静态属性引用的对象,
|
||||
|
||||
方法区中常量引用的对象,
|
||||
|
||||
本地方法栈中JNI(即native方法)引用的对象
|
||||
|
||||
#### 3.1.3 引用概念扩充,强度依次减弱:
|
||||
|
||||
* **强引用**(Strong Refrence)
|
||||
|
||||
Object obj = new Object(); 只要强引用还存在,GC永远不会回收.
|
||||
|
||||
* **软引用**(Soft Reference)
|
||||
|
||||
用来描述一些有用但不必需的对象,在系统将要发生内存溢出之前,GC会对软引用对象进行回收,若回收后仍没有足够内存,才会抛出异常。
|
||||
|
||||
JDK1.2之后提供了SoftReference 类来实现软引用
|
||||
|
||||
* **弱引用**(Weak Reference)
|
||||
|
||||
也是用来描述非必需对象的,但是强度比软引用更弱,弱引用对象只能生存到下一次GC发生之前,当GC工作时,无论内存是否足够,都会回收弱引用对象
|
||||
|
||||
JDK1.2之后提供了WeakReference 类来实现弱引用
|
||||
|
||||
* **虚引用**(Phantom Reference)
|
||||
|
||||
也称为幽灵引用或幻影引用,是最弱的一种引用关系。一个对象是否有虚引用存在,完全不会对其生存时间构成影响,也无法通过虚引用来获得一个实例。
|
||||
|
||||
为对象设置一个虚引用的唯一目的就是能在这个对象被GC回收时收到一个系统通知。
|
||||
|
||||
JDK1.2之后提供了PhantomReference 类来实现虚引用
|
||||
|
||||
#### 3.1.4 生存还是死亡
|
||||
|
||||
可达性分析算法中不可达的对象,并非是“非死不可”的,对象死亡需要一个过程:
|
||||
|
||||
(1)若不可达,筛选对象,若对象没有覆盖finalize()方法,或者finalize()已经执行过,将判定为没有必要执行(将跳过第2步);若判定为有必要执行,这个对象将放之在F-Queue队列中,并在稍后由一个虚拟机自动建立、低优先级的Finalizeer线程去执行。
|
||||
|
||||
(2)执行finalize()方法,只是触发,不会等待方法执行结束,目的是防止finalize执行时间过长或者发生死循环引起F-Queue中对象永久等待。
|
||||
|
||||
finalize方法是对象逃脱死亡的最后一次机会,若在finalize()方法中该对象被重新引用,该对象将被移出“即将回收集合”。
|
||||
|
||||
任何一个对象的finalize()方法只会被系统自动调用一次。该方法不确定性太高,建议不使用。
|
||||
|
||||
(3)回收对象
|
||||
|
||||
#### 3.1.5 回收方法区
|
||||
|
||||
(1)废弃常量和无用的类可以被回收
|
||||
|
||||
**废弃常量**:
|
||||
|
||||
系统中不存在对这个常量的引用
|
||||
|
||||
**无用的类**:
|
||||
|
||||
①该类的所有实例都被回收,也就是java堆中不存在该类的任何实例
|
||||
|
||||
②加载该类的ClassLoader已经被回收
|
||||
|
||||
③该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
|
||||
|
||||
(2)回收设置
|
||||
|
||||
-Xnoclassgc 不对类进行回收
|
||||
|
||||
-verbase:class -XX:+TraceClassLoading -XX:+TraceClassUnLoading 查看类的加载和卸载信息
|
||||
|
||||
其中-verbase:class -XX:+TraceClassLoading可以再Product版虚拟机使用,-XX:+TraceClassUnLoading需要FastDebug版支持
|
||||
|
||||
频繁自定义ClassLoader的场景都需要虚拟机具备类卸载功能,以保证永久代不会溢出。
|
||||
|
||||
### 3.2 垃圾收集算法
|
||||
|
||||
#### 3.2.1 标记-清除算法
|
||||
|
||||
先标记处所有需要回收的对象,标记完成后统一回收,这是最基础的收集算法,后续的收集算法都是基于这个思路改进的。
|
||||
|
||||
不足:①标记和清除两个过程效率都不高 ②会产生大量不连续的内存碎片,可能导致在创建大对象时,因没有足够的连续内存而触发另一次垃圾收集动作。
|
||||
|
||||
#### 3.2.2 复制算法
|
||||
|
||||
将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块survivor;当回收时,将Eden和survivor中还存活的对象一次性复制到另一块survivor中,最后清理掉Eden和刚才用过的survivor空间。
|
||||
|
||||
HotSpot默认Eden和survivor的大小比例为8:1(-XX:ServivorRatio=8设置比例),也就是每次新生代中可用内存为整个新生代容量的90%,只有10%会被浪费。
|
||||
|
||||
当survivor不够用时,需要依赖其他内存(老年代)进行分配担保。当survivor不够用时,这些对象将直接通过分配担保机制进入老年代。
|
||||
|
||||
>为什么需要两块Survivor?
|
||||
为了确保每次复制后,都必定有一块Survivor是空闲的。如果只有1个Survivor,将Eden复制到Survivor中然后清理Eden之后,还要将Survivor复制回Eden。
|
||||
|
||||
#### 3.2.3 标记-整理算法
|
||||
|
||||
标记过程与标记-清除算法相同,然后让所有对象向一端移动,最后清理掉端边界以外的内存。老年代适合这种算法。
|
||||
|
||||
#### 3.2.4 分代收集算法
|
||||
|
||||
根据对象存活周期不同,将内存分为几块,一般是把java堆分为新生代和老年代,这样可以根据年代特点选用合适的收集算法。
|
||||
|
||||
**新生代**:对象存活率低,选用复制算法
|
||||
|
||||
**老年代**:对象存活率高,没有额外空间进行分配担保,选用标记-清除或者标记-整理算法
|
||||
|
||||
### 3.3 HotSpot算法实现
|
||||
|
||||
#### 3.3.1 枚举根节点:
|
||||
|
||||
GC Roots 主要在全局性引用(常量或类静态属性)与执行上下文(栈帧中的本地变量表)中,若GC Roots过多(例如方法区数据过多),将消耗大量时间。
|
||||
|
||||
可达性分析时,整个系统的引用关系必须是不变的(一致性快照),因此必须停顿所有JAVA执行线程。
|
||||
|
||||
因为使用准确式GC,并不需要检查所有执行上下文和全局引用,虚拟机有办法知道哪些地方存放着对象引用。
|
||||
|
||||
缺陷--对执行时间敏感
|
||||
|
||||
#### 3.3.2 安全点(Safe Point):
|
||||
|
||||
只在安全点生成OopMap并"stop the world",因为要节省空间。
|
||||
|
||||
只在能让程序长时间执行的指令流(如方法调用、循环跳转、异常跳转)中选定安全点,因为安全点过少则GC等待时间过长,安全点过多则会增大运行负荷。
|
||||
|
||||
**抢先式中断**:gc发生时,先中断全部线程,若有线程不在安全点上,则恢复线程让其跑到安全点上。(几乎没有虚拟机使用)
|
||||
|
||||
**主动式中断**:gc发生时,不直接操作线程,在安全点和创建对象分配内存的位置设立一个标志,各个线程轮询这个标志,当中断标志位真时,自动中断挂起。
|
||||
|
||||
缺陷--在gc之前就已中断的线程无法进入安全点挂起,需通过安全区域来解决。
|
||||
|
||||
>线程中断有先后顺序,如何保证在错开的时间内引用关系不会发生改变?
|
||||
>
|
||||
>JAVA多线程是通过轮流切换实现的,一个线程执行时,其他线程都是阻塞的,不存在错开运行的情况;而且安全点设在长指令流中,不存在引用关系变化。
|
||||
|
||||
#### 3.3.3 安全区域(Safe Region):
|
||||
|
||||
在一段代码片段中,引用关系不会发生变化,在这个区域中的任意地方开始GC都是安全的,这个区域称为安全区域,可以看做扩展了的安全点。
|
||||
|
||||
当线程执行到 Safe Region 时,首先标记自己进入SafeRegion,当这段时间内要发起GC时可以不用关心SafeRegion状态的线程。
|
||||
|
||||
当线程要离开 Safe Region 时,它要检查系统是否完成了根节点枚举(或者是整个GC过程),如果完成了则线程继续运行,否则必须等待。
|
||||
|
||||
### 3.4 垃圾收集器
|
||||
|
||||
![gc][gc]
|
||||
|
||||
有连线表示可以搭配使用
|
||||
|
||||
#### 3.4.1 Serial收集器:
|
||||
|
||||
复制算法
|
||||
|
||||
最基本、最古老、单线程,工作时会停顿其他所有工作线程,因为简单且高效,所以作为Client模式下的默认新生代收集器。
|
||||
|
||||
#### 3.4.2 ParNew收集器:
|
||||
|
||||
复制算法
|
||||
|
||||
本质上是Serial收集器的并行(多个垃圾处理线程并行工作,但是用户线程仍然等待)多线程版本,指定CMS后的默认新生代收集器。
|
||||
|
||||
#### 3.4.3 Parallel Scavenge收集器:
|
||||
|
||||
复制算法
|
||||
|
||||
并行多线程
|
||||
|
||||
关注于使CUP达到可控的吞吐量(运行用户代码的时间与JVM总运行时间的比值),高效利用CUP,适合于在后台运算不需要交互的任务。俗称“吞吐量优先收集器”
|
||||
|
||||
`-XX:MaxGCPauseMillis` 控制最大垃圾收集停顿时间,大于0的毫秒数,这个值越小,新生代越小,吞吐量越小;
|
||||
|
||||
`-XX:GCTimeRatio` 设置吞吐量大小,大于0小于100的整数n,最大允许垃圾收集时间比例为 1/(1+n),n默认为99,即最大立即收集时间为1%
|
||||
|
||||
`-XX:UseAdaptiveSizePolicy` 开关参数,使用GC自适应调节策略
|
||||
|
||||
#### 3.4.4 Serial Old收集器:
|
||||
|
||||
标记-整理算法
|
||||
|
||||
Serial收集器老年代版本,单线程。
|
||||
|
||||
#### 3.4.5 Parallel Old收集器:
|
||||
|
||||
标记-整理算法
|
||||
|
||||
Parallel Scavenge收集器的老年代版本,多线程,
|
||||
|
||||
在出现该收集器之前Parallel Scavenge只能与Serial Old搭配使用,但是Serial Old会拖累Parallel Scavenge,导致这种组合没有CMS+ParNew给力
|
||||
|
||||
在注重**吞吐量**以及**CPU资源**的场合,应该优先考虑Parallel Scavenge + Parallel Old组合。
|
||||
|
||||
#### 3.4.6 CMS收集器:
|
||||
|
||||
hotspot中的第一款并发收集器,可以与用户线程同时工作
|
||||
|
||||
标记-清除算法,分4个步骤
|
||||
|
||||
①初始标记 标记GC能关联的对象
|
||||
|
||||
②并发标记
|
||||
|
||||
③重新标记 修正并发标记期间因程序继续运作而导致标记变动的一部分对象的标记记录
|
||||
|
||||
④并发清除
|
||||
|
||||
①③仍需停顿,但耗时短②④耗时长,但可以与用户线程一起工作
|
||||
|
||||
以最短回收停顿时间为目标的收集器。也称“并发低停顿收集器”
|
||||
|
||||
>3个缺点:
|
||||
>
|
||||
>* 对CPU资源敏感,面向并发的程序都对CPU资源敏感,在并发阶段(②④)会占用一部分线程(默认(cpu数量+3)/4)导致应用程序变慢,吞吐量变小。
|
||||
>
|
||||
>* 无法处理浮动垃圾,在④阶段,用户线程还活着,那么在标记之后可能产生新的垃圾,这部分垃圾只能留给下一次GC回收,称为“浮动垃圾”。
|
||||
|
||||
因为CMS收集同时用户线程也需要空间来运行,所以要预留足够空间给用户线程使用,所以老年代使用68%(1.6中为92%)空间后就会激活CMS。
|
||||
|
||||
-XX:CMSInitiatingOccupancyFraction 设置激活CMS的内存百分比,
|
||||
|
||||
设高了可以减少GC次数提高性能,但是更容易出现因预留空间无法满足用户程序的情况而临时启用Serial Old反而降低性能的情况。
|
||||
|
||||
>* 基于标记-清除算法,会产生大量空间碎片。
|
||||
>
|
||||
-XX:UseCMSCompactAtFullCollection 当CMS触发Full GC时对内存碎片进行合并整理,无法并发,停顿会变长。
|
||||
>
|
||||
>-XX:CMSFullGCsBeforeCompaction 设置执行多少次不整理的Full GC后执行一次整理的Full GC,默认值为0,表示每次Full GC都会整理。
|
||||
|
||||
#### 3.4.7 G1收集器
|
||||
|
||||
标记-整理算法
|
||||
|
||||
面向服务端应用,特点:
|
||||
|
||||
(1)并行与并发,利用多个CPU减少停顿时间,总体上可以与用户线程并发执行。
|
||||
|
||||
(2)分代收集,不需要与其他收集器配合,可以采用不同的方式处理垃圾。
|
||||
|
||||
(3)空间整合,虽然整体上采用标记-整理算法,但是局部(两个Region之间)上采用复制算法,不会产生内存空间碎片。
|
||||
|
||||
(4)可预测的停顿,能够让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集的上的时间不得超过N毫秒。
|
||||
|
||||
使用G1时,java堆被分为多个大小相等的独立区域(Region),新生代和老年代不再是物理隔离,而是一部分Region的集合。
|
||||
|
||||
能够预测停顿时间的原因:有计划地避免在整个java堆中进行全区域的垃圾收集,G1跟踪各个Region里垃圾的价值大小,在后台维护一个优先列表,
|
||||
|
||||
每次根据允许的收集时间优先收集价值最大的Region。
|
||||
|
||||
每个Region对应一个Rememberd Set,当程序对Reference类型进行写操作时,将会检测Reference引用的对象是否处于不同的Region中,
|
||||
|
||||
如果是,就会将相关引用信息写入对象所属Region的Remeberd Set中,当内存回收时,GC根节点的枚举范围加入Remeberd Set就不必对全堆扫描。
|
||||
|
||||
G1运作步骤:初始标记, 并发标记, 最终标记(修正变动,需停顿,可并行), 筛选回收。
|
||||
|
||||
#### 3.4.8 GC日志
|
||||
|
||||
`-XX:+PrintGCDetails` 开启垃圾回收日志
|
||||
|
||||
>33.125:[GC[DefNew:3324K->152K(3712K),0.0025925 secs]3324K-152K(11904K),0.0031680 secs]
|
||||
|
||||
`33.125`:虚拟机启动以来经过的秒数
|
||||
|
||||
"`[GC`"或者"`[Full GC`":停顿类型后者表示发生了Stop The World,如果是调用System.gc()方法触发的收集,将会显示为:"[Full GC (System)"
|
||||
|
||||
`DefNew`:GC发生的区域,该名称与垃圾收集器相关,DefNew为Serial收集器新生代区域
|
||||
|
||||
`3324K->152K(3712K)`:GC前该**区域**已使用容量->GC后该区域已使用容量(该区域总容量)
|
||||
|
||||
`0.0025925 secs`:该区域GC占用的时间
|
||||
|
||||
`3324K->152K(11904K)`:GC前java**堆**已使用的容量->GC后java堆已使用的容量(java堆总容量)
|
||||
|
||||
#### 3.4.9 垃圾收集器参数
|
||||
|
||||
![arg0][arg0]
|
||||
|
||||
![arg1][arg1]
|
||||
|
||||
### 3.5 内存分配与回收策略
|
||||
|
||||
#### 3.5.1 对象优先在Eden分配
|
||||
|
||||
Minor GC:新生代GC,对象大多朝生夕灭,GC非常频繁,回收速度较快。
|
||||
|
||||
Full GC/Major GC:老年代GC,经常会伴随至少一次Minor GC,速度一般比Minor GC慢10倍以上。
|
||||
|
||||
#### 3.5.2 大对象直接进入老年代
|
||||
|
||||
典型:很长的字符串以及数组
|
||||
|
||||
`-XX:PretenureSizeThreshold=3145728`(不能写成3MB,只对Serial和ParNew有效),令大于这个设置值的对象直接在老年代分配,目的是避免在Eden以及两个Servivor区发生大量的内存复制。
|
||||
|
||||
创建大对象时容易触发GC,即时此时还有大量的空间, 应尽量避免创建短命的大对象。
|
||||
|
||||
#### 3.5.3 长期存活的对象进入老年代
|
||||
|
||||
jvm给每个对象定义了一个年龄计数器。
|
||||
|
||||
如果对象在Eden出生并经过第一次Minor GC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor中,并将年龄设置为1。
|
||||
|
||||
对象在Survivor中每"熬过"一次Minor GC,年龄就+1,当年龄增加到15(默认)时,将在下一次GC被晋升到老年代中。
|
||||
|
||||
`-XX:MaxTenuringThreshold=15` 设置对象晋升老年代的阈值。
|
||||
|
||||
`-XX:+PrintTenuringDistribution` 显示更详细的GC信息
|
||||
|
||||
#### 3.5.4 动态对象年龄判定
|
||||
|
||||
如果在Survivor中相同年龄对象大小的总和大于Survivor大小的一半,年龄大于或等于该大小的对象就可以直接进入老年代,无需增长MaxTenuringThreshold。
|
||||
|
||||
#### 3.5.5 空间担保分配
|
||||
|
||||
发生Minor GC前,JVM会检查老年代最大可用连续内存是否大于新生代所有对象总大小,
|
||||
|
||||
如果这个条件成立,Minor GC可以确保是安全的。
|
||||
|
||||
如果不成立,虚拟机会查看`HandlePromotionFailure`设置是否允许担保失败。
|
||||
|
||||
如果不允许,将进行一次Full GC。
|
||||
|
||||
如果允许,那么会继续检查老年代最大可以连续空间是否大于历次晋升到老年代对象的平均大小.
|
||||
|
||||
如果小于,将进行一次Full GC。
|
||||
|
||||
如果大于,将尝试进行一次Minor GC,尽管这次GC是有风险的。
|
||||
|
||||
如果尝试失败,将进行一次Full GC。
|
||||
|
||||
所谓风险:Minor GC时,Survivor中无法容纳的对象将担保分配至老年代,如果本次GC时新生代对象超过平均大小,因为具体超过多少是未知的,老年代将可能无法容纳这些对象。
|
||||
|
||||
|
||||
|
||||
[java]: {{"/java-system.png" | prepend: site.imgrepo }}
|
||||
[runtime]: {{"/jvm-runtime.png" | prepend: site.imgrepo }}
|
||||
[handle]: {{"/jvm-handle.png" | prepend: site.imgrepo }}
|
||||
[point]: {{"/jvm-point.png" | prepend: site.imgrepo }}
|
||||
[gc]: {{"/jvm-gc.png" | prepend: site.imgrepo }}
|
||||
[arg0]: {{"/jvm-arg0.png" | prepend: site.imgrepo }}
|
||||
[arg1]: {{"/jvm-arg1.png" | prepend: site.imgrepo }}
|
||||
@@ -1,433 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 八种排序
|
||||
tags: 算法 algorithm 排序
|
||||
categories: algorithm
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
![八大排序][八大排序]
|
||||
|
||||
<br/>
|
||||
|
||||
## 1.直接插入排序
|
||||
|
||||
基本思想:在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
|
||||
|
||||
![插入排序][插入排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 形象描述:踢馆
|
||||
* 直接插入排序(从小到大)
|
||||
* @param src 待排序的数组
|
||||
*/
|
||||
public void straight_insertion_sort(int[] src){
|
||||
int tmp;
|
||||
for (int i = 0; i < src.length; i++) {
|
||||
tmp = src[i];
|
||||
int j = i - 1;
|
||||
//向前匹配,凡是比自己大的都往后移一位,碰到不比自己大的直接跳出
|
||||
for (; j >= 0 && tmp<src[j] ; j--) {
|
||||
src[j+1] = src[j];
|
||||
}
|
||||
//j-1位置匹配失败,在后一位插入
|
||||
src[j+1] = tmp;
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 2.希尔排序(缩小增量排序)
|
||||
|
||||
基本思想:算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差d.对每组中相同位置的元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,再对每组中相同位置的元素进行直接插入排序。当增量减到1时,进行直接插入排序后,排序完成。
|
||||
|
||||
![希尔排序][希尔排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 希尔排序(缩小增量排序)(从小到大)
|
||||
* @param src
|
||||
*/
|
||||
public void shell_sort(int[] src){
|
||||
int inc = src.length;
|
||||
int tmp;
|
||||
while(true){
|
||||
inc = (int)Math.ceil(inc/2);//增量,亦即每组长度
|
||||
//遍历每组进行排序的元素索引,具体看内部注释
|
||||
for (int x = 0; x < inc; x++) {
|
||||
//以下内容即插入排序,但是搜索头步进inc,回顾时步退inc
|
||||
//这是一个模拟,可以想象为:将src分组,每组长度为inc,然后对每组的第0,1,2,3...个元素分别进行插入排序
|
||||
//即:第二组的第一个元素与第一组的第一个元素进行插入排序,第三组的第一个元素与第一二组的第一个元素进行插入排序...
|
||||
// 第二组的第二个元素与第一组的第二个元素进行插入排序,第三组的第二个元素与第一二组的第二个元素进行插入排序...
|
||||
// ...
|
||||
for (int i = x + inc; i < src.length; i += inc) {
|
||||
tmp = src[i];
|
||||
int j = i - inc;
|
||||
for (; j >= 0 && tmp < src[j]; j-=inc) {
|
||||
src[j + inc] = src[j];
|
||||
}
|
||||
src[j + inc] = tmp;
|
||||
}
|
||||
}
|
||||
//不必担心增量为1时会完全等同于普通的直接插入排序,进而造成性能问题
|
||||
//原因:在排序过程中匹配时遵循"小者胜,大者让"的原则,因此在搜索头进行回顾匹配时,会很快(1~2个元素左右)碰上不久前刚刚打败过自己的对手.
|
||||
if(inc == 1){
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 3.简单选择排序
|
||||
|
||||
基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
|
||||
|
||||
![简单选择排序][简单选择排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 简单选择排序(从小到大)
|
||||
* @param src
|
||||
*/
|
||||
public void select_sort(int[] src){
|
||||
int pos,tmp,j; //定义最小值索引,最小值缓存,最小值检索起点索引
|
||||
//在每个i位置放入合适的值:i==0时放最小值;i==1时放第二小的值...
|
||||
for (int i = 0; i < src.length; i++) {
|
||||
//假定i位置的值就是合适的值
|
||||
tmp = src[i];
|
||||
pos = i;
|
||||
//检索i之后的所有元素(前面的元素都比i位置的小),找到一个最小的,与i位置的元素换位
|
||||
for (j = i+1; j < src.length; j++) {
|
||||
if(src[j] < tmp){
|
||||
tmp = src[j];
|
||||
pos = j;
|
||||
}
|
||||
}
|
||||
src[pos] = src[i];
|
||||
src[i] = tmp;
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 4.堆排序
|
||||
|
||||
基本思想:构建一个大顶堆完全二叉树,此时整个二叉树是无序的,二叉树中的无序部分称为堆,堆顶为最大值。将堆中的末尾节点与堆顶节点互换,将刚换到末尾的节点踢出堆(刚被换到末尾的节点与之前被换到末尾的节点之间将是有序的),调整剩余节点,使其满足大顶堆的要求。以此类堆,最后堆将消失,得到一组正序排列的节点。
|
||||
|
||||
建堆:
|
||||
|
||||
![堆排序1][堆排序1]
|
||||
|
||||
交换,从堆中踢出最大数
|
||||
|
||||
![堆排序2][堆排序2]
|
||||
|
||||
剩余结点再建堆,再交换踢出最大数
|
||||
|
||||
![堆排序3][堆排序3]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 调整堆
|
||||
* @param src 存放节点的数组,节点号从1开始
|
||||
* @param i 调整起点节点号
|
||||
* @param size 有效节点长度
|
||||
*/
|
||||
private void adjHeap(int[] src,int i,int size){
|
||||
int lc = 2*i;//左子节点号
|
||||
int rc = 2*i + 1;//右子节点号
|
||||
int mx = i;//最大值节点号
|
||||
//非叶节点最大序号为size/2
|
||||
if(i<=size/2){
|
||||
//如果左子节点存在,且大于最大节点
|
||||
if(lc<=size && src[lc-1]>src[mx-1]){
|
||||
mx = lc;
|
||||
}
|
||||
//如果右子节点存在,且大于最大节点
|
||||
if(rc<=size && src[rc-1]>src[mx-1]){
|
||||
mx = rc;
|
||||
}
|
||||
//表示节点关系需要变化
|
||||
if(mx!=i){
|
||||
swap(src,mx,i);
|
||||
adjHeap(src,mx,size);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* 交换节点
|
||||
* @param src 存放节点的数组,节点号从1开始
|
||||
* @param p 前一个节点号
|
||||
* @param n 后一个节点号
|
||||
*/
|
||||
private void swap(int[] src,int p, int n){
|
||||
int tmp = src[p-1];
|
||||
src[p-1] = src[n-1];
|
||||
src[n-1] = tmp;
|
||||
}
|
||||
|
||||
/**
|
||||
* 创建初始堆
|
||||
* @param src 存放节点的数组,节点号从1开始
|
||||
* @param size 有效节点长度
|
||||
*/
|
||||
private void buildHeap(int[] src, int size){
|
||||
for(int i=size/2; i>=1; i--){
|
||||
adjHeap(src,i,size);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* 最大堆排序(从小到大)
|
||||
* @param src
|
||||
*/
|
||||
public void heap_sort(int[] src){
|
||||
int size = src.length;
|
||||
buildHeap(src,size);
|
||||
for(int i=size; i>=1; i--){
|
||||
swap(src,1,i);
|
||||
adjHeap(src,1,i-1);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 5.冒泡排序
|
||||
|
||||
基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,由始至终对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。
|
||||
|
||||
![冒泡排序][冒泡排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 冒泡排序(从小到大)
|
||||
* @param src
|
||||
*/
|
||||
public void bubble_sort(int[] src){
|
||||
int tmp;
|
||||
//移动测头
|
||||
for (int i = 0; i < src.length; i++) {
|
||||
//从测头向前推进,若相邻元素前者大于后者,则两者换位
|
||||
for (int j = i; j > 0; j--) {
|
||||
if(src[j] < src[j-1]){
|
||||
tmp = src[j];
|
||||
src[j] = src[j-1];
|
||||
src[j-1] = tmp;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 6.快速排序
|
||||
|
||||
基本思想:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。
|
||||
|
||||
![快速排序][快速排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* 快速排序(从小到大)
|
||||
* @param src
|
||||
*/
|
||||
public void quick_sort(int[] src){
|
||||
doSort(src,0,src.length-1);
|
||||
}
|
||||
|
||||
/**
|
||||
* @param src 数组对象
|
||||
* @param bi 有效位开头
|
||||
* @param ei 有效位结尾
|
||||
* @return
|
||||
*/
|
||||
private int getMiddle(int[] src, int bi, int ei){
|
||||
//缓存开头的元素作为中轴
|
||||
int tmp = src[bi];
|
||||
while(bi < ei){
|
||||
//从右向左开始对比,不比中轴小的元素跳过,并继续向左推进
|
||||
while(bi < ei && src[ei] >= tmp){
|
||||
ei--;
|
||||
}
|
||||
//能够执行到这里,表示src[ei]<tmp,那么ei位元素应该被放到tmp元素左边,
|
||||
//但是tmp左边可能有多个元素,该放在什么位置暂时未知,先放在低于tmp的元素区的开头即bi位
|
||||
//bi位元素已缓存为tmp,不会丢失
|
||||
src[bi] = src[ei];
|
||||
//从左向右开始对比,不比中轴大的元素跳过,并继续向右推进
|
||||
while(bi < ei && src[bi] <= tmp){
|
||||
bi++;
|
||||
}
|
||||
//原理同上,ei位元素在之前已经复制到bi位,ei位已经没有意义了
|
||||
src[ei] = src[bi];
|
||||
}
|
||||
src[bi] = tmp;
|
||||
return bi;
|
||||
}
|
||||
|
||||
/**
|
||||
* @param src 数组对象
|
||||
* @param bi 有效位开头
|
||||
* @param ei 有效位结尾
|
||||
*/
|
||||
private void doSort(int[] src, int bi, int ei){
|
||||
if(bi >= ei) return;
|
||||
int mid = getMiddle(src,bi,ei);
|
||||
doSort(src,bi,mid-1);
|
||||
doSort(src,mid+1,ei);
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 7.归并排序
|
||||
|
||||
基本思想:归并排序法是将两个以上有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列
|
||||
|
||||
![归并排序][归并排序]
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* @param src 数组对象
|
||||
* @param bi 有效位开头
|
||||
* @param ei 有效位结尾
|
||||
*/
|
||||
private void doSort(int[] src, int bi, int ei){
|
||||
if(bi >= ei) return;
|
||||
int mid = (bi + ei)/2;
|
||||
doSort(src, bi, mid);
|
||||
doSort(src, mid + 1, ei);
|
||||
merge(src, bi, mid, ei);
|
||||
}
|
||||
|
||||
/**
|
||||
* @param src 数组对象
|
||||
* @param bi 有效位开头
|
||||
* @param mid 有效位中点
|
||||
* @param ei 有效位结尾
|
||||
*/
|
||||
private void merge(int[] src, int bi, int mid, int ei){
|
||||
int[] tmp = new int[ei-bi+1];
|
||||
int ti = 0; //tmp数组的索引
|
||||
int fbi = bi; //前半段的起点
|
||||
int bbi = mid + 1;//后半段的起点
|
||||
while (fbi<=mid&&bbi<=ei) {
|
||||
if(src[fbi] <= src[bbi]){
|
||||
//更小的元素将先被放入tmp,然后再对比下一个
|
||||
//因为是递归方法,所以前半段是有序的,后半段也是有序的,
|
||||
//所以前半段的第一个元素比后半段的第一个元素小,那么前半段的第一个元素一定是最小的
|
||||
//比较大小往tmp中插入的过程其实类似选择排序+希尔排序
|
||||
tmp[ti++] = src[fbi++];
|
||||
}else{
|
||||
tmp[ti++] = src[bbi++];
|
||||
}
|
||||
}
|
||||
//有序元素放入tmp后,前半段的游标可能没有到头(因为后半段的可能先到头了)
|
||||
while (fbi<=mid){
|
||||
tmp[ti++] = src[fbi++];
|
||||
}
|
||||
//有序元素放入tmp后,后半段的游标可能没有到头(因为前半段的可能先到头了)
|
||||
while (bbi<=ei){
|
||||
tmp[ti++] = src[bbi++];
|
||||
}
|
||||
//用tmp中排好序的元素替换掉src中指定范围的元素
|
||||
for (ti = 0; ti < tmp.length; ti++) {
|
||||
src[bi+ti] = tmp[ti];
|
||||
}
|
||||
}
|
||||
|
||||
public void merge_sort(int[] src){
|
||||
doSort(src,0,src.length-1);
|
||||
}
|
||||
~~~
|
||||
|
||||
<br/>
|
||||
|
||||
## 8.基数排序
|
||||
|
||||
基本思想:创建0-9十个容器,对数组中每个数取其相同位的数字,将数组元素放入到对应的容器中,然后按容器顺序从容器中取出放回数组,以此类推当位数递增到最大数的位宽时,排序完成
|
||||
|
||||
![基数排序][基数排序]
|
||||
|
||||
~~~java
|
||||
public void radix_sort(int[] src){
|
||||
//取最大值
|
||||
int max = src[0];
|
||||
for (int i = 0; i < src.length; i++) {
|
||||
max = src[i] > max ? src[i] : max;
|
||||
}
|
||||
//取最大值的位数
|
||||
int w = 0;
|
||||
while (max>0){
|
||||
max/=10;
|
||||
w++;
|
||||
}
|
||||
//创建十个队列,用二维数组模拟
|
||||
int[][] bkt = new int[10][src.length];
|
||||
|
||||
//记录每个bkt队列中有几个src元素
|
||||
int[] cm = new int[10];
|
||||
|
||||
for (int i = 0; i < w; i++) {
|
||||
//遍历元素,按元素的第i位数值分类排放
|
||||
for (int j = 0; j < src.length; j++) {
|
||||
int item = src[j];
|
||||
//求src中第j(从0开始)个元素的第i(从0开始)位数字
|
||||
//例如987的第1位数字是(987%100)/10
|
||||
int l = (item % (int)Math.pow(10,i+1))/(int)Math.pow(10,i);
|
||||
//bkt第l个队列可能有多个数据,用现有的数量表示位置
|
||||
bkt[l][cm[l]] = item;
|
||||
//位置后移1位
|
||||
cm[l] += 1;
|
||||
}
|
||||
//重新取出放回src
|
||||
//记录已经取出的个数
|
||||
int count = 0;
|
||||
for (int j = 0; j < 10; j++) {
|
||||
//第i位为j的元素的个数
|
||||
int cml = cm[j];
|
||||
while (cm[j] > 0){
|
||||
//j从小到大递增,这样取数据将使src具有递增趋势
|
||||
//将这样的元素存入bkt,将使bkt中每个队列都具有递增趋势
|
||||
//为了不破换这样的趋势,将需要从每个bkt队列的开头开始取数据
|
||||
src[count] = bkt[j][cml-cm[j]];
|
||||
//减去一个元素
|
||||
cm[j] -= 1;
|
||||
count++;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
[八大排序]:http://my.csdn.net/uploads/201205/12/1336792573_1570.png
|
||||
|
||||
[插入排序]:http://my.csdn.net/uploads/201205/12/1336792682_4218.png
|
||||
|
||||
[希尔排序]:http://my.csdn.net/uploads/201205/12/1336792712_3691.png
|
||||
|
||||
[简单选择排序]:http://my.csdn.net/uploads/201205/12/1336793705_2932.png
|
||||
|
||||
[堆排序1]:http://my.csdn.net/uploads/201205/12/1336793950_6973.png
|
||||
|
||||
[堆排序2]:http://my.csdn.net/uploads/201205/12/1336793977_2095.png
|
||||
|
||||
[堆排序3]:http://my.csdn.net/uploads/201205/12/1336793996_7183.png
|
||||
|
||||
[冒泡排序]:http://my.csdn.net/uploads/201205/12/1336807392_9769.png
|
||||
|
||||
[快速排序]:http://my.csdn.net/uploads/201205/12/1336807447_1275.png
|
||||
|
||||
[归并排序]:http://my.csdn.net/uploads/201205/12/1336807959_9188.png
|
||||
|
||||
[基数排序]:http://my.csdn.net/uploads/201205/12/1336807988_2428.png
|
||||
@@ -1,64 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Bitmap
|
||||
tags: 算法 algorithm Bitmap
|
||||
categories: algorithm
|
||||
---
|
||||
|
||||
# bitmap
|
||||
|
||||
所谓bitmap就是用一个bit位来标记某个元素对应的value,而key即是这个元素。由于采用bit为单位来存储数据,因此在可以大大的节省存储空间
|
||||
|
||||
## 算法思想
|
||||
|
||||
32位机器上,一个整形,比如 `int a;` 在内存中占32bit,可以用对应的32个bit位来表示十进制的0-31个数,bitmap算法利用这种思想处理大量数据的排序与查询
|
||||
|
||||
优点:
|
||||
|
||||
* 效率高,不许进行比较和移位
|
||||
|
||||
* 占用内存少,比如有N=10000000个正整数,用bit存储占用内存为N/8 = 1250000Bytes = 1.2M,如果采用int数组存储,则需要38M以上
|
||||
|
||||
缺点:
|
||||
|
||||
无法对存在重复的数据进行排序和查找,因为key唯一,value只有0/1
|
||||
|
||||
示例:
|
||||
|
||||
申请一个int型的内存空间,则有4Byte,32bit。输入 4, 2, 1, 3时:
|
||||
|
||||
![bitmap][bitmap]
|
||||
|
||||
思想比较简单,关键是十进制和二进制bit位需要一个map映射表,把10进制映射到bit位上
|
||||
|
||||
## map映射表
|
||||
|
||||
假设需要排序或者查找的总数N=10000000,那么我们需要申请的内存空间为 int a[N/32 + 1]。其中a[0]在内存中占32位,依此类推:
|
||||
|
||||
bitmap表为:
|
||||
|
||||
a[0] ------> 0 - 31
|
||||
|
||||
a[1] ------> 32 - 63
|
||||
|
||||
a[2] ------> 64 - 95
|
||||
|
||||
a[3] ------> 96 - 127
|
||||
|
||||
......
|
||||
|
||||
## 位移转换
|
||||
|
||||
(1) 求十进制数0-N对应的在数组a中的下标
|
||||
|
||||
`index_loc = N / 32`即可,index_loc即为n对应的数组下标。例如n = 76, 则loc = 76 / 32 = 2,因此76在a[2]中。
|
||||
|
||||
(2)求十进制数0-N对应的bit位
|
||||
|
||||
`bit_loc = N % 32`即可,例如 n = 76, bit_loc = 76 % 32 = 12
|
||||
|
||||
(3)利用移位0-31使得对应的32bit位为1
|
||||
|
||||
`int[index_loc] << bit_loc`
|
||||
|
||||
[bitmap]: {{"/bitmap.jpg" | prepend: site.imgrepo }}
|
||||
@@ -1,42 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 告别rm,自制回收站
|
||||
tags: trash shell Linux script
|
||||
categories: linux
|
||||
---
|
||||
|
||||
常在河边走,哪有不湿鞋?命令敲多了,总会手欠的,笔者刚在不久前尝到了`rm`命令带来的苦果,于是一怒之下决定自制一个回收脚本,从此告别rm命令。
|
||||
|
||||
因为rm是落子无悔的,所以网上有一种做法是自制一个shell脚本,封装一些mv操作,并用这个新脚本替换原来的rm命令。本人不太赞成这种做法,一是因为rm是系统默认的命令,已经是一种事实上的标准,若胡乱改动其功能,难免会对依赖这个命令的程序造成影响;二是因为,改变了rm的删除行为后,系统就失去了彻底删除一个文件的能力,为了弥补又必须考虑从回收站中彻底删除文件的情形,反而将简单问题复杂化了。
|
||||
|
||||
我的做法非常简单,回收脚本直接作为一个新命令,使用的时候想删除就删除,想回收就回收,连从回收站恢复的功能都不需要,想恢复文件,自己用mv从回收站移出来就行了。
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
readonly trash_home=/tmp/trash
|
||||
|
||||
for target in "$@"
|
||||
do
|
||||
dest=${trash_home}`realpath $target | xargs dirname`
|
||||
|
||||
if [ ! -e ${dest} ]; then
|
||||
mkdir -p ${dest};
|
||||
fi
|
||||
|
||||
if [ -d $target ]; then
|
||||
mv -i $target ${dest};
|
||||
elif [ -f $target ]; then
|
||||
mv -i $target ${dest};
|
||||
fi
|
||||
done
|
||||
~~~
|
||||
|
||||
在`/etc/profile.d`目录新建文件`trash`,将以上代码粘贴进去,然后赋予其可执行权限。
|
||||
|
||||
命令运行效果应该如此:
|
||||
|
||||
![trash][trash]
|
||||
|
||||
[trash]: {{"/shell-trash.png" | prepend: site.imgrepo }}
|
||||
|
||||
@@ -1,536 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Java Concurrent
|
||||
tags: Java Concurrent
|
||||
categories: Java
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
线程拥有通过程序运行的独立的并发路径,并且每个线程都有自己的程序计数器,称为堆栈和本地变量。线程存在于进程中,它们与同一进程内的其他线程共享内存、文件句柄以及进程状态。
|
||||
|
||||
---
|
||||
|
||||
JDK 5.0 中的并发改进可以分为三组:
|
||||
|
||||
* JVM 级别更改。大多数现代处理器对并发对某一硬件级别提供支持,通常以 **compare-and-swap** (CAS)指令形式。CAS 是一种低级别的、细粒度的技术,它允许多个线程更新一个内存位置,同时能够检测其他线程的冲突并进行恢复。它是许多高性能并发算法的基础。在 JDK 5.0 之前,Java 语言中用于协调线程之间的访问的惟一原语是同步,同步是更重量级和粗粒度的。公开 CAS 可以开发高度可伸缩的并发 Java 类。这些更改主要由 JDK 库类使用,而不是由开发人员使用。
|
||||
|
||||
* 低级实用程序类 -- `锁定`和`原子类`。使用 CAS 作为并发原语,**ReentrantLock** 类提供与 synchronized 原语相同的锁定和内存语义,然而这样可以更好地控制锁定(如计时的锁定等待、锁定轮询和可中断的锁定等待)和提供更好的可伸缩性(竞争时的高性能)。大多数开发人员将不再直接使用 ReentrantLock 类,而是使用在 ReentrantLock 类上构建的高级类。
|
||||
|
||||
* 高级实用程序类。这些类实现并发构建块,每个计算机科学文本中都会讲述这些类 -- `信号`、`互斥`、`闩锁`、`屏障`、`交换程序`、`线程池`和`线程安全集合类`等。大部分开发人员都可以在应用程序中用这些类来替换许多同步、wait() 和 notify() 的使用,从而提高性能、可读性和正确性。
|
||||
|
||||
---
|
||||
|
||||
# 线程安全的类
|
||||
|
||||
* 首先它必须在单线程环境中正确运行。如果正确实现了类,那么说明它符合规范,对该类的对象的任何顺序的操作(公共字段的读写、公共方法的调用)都不应该:
|
||||
|
||||
* 使对象处于无效状态;
|
||||
|
||||
* 观察处于无效状态的对象;
|
||||
|
||||
* 违反类的任何变量、前置条件或后置条件。
|
||||
|
||||
* 而且,要成为线程安全的类,在从多个线程访问时,它必须继续正确运行,而不管运行时环境执行那些线程的调度和交叉,且无需对部分调用代码执行任何其他同步。
|
||||
|
||||
* 如果没有线程之间的某种明确协调,比如锁定,运行时可以随意在需要时在多线程中交叉操作执行。
|
||||
|
||||
* 在并发编程中,一种被普遍认可的原则就是:尽可能的使用**不可变对象**来创建简单、可靠的代码。
|
||||
|
||||
# Thread
|
||||
|
||||
* 任何一个时刻,对象的控制权(monitor)只能被一个线程拥有。
|
||||
|
||||
* 无论是执行对象的`wait`、`notify`还是`notifyAll`方法,必须保证当前运行的线程取得了该对象的控制权(monitor)。
|
||||
|
||||
* 如果在没有控制权的线程里执行对象的以上三种方法,就会报java.lang.IllegalMonitorStateException异常。
|
||||
|
||||
* JVM基于多线程,默认情况下不能保证运行时线程的时序性。
|
||||
|
||||
|
||||
## interrupt
|
||||
|
||||
* 当调用`th.interrput()`的时候,线程th的中断状态(interrupted status) 会被置位。我们可以通过Thread.currentThread().isInterrupted() 来检查这个布尔型的中断状态。
|
||||
|
||||
* **没有任何语言方面的需求要求一个被中断的程序应该终止**。中断一个线程只是为了引起该线程的注意,被中断线程可以决定如何应对中断。这说明interrupt中断的是线程的某一部分业务逻辑,前提是线程需要检查自己的中断状态(isInterrupted())。
|
||||
|
||||
* 当th被阻塞的时候,比如被`Object.wait`, `Thread.join`和`Thread.sleep`三种方法之一阻塞时, 调用它的interrput()方法,可想而知,没有占用CPU运行的线程是不可能给自己的中断状态置位的, 这就会产生一个InterruptedException异常。
|
||||
|
||||
## join
|
||||
|
||||
* join方法可以让一个线程**等待**另一个线程执行完成。
|
||||
|
||||
* 若t是一个正在执行的Thread对象,t.join() 将会使当前线程暂停执行并等待t执行完成。重载的join()方法可以让开发者自定义等待周期。然而,和sleep()方法一样join()方法依赖于操作系统的时间处理机制,你不能假定join()方法将会精确的等待你所定义的时长。
|
||||
|
||||
* 如同sleep()方法,join()方法响应中断并在中断时抛出InterruptedException。
|
||||
|
||||
## 同步
|
||||
|
||||
* 同步的构造方法没有意义,因为当这个对象被创建的时候,只有创建对象的线程能访问它。
|
||||
|
||||
* 静态方法是和类(而不是对象)相关的,所以线程会请求类对象(Class Object)的内部锁。因此用来控制类的**静态域**访问的锁不同于控制**对象**访问的锁。
|
||||
|
||||
* 如果类中的两个域需要同步访问,但是两个域没有什么关联,那么可以为两个域个创建一个私有的锁对象,使两个域能分别同步。
|
||||
|
||||
## 锁
|
||||
|
||||
* 死锁描述了这样一种情景,两个或多个线程永久阻塞,互相等待对方释放资源。
|
||||
|
||||
* 饥饿是指当一个线程不能正常的访问共享资源并且不能正常执行的情况。这通常在共享资源被其他“贪心”的线程长期占用时发生
|
||||
|
||||
* 一个线程通常会有会响应其他线程的活动。如果其他线程也会响应另一个线程的活动,那么就有可能发生活锁。同死锁一样,发生活锁的线程无法继续执行, 然而线程并没有阻塞, 他们在忙于响应对方无法恢复工作。
|
||||
|
||||
* wait方法,释放锁并挂起
|
||||
|
||||
* 如果在一个执行序列中,需要确定对象的状态,那么某个线程在执行这个序列时,需要获得所有这些对象的锁(如一来一回的相互鞠躬,必须保证不会同时鞠躬也不会同时静止)
|
||||
|
||||
|
||||
# 线程安全集合
|
||||
|
||||
* java.util.concurrent 包添加了多个新的线程安全集合类 `ConcurrentHashMap`, `CopyOnWriteArrayList`, `CopyOnWriteArraySet`
|
||||
|
||||
* JDK 5.0 还提供了两个新集合接口 -- `Queue` 和 `BlockingQueue`。Queue 接口与 List 类似,但它只允许从后面插入,从前面删除。BlockingQueue定义了一个先进先出的数据结构,当你尝试往满队列中添加元素,或者从空队列中获取元素时,将会阻塞或者超时。
|
||||
|
||||
* `ConcurrentMap`是java.util.Map的子接口,定义了一些有用的原子操作。移除或者替换键值对的操作只有当key存在时才能进行,而新增操作只有当key不存在时才能进行, 使这些操作原子化,可以避免同步。ConcurrentMap的标准实现是`ConcurrentHashMap`,它是`HashMap`的并发模式。
|
||||
|
||||
* `ConcurrentNavigableMap`是ConcurrentMap的子接口,支持近似匹配。ConcurrentNavigableMap的标准实现是`ConcurrentSkipListMap`,它是`TreeMap`的并发模式。
|
||||
|
||||
* 所有这些集合,通过 在集合里新增对象和访问或移除对象的操作之间,定义一个`happens-before`的关系,来帮助程序员避免内存一致性错误。
|
||||
|
||||
## CopyOnWrite
|
||||
|
||||
* Vector 的常见应用是存储通过组件注册的监听器的列表。当发生适合的事件时,该组件将在监听器的列表中迭代,调用每个监听器。为了防止ConcurrentModificationException,迭代线程必须复制列表或锁定列表,以便进行整体迭代,而这两种情况都需要大量的性能成本。
|
||||
|
||||
* CopyOnWriteArrayList及CopyOnWriteArraySet 类通过每次添加或删除元素时创建数组的新副本,避免了这个问题,但是进行中的迭代保持对创建迭代器时的副本进行操作。虽然复制也会有一些成本,但是在许多情况下,迭代要比修改多得多,在这些情况下,写入时复制要比其他备用方法具有更好的性能和并发性。
|
||||
|
||||
## ConcurrentHashMap
|
||||
|
||||
* `Hashtable` 和 `synchronizedMap` 所采取的获得同步的简单方法(同步 Hashtable 或者同步 Map 封装器对象中的每个方法)有两个主要的不足:
|
||||
|
||||
* 第一,这种方法对于可伸缩性是一种障碍,因为一次只能有一个线程可以访问 hash 表;
|
||||
|
||||
* 第二,这样仍不足以提供真正的线程安全性,许多公用的混合操作仍然需要额外的同步。虽然诸如 get() 和 put() 之类的简单操作可以在不需要额外同步的情况下安全地完成,但还是有一些公用的操作序列,例如迭代或者 put-if-absent(空则放入),需要外部的同步,以避免数据争用。
|
||||
|
||||
* 在大多数情况下,`ConcurrentHashMap` 是 Hashtable或 Collections.synchronizedMap(new HashMap()) 的简单替换。然而,其中有一个显著不同,即 ConcurrentHashMap 实例中的同步**不锁定**Map进行独占使用, 实际上,没有办法锁定 ConcurrentHashMap 进行独占使用,它被设计用于进行并发访问。为了使集合不被锁定进行独占使用,还提供了公用的混合操作的其他(原子)方法,如 **put-if-absent**。
|
||||
|
||||
* ConcurrentHashMap 返回的迭代器是弱一致的,意味着它们将不抛出ConcurrentModificationException ,将进行 "合理操作" 来反映迭代过程中其他线程对 Map 的修改。
|
||||
|
||||
## 队列
|
||||
|
||||
* `Queue` 接口比 List 简单得多,仅包含 put() 和 take() 方法,并允许比 LinkedList 更有效的实现。
|
||||
|
||||
* Queue 接口还允许实现来确定存储元素的顺序。`ConcurrentLinkedQueue` 类实现先进先出(first-in-first-out,FIFO)队列。`PriorityQueue` 类实现优先级队列(也称为堆),它对于构建调度器非常有用,调度器必须按优先级或预期的执行时间执行任务。
|
||||
|
||||
* 实现 Queue 的类是:
|
||||
|
||||
* `LinkedList` 已经进行了改进来实现 Queue。
|
||||
|
||||
* `PriorityQueue` 非线程安全的优先级队列(堆)实现,根据自然顺序或比较器返回元素。
|
||||
|
||||
* `ConcurrentLinkedQueue` 快速、线程安全的、无阻塞 FIFO 队列。
|
||||
|
||||
## 弱一致的迭代器
|
||||
|
||||
* java.util 包中的集合类都返回 `fail-fast` 迭代器,这意味着它们假设线程在集合内容中进行迭代时,集合不会更改它的内容。如果 fail-fast 迭代器检测到在迭代过程中进行了更改操作,那么它会抛出 **ConcurrentModificationException**,这是不可控异常。
|
||||
|
||||
* java.util.concurrent 集合返回的迭代器称为弱一致的(`weakly consistent`)迭代器。对于这些类,如果元素自从迭代开始已经删除,且尚未由 next() 方法返回,那么它将不返回到调用者。如果元素自迭代开始已经添加,那么它可能返回调用者,也可能不返回。在一次迭代中,无论如何更改底层集合,元素不会被返回两次。
|
||||
|
||||
|
||||
|
||||
# 线程池
|
||||
|
||||
* 管理一大组小任务的标准机制是**组合工作队列**和**线程池**。工作队列就是要处理的任务的队列,前面描述的 Queue 类完全适合。线程池是线程的集合,每个线程都提取公用工作队列。当一个工作线程完成任务处理后,它会返回队列,查看是否有其他任务需要处理。如果有,它会转移到下一个任务,并开始处理。
|
||||
|
||||
* 线程池为线程生命周期间接成本问题和资源崩溃问题提供了解决方案。
|
||||
* 通过对多个任务重新使用线程,创建线程的间接成本将分布到多个任务中。
|
||||
* 作为一种额外好处,因为请求到达时,线程已经存在,从而可以消除由创建线程引起的延迟, 因此,可以立即处理请求,使应用程序更易响应。
|
||||
* 而且,通过正确调整线程池中的线程数,可以强制超出特定限制的任何请求等待,直到有线程可以处理它,它们等待时所消耗的资源要少于使用额外线程所消耗的资源,这样可以防止资源崩溃。
|
||||
|
||||
# Executor 框架
|
||||
|
||||
* `Executor` 接口关注任务提交,确定执行策略。这使在部署时调整执行策略(队列限制、池大小、优先级排列等等)更加容易,更改的代码最少。
|
||||
|
||||
* 大多数 Executor 实现类还实现 `ExecutorService`接口,ExecutorService是Executor的子接口,它还管理执行服务的生命周期。这使它们更易于管理,并向生命可能比单独 Executor 的生命更长的应用程序提供服务。
|
||||
|
||||
* **执行策略**定义何时在哪个线程中运行任务,执行任务可能消耗的资源级别(线程、内存等等),以及如果执行程序超载该怎么办。
|
||||
|
||||
## ExecutorService
|
||||
|
||||
* `ExecutorService`接口在提供了execute方法的同时,新加了更加通用的`submit`方法。
|
||||
|
||||
* 通过submit方法返回的`Future`对象可以读取`Callable`任务的执行结果,或管理Callable任务和Runnable任务的状态。
|
||||
|
||||
* ExecutorService也提供了批量运行Callable任务的方法,ExecutorService还提供了一些关闭执行器的方法。
|
||||
|
||||
## ScheduledExecutorService
|
||||
|
||||
* `ScheduledExecutorService`扩展ExecutorService接口并添加了`schedule`方法。调用schedule方法可以在指定的延时后执行一个Runnable或者Callable任务。
|
||||
|
||||
* ScheduledExecutorService接口还定义了按照指定时间间隔定期执行任务的`scheduleAtFixedRate`方法和`scheduleWithFixedDelay`方法。
|
||||
|
||||
## Executors
|
||||
|
||||
`Executors类`包含用于构造许多不同类型的 Executor 实现的静态工厂方法:
|
||||
|
||||
* `newCachedThreadPool()` 创建不限制大小的线程池,但是当以前创建的线程可以使用时将重新使用那些线程。如果没有现有线程可用,将创建新的线程并将其添加到池中。已有 60 秒钟未被使用的线程将其终止并从缓存中删除。
|
||||
|
||||
* `newFixedThreadPool(int n)` 创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新线程将代替它执行后续的任务。
|
||||
|
||||
* `newSingleThreadExecutor()` 创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务, 此线程池保证所有任务的执行顺序按照任务的提交顺序执行。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。
|
||||
|
||||
* `newScheduledThreadPool(int n)` 创建一个大小无限的线程池, 此线程池支持定时以及周期性执行任务的需求。
|
||||
|
||||
* 如果上面的方法都不满足需要,可以尝试`ThreadPoolExecutor`或者`ScheduledThreadPoolExecutor`。
|
||||
|
||||
## 定制 ThreadPoolExecutor
|
||||
|
||||
通过使用包含 `ThreadFactory` 变量的工厂方法或构造函数的版本,可以定义线程的创建。ThreadFactory 是工厂对象,其构造执行程序要使用的新线程。
|
||||
|
||||
```java
|
||||
public class DaemonThreadFactory implements ThreadFactory {
|
||||
public Thread newThread(Runnable r) {
|
||||
Thread thread = new Thread(r);
|
||||
thread.setDaemon(true);
|
||||
return thread;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
有时,Executor 不能执行任务,因为它已经关闭或者因为 Executor 使用受限制队列存储等待任务,而该队列已满。在这种情况下,需要咨询执行程序的`RejectedExecutionHandler` 来确定如何处理任务:
|
||||
|
||||
* 抛出异常(默认情况),
|
||||
|
||||
* 放弃任务,
|
||||
|
||||
* 在调用者的线程中执行任务,
|
||||
|
||||
* 或放弃队列中最早的任务以为新任务腾出空间。
|
||||
|
||||
* `setRejectedExecutionHandler`可以设置拒绝的执行处理程序。
|
||||
|
||||
|
||||
## 需要特别考虑的问题
|
||||
|
||||
如果应用程序对特定执行程序进行了假设,那么应该在 Executor 定义和初始化的附近对这些进行说明,从而使善意的更改不会破坏应用程序的正确功能。
|
||||
|
||||
* 一些任务可能同时等待其他任务完成。在这种情况下,当线程池没有足够的线程时,如果所有当前执行的任务都在等待另一项任务,而该任务因为线程池已满不能执行,那么线程池可能会死锁。
|
||||
|
||||
* 一组线程必须作为共同操作组一起工作。在这种情况下,需要确保线程池能够容纳所有线程。
|
||||
|
||||
## 调整线程池
|
||||
|
||||
* 如果线程池太小,资源可能不能被充分利用,在一些任务还在工作队列中等待执行时,可能会有处理器处于闲置状态。
|
||||
|
||||
* 另一方面,如果线程池太大,则将有许多有效线程,因为大量有效线程使用内存,或者因为每项任务要比使用少量线程有更多上下文切换,性能可能会受损。
|
||||
|
||||
* Amdahl 法则提供很好的近似公式来确定线程池的大小:
|
||||
|
||||
>用 `WT` 表示每项任务的平均等待时间,`ST` 表示每项任务的平均服务时间(计算时间)。则 `WT/ST` 是每项任务等待所用时间的百分比。对于 N 处理器系统,池中可以近似有 `N*(1+WT/ST)` 个线程。
|
||||
|
||||
## Future 接口
|
||||
|
||||
* `Future` 接口允许表示已经完成的任务、正在执行过程中的任务或者尚未开始执行的任务。通过 Future 接口,可以尝试取消尚未完成的任务,查询任务已经完成还是取消了,以及提取(或等待)任务的结果值。
|
||||
|
||||
* `FutureTask` 类实现了 Future,并包含一些构造函数,允许将 Runnable 或 Callable和 Future 接口封装。因为 FutureTask 也实现 Runnable,所以可以只将 FutureTask 提供给 Executor。一些提交方法(如 `ExecutorService.submit()`)除了提交任务之外,还将返回 Future 接口。
|
||||
|
||||
* `Future.get()` 方法检索任务计算的结果, 如果任务尚未完成,那么 Future.get() 将被阻塞直到任务完成;如果任务已经完成,那么它将立即返回结果; 如果任务完成,但有异常,则抛出 ExecutionException。
|
||||
|
||||
## 使用 Future 构建缓存
|
||||
|
||||
该示例利用 ConcurrentHashMap 中的原子 `putIfAbsent()` 方法,确保仅有一个线程试图计算给定关键字的值。如果其他线程随后请求同一关键字的值,它仅能等待(通过 Future.get() 的帮助)第一个线程完成。因此两个线程不会计算相同的值。
|
||||
|
||||
```java
|
||||
public class Cache<K,V> {
|
||||
private ConcurrentMap<K,FutureTask<V>> map = new ConcurrentHashMap<>();
|
||||
private Executor executor = Executors.newFixedThreadPool(8);
|
||||
|
||||
static class Task<V> implements Callable<V>{
|
||||
@Override
|
||||
public V call() throws Exception {
|
||||
return null;
|
||||
}
|
||||
}
|
||||
|
||||
public V get(final K key) throws ExecutionException, InterruptedException {
|
||||
FutureTask<V> ft = map.get(key);
|
||||
if (ft == null) {
|
||||
ft = new FutureTask(new Task());
|
||||
FutureTask<V> old = map.putIfAbsent(key, ft);
|
||||
if (old == null){
|
||||
executor.execute(ft);
|
||||
}else{
|
||||
ft = old;
|
||||
}
|
||||
}
|
||||
return ft.get();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## CompletionService
|
||||
|
||||
* `CompletionService` 将执行服务与类似 Queue 的接口组合,从任务执行中删除任务结果的处理。CompletionService 接口包含用来提交将要执行的任务的 submit() 方法和用来询问下一完成任务的 `take()`/`poll()` 方法。
|
||||
|
||||
* CompletionService 允许应用程序结构化,使用 `Producer`/`Consumer` 模式,其中生产者创建任务并提交,消费者请求完成任务的结果并处理这些结果。CompletionService 接口由 `ExecutorCompletionService` 类实现,该类使用 Executor 处理任务并从 CompletionService 导出 `submit`/`poll`/`take` 方法。
|
||||
|
||||
* 下列代码使用 Executor 和 CompletionService 来启动许多任务,并使用第一个生成的非空结果,然后取消其余任务:
|
||||
|
||||
```java
|
||||
<V> V solve(Executor e, Collection<Callable<V>> tasks) throws InterruptedException, ExecutionException {
|
||||
CompletionService<V> ecs = new ExecutorCompletionService<>(e);
|
||||
List<Future<V>> futures = new ArrayList<>();
|
||||
V result = null;
|
||||
|
||||
try {
|
||||
tasks.forEach(p -> futures.add(ecs.submit(p)));
|
||||
for (int i = 0; i < tasks.size(); ++i) {
|
||||
V r = ecs.take().get();
|
||||
if (r != null) {
|
||||
result = r;
|
||||
break;
|
||||
}
|
||||
}
|
||||
} finally {
|
||||
for (Future<V> f : futures){
|
||||
f.cancel(true);
|
||||
}
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
```
|
||||
|
||||
## Fork/Join
|
||||
|
||||
* `fork/join`框架是ExecutorService接口的一种具体实现,目的是为了更好地利用多处理器带来的好处。它是为那些能够被递归地拆解成子任务的工作类型量身设计的。其目的在于能够使用所有可用的运算能力来提升你的应用的性能。
|
||||
|
||||
* 类似于ExecutorService接口的其他实现,fork/join框架会将任务分发给线程池中的工作线程。fork/join框架的独特之处在与它使用工作窃取(`work-stealing`)算法。完成自己的工作而处于空闲的工作线程能够从其他仍然处于忙碌(busy)状态的工作线程处窃取等待执行的任务。
|
||||
|
||||
* fork/join框架的核心是`ForkJoinPool`类,它是对`AbstractExecutorService`类的扩展。ForkJoinPool实现了工作偷取算法,并可以执行ForkJoinTask任务。
|
||||
|
||||
* 在Java SE 8中,java.util.`Arrays`类的一系列`parallelSort()`方法就使用了fork/join来实现。这些方法与sort()系列方法很类似,但是通过使用fork/join框架,借助了并发来完成相关工作, 在多处理器系统中,对大数组的并行排序会比串行排序更快。
|
||||
|
||||
* 其他采用了fork/join框架的方法还有java.util.`streams`包中的一些方法,此包是Java SE 8发行版中Project Lambda的一部分。
|
||||
|
||||
# 同步工具
|
||||
|
||||
## Semaphore
|
||||
|
||||
* `Semaphore` 类实现标准 Dijkstra 计数信号。计数信号可以认为具有一定数量的许可权,该许可权可以获得或释放。如果有剩余的许可权,`acquire()` 方法将成功,否则该方法将被阻塞,直到其他线程释放`release()`许可权, 线程一次可以获得多个许可权。
|
||||
|
||||
* 计数信号可以用于限制有权对资源进行并发访问的线程数。该方法对于实现资源池或限制 Web 爬虫(Web crawler)中的输出 socket 连接非常有用。
|
||||
|
||||
* 注意信号不跟踪哪个线程拥有多少许可权, 这由应用程序来决定,以确保何时线程释放许可权,该信号表示其他线程拥有许可权或者正在释放许可权,以及其他线程知道它的许可权已释放。
|
||||
|
||||
## 互斥
|
||||
|
||||
* 计数信号的一种特殊情况是**互斥**,或者互斥信号。互斥就是具有单一许可权的计数信号,意味着在给定时间仅一个线程可以具有许可权, 互斥可以用于管理对共享资源的独占访问。
|
||||
|
||||
* 虽然互斥许多地方与锁定一样,但互斥还有一个锁定通常没有的功能,就是互斥可以由不具有许可权的其他线程来释放, 这在死锁恢复时会非常有用。
|
||||
|
||||
## CyclicBarrier
|
||||
|
||||
* `CyclicBarrier` 类可以帮助同步,它允许一组线程等待整个线程组到达公共屏障点。CyclicBarrier 是使用整型变量构造的,其确定组中的线程数。当一个线程到达屏障时(通过调用 CyclicBarrier.`await()`),它会被阻塞,直到所有线程都到达屏障,然后在该点允许所有线程继续执行。
|
||||
|
||||
* CyclicBarrier可以重新使用, 一旦所有线程都已经在屏障处集合并释放,则可以将该屏障重新初始化到它的初始状态。 还可以指定在屏障处等待时的超时;如果在该时间内其余线程还没有到达屏障,则认为屏障被打破,所有正在等待的线程会收到 `BrokenBarrierException`。
|
||||
|
||||
* 下列代码将创建 CyclicBarrier 并启动一组线程,每个线程在到达屏障点前会打印出自己的名字,等待其他线程到齐后,将执行CyclicBarrier绑定的Runnable,该Runnable在每个屏障点只执行一次。
|
||||
|
||||
```java
|
||||
public static void main(String[] args){
|
||||
Runnable ready = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("ready");
|
||||
}
|
||||
};
|
||||
|
||||
CyclicBarrier cyclicBarrier = new CyclicBarrier(5, ready);
|
||||
|
||||
ExecutorService executor = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < 5; i++) {
|
||||
Runnable task = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
System.out.println(Thread.currentThread().getName());
|
||||
cyclicBarrier.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
} catch (BrokenBarrierException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
};
|
||||
executor.submit(task);
|
||||
}
|
||||
executor.shutdown();
|
||||
}
|
||||
```
|
||||
|
||||
## CountdownLatch
|
||||
|
||||
* `CountdownLatch` 类与 CyclicBarrier 相似,因为它的角色是对已经在它们中间分摊了问题的一组线程进行协调。它也是使用整型变量构造的,指明计数的初始值,但是与 CyclicBarrier 不同的是,CountdownLatch 不能重新使用。
|
||||
|
||||
* 其中,CyclicBarrier 是到达屏障的所有线程的大门,只有当所有线程都已经到达屏障或屏障被打破时,才允许这些线程通过。CountdownLatch 将到达和等待功能分离,任何线程都可以通过调用 `countDown()` 减少当前计数,这种方式不会阻塞线程,而只是减少计数。`await()` 方法的行为与 CyclicBarrier.await() 稍微有所不同,调用 await() 任何线程都会被阻塞,直到闩锁计数减少为零,在该点等待的所有线程才被释放,对 await() 的后续调用将立即返回。
|
||||
|
||||
* 当问题已经分解为许多部分,每个线程都被分配一部分计算时,CountdownLatch 非常有用。在工作线程结束时,它们将减少计数,协调线程可以在闩锁处等待当前这一批计算结束,然后继续移至下一批计算。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
int concurrency = 5;
|
||||
ExecutorService executor = Executors.newCachedThreadPool();
|
||||
|
||||
final CountDownLatch ready = new CountDownLatch(concurrency);
|
||||
final CountDownLatch start = new CountDownLatch(1);
|
||||
final CountDownLatch done = new CountDownLatch(concurrency);
|
||||
for(int i=0; i<concurrency; i++){
|
||||
executor.execute(new Runnable(){
|
||||
public void run(){
|
||||
ready.countDown();
|
||||
try {
|
||||
start.await();
|
||||
System.out.println(Thread.currentThread().getName() + "----done");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
done.countDown();
|
||||
}
|
||||
});
|
||||
}
|
||||
ready.await();
|
||||
System.out.println("all threads are ready");
|
||||
start.countDown();
|
||||
done.await();
|
||||
System.out.println("all threads finished");
|
||||
executor.shutdown();
|
||||
}
|
||||
```
|
||||
|
||||
## Exchanger
|
||||
|
||||
* `Exchanger` 类方便了两个共同操作线程之间的双向交换,就像具有计数为 2 的 CyclicBarrier,并且两个线程在都到达屏障时可以"交换"一些状态。(Exchanger 模式有时也称为聚集。)
|
||||
|
||||
* Exchanger 通常用于一个线程填充缓冲(通过读取 socket),而另一个线程清空缓冲(通过处理从 socket 收到的命令)的情况。当两个线程在屏障处集合时,它们交换缓冲。
|
||||
|
||||
* 下列代码说明了这项技术:
|
||||
|
||||
```java
|
||||
public static void main(String[] args){
|
||||
Exchanger<String> exchanger = new Exchanger<>();
|
||||
ExecutorService executor = Executors.newCachedThreadPool();
|
||||
|
||||
Runnable producer = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
for (int i = 0; i < 5; i++) {
|
||||
try {
|
||||
String data = "produce";
|
||||
System.out.println(Thread.currentThread().getName() + "-offer----" + data);
|
||||
exchanger.exchange(data);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
Runnable consumer = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
for (int i = 0; i < 5; i++) {
|
||||
try {
|
||||
String data = exchanger.exchange(null);
|
||||
System.out.println(Thread.currentThread().getName() + "-get----" + data);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
executor.execute(producer);
|
||||
executor.execute(consumer);
|
||||
executor.shutdown();
|
||||
}
|
||||
```
|
||||
|
||||
# Lock工具
|
||||
|
||||
* `Lock` 接口将内置监视器锁定的行为普遍化,允许多个锁定实现,同时提供一些内置锁定缺少的功能,如**计时**的等待、**可中断**的等待、锁定**轮询**、每个锁定有多个**条件**等待集合以及**无阻塞**结构的锁定。
|
||||
|
||||
* java.util.concurrent.`locks`包提供了复杂的锁, 锁对象作用非常类似同步代码使用的隐式锁, 每次只有一个线程可以获得锁对象。通过关联`Condition`对象,锁对象也支持`wait/notify`机制。
|
||||
|
||||
* 锁对象之于隐式锁最大的优势在于,它们**有能力收回获取锁的尝试**(如果获取锁失败,将不会继续请求,以免发生死锁)。如果当前锁对象不可用,或者锁请求超时(如果超时时间已指定),`tryLock`方法会收回获取锁的请求。如果在锁获取前,另一个线程发送了一个中断,`lockInterruptibly`方法也会收回获取锁的请求。
|
||||
|
||||
|
||||
## ReentrantLock
|
||||
|
||||
* `ReentrantLock` 是具有与隐式监视器锁定(使用 synchronized 方法和语句访问)相同的基本行为和语义的 Lock 的实现,但它具有扩展的能力。
|
||||
|
||||
* 在竞争条件下,ReentrantLock 的实现要比现在的 synchronized 实现更具有可伸缩性。这意味着当许多线程都竞争相同锁定时,使用 ReentrantLock 的吞吐量通常要比 synchronized 好。
|
||||
|
||||
* 虽然 ReentrantLock 类有许多优点,但是与同步相比,它有一个主要**缺点** -- 它可能忘记释放锁定。因为锁定失误(忘记释放锁定)的风险,所以对于基本锁定,强烈建议继续使用 synchronized,除非真的需要 ReentrantLock 额外的灵活性和可伸缩性。
|
||||
|
||||
* 建议当获得和释放 ReentrantLock 时使用下列结构:
|
||||
|
||||
```java
|
||||
Lock lock = new ReentrantLock();
|
||||
...
|
||||
lock.lock();
|
||||
try {
|
||||
// perform operations protected by lock
|
||||
}
|
||||
catch(Exception ex) {
|
||||
// restore invariants
|
||||
}
|
||||
finally {
|
||||
lock.unlock();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Condition
|
||||
|
||||
* 就像 Lock 接口是同步的具体化,`Condition` 接口是 Object 中 wait() 和 notify() 方法的具体化。Lock 中的一个方法是 `newCondition()`,它要求该锁定返回新的 Condition 对象限制。
|
||||
|
||||
* `await()`、`signal()` 和 `signalAll()` 方法类似于 wait()、notify() 和 notifyAll(),但增加了灵活性,每个 Lock 都可以创建多个条件变量。这简化了一些并发算法的实现。
|
||||
|
||||
## ReadWriteLock
|
||||
|
||||
* ReentrantLock 实现的锁定规则非常简单 -- 每当一个线程具有锁定时,其他线程必须等待,直到该锁定可用。
|
||||
|
||||
* 有时,当对数据结构的读取通常多于修改时,可以使用更复杂的称为读写锁定的锁定结构,它允许有多个并发读者,同时还允许一个写入者独占锁定。该方法在一般情况下(只读)提供了更大的并发性,同时在必要时仍提供独占访问的安全性。
|
||||
|
||||
* `ReadWriteLock` 接口和 `ReentrantReadWriteLock` 类提供这种功能 -- **多读者**、**单写入**者锁定规则,可以用这种功能来保护共享的易变资源。
|
||||
|
||||
# 原子变量
|
||||
|
||||
* java.util.concurrent.`atomic`包定义了对单一变量进行原子操作的类。所有的类都提供了`get`和`set`方法,可以使用它们像读写`volatile`变量一样读写原子类。就是说,同一变量上的一个set操作对于任意后续的get操作存在happens-before关系。原子的`compareAndSet`方法也有内存一致性特点,就像应用到整型原子变量中的简单原子算法。
|
||||
|
||||
* 即使大多数用户将很少直接使用它们,原子变量类(`AtomicInteger`、`AtomicLong`、`AtomicReference` 等等)也有充分理由是最显著的新并发类。这些类公开对 JVM 的低级别改进,允许进行具有高度可伸缩性的**原子读-修改-写操作**。大多数现代 CPU 都有原子读-修改-写的原语,比如比较并交换(CAS)或加载链接/条件存储(LL/SC)。原子变量类使用硬件提供的最快的并发结构来实现。
|
||||
|
||||
* 几乎 java.util.concurrent 中的所有类都是在 `ReentrantLock` 之上构建的,ReentrantLock 则是在**原子变量类**的基础上构建的。所以,虽然仅少数并发专家使用原子变量类,但 java.util.concurrent 类的很多可伸缩性改进都是由它们提供的。
|
||||
|
||||
* 原子变量主要用于为原子地更新 "热" 字段提供有效的、细粒度的方式, "热" 字段是指由多个线程频繁访问和更新的字段。另外,原子变量还是计数器或生成序号的自然机制。
|
||||
|
||||
# 并发随机数
|
||||
|
||||
* 在JDK7中,java.util.concurrent包含了一个相当便利的类,`ThreadLocalRandom`,当应用程序期望在多个线程或ForkJoinTasks中使用随机数时。
|
||||
|
||||
* 对于并发访问,使用TheadLocalRandom代替Math.random()可以减少竞争,从而获得更好的性能。
|
||||
|
||||
* 只需调用ThreadLocalRandom.`current()`, 然后调用它的其中一个方法去获取一个随机数即可。
|
||||
|
||||
# 性能与可伸缩性
|
||||
|
||||
* **性能**是 "可以快速执行此任务的程度" 的评测。**可伸缩性**描述应用程序的**吞吐量如何表现为它的工作量和可用计算资源增加**。
|
||||
|
||||
* 可伸缩的程序可以按比例使用更多的处理器、内存或 I/O 带宽来处理更多个工作量。当我们在并发环境中谈论可伸缩性时,我们是在问当许多线程同时访问给定类时,这个类的执行情况。
|
||||
|
||||
* java.util.concurrent 中的低级别类 ReentrantLock 和原子变量类的可伸缩性要比内置监视器(同步)锁定高得多。因此,使用 ReentrantLock 或原子变量类来协调共享访问的类也可能更具有可伸缩性。
|
||||
|
||||
@@ -1,561 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Java8 新特性
|
||||
tags: Java 新特性
|
||||
categories: Java
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
# `1` 语言新特性
|
||||
|
||||
## `1.1` Lambda
|
||||
|
||||
自动推测形参类型`e`
|
||||
|
||||
~~~ java
|
||||
Arrays.asList( "a", "b", "d" ).forEach( e -> System.out.println( e ) );
|
||||
~~~
|
||||
指定形参类型`e`
|
||||
|
||||
~~~ java
|
||||
Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.println( e ) );
|
||||
~~~
|
||||
方法体可以用`{}`包裹
|
||||
|
||||
~~~ java
|
||||
Arrays.asList( "a", "b", "d" ).forEach( e -> {
|
||||
System.out.print( e );
|
||||
System.out.print( e );
|
||||
} );
|
||||
~~~
|
||||
|
||||
**effectively final**,lambda引用的对象会自动转为final
|
||||
|
||||
~~~java
|
||||
String separator = ",";
|
||||
Arrays.asList( "a", "b", "d" ).forEach(
|
||||
( String e ) -> System.out.print( e + separator ) );
|
||||
~~~
|
||||
|
||||
## `1.2` FunctionalInterface
|
||||
|
||||
函数接口就是只具有一个方法的普通接口,这样的接口,可以被隐式转换为lambda表达式,
|
||||
|
||||
然而,一旦在此接口中增加了方法,它将不再是函数接口,使用lambda时也将编译失败。
|
||||
|
||||
`@FunctionalInterface`注解可以约束接口的行为,**默认方法**与**静态方法**不会影响函数接口
|
||||
|
||||
~~~java
|
||||
@FunctionalInterface
|
||||
public interface Functional {
|
||||
void method();
|
||||
}
|
||||
~~~
|
||||
|
||||
## `1.3` 接口默认方法
|
||||
|
||||
~~~java
|
||||
public interface Defaulable {
|
||||
// Interfaces now allow default methods, the implementer may or
|
||||
// may not implement (override) them.
|
||||
default String notRequired() {
|
||||
return "Default implementation";
|
||||
}
|
||||
}
|
||||
|
||||
public class DefaultableImpl implements Defaulable {
|
||||
}
|
||||
|
||||
public class OverridableImpl implements Defaulable {
|
||||
@Override
|
||||
public String notRequired() {
|
||||
return "Overridden implementation";
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
## `1.4` 接口静态方法
|
||||
|
||||
~~~java
|
||||
private interface DefaulableFactory {
|
||||
// Interfaces now allow static methods
|
||||
static Defaulable create( Supplier< Defaulable > supplier ) {
|
||||
return supplier.get();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
## `1.5` 方法引用
|
||||
|
||||
可以将类中既有 方法引用为lambda
|
||||
|
||||
~~~java
|
||||
public static class Car {
|
||||
|
||||
public static Car create( final Supplier< Car > supplier ) {
|
||||
return supplier.get();
|
||||
}
|
||||
|
||||
public static void collide( final Car car ) {
|
||||
System.out.println( "Collided " + car.toString() );
|
||||
}
|
||||
|
||||
public void repair() {
|
||||
System.out.println( "Repaired " + this.toString() );
|
||||
}
|
||||
|
||||
public void follow( final Car another ) {
|
||||
System.out.println( "Following the " + another.toString() );
|
||||
}
|
||||
|
||||
}
|
||||
~~~
|
||||
|
||||
①构造器引用,语法为 `Class::new`,效果如同 `() -> new Class()`
|
||||
|
||||
~~~java
|
||||
Car car = Car.create( Car::new );
|
||||
final List< Car > cars = Arrays.asList( car );
|
||||
~~~
|
||||
|
||||
②静态方法引用,语法为 `Class::static_method`,效果如同 `p -> Class.static_method(p)`
|
||||
|
||||
~~~java
|
||||
cars.forEach( Car::collide );
|
||||
~~~
|
||||
|
||||
③实例**无参**方法引用,语法为 `Class::method`,效果如同 `p -> p.method()`,该方法没有参数
|
||||
|
||||
~~~java
|
||||
cars.forEach( Car::repair );
|
||||
~~~
|
||||
|
||||
④实例**有参**方法引用,语法为 `instance::method` ,效果如同 `p -> instance.method(p)`
|
||||
|
||||
~~~java
|
||||
final Car police = Car.create( Car::new );
|
||||
cars.forEach( police::follow );
|
||||
~~~
|
||||
|
||||
⑤其他
|
||||
|
||||
~~~java
|
||||
super::methName //引用某个对象的父类方法
|
||||
TypeName[]::new //引用一个数组的构造器
|
||||
~~~
|
||||
|
||||
## `1.6` 重复注解
|
||||
|
||||
相同的注解可以在同一地方声明多次,由 `@Repeatable` 提供此特性
|
||||
|
||||
~~~java
|
||||
/**
|
||||
* @Repeatable( Filters.class )
|
||||
* 表示该注解可重复使用,注解内容存放于Filters中
|
||||
*/
|
||||
@Target( ElementType.TYPE )
|
||||
@Retention( RetentionPolicy.RUNTIME )
|
||||
@Repeatable( Filters.class )
|
||||
public @interface Filter {
|
||||
String value();
|
||||
};
|
||||
|
||||
/**
|
||||
* 存放@Filter注解的数组
|
||||
* 该注解必须可以被访问
|
||||
*/
|
||||
@Target( ElementType.TYPE )
|
||||
@Retention( RetentionPolicy.RUNTIME )
|
||||
public @interface Filters {
|
||||
Filter[] value();
|
||||
}
|
||||
|
||||
/**
|
||||
* 测试
|
||||
*/
|
||||
@Filter( "filter1" )
|
||||
@Filter( "filter2" )
|
||||
public interface Filterable {
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
//java8 提供的新方法,用于获取重复的注解
|
||||
for(Filter filter : Filterable.class.getAnnotationsByType(Filter.class ) ) {
|
||||
System.out.println( filter.value() );
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
## `1.7` 类型推测
|
||||
|
||||
~~~java
|
||||
public class TypeInfer {
|
||||
public static void main(String[] args) {
|
||||
|
||||
final Value< String > value = new Value<>();
|
||||
|
||||
//value.setV(Value.<String>defV()); //以前的写法
|
||||
|
||||
//Value.defV()返回类型被推测为String
|
||||
value.setV(Value.defV());
|
||||
System.out.println(value.getV());
|
||||
}
|
||||
}
|
||||
|
||||
class Value< T > {
|
||||
|
||||
private T o;
|
||||
|
||||
public static <T> T defV() {
|
||||
//若T不为Object,将会出现类型转换异常
|
||||
return (T)new Object();
|
||||
}
|
||||
|
||||
public void setV(T o){
|
||||
this.o = o;
|
||||
}
|
||||
|
||||
public T getV(){
|
||||
return o;
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
## `1.8` 扩展注解
|
||||
|
||||
java8几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现以及方法异常
|
||||
|
||||
`ElementType.TYPE_USE`和`ElementType.TYPE_PARAMETER` 用于描述注解上下文
|
||||
|
||||
~~~java
|
||||
public class AnnotationEX {
|
||||
|
||||
@Retention( RetentionPolicy.RUNTIME )
|
||||
@Target( { ElementType.TYPE_USE, ElementType.TYPE_PARAMETER } )
|
||||
public @interface Anno {
|
||||
}
|
||||
|
||||
public static class TestAEX< @Anno T > extends @Anno Object {
|
||||
public void method() throws @Anno Exception {
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
final TestAEX< String > holder = new @Anno TestAEX<>();
|
||||
@Anno Collection< @Anno String > strings = new ArrayList<>();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# `2` 类库新特性
|
||||
|
||||
## `2.1` Optional
|
||||
|
||||
~~~java
|
||||
//将String对象装入Optional容器
|
||||
Optional< String > stringOptional = Optional.ofNullable( null );
|
||||
|
||||
//判断容器中的String对象是否不为空
|
||||
System.out.println(stringOptional.isPresent() );
|
||||
|
||||
//orElseGet通过lambda产生一个默认值
|
||||
System.out.println(stringOptional.orElseGet( () -> "[default string]" ) );
|
||||
|
||||
//map对String对象进行转化,然后返回一个新的Optional实例,
|
||||
// 此处s为null,所以未转换直接返回了1个新Optional实例,
|
||||
// orElse直接产生一个默认值
|
||||
System.out.println(stringOptional.map( p -> "[" + p + "]" ).orElse( "Hello Optional" ) );
|
||||
~~~
|
||||
|
||||
## `2.2` Stream
|
||||
|
||||
stream操作被分成了**中间操作**与**最终操作**两种
|
||||
|
||||
**中间操作**返回一个新的stream对象。中间操作总是采用惰性求值方式,运行一个像filter这样的中间操作实际上没有进行任何过滤,相反它在遍历元素时会产生了一个新的stream对象,这个新的stream对象包含原始stream中符合给定谓词的所有元素。
|
||||
|
||||
**最终操作**可能直接遍历stream,产生一个结果或副作用,如forEach、sum等。当最终操作执行结束之后,stream管道被认为已经被消耗了,没有可能再被使用了。在大多数情况下,最终操作都是采用及早求值方式,及早完成底层数据源的遍历。
|
||||
|
||||
~~~java
|
||||
public enum Status {
|
||||
OPEN, CLOSED
|
||||
};
|
||||
|
||||
public class Task {
|
||||
private final Status status;
|
||||
private final Integer points;
|
||||
|
||||
Task( final Status status, final Integer points ) {
|
||||
this.status = status;
|
||||
this.points = points;
|
||||
}
|
||||
|
||||
public Integer getPoints() {
|
||||
return points;
|
||||
}
|
||||
|
||||
public Status getStatus() {
|
||||
return status;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return String.format( "[%s, %d]", status, points );
|
||||
}
|
||||
}
|
||||
|
||||
~~~
|
||||
|
||||
~~~java
|
||||
public static void main(String[] args){
|
||||
Collection< Task > tasks = Arrays.asList(
|
||||
new Task( Status.OPEN, 5 ),
|
||||
new Task( Status.OPEN, 13 ),
|
||||
new Task( Status.CLOSED, 8 )
|
||||
);
|
||||
|
||||
long totalPointsOfOpenTasks = tasks
|
||||
.stream()
|
||||
.filter( task -> task.getStatus() == Status.OPEN )
|
||||
.mapToInt( Task::getPoints )
|
||||
.sum();
|
||||
|
||||
System.out.println( "Total points: " + totalPointsOfOpenTasks );
|
||||
}
|
||||
~~~
|
||||
|
||||
原生并行处理
|
||||
|
||||
~~~java
|
||||
double totalPoints = tasks
|
||||
.stream()
|
||||
.parallel()
|
||||
.map( task -> task.getPoints() ) // or map( Task::getPoints )
|
||||
.reduce( 0, Integer::sum );
|
||||
|
||||
System.out.println( "Total points (all tasks): " + totalPoints );
|
||||
~~~
|
||||
|
||||
分组
|
||||
|
||||
~~~java
|
||||
final Map< Status, List< Task >> map = tasks
|
||||
.stream()
|
||||
.collect( Collectors.groupingBy(Task::getStatus) );
|
||||
|
||||
System.out.println( map );
|
||||
~~~
|
||||
|
||||
权重
|
||||
|
||||
~~~java
|
||||
//计算权重
|
||||
final Collection< String > result = tasks
|
||||
.stream() // Stream< String >
|
||||
.mapToInt( Task::getPoints ) // IntStream
|
||||
.asLongStream() // LongStream
|
||||
.mapToDouble( points -> points / totalPoints ) // DoubleStream
|
||||
.boxed() // Stream< Double >
|
||||
.mapToLong( weigth -> ( long )( weigth * 100 ) ) // LongStream
|
||||
.mapToObj( percentage -> percentage + "%" ) // Stream< String>
|
||||
.collect( Collectors.toList() ); // List< String >
|
||||
|
||||
System.out.println( result );
|
||||
~~~
|
||||
|
||||
## `2.3` Date/Time API
|
||||
|
||||
时间格式均为 **ISO-8601**
|
||||
|
||||
`Clock`
|
||||
|
||||
~~~java
|
||||
//日期时间都有,有时区
|
||||
Clock clock = Clock.systemUTC();
|
||||
System.out.println(clock.instant());
|
||||
System.out.println(clock.millis());
|
||||
~~~
|
||||
|
||||
`LocalDate`
|
||||
|
||||
~~~java
|
||||
//只有日期没有时间
|
||||
LocalDate localDate = LocalDate.now();
|
||||
LocalDate localDateFromClock = LocalDate.now(clock);
|
||||
System.out.println(localDate);
|
||||
System.out.println(localDateFromClock);
|
||||
~~~
|
||||
|
||||
`LocalTime`
|
||||
|
||||
~~~java
|
||||
//只有时间没有日期
|
||||
LocalTime localTime = LocalTime.now();
|
||||
LocalTime localTimeFromClock = LocalTime.now(clock);
|
||||
System.out.println(localTime);
|
||||
System.out.println(localTimeFromClock);
|
||||
~~~
|
||||
|
||||
`LocalDateTime `
|
||||
|
||||
~~~java
|
||||
//日期时间都有,没有时区
|
||||
LocalDateTime localDateTime = LocalDateTime.now();
|
||||
LocalDateTime localDateTimeFromClock = LocalDateTime.now(clock);
|
||||
System.out.println(localDateTime);
|
||||
System.out.println(localDateTimeFromClock);
|
||||
~~~
|
||||
|
||||
`ZonedDateTime`
|
||||
|
||||
~~~java
|
||||
//指定时区,只有ZonedDateTime,没有ZoneDate与ZoneTime
|
||||
ZonedDateTime zonedDateTime = ZonedDateTime.now();
|
||||
ZonedDateTime zonedDateTimeFromClock = ZonedDateTime.now();
|
||||
ZonedDateTime zonedDateTimeFromZone = ZonedDateTime.now(ZoneId.of( "America/Los_Angeles" ));
|
||||
System.out.println(zonedDateTime);
|
||||
System.out.println(zonedDateTimeFromClock);
|
||||
System.out.println(zonedDateTimeFromZone);
|
||||
~~~
|
||||
|
||||
`Duration`
|
||||
|
||||
~~~java
|
||||
//计算时间差
|
||||
LocalDateTime from = LocalDateTime.of( 2014, Month.APRIL, 16, 0, 0, 0 );
|
||||
LocalDateTime to = LocalDateTime.of( 2015, Month.APRIL, 16, 23, 59, 59 );
|
||||
Duration duration = Duration.between( from, to );
|
||||
System.out.println( "Duration in days: " + duration.toDays() );
|
||||
System.out.println( "Duration in hours: " + duration.toHours() );
|
||||
~~~
|
||||
|
||||
## `2.4` Nashorn
|
||||
|
||||
`javax.script.ScriptEngine`的另一种实现,允许js与java相互调用
|
||||
|
||||
~~~java
|
||||
ScriptEngineManager manager = new ScriptEngineManager();
|
||||
ScriptEngine engine = manager.getEngineByName( "JavaScript" );
|
||||
|
||||
System.out.println( engine.getClass().getName() );
|
||||
System.out.println( "Result:" + engine.eval( "function f() { return 1; }; f() + 1;" ) );
|
||||
~~~
|
||||
|
||||
## `2.5` Base64
|
||||
|
||||
Base64编码已经成为Java8类库的标准
|
||||
|
||||
~~~java
|
||||
final String text = "Base64 finally in Java 8!";
|
||||
|
||||
final String encoded = Base64
|
||||
.getEncoder()
|
||||
.encodeToString( text.getBytes(StandardCharsets.UTF_8 ) );
|
||||
System.out.println( encoded );
|
||||
|
||||
final String decoded = new String(
|
||||
Base64.getDecoder().decode( encoded ),
|
||||
StandardCharsets.UTF_8 );
|
||||
System.out.println( decoded );
|
||||
~~~
|
||||
|
||||
>其他编码器与解码器
|
||||
>
|
||||
>`Base64.getUrlEncoder() Base64.getUrlDecoder()`
|
||||
>
|
||||
>`Base64.getMimeEncoder() Base64.getMimeDecoder()`
|
||||
|
||||
## `2.6` 并行(parallel )数组
|
||||
|
||||
**并行数组**操作可以在多核机器上极大提高性能
|
||||
|
||||
~~~java
|
||||
long[] arrayOfLong = new long [ 20000 ];
|
||||
|
||||
//对arrayLong所有元素随机赋值
|
||||
Arrays.parallelSetAll(arrayOfLong,
|
||||
index -> ThreadLocalRandom.current().nextInt(1000000));
|
||||
|
||||
//打印前10个元素
|
||||
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
|
||||
i -> System.out.print( i + " " ) );
|
||||
System.out.println();
|
||||
|
||||
//对arrayLong数组排序
|
||||
Arrays.parallelSort( arrayOfLong );
|
||||
|
||||
//打印前10个元素
|
||||
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
|
||||
i -> System.out.print( i + " " ) );
|
||||
System.out.println();
|
||||
~~~
|
||||
|
||||
## `2.7` 并发(concurrency)
|
||||
|
||||
* java.util.concurrent.`ConcurrentHashMap`类中加入了一些新方法来支持聚集操作
|
||||
|
||||
* java.util.concurrent.`ForkJoinPool`类中加入了一些新方法来支持共有资源池(common pool)
|
||||
|
||||
* java.util.concurrent.locks.`StampedLock`类提供基于容量的锁,这种锁有三个模型来控制读写操作
|
||||
|
||||
* java.util.concurrent.atomic包中增加新类:<br/>
|
||||
`DoubleAccumulator`,<br/>
|
||||
`DoubleAdder`,<br/>
|
||||
`LongAccumulator`,<br/>
|
||||
`LongAdder`
|
||||
|
||||
|
||||
# `3` 编译器新特性
|
||||
|
||||
## `3.1` 参数名
|
||||
|
||||
方法参数的名字保留在Java字节码中,并且能够在运行时获取它们
|
||||
|
||||
编译时需要加上 `–parameters` ,**maven-compiler-plugin** 可进行配置
|
||||
|
||||
~~~java
|
||||
public class ParameterNames {
|
||||
public static void main(String[] args) throws Exception {
|
||||
Method method = ParameterNames.class.getMethod( "main", String[].class );
|
||||
for( final Parameter parameter: method.getParameters() ) {
|
||||
System.out.println( "Parameter: " + parameter.getName() );
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# `4` 新的Java工具
|
||||
|
||||
## `4.1` Nashorn引擎 `jjs`
|
||||
|
||||
它接受一些JavaScript源代码为参数,并且执行这些源代码
|
||||
|
||||
创建 **func.js** 文件
|
||||
|
||||
~~~javascript
|
||||
function f() {
|
||||
return 1;
|
||||
};
|
||||
|
||||
print( f() + 1 );
|
||||
~~~
|
||||
~~~bash
|
||||
jjs func.js
|
||||
~~~
|
||||
|
||||
## `4.2` 类依赖分析器 `jdeps`
|
||||
|
||||
它可以显示Java类的包级别或类级别的依赖,它接受一个.class文件,一个目录,或者一个jar文件作为输入。jdeps默认把结果输出到系统输出(控制台)上。
|
||||
|
||||
~~~bash
|
||||
jdeps org.springframework.core-3.0.5.RELEASE.jar
|
||||
~~~
|
||||
|
||||
如果依赖不在classpath中,就会显示 **not found**
|
||||
|
||||
# `5` JVM新特性
|
||||
|
||||
**PermGen**空间被移除了,取而代之的是**Metaspace**(JEP 122)。JVM选项**-XX:PermSize**与**-XX:MaxPermSize**分别被**-XX:MetaSpaceSize**与**-XX:MaxMetaspaceSize**所代替
|
||||
@@ -1,754 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: WebService
|
||||
tags: WebService Java
|
||||
categories: web
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
**WSDL**
|
||||
|
||||
`definitions` 为根节点,属性为
|
||||
|
||||
>`name`:WS 名称,默认为“实现类 + Service”
|
||||
>
|
||||
>`targetNamespace`:WS 目标命名空间,默认为“WS 实现类对应包名倒排后构成的地址”
|
||||
|
||||
`definitions`的5个子节点
|
||||
|
||||
>`types`:描述了 WS 中所涉及的数据类型
|
||||
>
|
||||
>`portType`:定义了 WS 接口名称`portType.name`(`endpointInterface`默认为“WS 实现类所实现的接口”),及其操作名称,以及每个操作的输入与输出消息
|
||||
>
|
||||
>`message`:对相关消息进行了定义(供 types 与 portType 使用)
|
||||
>
|
||||
>`binding`:提供了对 WS 的数据绑定方式
|
||||
>
|
||||
>`service`:WS 名称及其端口名称`service_port.name`(`portName`默认为“WS 实现类 + Port”),以及对应的 WSDL 地址
|
||||
|
||||
**SOAP**
|
||||
|
||||
`header`
|
||||
|
||||
`body`
|
||||
|
||||
---
|
||||
|
||||
# `一`、产品
|
||||
|
||||
**soap**风格 (JAX-WS规范JSR-224)
|
||||
|
||||
JAX-WS RI:https://jax-ws.java.net/ Oracle 官方提供的实现
|
||||
|
||||
Axis:http://axis.apache.org/
|
||||
|
||||
CXF:http://cxf.apache.org/
|
||||
|
||||
**rest**风格 (JAX-RS规范JSR-339)
|
||||
|
||||
Jersey:https://jersey.java.net/ Oracle 官方提供的实现
|
||||
|
||||
Restlet:http://restlet.com/
|
||||
|
||||
RESTEasy:http://resteasy.jboss.org/
|
||||
|
||||
CXF:http://cxf.apache.org/
|
||||
|
||||
# `二`、JDK发布与调用
|
||||
|
||||
## `1`.发布
|
||||
|
||||
### 定义接口
|
||||
|
||||
~~~java
|
||||
//此注解必须
|
||||
@WebService
|
||||
public interface HelloService {
|
||||
String say();
|
||||
}
|
||||
~~~
|
||||
|
||||
### 实现接口
|
||||
|
||||
~~~java
|
||||
@WebService(serviceName = "HelloService",
|
||||
portName = "HelloServicePort",
|
||||
endpointInterface = "org.sllx.practice.jdkws.HelloService")
|
||||
public class HelloServiceImpl implements HelloService {
|
||||
@Override
|
||||
public String say() {
|
||||
return "helloWorld";
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
### 发布服务
|
||||
|
||||
~~~java
|
||||
public class Server {
|
||||
public static void main(String[] args){
|
||||
String address = "http://localhost:8081/ws/soap/hello";
|
||||
HelloService helloService = new HelloServiceImpl();
|
||||
Endpoint.publish(address, helloService);
|
||||
System.out.println("ws is published [" + address + "?wsdl]");
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
访问`http://localhost:8081/ws/soap/hello?wsdl`即可查看详情
|
||||
|
||||
## `2`.调用
|
||||
|
||||
### 静态客户端
|
||||
|
||||
`wsimport http://localhost:8080/ws/soap/hello?wsdl`//通过 WSDL 地址生成 class 文件
|
||||
|
||||
`jar -cf client.jar .` //通过 jar 命令将若干 class 文件压缩为一个 jar 包
|
||||
|
||||
`rmdir /s/q demo `//删除生成的 class 文件(删除根目录即可)
|
||||
|
||||
~~~java
|
||||
public static void main(String[] args){
|
||||
HelloService_Service hss = new HelloService_Service();
|
||||
HelloService hs = hss.getHelloServicePort();
|
||||
System.out.println(hs.say());
|
||||
}
|
||||
~~~
|
||||
|
||||
### 动态代理客户端
|
||||
|
||||
只需提供`HelloService`接口,无需jar
|
||||
|
||||
~~~java
|
||||
public static void main(String[] args){
|
||||
try {
|
||||
URL wsdl = new URL("http://localhost:8081/ws/soap/hello?wsdl");
|
||||
QName serviceName = new QName("http://jdkws.practice.sllx.org/", "HelloService");
|
||||
QName portName = new QName("http://jdkws.practice.sllx.org/", "HelloServicePort");
|
||||
Service service = Service.create(wsdl, serviceName);
|
||||
HelloService helloService = service.getPort(portName, HelloService.class);
|
||||
String result = helloService.say();
|
||||
System.out.println(result);
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
# `三`、CXF
|
||||
|
||||
User为自定义的POJO类
|
||||
|
||||
web发布示例集成spring
|
||||
|
||||
## `1.`SOAP风格
|
||||
|
||||
### 定义接口
|
||||
|
||||
~~~java
|
||||
package top.rainynight.sitews.user.ws;
|
||||
|
||||
import top.rainynight.sitews.user.entity.User;
|
||||
import javax.jws.WebService;
|
||||
|
||||
@WebService
|
||||
public interface UserWS {
|
||||
|
||||
User lookOver(int id);
|
||||
}
|
||||
~~~
|
||||
|
||||
### 实现接口
|
||||
|
||||
~~~java
|
||||
package top.rainynight.sitews.user.ws;
|
||||
|
||||
import top.rainynight.sitews.user.entity.User;
|
||||
import org.springframework.stereotype.Component;
|
||||
|
||||
@Component("userWS")
|
||||
public class UserWSImpl implements UserWS {
|
||||
|
||||
@Override
|
||||
public User lookOver(int id) {
|
||||
return new User();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
|
||||
### 发布服务
|
||||
|
||||
#### ①Jetty发布
|
||||
|
||||
配置依赖
|
||||
|
||||
~~~xml
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<cxf.version>3.0.0</cxf.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-frontend-jaxws</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-transports-http-jetty</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
~~~
|
||||
|
||||
发布
|
||||
|
||||
~~~java
|
||||
public class JaxWsServer {
|
||||
public static void main(String[] args) {
|
||||
JaxWsServerFactoryBean factory = new JaxWsServerFactoryBean();
|
||||
factory.setAddress("http://localhost:8080/ws/user");
|
||||
factory.setServiceClass(UserWS.class);
|
||||
factory.setServiceBean(new UserWSImpl());
|
||||
factory.create();
|
||||
System.out.println("soap ws is published");
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
访问`http://localhost:8080/ws/user?wsdl`
|
||||
|
||||
#### ②Web发布
|
||||
|
||||
配置依赖
|
||||
|
||||
~~~xml
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<spring.version>4.0.5.RELEASE</spring.version>
|
||||
<cxf.version>3.0.0</cxf.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework</groupId>
|
||||
<artifactId>spring-web</artifactId>
|
||||
<version>${spring.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-frontend-jaxws</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-transports-http</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
~~~
|
||||
|
||||
配置web.xml
|
||||
|
||||
~~~xml
|
||||
<listener>
|
||||
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
|
||||
</listener>
|
||||
<context-param>
|
||||
<param-name>contextConfigLocation</param-name>
|
||||
<param-value>
|
||||
classpath:spring.xml
|
||||
</param-value>
|
||||
</context-param>
|
||||
|
||||
<servlet>
|
||||
<servlet-name>cxf</servlet-name>
|
||||
<servlet-class>org.apache.cxf.transport.servlet.CXFServlet</servlet-class>
|
||||
</servlet>
|
||||
<servlet-mapping>
|
||||
<servlet-name>cxf</servlet-name>
|
||||
<url-pattern>/*</url-pattern>
|
||||
</servlet-mapping>
|
||||
~~~
|
||||
|
||||
发布
|
||||
|
||||
~~~xml
|
||||
<beans xmlns="http://www.springframework.org/schema/beans"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xmlns:context="http://www.springframework.org/schema/context"
|
||||
xmlns:jaxws="http://cxf.apache.org/jaxws"
|
||||
xsi:schemaLocation="http://www.springframework.org/schema/beans
|
||||
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
|
||||
http://www.springframework.org/schema/context
|
||||
http://www.springframework.org/schema/context/spring-context.xsd
|
||||
http://cxf.apache.org/jaxws
|
||||
http://cxf.apache.org/schemas/jaxws.xsd">
|
||||
|
||||
<context:component-scan base-package="top.rainynight.sitews.user.ws" />
|
||||
|
||||
<!-- 下面的方法更简单
|
||||
<jaxws:server address="/ws/user">
|
||||
<jaxws:serviceBean>
|
||||
<ref bean="userWS"/>
|
||||
</jaxws:serviceBean>
|
||||
</jaxws:server>
|
||||
-->
|
||||
|
||||
<jaxws:endpoint implementor="# userWS" address="/ws/user" />
|
||||
</beans>
|
||||
~~~
|
||||
|
||||
访问`http://localhost:8080/ws/user?wsdl`
|
||||
|
||||
### 调用服务
|
||||
|
||||
#### ①静态客户端
|
||||
|
||||
~~~java
|
||||
public class JaxWsClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
JaxWsProxyFactoryBean factory = new JaxWsProxyFactoryBean();
|
||||
factory.setAddress("http://localhost:8080/ws/user");
|
||||
factory.setServiceClass(UserWS .class);
|
||||
|
||||
UserWS userWS = factory.create(UserWS .class);
|
||||
User result = userWS .lookOver(1);
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ②动态代理客户端
|
||||
|
||||
~~~java
|
||||
public class JaxWsDynamicClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
JaxWsDynamicClientFactory factory = JaxWsDynamicClientFactory.newInstance();
|
||||
Client client = factory.createClient("http://localhost:8080/ws/user?wsdl");
|
||||
|
||||
try {
|
||||
Object[] results = client.invoke("lookOver", 1);
|
||||
System.out.println(results[0]);
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ③通用动态代理客户端
|
||||
|
||||
既可调用 JAX-WS 服务,也可调用 Simple 服务
|
||||
|
||||
~~~java
|
||||
public class DynamicClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
DynamicClientFactory factory = DynamicClientFactory.newInstance();
|
||||
Client client = factory.createClient("http://localhost:8080/ws/user?wsdl");
|
||||
|
||||
try {
|
||||
Object[] results = client.invoke("lookOver", 1);
|
||||
System.out.println(results[0]);
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ④Spring客户端
|
||||
|
||||
~~~xml
|
||||
<beans xmlns="http://www.springframework.org/schema/beans"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xmlns:jaxws="http://cxf.apache.org/jaxws"
|
||||
xsi:schemaLocation="http://www.springframework.org/schema/beans
|
||||
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
|
||||
http://cxf.apache.org/jaxws
|
||||
http://cxf.apache.org/schemas/jaxws.xsd">
|
||||
|
||||
<jaxws:client id="userWSClient"
|
||||
serviceClass="top.rainynight.sitews.user.ws.UserWS"
|
||||
address="http://localhost:8080/ws/user"/>
|
||||
|
||||
</beans>
|
||||
~~~
|
||||
|
||||
~~~java
|
||||
public class UserWSClient{
|
||||
|
||||
public static void main(String[] args) {
|
||||
ApplicationContext context = new ClassPathXmlApplicationContext("spring-client.xml");
|
||||
|
||||
UserWS userWS= context.getBean("userWSClient", UserWS.class);
|
||||
User result = userWS.lookOver(1);
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
## `2`.REST风格
|
||||
|
||||
### 定义接口
|
||||
|
||||
`!`REST 规范允许资源类没有接口
|
||||
|
||||
>请求方式注解,包括:`@GET、@POST、@PUT、@DELETE`
|
||||
>
|
||||
>请求路径注解,包括:`@Path` ,其中包括一个路径参数
|
||||
>
|
||||
>数据格式注解,包括:`@Consumes`(输入)、`@Produces`(输出),可使用 `MediaType` 常量
|
||||
>
|
||||
>相关参数注解,包括:`@PathParam`(路径参数)、`@FormParam`(表单参数),此外还有 `@QueryParam`(请求参数)
|
||||
|
||||
~~~java
|
||||
package top.rainynight.sitews.user.ws;
|
||||
|
||||
import top.rainynight.sitews.user.entity.User;
|
||||
import javax.jws.WebService;
|
||||
|
||||
@WebService
|
||||
@Path("/")
|
||||
public interface UserWS {
|
||||
|
||||
@GET
|
||||
@Path("{id:[1-9]{1,9}}")
|
||||
@Produces(MediaType.APPLICATION_JSON)
|
||||
User lookOver(@PathParam("id") int id);
|
||||
}
|
||||
~~~
|
||||
|
||||
### 实现接口
|
||||
|
||||
~~~java
|
||||
package top.rainynight.sitews.user.ws;
|
||||
|
||||
import top.rainynight.sitews.user.entity.User;
|
||||
import org.springframework.stereotype.Component;
|
||||
|
||||
@Component("userWS")
|
||||
public class UserWSImpl implements UserWS {
|
||||
|
||||
@Override
|
||||
public User lookOver(int id) {
|
||||
return new User();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
### 发布服务
|
||||
|
||||
#### ①jetty发布
|
||||
|
||||
配置依赖
|
||||
|
||||
~~~xml
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<cxf.version>3.0.0</cxf.version>
|
||||
<jackson.version>2.4.1</jackson.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-frontend-jaxrs</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-transports-http-jetty</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.fasterxml.jackson.jaxrs</groupId>
|
||||
<artifactId>jackson-jaxrs-json-provider</artifactId>
|
||||
<version>${jackson.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
~~~
|
||||
|
||||
发布
|
||||
|
||||
~~~java
|
||||
public class Server {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 添加 ResourceClass
|
||||
List<Class<?>> resourceClassList = new ArrayList<Class<?>>();
|
||||
resourceClassList.add(UserWSImpl .class);
|
||||
|
||||
// 添加 ResourceProvider
|
||||
List<ResourceProvider> resourceProviderList = new ArrayList<ResourceProvider>();
|
||||
resourceProviderList.add(new SingletonResourceProvider(new ProductServiceImpl()));
|
||||
|
||||
// 添加 Provider
|
||||
List<Object> providerList = new ArrayList<Object>();
|
||||
providerList.add(new JacksonJsonProvider());
|
||||
|
||||
// 发布 REST 服务
|
||||
JAXRSServerFactoryBean factory = new JAXRSServerFactoryBean();
|
||||
factory.setAddress("http://localhost:8080/rs/user");
|
||||
factory.setResourceClasses(resourceClassList);
|
||||
factory.setResourceProviders(resourceProviderList);
|
||||
factory.setProviders(providerList);
|
||||
factory.create();
|
||||
System.out.println("rest ws is published");
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
访问`http://localhost:8080/rs/user?_wadl`
|
||||
|
||||
#### ②web发布
|
||||
|
||||
配置依赖
|
||||
|
||||
~~~xml
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<spring.version>4.0.6.RELEASE</spring.version>
|
||||
<cxf.version>3.0.0</cxf.version>
|
||||
<jackson.version>2.4.1</jackson.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework</groupId>
|
||||
<artifactId>spring-web</artifactId>
|
||||
<version>${spring.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-frontend-jaxrs</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.fasterxml.jackson.jaxrs</groupId>
|
||||
<artifactId>jackson-jaxrs-json-provider</artifactId>
|
||||
<version>${jackson.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
~~~
|
||||
|
||||
配置web.xml
|
||||
|
||||
~~~xml
|
||||
<listener>
|
||||
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
|
||||
</listener>
|
||||
<context-param>
|
||||
<param-name>contextConfigLocation</param-name>
|
||||
<param-value>
|
||||
classpath:spring.xml
|
||||
</param-value>
|
||||
</context-param>
|
||||
|
||||
<servlet>
|
||||
<servlet-name>cxf</servlet-name>
|
||||
<servlet-class>org.apache.cxf.transport.servlet.CXFServlet</servlet-class>
|
||||
</servlet>
|
||||
<servlet-mapping>
|
||||
<servlet-name>cxf</servlet-name>
|
||||
<url-pattern>/*</url-pattern>
|
||||
</servlet-mapping>
|
||||
~~~
|
||||
|
||||
发布
|
||||
|
||||
~~~xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
|
||||
<beans xmlns="http://www.springframework.org/schema/beans"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xmlns:context="http://www.springframework.org/schema/context"
|
||||
xmlns:jaxrs="http://cxf.apache.org/jaxrs"
|
||||
xsi:schemaLocation="http://www.springframework.org/schema/beans
|
||||
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
|
||||
http://www.springframework.org/schema/context
|
||||
http://www.springframework.org/schema/context/spring-context.xsd
|
||||
http://cxf.apache.org/jaxrs
|
||||
http://cxf.apache.org/schemas/jaxrs.xsd">
|
||||
|
||||
<context:component-scan base-package="top.rainynight.sitews.user.ws" />
|
||||
|
||||
<jaxrs:server address="/rs/user">
|
||||
<jaxrs:serviceBeans>
|
||||
<ref bean="userWS"/>
|
||||
</jaxrs:serviceBeans>
|
||||
<jaxrs:providers>
|
||||
<bean class="com.fasterxml.jackson.jaxrs.json.JacksonJsonProvider"/>
|
||||
</jaxrs:providers>
|
||||
</jaxrs:server>
|
||||
</beans>
|
||||
~~~
|
||||
|
||||
访问`http://localhost:8080/rs/user?_wadl`
|
||||
|
||||
### 调用服务
|
||||
|
||||
#### ①JAX-RS 1.0 客户端
|
||||
|
||||
~~~java
|
||||
public class JAXRSClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
String baseAddress = "http://localhost:8080/rs/user";
|
||||
|
||||
List<Object> providerList = new ArrayList<Object>();
|
||||
providerList.add(new JacksonJsonProvider());
|
||||
|
||||
UserWS userWS = JAXRSClientFactory.create(baseAddress, UserWS.class, providerList);
|
||||
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ②JAX-RS 2.0 客户端
|
||||
|
||||
~~~java
|
||||
public class JAXRS20Client {
|
||||
|
||||
public static void main(String[] args) {
|
||||
String baseAddress = "http://localhost:8080/rs/user";
|
||||
|
||||
JacksonJsonProvider jsonProvider = new JacksonJsonProvider();
|
||||
|
||||
List<User> userList = ClientBuilder.newClient()
|
||||
.register(jsonProvider)
|
||||
.target(baseAddress)
|
||||
.path("/1")
|
||||
.request(MediaType.APPLICATION_JSON)
|
||||
.get(new GenericType<List<User>>() {});
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ③WebClient 客户端
|
||||
|
||||
~~~java
|
||||
public class CXFWebClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
String baseAddress = "http://localhost:8080/rs/user";
|
||||
|
||||
List<Object> providerList = new ArrayList<Object>();
|
||||
providerList.add(new JacksonJsonProvider());
|
||||
|
||||
List<User> userList = WebClient.create(baseAddress, providerList)
|
||||
.path("/1")
|
||||
.accept(MediaType.APPLICATION_JSON)
|
||||
.get(new GenericType<List<User>>() {});
|
||||
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
#### ④AJAX客户端
|
||||
|
||||
~~~javascript
|
||||
$.ajax({
|
||||
type: 'get',
|
||||
url: 'http://localhost:8080/rs/user/1',
|
||||
dataType: 'json',
|
||||
success: function(data) {
|
||||
//...
|
||||
}
|
||||
});
|
||||
~~~
|
||||
|
||||
跨域方案1:jsonp
|
||||
|
||||
~~~xml
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-rs-extension-providers</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
~~~
|
||||
|
||||
~~~xml
|
||||
<jaxrs:server address="/rs/user">
|
||||
<jaxrs:serviceBeans>
|
||||
<ref bean="userWS"/>
|
||||
</jaxrs:serviceBeans>
|
||||
<jaxrs:providers>
|
||||
<bean class="com.fasterxml.jackson.jaxrs.json.JacksonJsonProvider"/>
|
||||
<bean class="org.apache.cxf.jaxrs.provider.jsonp.JsonpPreStreamInterceptor"/>
|
||||
</jaxrs:providers>
|
||||
<jaxrs:inInterceptors>
|
||||
<bean class="org.apache.cxf.jaxrs.provider.jsonp.JsonpInInterceptor"/>
|
||||
</jaxrs:inInterceptors>
|
||||
<jaxrs:outInterceptors>
|
||||
<bean class="org.apache.cxf.jaxrs.provider.jsonp.JsonpPostStreamInterceptor"/>
|
||||
</jaxrs:outInterceptors>
|
||||
</jaxrs:server>
|
||||
~~~
|
||||
|
||||
~~~javascript
|
||||
$.ajax({
|
||||
type: 'get',
|
||||
url: 'http://localhost:8080/rs/user/1',
|
||||
dataType: 'jsonp',
|
||||
jsonp: '_jsonp',
|
||||
jsonpCallback: 'callback',
|
||||
success: function(data) {
|
||||
//...
|
||||
}
|
||||
});
|
||||
~~~
|
||||
|
||||
跨域方案2:cors
|
||||
|
||||
~~~xml
|
||||
<dependency>
|
||||
<groupId>org.apache.cxf</groupId>
|
||||
<artifactId>cxf-rt-rs-security-cors</artifactId>
|
||||
<version>${cxf.version}</version>
|
||||
</dependency>
|
||||
~~~
|
||||
|
||||
~~~xml
|
||||
<jaxrs:server address="/rs/user">
|
||||
<jaxrs:serviceBeans>
|
||||
<ref bean="userWS"/>
|
||||
</jaxrs:serviceBeans>
|
||||
<jaxrs:providers>
|
||||
<bean class="com.fasterxml.jackson.jaxrs.json.JacksonJsonProvider"/>
|
||||
<bean class="org.apache.cxf.rs.security.cors.CrossOriginResourceSharingFilter">
|
||||
<property name="allowOrigins" value="http://localhost"/>
|
||||
</bean>
|
||||
</jaxrs:providers>
|
||||
</jaxrs:server>
|
||||
~~~
|
||||
|
||||
allowOrigins 设置客户端域名
|
||||
|
||||
IE8 中使用 jQuery 发送 AJAX 请求时,需要配置 `$.support.cors = true`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## `~~`警告`~~`
|
||||
`!warning` 极重要,cxf在wsdl中发布的`targetNamespace`是实现类路径,而被调用时却只接受接口路径。所以,请将接口与实现类放在同一路径下,或者在实现类中指定`targetNamespace`为接口的路径;否则客户端将抛出 ..common.i18n.UncheckedException: No operation was found with the name ... 异常
|
||||
@@ -1,494 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: make
|
||||
tags: make Linux script
|
||||
categories: Linux
|
||||
published: false
|
||||
---
|
||||
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
代码变成可执行文件,叫做编译(compile);先编译这个,还是先编译那个(即编译的安排),叫做构建(build)
|
||||
|
||||
|
||||
指定规则进行编译,默认为当前目录下的Makefile文件
|
||||
|
||||
~~~
|
||||
$ make -f rules.txt
|
||||
或者
|
||||
make --file=rules.txt
|
||||
|
||||
~~~
|
||||
|
||||
# Makefile 文件结构
|
||||
|
||||
Makefile文件由一系列规则(rules)构成。每条规则的形式如下。
|
||||
|
||||
~~~
|
||||
<target> : <prerequisites>
|
||||
[tab] <commands>
|
||||
|
||||
~~~
|
||||
|
||||
上面第一行冒号前面的部分,叫做"目标"(target),冒号后面的部分叫做"前置条件"(prerequisites);第二行必须由一个tab键起首,后面跟着"命令"(commands)。
|
||||
|
||||
"目标"是必需的,不可省略;"前置条件"和"命令"都是可选的,但是两者之中必须至少存在一个。
|
||||
|
||||
## 目标(target)
|
||||
|
||||
一个目标(target)就构成一条规则。目标通常是文件名,指明Make命令所要构建的对象 。目标可以是一个文件名,也可以是多个文件名,之间用空格分隔。
|
||||
|
||||
除了文件名,目标还可以是某个操作的名字,这称为"伪目标"(phony target)。
|
||||
|
||||
~~~
|
||||
clean:
|
||||
rm *.o
|
||||
|
||||
~~~
|
||||
上面代码的目标是clean,它不是文件名,而是一个操作的名字,属于"伪目标 ",作用是删除对象文件。
|
||||
|
||||
~~~
|
||||
$ make clean
|
||||
|
||||
~~~
|
||||
|
||||
但是,如果当前目录中,正好有一个文件叫做clean,那么这个命令不会执行。因为Make发现clean文件已经存在,就认为没有必要重新构建了,就不会执行指定的rm命令。
|
||||
|
||||
为了避免这种情况,可以明确声明clean是"伪目标",写法如下。
|
||||
|
||||
~~~
|
||||
.PHONY: clean
|
||||
clean:
|
||||
rm *.o temp
|
||||
|
||||
~~~
|
||||
|
||||
声明clean是"伪目标"之后,make就不会去检查是否存在一个叫做clean的文件,而是每次运行都执行对应的命令。像.PHONY这样的内置目标名还有不少,可以查看手册。
|
||||
|
||||
如果Make命令运行时没有指定目标,默认会执行Makefile文件的第一个目标。
|
||||
|
||||
~~~
|
||||
$ make
|
||||
|
||||
~~~
|
||||
|
||||
## 前置条件(prerequisites)
|
||||
|
||||
前置条件通常是一组文件名,之间用空格分隔。它指定了"目标"是否重新构建的判断标准:只要有一个前置文件不存在,或者有过更新(前置文件的last-modification时间戳比目标的时间戳新),"目标"就需要重新构建。
|
||||
|
||||
~~~
|
||||
result.txt: source.txt
|
||||
cp source.txt result.txt
|
||||
|
||||
~~~
|
||||
|
||||
如果当前目录中,source.txt 已经**存在**,那么make result.txt可以正常运行,否则必须再写一条规则,来生成 source.txt 。
|
||||
|
||||
~~~
|
||||
source.txt:
|
||||
echo "this is the source" > source.txt
|
||||
|
||||
~~~
|
||||
|
||||
上面代码中,source.txt后面没有前置条件,就意味着它跟其他文件都无关,只要这个文件还**不存在**,每次调用make source.txt,它都会生成。
|
||||
|
||||
~~~
|
||||
$ make result.txt
|
||||
$ make result.txt
|
||||
|
||||
~~~
|
||||
|
||||
上面命令连续执行两次make result.txt。第一次执行会先新建 source.txt,然后再新建 result.txt。第二次执行,Make发现 source.txt **没有变动**(时间戳晚于 result.txt),就不会执行任何操作,result.txt 也不会重新生成。
|
||||
|
||||
如果需要生成多个文件,往往采用下面的写法。
|
||||
|
||||
~~~
|
||||
source: file1 file2 file3
|
||||
|
||||
~~~
|
||||
|
||||
上面代码中,source 是一个伪目标,只有三个前置文件,没有任何对应的命令。
|
||||
|
||||
~~~
|
||||
$ make source
|
||||
|
||||
~~~
|
||||
|
||||
执行make source命令后,就会一次性生成 file1,file2,file3 三个文件
|
||||
|
||||
## 命令(commands)
|
||||
|
||||
命令(commands)表示如何更新目标文件,由一行或多行的Shell命令组成。它是构建"目标"的具体指令,它的运行结果通常就是生成目标文件。
|
||||
|
||||
每行命令之前必须有一个tab键。如果想用其他键,可以用内置变量.RECIPEPREFIX声明。
|
||||
|
||||
~~~
|
||||
.RECIPEPREFIX = >
|
||||
all:
|
||||
> echo Hello, world
|
||||
|
||||
~~~
|
||||
|
||||
上面代码用.RECIPEPREFIX指定,大于号(>)替代tab键。所以,每一行命令的起首变成了大于号,而不是tab键。
|
||||
|
||||
需要注意的是,每行命令在一个单独的shell中执行。这些Shell之间没有继承关系。
|
||||
|
||||
~~~
|
||||
var-lost:
|
||||
export foo=bar
|
||||
echo "foo=[$$foo]"
|
||||
|
||||
~~~
|
||||
上面代码执行后(make var-lost),取不到foo的值。因为两行命令在两个不同的进程执行。一个解决办法是将两行命令写在一行,中间用分号分隔。
|
||||
|
||||
~~~
|
||||
var-kept:
|
||||
export foo=bar; echo "foo=[$$foo]"
|
||||
|
||||
~~~
|
||||
|
||||
另一个解决办法是在换行符前加反斜杠转义。
|
||||
|
||||
~~~
|
||||
var-kept:
|
||||
export foo=bar; \
|
||||
echo "foo=[$$foo]"
|
||||
|
||||
~~~
|
||||
|
||||
最后一个方法是加上.ONESHELL:命令。
|
||||
|
||||
~~~
|
||||
.ONESHELL:
|
||||
var-kept:
|
||||
export foo=bar;
|
||||
echo "foo=[$$foo]"
|
||||
|
||||
~~~
|
||||
|
||||
|
||||
# Makefile 文件语法
|
||||
|
||||
**`# `号注释**
|
||||
|
||||
## 通配符
|
||||
|
||||
通配符(wildcard)用来指定一组符合条件的文件名。Makefile 的通配符与 Bash 一致,主要有星号(*)、问号(?)和 [...] 。比如, *.o 表示所有后缀名为o的文件。
|
||||
|
||||
## 回声(echoing)
|
||||
|
||||
正常情况下,make会打印每条命令,然后再执行,这就叫做回声(echoing)。
|
||||
|
||||
在命令的前面加上@,就可以关闭回声。
|
||||
|
||||
## 模式匹配
|
||||
|
||||
Make命令允许对文件名,进行类似正则运算的匹配,主要用到的匹配符是%。比如,假定当前目录下有 f1.c 和 f2.c 两个源码文件,需要将它们编译为对应的对象文件。
|
||||
|
||||
~~~
|
||||
%.o: %.c
|
||||
|
||||
~~~
|
||||
|
||||
等同于下面的写法。
|
||||
|
||||
~~~
|
||||
f1.o: f1.c
|
||||
f2.o: f2.c
|
||||
|
||||
~~~
|
||||
|
||||
使用匹配符%,可以将大量同类型的文件,只用一条规则就完成构建。
|
||||
|
||||
>待验证
|
||||
>
|
||||
>关于模式匹配有个误解区,%.o:%.c并不是直接去匹配文件目录里的文件,而是匹配上下文的东西:
|
||||
>
|
||||
>`%.o:%.c`
|
||||
>
|
||||
>`gcc main.c -o main.o`
|
||||
>
|
||||
>`main.o:main.c`
|
||||
>
|
||||
>当我们make的时候 会执行 gcc main.c -o main.o
|
||||
|
||||
|
||||
## 变量和赋值符
|
||||
|
||||
Makefile 允许使用等号自定义变量。
|
||||
|
||||
调用时,变量需要放在 $( ) 之中。
|
||||
|
||||
~~~
|
||||
txt = Hello World
|
||||
test:
|
||||
@echo $(txt)
|
||||
|
||||
~~~
|
||||
|
||||
调用Shell变量,需要在美元符号前,再加一个美元符号,这是因为Make命令会对美元符号转义。
|
||||
|
||||
~~~
|
||||
test:
|
||||
@echo $$HOME
|
||||
|
||||
~~~
|
||||
|
||||
有时,变量的值可能指向另一个变量。
|
||||
|
||||
~~~
|
||||
v1 = $(v2)
|
||||
|
||||
~~~
|
||||
|
||||
上面代码中,变量 v1 的值是另一个变量 v2。这时会产生一个问题,v1 的值到底在定义时扩展(**静态扩展**),还是在运行时扩展(**动态扩展**)?如果 v2 的值是动态的,这两种扩展方式的结果可能会差异很大。
|
||||
|
||||
为了解决类似问题,Makefile一共提供了四个赋值运算符 (=、:=、?=、+=),它们的区别请看[StackOverflow](http://stackoverflow.com/questions/448910/makefile-variable-assignment)。
|
||||
|
||||
~~~
|
||||
VARIABLE = value
|
||||
# 在执行时扩展,允许递归扩展。
|
||||
|
||||
VARIABLE := value
|
||||
# 在定义时扩展。
|
||||
|
||||
VARIABLE ?= value
|
||||
# 只有在该变量为空时才设置值。
|
||||
|
||||
VARIABLE += value
|
||||
# 将值追加到变量的尾端。
|
||||
|
||||
~~~
|
||||
|
||||
## 内置变量(Implicit Variables)
|
||||
|
||||
Make命令提供一系列内置变量,比如,$(CC) 指向当前使用的编译器,$(MAKE) 指向当前使用的Make工具。这主要是为了跨平台的兼容性,详细的内置变量清单见[手册](https://www.gnu.org/software/make/manual/html_node/Implicit-Variables.html)。
|
||||
|
||||
~~~
|
||||
output:
|
||||
$(CC) -o output input.c
|
||||
|
||||
~~~
|
||||
|
||||
## 自动变量(Automatic Variables)
|
||||
|
||||
(1)`$@`
|
||||
|
||||
`$@`指代当前目标,就是Make命令当前构建的那个目标。比如,make foo的 `$@` 就指代foo。
|
||||
|
||||
~~~
|
||||
a.txt b.txt:
|
||||
touch $@
|
||||
|
||||
~~~
|
||||
等同于下面的写法。
|
||||
|
||||
~~~
|
||||
a.txt:
|
||||
touch a.txt
|
||||
b.txt:
|
||||
touch b.txt
|
||||
|
||||
~~~
|
||||
|
||||
(2)`$<`
|
||||
|
||||
`$<` 指代第一个前置条件。比如,规则为 t: p1 p2,那么`$<` 就指代p1。
|
||||
|
||||
~~~
|
||||
a.txt: b.txt c.txt
|
||||
cp $< $@
|
||||
|
||||
~~~
|
||||
|
||||
等同于下面的写法。
|
||||
|
||||
~~~
|
||||
a.txt: b.txt c.txt
|
||||
cp b.txt a.txt
|
||||
|
||||
~~~
|
||||
|
||||
(3)`$?`
|
||||
|
||||
`$?` 指代比目标更新的所有前置条件,之间以空格分隔。比如,规则为 t: p1 p2,其中 p2 的时间戳比 t 新,`$?`就指代p2。
|
||||
|
||||
(4)`$^`
|
||||
|
||||
`$^` 指代所有前置条件,之间以空格分隔。比如,规则为 t: p1 p2,那么 `$^` 就指代 p1 p2 。
|
||||
|
||||
(5)`$*`
|
||||
|
||||
`$*` 指代匹配符 % 匹配的部分, 比如% 匹配 f1.txt 中的f1 ,`$*` 就表示 f1。
|
||||
|
||||
(6)`$(@D)` 和 `$(@F)`
|
||||
|
||||
`$(@D) `和` $(@F) `分别指向 `$@` 的目录名和文件名。比如,`$@`是 src/input.c,那么`$(@D)` 的值为 src ,`$(@F) `的值为 input.c。
|
||||
|
||||
(7)`$(<D)` 和 `$(<F)`
|
||||
|
||||
`$(<D) `和` $(<F) `分别指向 `$< `的目录名和文件名。
|
||||
|
||||
所有的自动变量清单,请看[手册](https://www.gnu.org/software/make/manual/html_node/Automatic-Variables.html)。下面是自动变量的一个例子。
|
||||
|
||||
~~~
|
||||
dest/%.txt: src/%.txt
|
||||
@[ -d dest ] || mkdir dest
|
||||
cp $< $@
|
||||
|
||||
~~~
|
||||
|
||||
上面代码将 src 目录下的 txt 文件,拷贝到 dest 目录下。首先判断 dest 目录是否存在,如果不存在就新建,然后,`$<` 指代前置文件(src/%.txt), `$@` 指代目标文件(dest/%.txt)。
|
||||
|
||||
|
||||
## 判断与循环
|
||||
|
||||
Makefile使用 Bash 语法,完成判断和循环。
|
||||
|
||||
~~~
|
||||
ifeq ($(CC),gcc)
|
||||
libs=$(libs_for_gcc)
|
||||
else
|
||||
libs=$(normal_libs)
|
||||
endif
|
||||
|
||||
~~~
|
||||
|
||||
上面代码判断当前编译器是否 gcc ,然后指定不同的库文件。
|
||||
|
||||
~~~
|
||||
LIST = one two three
|
||||
all:
|
||||
for i in $(LIST); do \
|
||||
echo $$i; \
|
||||
done
|
||||
|
||||
# 等同于
|
||||
|
||||
all:
|
||||
for i in one two three; do \
|
||||
echo $i; \
|
||||
done
|
||||
~~~
|
||||
|
||||
## 函数
|
||||
|
||||
Makefile 还可以使用函数,格式如下。
|
||||
|
||||
~~~
|
||||
$(function arguments)
|
||||
# 或者
|
||||
${function arguments}
|
||||
~~~
|
||||
|
||||
Makefile提供了许多[内置函数](http://www.gnu.org/software/make/manual/html_node/Functions.html),可供调用。下面是几个常用的内置函数。
|
||||
|
||||
(1)shell 函数
|
||||
|
||||
shell 函数用来执行 shell 命令
|
||||
|
||||
~~~
|
||||
srcfiles := $(shell echo src/{00..99}.txt)
|
||||
~~~
|
||||
|
||||
(2)wildcard 函数
|
||||
|
||||
wildcard 函数用来在 Makefile 中,替换 Bash 的通配符。
|
||||
|
||||
~~~
|
||||
srcfiles := $(wildcard src/*.txt)
|
||||
|
||||
~~~
|
||||
|
||||
(3)subst 函数
|
||||
|
||||
subst 函数用来文本替换,格式如下。
|
||||
|
||||
~~~
|
||||
$(subst from,to,text)
|
||||
~~~
|
||||
|
||||
下面的例子将字符串"feet on the street"替换成"fEEt on the strEEt"。
|
||||
|
||||
~~~
|
||||
$(subst ee,EE,feet on the street)
|
||||
~~~
|
||||
|
||||
下面是一个稍微复杂的例子。
|
||||
|
||||
~~~
|
||||
comma:= ,
|
||||
empty:=
|
||||
# space变量用两个空变量作为标识符,当中是一个空格
|
||||
space:= $(empty) $(empty)
|
||||
foo:= a b c
|
||||
bar:= $(subst $(space),$(comma),$(foo))
|
||||
# bar is now `a,b,c'.
|
||||
~~~
|
||||
|
||||
(4)patsubst函数
|
||||
|
||||
patsubst 函数用于模式匹配的替换,格式如下。
|
||||
|
||||
~~~
|
||||
$(patsubst pattern,replacement,text)
|
||||
~~~
|
||||
|
||||
下面的例子将文件名"x.c.c bar.c",替换成"x.c.o bar.o"。
|
||||
|
||||
~~~
|
||||
$(patsubst %.c,%.o,x.c.c bar.c)
|
||||
~~~
|
||||
|
||||
(5)替换后缀名
|
||||
|
||||
替换后缀名函数的写法是:变量名 + 冒号 + 后缀名替换规则。它实际上patsubst函数的一种简写形式。
|
||||
|
||||
~~~
|
||||
min: $(OUTPUT:.js=.min.js)
|
||||
~~~
|
||||
|
||||
上面代码的意思是,将变量OUTPUT中的后缀名 .js 全部替换成 .min.js 。
|
||||
|
||||
# 实例
|
||||
|
||||
(1)执行多个目标
|
||||
|
||||
~~~
|
||||
.PHONY: cleanall cleanobj cleandiff
|
||||
|
||||
cleanall : cleanobj cleandiff
|
||||
rm program
|
||||
|
||||
cleanobj :
|
||||
rm *.o
|
||||
|
||||
cleandiff :
|
||||
rm *.diff
|
||||
~~~
|
||||
|
||||
上面代码可以调用不同目标,删除不同后缀名的文件,也可以调用一个目标(cleanall),删除所有指定类型的文件。
|
||||
|
||||
(2)编译C语言项目
|
||||
|
||||
~~~
|
||||
edit : main.o kbd.o command.o display.o
|
||||
cc -o edit main.o kbd.o command.o display.o
|
||||
|
||||
main.o : main.c defs.h
|
||||
cc -c main.c
|
||||
kbd.o : kbd.c defs.h command.h
|
||||
cc -c kbd.c
|
||||
command.o : command.c defs.h command.h
|
||||
cc -c command.c
|
||||
display.o : display.c defs.h
|
||||
cc -c display.c
|
||||
|
||||
clean :
|
||||
rm edit main.o kbd.o command.o display.o
|
||||
|
||||
.PHONY: edit clean
|
||||
|
||||
~~~
|
||||
@@ -1,806 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: shell
|
||||
tags: shell Linux script
|
||||
categories: Linux
|
||||
published: false
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
Shell有两种执行命令的方式:
|
||||
|
||||
* 交互式(Interactive):解释执行用户的命令,用户输入一条命令,Shell就解释执行一条。
|
||||
|
||||
* 批处理(Batch):用户事先写一个Shell脚本(Script),其中有很多条命令,让Shell一次把这些命令执行完,而不必一条一条地敲命令。
|
||||
|
||||
几种shell:
|
||||
bash(默认),sh,ash,csh,ksh
|
||||
|
||||
# 变量
|
||||
|
||||
变量名和等号之间不能有空格
|
||||
|
||||
首个字符必须为字母(a-z,A-Z)。
|
||||
|
||||
中间不能有空格,可以使用下划线(_)。
|
||||
|
||||
不能使用标点符号。
|
||||
|
||||
不能使用bash里的关键字(可用help命令查看保留关键字)。
|
||||
|
||||
使用变量,只要在变量名前面加美元符号(`$`)即可
|
||||
|
||||
加`{}`是为了帮助解释器识别变量的边界,推荐给所有变量引用加上花括号
|
||||
|
||||
使用 `readonly` 命令可以将变量定义为`只读`变量,只读变量的值不能被改变。
|
||||
|
||||
定义变量:`variableName="value"`
|
||||
|
||||
使用 `unset` 命令可以`删除`变量
|
||||
|
||||
|
||||
## 变量类型
|
||||
|
||||
运行shell时,会同时存在三种变量:
|
||||
|
||||
1) 局部变量
|
||||
|
||||
局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
|
||||
|
||||
2) 环境变量
|
||||
|
||||
所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
|
||||
|
||||
3) shell变量
|
||||
|
||||
shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
|
||||
|
||||
## 特殊变量
|
||||
|
||||
`$0` 当前脚本的文件名
|
||||
|
||||
`$n` 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是`$1`,第二个参数是`$2`。
|
||||
|
||||
`$# ` 传递给脚本或函数的参数个数。
|
||||
|
||||
`$*` 传递给脚本或函数的所有参数。
|
||||
|
||||
`$@` 传递给脚本或函数的所有参数。被双引号(" ")包含时,与 `$*` 稍有不同,下面将会讲到。
|
||||
|
||||
`$?` 上个命令的退出状态,或函数的返回值,大部分命令执行成功会返回 0,失败返回 1;不过,也有一些命令返回其他值,表示不同类型的错误。
|
||||
|
||||
`$$` 当前Shell进程ID。对于 Shell 脚本,就是这些脚本所在的进程ID。
|
||||
|
||||
`$*` 和 `$@` 的区别:`$*` 和 `$@` 都表示传递给函数或脚本的所有参数,不被双引号(" ")包含时,都以"`$1`" "`$2`" … "`$n`" 的形式输出所有参数;但是当它们被双引号(" ")包含时,"`$*`" 会将所有的参数作为一个整体,以"`$1` `$2` … `$n`"的形式输出所有参数;"`$@`" 会将各个参数分开,以"`$1`" "`$2`" … "`$n`" 的形式输出所有参数。
|
||||
|
||||
# 替换
|
||||
|
||||
转义字符
|
||||
|
||||
`\\` 反斜杠
|
||||
|
||||
`\a` 警报,响铃
|
||||
|
||||
`\b` 退格(删除键)
|
||||
|
||||
`\f` 换页(FF),将当前位置移到下页开头
|
||||
|
||||
`\n` 换行
|
||||
|
||||
`\r` 回车
|
||||
|
||||
`\t` 水平制表符(tab键)
|
||||
|
||||
`\v` 垂直制表符
|
||||
|
||||
-e 表示对转义字符进行替换
|
||||
|
||||
-E 选项禁止转义
|
||||
|
||||
-n 选项可以禁止插入换行符
|
||||
|
||||
## 命令替换
|
||||
|
||||
命令替换是指Shell可以先执行命令,将输出结果暂时保存,在适当的地方输出。
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
DATE=`date`
|
||||
echo "Date is $DATE"
|
||||
|
||||
USERS=`who | wc -l`
|
||||
echo "Logged in user are $USERS"
|
||||
|
||||
UP=`date ; uptime`
|
||||
echo "Uptime is $UP"
|
||||
~~~
|
||||
|
||||
|
||||
## 变量替换
|
||||
|
||||
变量替换可以根据变量的状态(是否为空、是否定义等)来改变它的值
|
||||
|
||||
`${var}` 变量本来的值
|
||||
|
||||
`${var:-word}` 如果变量 var 为空或已被删除(unset),那么返回 word,但不改变 var 的值。
|
||||
|
||||
`${var:=word}` 如果变量 var 为空或已被删除(unset),那么返回 word,并将 var 的值设置为 word。
|
||||
|
||||
`${var:?message}` 如果变量 var 为空或已被删除(unset),那么将消息 message 送到标准错误输出,可以用来检测变量 var 是否可以被正常赋值。若此替换出现在Shell脚本中,那么脚本将停止运行。
|
||||
|
||||
`${var:+word}` 如果变量 var 被定义,那么返回 word,但不改变 var 的值。
|
||||
|
||||
# 运算符
|
||||
|
||||
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
|
||||
|
||||
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
val=`expr 2 + 2`
|
||||
echo "Total value : $val"
|
||||
~~~
|
||||
|
||||
* 表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2,这与我们熟悉的大多数编程语言不一样。
|
||||
|
||||
* 完整的表达式要被 \` \` 包含,注意这个字符不是常用的单引号,在 Esc 键下边。
|
||||
|
||||
## 算术运算符
|
||||
|
||||
`+` 加法 `expr $a + $b`
|
||||
|
||||
`-` 减法 `expr $a - $b`
|
||||
|
||||
`*` 乘法 `expr $a \* $b`
|
||||
|
||||
`/` 除法 `expr $b / $a`
|
||||
|
||||
`%` 取余 `expr $b % $a`
|
||||
|
||||
`=` 赋值
|
||||
|
||||
`==` 相等。
|
||||
|
||||
`!=` 不相等。
|
||||
|
||||
乘号(*)前边必须加反斜杠(\)才能实现乘法运算
|
||||
|
||||
## 关系运算符
|
||||
|
||||
`-eq` 检测两个数是否相等,相等返回 true。
|
||||
|
||||
`-ne` 检测两个数是否相等,不相等返回 true。
|
||||
|
||||
`-gt` 检测左边的数是否大于右边的,如果是,则返回 true。
|
||||
|
||||
`-lt` 检测左边的数是否小于右边的,如果是,则返回 true。
|
||||
|
||||
`-ge` 检测左边的数是否大等于右边的,如果是,则返回 true。
|
||||
|
||||
`-le` 检测左边的数是否小于等于右边的,如果是,则返回 true。
|
||||
|
||||
## 布尔运算符
|
||||
|
||||
`!` 非运算,表达式为 true 则返回 false,否则返回 true。
|
||||
|
||||
`-o` 或运算,有一个表达式为 true 则返回 true。
|
||||
|
||||
`-a` 与运算,两个表达式都为 true 才返回 true。
|
||||
|
||||
## 字符串运算符
|
||||
|
||||
`=` 检测两个字符串是否相等,相等返回 true。
|
||||
|
||||
`!=` 检测两个字符串是否相等,不相等返回 true。
|
||||
|
||||
`-z str` 检测字符串长度是否为0,为0返回 true。
|
||||
|
||||
`-n str` 检测字符串长度是否不为0,不为0返回 true。
|
||||
|
||||
`str` 检测字符串是否为空,不为空返回 true。
|
||||
|
||||
## 文件测试运算符
|
||||
|
||||
文件测试运算符用于检测 Unix 文件的各种属性。
|
||||
|
||||
`-b file` 检测文件是否是块设备文件,如果是,则返回 true。
|
||||
|
||||
`-c file` 检测文件是否是字符设备文件,如果是,则返回 true。
|
||||
|
||||
`-d file` 检测文件是否是目录,如果是,则返回 true。
|
||||
|
||||
`-f file` 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。
|
||||
|
||||
`-g file` 检测文件是否设置了 SGID 位,如果是,则返回 true。
|
||||
|
||||
`-k file` 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。
|
||||
|
||||
`-p file` 检测文件是否是具名管道,如果是,则返回 true。
|
||||
|
||||
`-u file` 检测文件是否设置了 SUID 位,如果是,则返回 true。
|
||||
|
||||
`-r file` 检测文件是否可读,如果是,则返回 true。
|
||||
|
||||
`-w file` 检测文件是否可写,如果是,则返回 true。
|
||||
|
||||
`-x file` 检测文件是否可执行,如果是,则返回 true。
|
||||
|
||||
`-s file` 检测文件是否为空(文件大小是否大于0),不为空返回 true。
|
||||
|
||||
`-e file` 检测文件(包括目录)是否存在,如果是,则返回 true。
|
||||
|
||||
# 注释
|
||||
|
||||
以“# ”开头的行就是注释,会被解释器忽略。
|
||||
|
||||
sh里没有多行注释,只能每一行加一个# 号。可以把这一段要注释的代码用一对花括号括起来,定义成一个函数,没有地方调用这个函数,这块代码就不会执行,达到了和注释一样的效果。
|
||||
|
||||
# 字符串
|
||||
|
||||
单引号字符串的限制:
|
||||
|
||||
* 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
|
||||
|
||||
* 单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
|
||||
|
||||
双引号的优点:
|
||||
|
||||
* 双引号里可以有变量
|
||||
|
||||
* 双引号里可以出现转义字符
|
||||
|
||||
拼接字符串
|
||||
|
||||
~~~
|
||||
your_name="qinjx"
|
||||
greeting="hello, "$your_name" !"
|
||||
greeting_1="hello, ${your_name} !"
|
||||
|
||||
echo $greeting $greeting_1
|
||||
~~~
|
||||
|
||||
获取字符串长度
|
||||
|
||||
~~~
|
||||
string="abcd"
|
||||
echo ${# string} # 输出 4
|
||||
~~~
|
||||
|
||||
提取子字符串
|
||||
|
||||
~~~
|
||||
string="alibaba is a great company"
|
||||
echo ${string:1:4} # 输出liba
|
||||
~~~
|
||||
|
||||
查找子字符串
|
||||
|
||||
`expr index String1 String2` 返回 String1 中包含 String2 中任意字符的第一个位置。(从1开始数)
|
||||
|
||||
~~~
|
||||
string="alibaba is a great company"
|
||||
echo `expr index "$string" is`
|
||||
~~~
|
||||
|
||||
# 数组
|
||||
|
||||
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。类似与C语言,数组元素的下标由0开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。
|
||||
|
||||
## 定义
|
||||
|
||||
在Shell中,用括号来表示数组,数组元素用“空格”符号分割开。定义数组的一般形式为:array_name=(value1 ... valuen)
|
||||
|
||||
~~~
|
||||
array_name=(value0 value1 value2 value3)
|
||||
|
||||
array_name=(
|
||||
value0
|
||||
value1
|
||||
value2
|
||||
value3
|
||||
)
|
||||
|
||||
array_name[0]=value0
|
||||
array_name[1]=value1
|
||||
array_name[2]=value2
|
||||
~~~
|
||||
|
||||
## 读取
|
||||
|
||||
~~~
|
||||
valuen=${array_name[2]}
|
||||
~~~
|
||||
|
||||
使用`@`或 `*` 可以获取数组中的所有元素
|
||||
|
||||
~~~
|
||||
${array_name[*]}
|
||||
${array_name[@]}
|
||||
~~~
|
||||
|
||||
## 长度
|
||||
|
||||
~~~
|
||||
# 取得数组元素的个数
|
||||
length=${# array_name[@]}
|
||||
# 或者
|
||||
length=${# array_name[*]}
|
||||
# 取得数组单个元素的长度
|
||||
lengthn=${# array_name[n]}
|
||||
~~~
|
||||
|
||||
# echo
|
||||
|
||||
echo是Shell的一个内部指令,用于在屏幕上打印出指定的字符串。
|
||||
|
||||
`-n` 不要在最后自动换行
|
||||
|
||||
`-e` 若字符串中出现以下字符,则特别加以处理,而不会将它当成一般
|
||||
|
||||
文字输出:
|
||||
|
||||
>`\a` 发出警告声;
|
||||
>
|
||||
>`\b` 删除前一个字符;
|
||||
>
|
||||
>`\c` 最后不加上换行符号;
|
||||
>
|
||||
>`\f` 换行但光标仍旧停留在原来的位置;
|
||||
>
|
||||
>`\n` 换行且光标移至行首;
|
||||
>
|
||||
>`\r` 光标移至行首,但不换行;
|
||||
>
|
||||
>`\t` 插入tab;
|
||||
>
|
||||
>`\v` 与\f相同;
|
||||
>
|
||||
>`\\` 插入\字符;
|
||||
>
|
||||
>`\nnn` 插入nnn(八进制)所代表的ASCII字符;
|
||||
|
||||
`–help` 显示帮助
|
||||
|
||||
`–version` 显示版本信息
|
||||
|
||||
## 原样输出字符串
|
||||
|
||||
若需要原样输出字符串(不进行转义),请使用单引号
|
||||
|
||||
~~~
|
||||
echo '$name\"'
|
||||
~~~
|
||||
|
||||
## 显示命令执行结果
|
||||
|
||||
~~~
|
||||
echo `date`
|
||||
~~~
|
||||
|
||||
# printf
|
||||
|
||||
printf 命令用于格式化输出, 是echo命令的增强版。它是C语言printf()库函数的一个有限的变形,并且在语法上有些不同。
|
||||
|
||||
注意:printf 由 POSIX 标准所定义,移植性要比 echo 好。
|
||||
|
||||
printf 不像 echo 那样会自动换行,必须显式添加换行符(\n)。
|
||||
|
||||
~~~
|
||||
$printf "Hello, Shell\n"
|
||||
Hello, Shell
|
||||
$
|
||||
|
||||
~~~
|
||||
printf 命令的语法
|
||||
|
||||
~~~
|
||||
printf format-string [arguments...]
|
||||
~~~
|
||||
|
||||
format-string 为格式控制字符串,arguments 为参数列表。
|
||||
|
||||
这里仅说明与C语言printf()函数的不同:
|
||||
|
||||
* printf 命令不用加括号
|
||||
|
||||
* format-string 可以没有引号,但最好加上,单引号双引号均可。
|
||||
|
||||
* 参数多于格式控制符(%)时,format-string 可以重用,可以将所有参数都转换。
|
||||
|
||||
* arguments 使用空格分隔,不用逗号。
|
||||
|
||||
注意,根据POSIX标准,浮点格式%e、%E、%f、%g与%G是“不需要被支持”。这是因为awk支持浮点预算,且有它自己的printf语句。这样Shell程序中需要将浮点数值进行格式化的打印时,可使用小型的awk程序实现。然而,内建于bash、ksh93和zsh中的printf命令都支持浮点格式。
|
||||
|
||||
# 分支
|
||||
|
||||
Shell 有三种 if ... else 语句:
|
||||
|
||||
* if ... fi 语句;
|
||||
|
||||
* if ... else ... fi 语句;
|
||||
|
||||
* if ... elif ... else ... fi 语句。
|
||||
|
||||
|
||||
最后必须以 fi 来结尾闭合 if,fi 就是 if 倒过来拼写,后面也会遇见。
|
||||
注意:expression 和方括号([ ])之间必须有空格,否则会有语法错误。
|
||||
|
||||
## if
|
||||
|
||||
~~~
|
||||
if [ expression ]
|
||||
then
|
||||
statements
|
||||
fi
|
||||
~~~
|
||||
|
||||
## if else
|
||||
|
||||
~~~
|
||||
if [ expression ]
|
||||
then
|
||||
Statements
|
||||
else
|
||||
Statements
|
||||
fi
|
||||
~~~
|
||||
|
||||
## if elif fi
|
||||
|
||||
~~~
|
||||
if [ expression 1 ]
|
||||
then
|
||||
Statements
|
||||
elif [ expression 2 ]
|
||||
then
|
||||
Statements
|
||||
elif [ expression 3 ]
|
||||
then
|
||||
Statements
|
||||
else
|
||||
Statements
|
||||
fi
|
||||
~~~
|
||||
|
||||
if ... else 语句也可以写成一行,以命令的方式来运行,经常与 test 命令结合使用
|
||||
`test` 命令用于检查某个条件是否成立,与方括号([ ])类似。
|
||||
|
||||
~~~
|
||||
if test $[2*3] -eq $[1+5]; then echo 'The two numbers are equal!'; fi;
|
||||
~~~
|
||||
|
||||
# 多分枝选择
|
||||
|
||||
case ... esac 与其他语言中的 switch ... case 语句类似,是一种多分枝选择结构。
|
||||
case 语句匹配一个值或一个模式,如果匹配成功,执行相匹配的命令。
|
||||
|
||||
~~~
|
||||
case 值 in
|
||||
模式1)
|
||||
command1
|
||||
command2
|
||||
command3
|
||||
;;
|
||||
模式2)
|
||||
command1
|
||||
command2
|
||||
command3
|
||||
;;
|
||||
*)
|
||||
command1
|
||||
command2
|
||||
command3
|
||||
;;
|
||||
esac
|
||||
~~~
|
||||
|
||||
取值后面必须为关键字 `in`
|
||||
|
||||
每一模式必须以`)`结束
|
||||
|
||||
`;;` 与其他语言中的 break 类似
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
option="${1}"
|
||||
case ${option} in
|
||||
-f) FILE="${2}"
|
||||
echo "File name is $FILE"
|
||||
;;
|
||||
-d) DIR="${2}"
|
||||
echo "Dir name is $DIR"
|
||||
;;
|
||||
*)
|
||||
echo "`basename ${0}`:usage: [-f file] | [-d directory]"
|
||||
exit 1 # Command to come out of the program with status 1
|
||||
;;
|
||||
esac
|
||||
~~~
|
||||
|
||||
# 循环
|
||||
|
||||
## for
|
||||
|
||||
~~~
|
||||
for 变量 in 列表
|
||||
do
|
||||
command1
|
||||
command2
|
||||
...
|
||||
commandN
|
||||
done
|
||||
~~~
|
||||
|
||||
列表是一组值(数字、字符串等)组成的序列,每个值通过空格分隔。每循环一次,就将列表中的下一个值赋给变量。
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
for loop in 1 2 3 4 5
|
||||
do
|
||||
echo "The value is: $loop"
|
||||
done
|
||||
~~~
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
for FILE in $HOME/.bash*
|
||||
do
|
||||
echo $FILE
|
||||
done
|
||||
~~~
|
||||
|
||||
## while
|
||||
|
||||
~~~
|
||||
while command
|
||||
do
|
||||
statements
|
||||
done
|
||||
~~~
|
||||
|
||||
~~~
|
||||
COUNTER=0
|
||||
while [ $COUNTER -lt 5 ]
|
||||
do
|
||||
COUNTER=`expr $COUNTER+1`
|
||||
echo $COUNTER
|
||||
done
|
||||
~~~
|
||||
|
||||
while循环可用于读取键盘信息
|
||||
|
||||
~~~
|
||||
echo 'type <CTRL-D> to terminate'
|
||||
echo -n 'enter your most liked film: '
|
||||
while read FILM
|
||||
do
|
||||
echo "Yeah! great film the $FILM"
|
||||
done
|
||||
~~~
|
||||
|
||||
## until
|
||||
|
||||
until 循环执行一系列命令直至条件为 `true` 时`停止`。until 循环与 while 循环在处理方式上刚好相反。一般while循环优于until循环,但在某些时候,也只是极少数情况下,until 循环更加有用。
|
||||
|
||||
~~~
|
||||
until command
|
||||
do
|
||||
statements
|
||||
done
|
||||
~~~
|
||||
|
||||
## 跳出循环
|
||||
|
||||
### break
|
||||
|
||||
break将终止循环体中的后续操作
|
||||
|
||||
在嵌套循环中,break 命令后面还可以跟一个整数,表示跳出第几层循环`break n`
|
||||
|
||||
### continue
|
||||
|
||||
continue跳出当次循环
|
||||
|
||||
同样,continue 后面也可以跟一个数字,表示跳出第几层循环`continue n`
|
||||
|
||||
# 函数
|
||||
|
||||
## 定义
|
||||
|
||||
~~~
|
||||
function_name () {
|
||||
list of commands
|
||||
[ return value ]
|
||||
}
|
||||
|
||||
# 可以加上function 关键字
|
||||
function function_name () {
|
||||
list of commands
|
||||
[ return value ]
|
||||
}
|
||||
# 函数返回值,可以显式增加return语句;如果不加,会将最后一条命令运行结果作为返回值。
|
||||
~~~
|
||||
|
||||
Shell 函数返回值只能是整数,一般用来表示函数执行成功与否,0表示成功,其他值表示失败。如果 return 其他数据,比如一个字符串,往往会得到错误提示:“numeric argument required”。
|
||||
|
||||
如果一定要让函数返回字符串,那么可以先定义一个变量,用来接收函数的计算结果,脚本在需要的时候访问这个变量来获得函数返回值。
|
||||
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
funWithReturn(){
|
||||
echo "The function is to get the sum of two numbers..."
|
||||
echo -n "Input first number: "
|
||||
read aNum
|
||||
echo -n "Input another number: "
|
||||
read anotherNum
|
||||
echo "The two numbers are $aNum and $anotherNum !"
|
||||
return $(($aNum+$anotherNum))
|
||||
# 两组括号的意思是做算术运算,如果不这么写直接写$a+$b的话,是按字符串理解的,就是25+50这个字符串
|
||||
}
|
||||
funWithReturn
|
||||
# Capture value returnd by last command
|
||||
ret=$?
|
||||
echo "The sum of two numbers is $ret !"
|
||||
~~~
|
||||
|
||||
调用函数只需要给出函数名,不需要加括号。
|
||||
|
||||
函数返回值在调用该函数后通过 `$?` 来获得。
|
||||
|
||||
## 嵌套
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
|
||||
# Calling one function from another
|
||||
number_one () {
|
||||
echo "Url_1 is http://see.xidian.edu.cn/cpp/shell/"
|
||||
number_two
|
||||
}
|
||||
|
||||
number_two () {
|
||||
echo "Url_2 is http://see.xidian.edu.cn/cpp/u/xitong/"
|
||||
}
|
||||
|
||||
number_one
|
||||
~~~
|
||||
|
||||
## 删除
|
||||
|
||||
~~~
|
||||
unset .f function_name
|
||||
~~~
|
||||
|
||||
## 参数
|
||||
|
||||
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 `$n` 的形式来获取参数的值,例如,`$1`表示第一个参数,`$2`表示第二个参数...
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
funWithParam(){
|
||||
echo "The value of the first parameter is $1 !"
|
||||
echo "The value of the second parameter is $2 !"
|
||||
echo "The value of the tenth parameter is $10 !"
|
||||
echo "The value of the tenth parameter is ${10} !"
|
||||
echo "The value of the eleventh parameter is ${11} !"
|
||||
echo "The amount of the parameters is $# !" # 参数个数
|
||||
echo "The string of the parameters is $* !" # 传递给函数的所有参数
|
||||
}
|
||||
funWithParam 1 2 3 4 5 6 7 8 9 34 73
|
||||
~~~
|
||||
|
||||
注意,`$10` 不能获取第十个参数,获取第十个参数需要`${10}`。当n>=10时,需要使用`${n}`来获取参数。
|
||||
|
||||
特殊参数
|
||||
|
||||
`$# ` 传递给函数的参数个数。
|
||||
|
||||
`$*` 显示所有传递给函数的参数。
|
||||
|
||||
`$@` 与`$*`相同,但是略有区别,请查看Shell特殊变量。
|
||||
|
||||
`$?` 函数的返回值。
|
||||
|
||||
# IO重定向
|
||||
|
||||
~~~
|
||||
command > file
|
||||
command < file
|
||||
~~~
|
||||
|
||||
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
|
||||
|
||||
* 标准输入文件(`stdin`):stdin的文件描述符为`0`,Unix程序默认从stdin读取数据。
|
||||
|
||||
* 标准输出文件(`stdout`):stdout 的文件描述符为`1`,Unix程序默认向stdout输出数据。
|
||||
|
||||
* 标准错误文件(`stderr`):stderr的文件描述符为`2`,Unix程序会向stderr流中写入错误信息。
|
||||
|
||||
stderr 重定向到 file
|
||||
|
||||
~~~
|
||||
command 2 > file
|
||||
~~~
|
||||
|
||||
将 stdout 和 stderr 合并后重定向到 file
|
||||
|
||||
~~~
|
||||
command > file 2>&1
|
||||
~~~
|
||||
|
||||
默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。
|
||||
|
||||
`command > file` 将输出重定向到 file。
|
||||
|
||||
`command < file` 将输入重定向到 file。
|
||||
|
||||
`command >> file` 将输出以追加的方式重定向到 file。
|
||||
|
||||
`n > file` 将文件描述符为 n 的文件重定向到 file。
|
||||
|
||||
`n >> file` 将文件描述符为 n 的文件以追加的方式重定向到 file。
|
||||
|
||||
`n >& m` 将输出文件 m 和 n 合并。
|
||||
|
||||
`n <& m` 将输入文件 m 和 n 合并。
|
||||
|
||||
`<< tag` 将开始标记 tag 和结束标记 tag 之间的内容作为输入。
|
||||
|
||||
## Here Document
|
||||
|
||||
~~~
|
||||
command << delimiter
|
||||
document
|
||||
delimiter
|
||||
~~~
|
||||
|
||||
它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。
|
||||
注意:
|
||||
|
||||
* 结尾的delimiter 一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。
|
||||
|
||||
* 开始的delimiter前后的空格会被忽略掉。
|
||||
|
||||
## /dev/null
|
||||
|
||||
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到”禁止输出“的效果。
|
||||
屏蔽 stdout 和 stderr
|
||||
|
||||
~~~
|
||||
command > /dev/null 2>&1
|
||||
~~~
|
||||
|
||||
# 文件包含
|
||||
|
||||
Shell 也可以包含外部脚本,将外部脚本的内容合并到当前脚本
|
||||
|
||||
~~~
|
||||
. filename
|
||||
# 或
|
||||
source filename
|
||||
~~~
|
||||
|
||||
两种方式的效果相同,简单起见,一般使用点号(.),但是注意点号(.)和文件名中间有一空格
|
||||
|
||||
脚本 subscript.sh
|
||||
|
||||
~~~
|
||||
url="http://see.xidian.edu.cn/cpp/view/2738.html"
|
||||
~~~
|
||||
|
||||
引入当前目录下的subscript.sh脚本
|
||||
|
||||
~~~
|
||||
# !/bin/bash
|
||||
. ./subscript.sh
|
||||
echo $url
|
||||
~~~
|
||||
@@ -1,63 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: JS 闭包
|
||||
tags: closure javascript script
|
||||
categories: front-end
|
||||
published: false
|
||||
---
|
||||
|
||||
在JS中,当内部的方法被其他对象引用,如果内部的方法使用了外部方法的变量,将造成外部方法无法释放,变量将被保持,此时将形成闭包。
|
||||
|
||||
看一个例子
|
||||
|
||||
~~~html
|
||||
<a href="# " id="closureTest1">闭包测试1</a><br />
|
||||
<a href="# " id="closureTest2">闭包测试2</a><br />
|
||||
<a href="# " id="closureTest3">闭包测试3</a><br />
|
||||
~~~
|
||||
|
||||
~~~javascript
|
||||
function closureTest(){
|
||||
for (var i = 1; i < 4; i++) {
|
||||
var element = document.getElementById('closureTest' + i);
|
||||
element.onclick = function(){
|
||||
alert(i);
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
此时无论点击哪个超链接,弹出的都是`3`,这是因为onclick触发时,绑定函数才会去初始化`i`的值,而`i`引用自外部函数`closureTest`,在closureTest中,`i`早已递增到3。
|
||||
|
||||
|
||||
解决办法很简单,不闭包就行了。
|
||||
|
||||
~~~javascript
|
||||
function badClosureExample(){
|
||||
for (var i = 1; i <4; i++) {
|
||||
var element = document.getElementById('closureTest' + i);
|
||||
element.onclick = clickCall(i);
|
||||
}
|
||||
}
|
||||
|
||||
function clickCall(j){
|
||||
return function(){
|
||||
alert('您单击的是第' + j + '个链接');
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
闭包也并非全然有害,有时我们也可以利用做些有趣的事,例如定时任务的传参
|
||||
|
||||
~~~javascript
|
||||
function bind(){
|
||||
var element = document.getElementById('closureTest0');
|
||||
element.onclick = function(){
|
||||
setTimeout(function(p){
|
||||
return function(){
|
||||
alert(p);
|
||||
}
|
||||
}('998'), 1000); //延迟1秒弹出提示
|
||||
}
|
||||
}
|
||||
~~~
|
||||
@@ -1,135 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: DIY的 ajax 框架
|
||||
tags: ajax javascript
|
||||
categories: front-end
|
||||
published: true
|
||||
---
|
||||
|
||||
话不多说,直接上源码,用了传说中的伪面向对象写法
|
||||
|
||||
加了个`jsonp`用来跨域,当然了,需要服务端支持才有效
|
||||
|
||||
~~~javascript
|
||||
(function(){
|
||||
var WT = {
|
||||
|
||||
ID_SEL:'# ',
|
||||
|
||||
CLA_SEL:'.',
|
||||
|
||||
newInstance:function(){
|
||||
|
||||
var instance = {};
|
||||
|
||||
var setAttrs = function (dom,attrs){
|
||||
for(var key in attrs){
|
||||
dom.setAttribute(key,attrs[key]);
|
||||
}
|
||||
}
|
||||
|
||||
var convertParam = function(data){
|
||||
var param = [];
|
||||
for (var key in data) {
|
||||
param.push(encodeURIComponent(key) + '=' + encodeURIComponent(data[key]));
|
||||
}
|
||||
return param;
|
||||
}
|
||||
|
||||
instance.select = function(selector){
|
||||
var h = selector.charAt(0);
|
||||
var o = null;
|
||||
var m = null;
|
||||
if(h==WT.ID_SEL){
|
||||
m = selector.substr(1);
|
||||
o = document.getElementById(m);
|
||||
}
|
||||
else if(h==WT.CLA_SEL){
|
||||
//TODO
|
||||
//m = selector.substr(1);
|
||||
//o = document.getElementsByClassName(m);
|
||||
}else {
|
||||
m = selector;
|
||||
o = document.getElementsByTagName(m);
|
||||
}
|
||||
return o;
|
||||
}
|
||||
|
||||
instance.load = function(tagName, attrs, callback){
|
||||
var dom = document.createElement(tagName);
|
||||
setAttrs(dom,attrs);
|
||||
dom.onload=function(){
|
||||
typeof callback === 'function' && callback.call(this,dom);
|
||||
dom = null; callback =null;
|
||||
}
|
||||
return dom;
|
||||
}
|
||||
|
||||
|
||||
instance.jsonp = function(jp){
|
||||
//---- attributes----//
|
||||
var callback = jp.callback;
|
||||
var url = jp.url;
|
||||
var data = jp.data;
|
||||
|
||||
var cn = 'jsonp'+ Date.now();
|
||||
window[cn] = callback;
|
||||
var param = convertParam(data);
|
||||
param.push('callback=' + cn);
|
||||
url += (url.indexOf('?')==-1 ? '?' : '') + param.join('&');
|
||||
|
||||
var script = document.createElement('script');
|
||||
script.type = 'text/javascript';
|
||||
script.onload = script.onreadystatechange = function() {
|
||||
this.parentNode.removeChild(script);
|
||||
delete window[cn];
|
||||
script.onload = script.onreadystatechange = null;
|
||||
}
|
||||
script.src = url;
|
||||
this.select('body')[0].appendChild(script);
|
||||
}
|
||||
|
||||
instance.ajax = function(jp){
|
||||
//---- attributes----//
|
||||
var type = jp.type;type ? type : 'GET';
|
||||
var url = jp.url;
|
||||
var data = jp.data;
|
||||
var success = jp.success;
|
||||
|
||||
var xhr = XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP");
|
||||
xhr.open(type,url);
|
||||
if (type.toUpperCase() === 'POST') {
|
||||
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
|
||||
}
|
||||
xhr.onreadystatechange = function(){
|
||||
if(xhr.readyState==4){
|
||||
typeof success === 'function' && success(eval('(' + xhr.responseText + ')'), xhr.status);
|
||||
xhr = null;
|
||||
}
|
||||
}
|
||||
xhr.send(convertParam(data).join('&'));
|
||||
}
|
||||
|
||||
instance.loadImg = function (url, callback) {
|
||||
/** img的onload在图片下载完成后,dom加载前发生 **/
|
||||
this.load('img',{src:url},callback);
|
||||
}
|
||||
|
||||
instance.loadCss = function(url,callback){
|
||||
/** css的onload 在 dom加载后发生 **/
|
||||
var dom = this.load('link',{rel:'stylesheet',type:'text/css',href:url},callback);
|
||||
this.select('head')[0].appendChild(dom);
|
||||
}
|
||||
|
||||
instance.loadJs = function(url,callback){
|
||||
/** js的onload 在 dom加载后发生 **/
|
||||
var js = this.load('script',{type:'text/javascript',src:url},callback);
|
||||
this.select('body')[0].appendChild(js);
|
||||
}
|
||||
|
||||
return instance;
|
||||
}
|
||||
};
|
||||
window['$'] = WT.newInstance();
|
||||
})();
|
||||
~~~
|
||||
@@ -1,341 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: SQL 拼接
|
||||
tags: sql database Java
|
||||
categories: database
|
||||
published: true
|
||||
---
|
||||
|
||||
在java中进行SQL拼接是一件无比痛苦的工作,这是由于需要通过判断参数动态生成SQL
|
||||
|
||||
而且拼接时产生满屏幕的加号或者append,使SQL几乎失去了可读性,那么丢失`WHERE`,`AND`,逗号等语法错误将随之而来
|
||||
|
||||
最近研究mybatis时发现了一个非常好用的工具类 SQL Builder [^sqlBuilder]
|
||||
|
||||
|
||||
## 示例
|
||||
|
||||
~~~java
|
||||
@Test
|
||||
public void test(){
|
||||
String sql = new SQL(){ {
|
||||
SELECT("name");
|
||||
SELECT("password");
|
||||
SELECT("sex");
|
||||
FROM("student s");
|
||||
INNER_JOIN("info i on s.id = i.id");
|
||||
WHERE(String.format("name = '%s'","HanMeiMei"));
|
||||
} }.toString();
|
||||
|
||||
System.out.println(sql);
|
||||
}
|
||||
~~~
|
||||
|
||||
运行结果为:
|
||||
|
||||
SELECT name, password, sex
|
||||
|
||||
FROM student s
|
||||
|
||||
INNER JOIN info i on s.id = i.id
|
||||
|
||||
WHERE (name = 'HanMeiMei' AND i.sex = 1)
|
||||
|
||||
SQL的拼接词都自动生成了
|
||||
|
||||
## 源码
|
||||
|
||||
事实上不必为了使用这个类而引入Mybatis,SQL Builder非常简单,简单到没有使用任何第三方类库,只需将这个类复制粘贴一下就可以直接用了。
|
||||
|
||||
SQL Builder 全部代码
|
||||
|
||||
~~~java
|
||||
import java.io.IOException;
|
||||
import java.util.ArrayList;
|
||||
import java.util.List;
|
||||
|
||||
public abstract class AbstractSQL<T> {
|
||||
|
||||
private static final String AND = ") \nAND (";
|
||||
private static final String OR = ") \nOR (";
|
||||
|
||||
public abstract T getSelf();
|
||||
|
||||
public T UPDATE(String table) {
|
||||
sql().statementType = SQLStatement.StatementType.UPDATE;
|
||||
sql().tables.add(table);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T SET(String sets) {
|
||||
sql().sets.add(sets);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T INSERT_INTO(String tableName) {
|
||||
sql().statementType = SQLStatement.StatementType.INSERT;
|
||||
sql().tables.add(tableName);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T VALUES(String columns, String values) {
|
||||
sql().columns.add(columns);
|
||||
sql().values.add(values);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T SELECT(String columns) {
|
||||
sql().statementType = SQLStatement.StatementType.SELECT;
|
||||
sql().select.add(columns);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T SELECT_DISTINCT(String columns) {
|
||||
sql().distinct = true;
|
||||
SELECT(columns);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T DELETE_FROM(String table) {
|
||||
sql().statementType = SQLStatement.StatementType.DELETE;
|
||||
sql().tables.add(table);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T FROM(String table) {
|
||||
sql().tables.add(table);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T JOIN(String join) {
|
||||
sql().join.add(join);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T INNER_JOIN(String join) {
|
||||
sql().innerJoin.add(join);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T LEFT_OUTER_JOIN(String join) {
|
||||
sql().leftOuterJoin.add(join);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T RIGHT_OUTER_JOIN(String join) {
|
||||
sql().rightOuterJoin.add(join);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T OUTER_JOIN(String join) {
|
||||
sql().outerJoin.add(join);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T WHERE(String conditions) {
|
||||
sql().where.add(conditions);
|
||||
sql().lastList = sql().where;
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T OR() {
|
||||
sql().lastList.add(OR);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T AND() {
|
||||
sql().lastList.add(AND);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T GROUP_BY(String columns) {
|
||||
sql().groupBy.add(columns);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T HAVING(String conditions) {
|
||||
sql().having.add(conditions);
|
||||
sql().lastList = sql().having;
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
public T ORDER_BY(String columns) {
|
||||
sql().orderBy.add(columns);
|
||||
return getSelf();
|
||||
}
|
||||
|
||||
private SQLStatement sql = new SQLStatement();
|
||||
|
||||
private SQLStatement sql() {
|
||||
return sql;
|
||||
}
|
||||
|
||||
public <A extends Appendable> A usingAppender(A a) {
|
||||
sql().sql(a);
|
||||
return a;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
StringBuilder sb = new StringBuilder();
|
||||
sql().sql(sb);
|
||||
return sb.toString();
|
||||
}
|
||||
|
||||
private static class SafeAppendable {
|
||||
private final Appendable a;
|
||||
private boolean empty = true;
|
||||
|
||||
public SafeAppendable(Appendable a) {
|
||||
super();
|
||||
this.a = a;
|
||||
}
|
||||
|
||||
public SafeAppendable append(CharSequence s) {
|
||||
try {
|
||||
if (empty && s.length() > 0) empty = false;
|
||||
a.append(s);
|
||||
} catch (IOException e) {
|
||||
throw new RuntimeException(e);
|
||||
}
|
||||
return this;
|
||||
}
|
||||
|
||||
public boolean isEmpty() {
|
||||
return empty;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
private static class SQLStatement {
|
||||
|
||||
public enum StatementType {
|
||||
DELETE, INSERT, SELECT, UPDATE
|
||||
}
|
||||
|
||||
StatementType statementType;
|
||||
List<String> sets = new ArrayList<String>();
|
||||
List<String> select = new ArrayList<String>();
|
||||
List<String> tables = new ArrayList<String>();
|
||||
List<String> join = new ArrayList<String>();
|
||||
List<String> innerJoin = new ArrayList<String>();
|
||||
List<String> outerJoin = new ArrayList<String>();
|
||||
List<String> leftOuterJoin = new ArrayList<String>();
|
||||
List<String> rightOuterJoin = new ArrayList<String>();
|
||||
List<String> where = new ArrayList<String>();
|
||||
List<String> having = new ArrayList<String>();
|
||||
List<String> groupBy = new ArrayList<String>();
|
||||
List<String> orderBy = new ArrayList<String>();
|
||||
List<String> lastList = new ArrayList<String>();
|
||||
List<String> columns = new ArrayList<String>();
|
||||
List<String> values = new ArrayList<String>();
|
||||
boolean distinct;
|
||||
|
||||
private void sqlClause(SafeAppendable builder, String keyword, List<String> parts, String open, String close,
|
||||
String conjunction) {
|
||||
if (!parts.isEmpty()) {
|
||||
if (!builder.isEmpty())
|
||||
builder.append("\n");
|
||||
builder.append(keyword);
|
||||
builder.append(" ");
|
||||
builder.append(open);
|
||||
String last = "________";
|
||||
for (int i = 0, n = parts.size(); i < n; i++) {
|
||||
String part = parts.get(i);
|
||||
if (i > 0 && !part.equals(AND) && !part.equals(OR) && !last.equals(AND) && !last.equals(OR)) {
|
||||
builder.append(conjunction);
|
||||
}
|
||||
builder.append(part);
|
||||
last = part;
|
||||
}
|
||||
builder.append(close);
|
||||
}
|
||||
}
|
||||
|
||||
private String selectSQL(SafeAppendable builder) {
|
||||
if (distinct) {
|
||||
sqlClause(builder, "SELECT DISTINCT", select, "", "", ", ");
|
||||
} else {
|
||||
sqlClause(builder, "SELECT", select, "", "", ", ");
|
||||
}
|
||||
|
||||
sqlClause(builder, "FROM", tables, "", "", ", ");
|
||||
sqlClause(builder, "JOIN", join, "", "", "\nJOIN ");
|
||||
sqlClause(builder, "INNER JOIN", innerJoin, "", "", "\nINNER JOIN ");
|
||||
sqlClause(builder, "OUTER JOIN", outerJoin, "", "", "\nOUTER JOIN ");
|
||||
sqlClause(builder, "LEFT OUTER JOIN", leftOuterJoin, "", "", "\nLEFT OUTER JOIN ");
|
||||
sqlClause(builder, "RIGHT OUTER JOIN", rightOuterJoin, "", "", "\nRIGHT OUTER JOIN ");
|
||||
sqlClause(builder, "WHERE", where, "(", ")", " AND ");
|
||||
sqlClause(builder, "GROUP BY", groupBy, "", "", ", ");
|
||||
sqlClause(builder, "HAVING", having, "(", ")", " AND ");
|
||||
sqlClause(builder, "ORDER BY", orderBy, "", "", ", ");
|
||||
return builder.toString();
|
||||
}
|
||||
|
||||
private String insertSQL(SafeAppendable builder) {
|
||||
sqlClause(builder, "INSERT INTO", tables, "", "", "");
|
||||
sqlClause(builder, "", columns, "(", ")", ", ");
|
||||
sqlClause(builder, "VALUES", values, "(", ")", ", ");
|
||||
return builder.toString();
|
||||
}
|
||||
|
||||
private String deleteSQL(SafeAppendable builder) {
|
||||
sqlClause(builder, "DELETE FROM", tables, "", "", "");
|
||||
sqlClause(builder, "WHERE", where, "(", ")", " AND ");
|
||||
return builder.toString();
|
||||
}
|
||||
|
||||
private String updateSQL(SafeAppendable builder) {
|
||||
|
||||
sqlClause(builder, "UPDATE", tables, "", "", "");
|
||||
sqlClause(builder, "SET", sets, "", "", ", ");
|
||||
sqlClause(builder, "WHERE", where, "(", ")", " AND ");
|
||||
return builder.toString();
|
||||
}
|
||||
|
||||
public String sql(Appendable a) {
|
||||
SafeAppendable builder = new SafeAppendable(a);
|
||||
if (statementType == null) {
|
||||
return null;
|
||||
}
|
||||
|
||||
String answer;
|
||||
|
||||
switch (statementType) {
|
||||
case DELETE:
|
||||
answer = deleteSQL(builder);
|
||||
break;
|
||||
|
||||
case INSERT:
|
||||
answer = insertSQL(builder);
|
||||
break;
|
||||
|
||||
case SELECT:
|
||||
answer = selectSQL(builder);
|
||||
break;
|
||||
|
||||
case UPDATE:
|
||||
answer = updateSQL(builder);
|
||||
break;
|
||||
|
||||
default:
|
||||
answer = null;
|
||||
}
|
||||
|
||||
return answer;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
public class SQL extends AbstractSQL<SQL> {
|
||||
|
||||
@Override
|
||||
public SQL getSelf() {
|
||||
return this;
|
||||
}
|
||||
|
||||
}
|
||||
~~~
|
||||
|
||||
[^sqlBuilder]: [http://mybatis.github.io/mybatis-3/statement-builders.html](http://mybatis.github.io/mybatis-3/statement-builders.html)
|
||||
@@ -1,47 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Java中用js解析json
|
||||
tags: ScriptEngineManager Java javascript
|
||||
categories: java
|
||||
published: java
|
||||
---
|
||||
|
||||
在java中如何解析json?fastjson?jackson?那未免太无趣了
|
||||
|
||||
其实我们可以试试ScriptEngine
|
||||
|
||||
~~~java
|
||||
public class NashornTest {
|
||||
|
||||
private static String json = "[{name:'A',age:'18'},{name:'B',age:'19'},{name:'C',age:'30'}]";
|
||||
|
||||
private static String script =
|
||||
"function parse(json){" +
|
||||
" var names = new Array();" +
|
||||
" for(var i in json){" +
|
||||
" names.push(json[i].name);" +
|
||||
" }" +
|
||||
" return names;" +
|
||||
"};" +
|
||||
"parse(" + json + ");";
|
||||
|
||||
public static void main(String[] args) throws ScriptException {
|
||||
ScriptEngineManager manager = new ScriptEngineManager();
|
||||
ScriptEngine engine = manager.getEngineByName( "JavaScript" );
|
||||
|
||||
Map<String,String> result = (Map<String,String>)engine.eval(script);
|
||||
result.forEach((k,v) -> System.out.println(v));
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
输出:
|
||||
|
||||
A
|
||||
|
||||
B
|
||||
|
||||
C
|
||||
|
||||
> 代码中使用了 [lambda](http://blog.rainynight.top/2014-12-13/java-newfeature/# lambda)
|
||||
|
||||
@@ -1,142 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Bean Validation
|
||||
tags: Bean Validation Java
|
||||
categories: java
|
||||
published: true
|
||||
---
|
||||
|
||||
[BeanValidation][BeanValidation] 可以帮助开发者方便地对数据进行校验,但它只是一个标准,只有一套接口,要想使用它的功能必须选择一种实现,`hibernate-validator`是个不错的选择
|
||||
|
||||
~~~xml
|
||||
<dependency>
|
||||
<groupId>org.hibernate</groupId>
|
||||
<artifactId>hibernate-validator</artifactId>
|
||||
<version>5.0.2.Final</version>
|
||||
</dependency>
|
||||
~~~
|
||||
|
||||
BeanValidator 可以自动扫描到hibernate-validator,而不用进行任何配置,前提是需要将hibernate-validator放到classpath下
|
||||
|
||||
在JAVA类中可以直接得到可用的检验器实现:
|
||||
|
||||
~~~
|
||||
private Validator validator = Validation.buildDefaultValidatorFactory().getValidator();
|
||||
~~~
|
||||
|
||||
它是怎么做到的?笔者和你具有一样强的好奇心,深入源码后,笔者发现了这样一段代码
|
||||
|
||||
~~~
|
||||
private List<ValidationProvider<?>> loadProviders(ClassLoader classloader) {
|
||||
ServiceLoader<ValidationProvider> loader = ServiceLoader.load( ValidationProvider.class, classloader );
|
||||
Iterator<ValidationProvider> providerIterator = loader.iterator();
|
||||
List<ValidationProvider<?>> validationProviderList = new ArrayList<ValidationProvider<?>>();
|
||||
while ( providerIterator.hasNext() ) {
|
||||
try {
|
||||
validationProviderList.add( providerIterator.next() );
|
||||
}
|
||||
catch ( ServiceConfigurationError e ) {
|
||||
// ignore, because it can happen when multiple
|
||||
// providers are present and some of them are not class loader
|
||||
// compatible with our API.
|
||||
}
|
||||
}
|
||||
return validationProviderList;
|
||||
}
|
||||
~~~
|
||||
|
||||
显而易见,通过`ClassLoader`可以找出所有实现了`ValidationProvider`的接口的类,这些类即为BeanValidator的实现,然后从这个列表中取第一个就行了。
|
||||
|
||||
BeanValidation 使用方法也非常简单,调用`validate`方法后会返回一个校验结果集,如果结果集长度为0则表示校验完全通过;否则将可以从`ConstraintViolation`中获取失败信息
|
||||
|
||||
~~~
|
||||
Set<ConstraintViolation<Article>> constraintViolations = validator.validate(new Article());
|
||||
~~~
|
||||
|
||||
当然,前提是先要定义字段的约束,`@NotNull`表示此字段的值不可为空,注解也可以在字段上,更多预置的注解在`javax.validation.constraints`包中
|
||||
|
||||
~~~
|
||||
@NotNull
|
||||
public String getTitle() {
|
||||
return title;
|
||||
}
|
||||
~~~
|
||||
|
||||
# 与Spring集成
|
||||
|
||||
现在Spring4已经集成了BeanValidation,并增加了国际化支持,这个LocalValidatorFactoryBean可以注入到任何类中使用
|
||||
|
||||
~~~
|
||||
<bean id="validator" class="org.springframework.validation.beanvalidation.LocalValidatorFactoryBean">
|
||||
<property name="providerClass" value="org.hibernate.validator.HibernateValidator"/>
|
||||
<!-- 如果不加默认到 使用classpath下的 ValidationMessages.properties -->
|
||||
<property name="validationMessageSource" ref="validationMessageSource"/>
|
||||
</bean>
|
||||
|
||||
<!-- 国际化的消息资源文件(本系统中主要用于显示/错误消息定制) -->
|
||||
<bean id="validationMessageSource" class="org.springframework.context.support.ReloadableResourceBundleMessageSource">
|
||||
<property name="basenames">
|
||||
<list>
|
||||
<!-- 在web环境中一定要定位到classpath 否则默认到当前web应用下找 -->
|
||||
<value>classpath:messages/validationMessages</value>
|
||||
<value>classpath:org/hibernate/validator/ValidationMessages</value>
|
||||
</list>
|
||||
</property>
|
||||
<property name="useCodeAsDefaultMessage" value="false"/>
|
||||
<property name="defaultEncoding" value="UTF-8"/>
|
||||
<property name="cacheSeconds" value="60"/>
|
||||
</bean>
|
||||
~~~
|
||||
|
||||
如果你正在使用 SpringMVC 集成就更简单了
|
||||
|
||||
~~~
|
||||
<mvc:annotation-driven validator="validator"/>
|
||||
~~~
|
||||
|
||||
然后在需要校验的Bean上注解`@Valid`,并紧随其后添加`BindingResult`
|
||||
|
||||
~~~
|
||||
@RequestMapping(value = "release", method = RequestMethod.POST)
|
||||
public String release(@Valid Article article, BindingResult bindingResult, HttpSession session, ModelMap modelMap){
|
||||
...
|
||||
...
|
||||
}
|
||||
~~~
|
||||
|
||||
如果想要将校验失败的信息展示在页面上可以使用el表达式, 注意el版本必须在2.2以上, s前缀指的是spring标签
|
||||
|
||||
~~~
|
||||
<%@taglib prefix="s" uri="http://www.springframework.org/tags" %>
|
||||
~~~
|
||||
|
||||
~~~
|
||||
<s:hasBindErrors name="article">
|
||||
<c:if test="${errors.fieldErrorCount > 0}">
|
||||
字段错误:<br/>
|
||||
<c:forEach items="${errors.fieldErrors}" var="error">
|
||||
<s:message var="message" code="${error.code}" arguments="${error.arguments}" text="${error.defaultMessage}"/>
|
||||
${error.field}------${message}<br/>
|
||||
</c:forEach>
|
||||
</c:if>
|
||||
|
||||
<c:if test="${errors.globalErrorCount > 0}">
|
||||
全局错误:<br/>
|
||||
<c:forEach items="${errors.globalErrors}" var="error">
|
||||
<s:message var="message" code="${error.code}" arguments="${error.arguments}" text="${error.defaultMessage}"/>
|
||||
<c:if test="${not empty message}">
|
||||
${message}<br/>
|
||||
</c:if>
|
||||
</c:forEach>
|
||||
</c:if>
|
||||
</s:hasBindErrors>
|
||||
~~~
|
||||
|
||||
---
|
||||
|
||||
其实 BeanValidation的内容远不止于此,它还有很多更高级的特性,如分组校验等,详情请[点我][more]
|
||||
|
||||
|
||||
|
||||
[BeanValidation]:http://beanvalidation.org/
|
||||
[more]:http://www.ibm.com/developerworks/cn/java/j-lo-beanvalid/
|
||||
@@ -1,320 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: spring security 探秘
|
||||
tags: spring security Java
|
||||
categories: web
|
||||
---
|
||||
|
||||
# 概述
|
||||
|
||||
[Spring Security][site]这是一种基于Spring AOP和Servlet过滤器的安全框架。它提供全面的安全性解决方案,同时在Web请求级和方法调用级处理身份确认和授权。在Spring Framework基础上,Spring Security充分利用了依赖注入(DI,Dependency Injection)和面向切面技术。
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
本文的宗旨并非描述如何从零开始搭建一个 "hello world" 级的demo,或者列举有哪些可配置项(这种类似于词典的文档,没有比[参考书][doc]更合适的了),而是简单描述spring-security项目的整体结构,设计思想,以及某些重要配置做了什么。
|
||||
|
||||
本文所有内容基于spring-security-4.0.1.RELEASE ,你可以在[Github][github]中找到它,或者使用Maven获取,引入spring-security-config是为了通过命名空间简化配置。
|
||||
|
||||
~~~xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.security</groupId>
|
||||
<artifactId>spring-security-web</artifactId>
|
||||
<version>4.0.1.RELEASE</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.security</groupId>
|
||||
<artifactId>spring-security-config</artifactId>
|
||||
<version>4.0.1.RELEASE</version>
|
||||
</dependency>
|
||||
~~~
|
||||
|
||||
|
||||
# Filter
|
||||
|
||||
spring-security的业务流程是独立于项目的,我们需要在web.xml中指定其入口,注意该过滤器必须在项目的过滤器之前。
|
||||
|
||||
~~~xml
|
||||
<filter>
|
||||
<filter-name>springSecurityFilterChain</filter-name>
|
||||
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
|
||||
</filter>
|
||||
<filter-mapping>
|
||||
<filter-name>springSecurityFilterChain</filter-name>
|
||||
<servlet-name>/*</servlet-name>
|
||||
</filter-mapping>
|
||||
~~~
|
||||
|
||||
值得一提的是,该过滤器的名字具有特殊意义,没有特别需求不建议修改,我们可以在该过滤的源码中看到,其过滤行为委托给了一个`delegate`对象,该delegate对象是一个从spring容器中获取的bean,依据的beanid就是filter-name。
|
||||
|
||||
~~~java
|
||||
@Override
|
||||
protected void initFilterBean() throws ServletException {
|
||||
synchronized (this.delegateMonitor) {
|
||||
if (this.delegate == null) {
|
||||
|
||||
if (this.targetBeanName == null) {
|
||||
this.targetBeanName = getFilterName();
|
||||
}
|
||||
|
||||
WebApplicationContext wac = findWebApplicationContext();
|
||||
if (wac != null) {
|
||||
this.delegate = initDelegate(wac);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
|
||||
# HTTP
|
||||
|
||||
我们可以在security中声明多个`http`元素,每个http元素将产生一个`FilterChain`,这些FilterChain将按照声明顺序加入到`FilterChainProxy`中,而这个FilterChainProxy就是web.xml中定义的springSecurityFilterChain内部的`delegate`。
|
||||
|
||||
~~~xml
|
||||
<security:http security="none" pattern="/favicon.ico" />
|
||||
<security:http security="none" pattern="/resources/**" />
|
||||
<security:http security="none" pattern="/user/login" />
|
||||
~~~
|
||||
|
||||
在http元素也就是FilterChain中,以责任链的形式存在多个`Filter`,这些Filter真正执行过滤操作,http标签中的许多配置项,如` <security:http-basic/>`、`<security:logout/>`等,其实就是创建指定的Filter,以下表格列举了这些Filter。
|
||||
|
||||
![filter][filter]
|
||||
|
||||
利用别名,我们可以将自定义的过滤器加入指定的位置,或者替换其中的某个过滤器。
|
||||
|
||||
~~~xml
|
||||
<security:custom-filter ref="filterSecurityInterceptor" before="FILTER_SECURITY_INTERCEPTOR" />
|
||||
~~~
|
||||
|
||||
整体来看,一个FilterChainProxy中可以包含有多个FilterChain,一个FilterChain中又可以包含有多个Filter,然而对于一个既定请求,只会使用其中一个FilterChain。
|
||||
|
||||
# FilterChain
|
||||
|
||||
![filterChain][filterChain]
|
||||
|
||||
上图列举了一些Filter, 此处将说明这些Filter的作用, 在需要插入自定义Filter时, 这些说明可以作为参考。
|
||||
|
||||
* SecurityContextPersistenceFilter
|
||||
创建一个空的SecurityContext(如果session中没有SecurityContext实例),然后持久化到session中。在filter原路返回时,还需要保存这个SecurityContext实例到session中。
|
||||
|
||||
* RequestCacheAwareFilter
|
||||
用于用户登录成功后,重新恢复因为登录被打断的请求
|
||||
|
||||
* AnonymousAuthenticationFilter
|
||||
如果之前的过滤器都没有认证成功,则为当前的SecurityContext中添加一个经过匿名认证的token, 所有与认证相关的过滤器(如CasAuthenticationFilter)都应当放在AnonymousAuthenticationFilter之前。
|
||||
|
||||
* SessionManagementFilter
|
||||
1.session固化保护-通过session-fixation-protection配置
|
||||
2.session并发控制-通过concurrency-control配置
|
||||
|
||||
* ExceptionTranslationFilter
|
||||
主要拦截两类安全异常:认证异常、访问拒绝异常。而且仅仅是捕获后面的过滤器产生的异常。所以在自定义拦截器时,需要注意在链中的顺序。
|
||||
|
||||
* FilterSecurityInterceptor
|
||||
通过决策管理器、认证管理器、安全元数据来判断用户是否能够访问资源。
|
||||
|
||||
|
||||
|
||||
# FilterSecurityInterceptor
|
||||
|
||||
如果一个http请求能够匹配security定义的规则,那么该请求将进入security处理流程,大体上,security分为三个部分:
|
||||
|
||||
* AuthenticationManager 处理认证请求
|
||||
* AccessDecisionManager 提供访问决策
|
||||
* SecurityMetadataSource 元数据
|
||||
|
||||
以下代码摘自`AbstractSecurityInterceptor`, 这是`FilterSecurityInterceptor`的父类, 也正是在此处区分了web请求拦截器与方法调用拦截器。(代码有所精简)
|
||||
|
||||
~~~java
|
||||
protected InterceptorStatusToken beforeInvocation(Object object) {
|
||||
|
||||
if (!getSecureObjectClass().isAssignableFrom(object.getClass())) {
|
||||
throw new IllegalArgumentException();
|
||||
}
|
||||
|
||||
Collection<ConfigAttribute> attributes =
|
||||
this.obtainSecurityMetadataSource().getAttributes(object);
|
||||
|
||||
if (attributes == null || attributes.isEmpty()) {
|
||||
if (rejectPublicInvocations) {
|
||||
throw new IllegalArgumentException();
|
||||
}
|
||||
publishEvent(new PublicInvocationEvent(object));
|
||||
return null; // no further work post-invocation
|
||||
}
|
||||
|
||||
if (SecurityContextHolder.getContext().getAuthentication() == null) {
|
||||
//...
|
||||
}
|
||||
|
||||
Authentication authenticated = authenticateIfRequired();
|
||||
|
||||
// Attempt authorization
|
||||
try {
|
||||
this.accessDecisionManager.decide(authenticated, object, attributes);
|
||||
}
|
||||
catch (AccessDeniedException accessDeniedException) {
|
||||
publishEvent(new AuthorizationFailureEvent(object, attributes,
|
||||
authenticated,accessDeniedException));
|
||||
throw accessDeniedException;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
private Authentication authenticateIfRequired() {
|
||||
Authentication authentication = SecurityContextHolder.getContext()
|
||||
.getAuthentication();
|
||||
|
||||
if (authentication.isAuthenticated() && !alwaysReauthenticate) {
|
||||
return authentication;
|
||||
}
|
||||
|
||||
authentication = authenticationManager.authenticate(authentication);
|
||||
|
||||
SecurityContextHolder.getContext().setAuthentication(authentication);
|
||||
|
||||
return authentication;
|
||||
}
|
||||
~~~
|
||||
|
||||
在FilterSecurityInterceptor的处理流程中,首先会处理认证请求,获取用户信息,然后决策处理器根据用户信息与权限元数据进行决策,同样,这三个部分都是可以自定义的。
|
||||
|
||||
~~~xml
|
||||
<!-- 自定义过滤器 -->
|
||||
<bean id="filterSecurityInterceptor"
|
||||
class="org.springframework.security.web.access.intercept.FilterSecurityInterceptor">
|
||||
<property name="securityMetadataSource" ref="securityMetadataSource"/>
|
||||
<property name="authenticationManager" ref="authenticationManager"/>
|
||||
<property name="accessDecisionManager" ref="accessDecisionManager"/>
|
||||
</bean>
|
||||
~~~
|
||||
|
||||
|
||||
# AuthenticationManager
|
||||
|
||||
AuthenticationManager处理认证请求,然而它并不直接处理,而是将工作委托给了一个`ProviderManager`,ProviderManager又将工作委托给了一个`AuthenticationProvider`列表,只要任何一个AuthenticationProvider认证通过,则AuthenticationManager认证通过,我们可以配置一个或者多个AuthenticationProvider,还可以对密码进行加密。
|
||||
|
||||
~~~xml
|
||||
<security:authentication-manager id="authenticationManager">
|
||||
<security:authentication-provider user-service-ref="userDetailsService" >
|
||||
<security:password-encoder base64="true" hash="md5">
|
||||
<security:salt-source user-property="username"/>
|
||||
</security:password-encoder>
|
||||
</security:authentication-provider>
|
||||
</security:authentication-manager>
|
||||
~~~
|
||||
|
||||
考虑到一种常见情形,用户输入用户名密码,然后与数据比对,验证用户信息,security提供了类来处理。
|
||||
|
||||
~~~xml
|
||||
<bean id="userDetailsService"
|
||||
class="org.springframework.security.core.userdetails.jdbc.JdbcDaoImpl" >
|
||||
<property name="dataSource" ref="dataSource"/>
|
||||
</bean>
|
||||
~~~
|
||||
JdbcDaoImpl使用内置的SQL查询数据,这些SQL以常量的形式出现在JdbcDaoImpl开头,同样可以注入修改。
|
||||
|
||||
|
||||
# AccessDecisionManager
|
||||
|
||||
AccessDecisionManager提供访问决策,它同样不会直接处理,而是仅仅抽象为一种投票规则,然后决策行为委托给所有投票人。
|
||||
|
||||
~~~xml
|
||||
<!-- 决策管理器 -->
|
||||
<bean id="accessDecisionManager"
|
||||
class="org.springframework.security.access.vote.AffirmativeBased" >
|
||||
<property name="allowIfAllAbstainDecisions" value="false"/>
|
||||
<constructor-arg index="0">
|
||||
<list>
|
||||
<!-- <bean class="org.springframework.security.web.access.expression.WebExpressionVoter"/>-->
|
||||
<bean class="org.springframework.security.access.vote.RoleVoter">
|
||||
<!-- 支持所有角色名称,无需前缀 -->
|
||||
<property name="rolePrefix" value=""/>
|
||||
</bean>
|
||||
<bean class="org.springframework.security.access.vote.AuthenticatedVoter"/>
|
||||
</list>
|
||||
</constructor-arg>
|
||||
</bean>
|
||||
~~~
|
||||
|
||||
security提供了三种投票规则:
|
||||
|
||||
* AffirmativeBased 只要有一个voter同意就通过
|
||||
* ConsensusBased 只要投同意票的大于投反对票的就通过
|
||||
* UnanimousBased 需要一致同意才通过
|
||||
|
||||
以下为`AffirmativeBased`决策过程
|
||||
|
||||
~~~java
|
||||
public void decide(Authentication authentication, Object object,
|
||||
Collection<ConfigAttribute> configAttributes) throws AccessDeniedException {
|
||||
int deny = 0;
|
||||
|
||||
for (AccessDecisionVoter voter : getDecisionVoters()) {
|
||||
int result = voter.vote(authentication, object, configAttributes);
|
||||
|
||||
switch (result) {
|
||||
case AccessDecisionVoter.ACCESS_GRANTED:
|
||||
return;
|
||||
|
||||
case AccessDecisionVoter.ACCESS_DENIED:
|
||||
deny++;
|
||||
|
||||
break;
|
||||
|
||||
default:
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (deny > 0) {
|
||||
throw new AccessDeniedException(messages.getMessage(
|
||||
"AbstractAccessDecisionManager.accessDenied", "Access is denied"));
|
||||
}
|
||||
|
||||
// To get this far, every AccessDecisionVoter abstained
|
||||
checkAllowIfAllAbstainDecisions();
|
||||
}
|
||||
~~~
|
||||
|
||||
|
||||
# SecurityMetadataSource
|
||||
|
||||
SecurityMetadataSource定义权限元数据(如资源与角色的关系),并提供了一个核心方法`Collection<ConfigAttribute> getAttributes(Object object)`来获取资源对应的角色列表,这种结构非常类似于Map。
|
||||
|
||||
security提供了`DefaultFilterInvocationSecurityMetadataSource`来进行角色读取操作,并将数据存储委托给一个`LinkedHashMap`对象。
|
||||
|
||||
~~~xml
|
||||
<!-- 资源与角色关系元数据 -->
|
||||
<bean id="securityMetadataSource"
|
||||
class="org.springframework.security.web.access.intercept.DefaultFilterInvocationSecurityMetadataSource">
|
||||
<constructor-arg index="0">
|
||||
<bean class="top.rainynight.site.core.RequestMapFactoryBean">
|
||||
<property name="dataSource" ref="dataSource"/>
|
||||
</bean>
|
||||
</constructor-arg>
|
||||
</bean>
|
||||
~~~
|
||||
|
||||
DefaultFilterInvocationSecurityMetadataSource获取角色方法
|
||||
|
||||
~~~java
|
||||
public Collection<ConfigAttribute> getAttributes(Object object) {
|
||||
final HttpServletRequest request = ((FilterInvocation) object).getRequest();
|
||||
for (Map.Entry<RequestMatcher, Collection<ConfigAttribute>> entry : requestMap
|
||||
.entrySet()) {
|
||||
if (entry.getKey().matches(request)) {
|
||||
return entry.getValue();
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
~~~
|
||||
|
||||
|
||||
[site]: http://projects.spring.io/spring-security
|
||||
[github]: https://github.com/spring-projects/spring-security
|
||||
[filter]: {{"/spring-security-filter.png" | prepend: site.imgrepo }}
|
||||
[filterChain]: {{"/spring-security-filterChain.jpg" | prepend: site.imgrepo }}
|
||||
[doc]: http://docs.spring.io/spring-security/site/docs/4.0.1.RELEASE/reference/htmlsingle/
|
||||
@@ -1,201 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Servlet乱码分析
|
||||
tags: servlet encode Java
|
||||
categories: web
|
||||
---
|
||||
|
||||
我们知道,web浏览器会将form中的内容打包成HTTP请求体,然后发送到服务端,服务端对请求体解析后可以得到传递的数据。这当中包含两个过程:`encode`与`decode`。
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
|
||||
# HTTP
|
||||
|
||||
我们使用ServerSocket搭建一个小服务器来看清http请求的全貌, 该服务器只有一个功能, 就是打印请求体。
|
||||
|
||||
~~~java
|
||||
public class HttpPrint {
|
||||
private ServerSocket serverSocket;
|
||||
|
||||
public HttpPrint() throws IOException {
|
||||
serverSocket = new ServerSocket(8080);
|
||||
}
|
||||
|
||||
public void show() throws IOException{
|
||||
while(true){
|
||||
Socket socket = serverSocket.accept();
|
||||
byte[] buf = new byte[1024];
|
||||
InputStream is = socket.getInputStream();
|
||||
ByteArrayOutputStream os = new ByteArrayOutputStream();
|
||||
int n = 0;
|
||||
while ((n = is.read(buf)) > -1){
|
||||
os.write(buf,0,n);
|
||||
}
|
||||
os.close();
|
||||
is.close();
|
||||
socket.close();
|
||||
System.out.println(os);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
new HttpPrint().show();
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
用html页面来发送get与post请求
|
||||
|
||||
~~~html
|
||||
<a href="http://localhost:8080/hsp?param=你好全世界">Test</a>
|
||||
<form action="http://localhost:8080/hsp" method="post">
|
||||
<input type="text" name="param" value="你好全世界"/>
|
||||
<input type="submit"/>
|
||||
</form>
|
||||
~~~
|
||||
|
||||
启动服务器后,查看打印内容,在我的机器上,请求内容如下:
|
||||
|
||||
get
|
||||
|
||||
![get][get]
|
||||
|
||||
post
|
||||
|
||||
![post][post]
|
||||
|
||||
从post中的`Content-Type:application/x-www-form-urlencoded`可以看到,虽然数据为中文,但是在传递的时候,经过了一次urlEncode,这样一来,在数据交换层面就可以屏蔽编码的不一致性。
|
||||
|
||||
# UrlEncode
|
||||
|
||||
`urlEncode`的任务是将form中的数据进行编码, 编码过程非常简单, 任何字符只要不是`ASCII`码, 它们都将被转换成字节形式, 每个字节都写成这种形式:一个 "%" 后面跟着两位16进制的数值。
|
||||
urlEncode只能识别ASCII码,可以想象的是,那些urlEncode不能识别的字符,也就是十六进制数,一定是依赖于特定的字符集产生的, 字符集包括unicode,iso等。
|
||||
|
||||
那么浏览器用的是什么字符集呢? 答案是:默认与`contentType`相同, form可以通过属性`accept-charset`指定。
|
||||
|
||||
例如我们通常可以在jsp中看到这样的设置:
|
||||
|
||||
~~~jsp
|
||||
<%@page contentType="text/html;charset=UTF-8" %>
|
||||
~~~
|
||||
|
||||
或者在html中这样设置:
|
||||
|
||||
~~~html
|
||||
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
|
||||
~~~
|
||||
|
||||
这表示浏览器得到响应流之后,用contentType指定的字符集,将流中的字节转换为字符,同样地,也会用这个字符集将页面中字符转换为字节。
|
||||
|
||||
关于浏览器设定字符集的问题,我们不过多讨论,现在只需要知道有这么个过程就行了, 需要注意的是,无论浏览器使用什么字符集,服务端都是无法获知的。
|
||||
这里需要换位考虑一下,浏览器是一个客户端,应该让客户端 "迁就" 服务端, 所以浏览器请求一个服务的时候,应该让浏览器考虑服务端支持什么字符集, 得到了响应后, 用服务端告诉浏览器的字符集进行解析。
|
||||
|
||||
|
||||
# UrlDecode
|
||||
|
||||
现在我们将目光转向Servlet, 并使用上面的html来请求服务,请确保请求的字符集为`unicode`, 应用服务器使用tomcat6。
|
||||
|
||||
~~~java
|
||||
public class HttpServletPrint extends HttpServlet{
|
||||
@Override
|
||||
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
|
||||
System.out.println(req.getParameter("param"));
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
|
||||
this.doPost(req,resp);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
get与post结果如下,果然不负众望地乱码了(如果不乱码,我还写个毛?)。
|
||||
|
||||
![param][param]
|
||||
|
||||
现在我们从Servlet中看看请求体, 修改上面的Servlet代码如下:
|
||||
|
||||
~~~java
|
||||
public class HttpServletPrint extends HttpServlet{
|
||||
@Override
|
||||
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
|
||||
//System.out.println(req.getParameter("param"));
|
||||
byte[] buf = new byte[1024];
|
||||
int n = 0;
|
||||
ByteArrayOutputStream bos = new ByteArrayOutputStream();
|
||||
InputStream is = req.getInputStream();
|
||||
while ((n = is.read(buf, 0, buf.length))>-1){
|
||||
bos.write(buf, 0, n);
|
||||
}
|
||||
String param = bos.toString();
|
||||
String s = URLDecoder.decode(param,"utf-8");
|
||||
System.out.println(s);
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
|
||||
this.doPost(req,resp);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
get与post结果如下,Servlet将http头部解析完成后,将请求体留了下来供应用程序使用, 这是考虑到http请求可能有多种 [enctype][enctype] , 请求体的结构可能不同,
|
||||
例如,`multipart/form-data`就不是这样的key=value结构,关于multipart/form-data,我在这篇 [fileupload][fileupload] 中曾有过简要分析。
|
||||
|
||||
![body-utf][body-utf]
|
||||
|
||||
从图中可以看到, 设置了正确的字符集后, 服务端将能够正确地解析, get部分什么都没有,这是因为get没有请求体。
|
||||
|
||||
让我们换种字符集试试, 比如, 将servet中的"utf-8"换成"iso-8859-1"。
|
||||
|
||||
![body-iso][body-iso]
|
||||
|
||||
嘿,果然如我所料,而且这个字符串好像很眼熟,和req.getParameter("param")结果是一样的,没错,事实上,tomcat默认的字符集就是`iso-8859-1`, 我们从中可以得到一个推论,tomcat使用默认的字符集,对http请求进行过一次decode。
|
||||
|
||||
|
||||
|
||||
# 方案
|
||||
|
||||
`urlDecode`的任务是将请求中的百分号码转换成字符,显而易见的是,使用与`urlEncode`时相同的字符集才能成功转换。通常的做法是,让服务端支持涵盖多国语言的"utf-8",然后让客户端也用"utf-8"请求服务。
|
||||
|
||||
指定服务端字符集的方式有两种,一是修改应用服务器的默认编码,二是添加一个过滤器进行编码转换, 方法一最方便, 但是影响了程序的可移植性, 方法二可移植, 它只需要做一件事:`requet.setCharacterEncoding("UTF-8");`,
|
||||
实际上,该过滤器并没有进行任何编码转换的工作,它仅仅只是一个配置,该配置项将被后续程序使用,这些后续程序包括web服务器内置的解析程序,以及第三方解析工具等。
|
||||
|
||||
需要注意的是,requet.setCharacterEncoding("UTF-8");,只对请求体有效,也就是说,请求头不归它管,而是由web服务器采用自己配置的字符编码进行解析,此时如果url中包含中文(如get请求的参数),那么将不可避免地出现字符丢失。
|
||||
解决办法是在客户端对url进行`encodeURI`**两次**, 然后再在服务端`URLDecoder.decode(param,"utf-8");`。
|
||||
|
||||
为什么要 [encodeURI][encodeURI-link] 两次?talk is cheap, let's code!
|
||||
|
||||
![encodeURI][encodeURI]
|
||||
|
||||
注意观察这张图片,从中发现了什么? 没错,第一次encodeURI生成了HTTP一节的示例中一样的结果。
|
||||
我们在浏览器窗口中输入 "http://localhost:8080/hsp?param=%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C", 会发现它变成了 "http://localhost:8080/hsp?param=你好全世界",
|
||||
在url里,浏览器认为%是个转义字符,浏览器会把%与%之间的编码,两位两位取出后进行decode, 也就是变回 "你好全世界", 然后再用这个url发送请求, 最终实际发送的内容实际上还是`%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C`。
|
||||
换言之,以明文传递的这种url会被浏览器否决一次,再换言之,在js中进行一次encodeURI等于什么都没做。
|
||||
|
||||
再注意观察第2和第3个输出,有什么规律? 是的,从第二次开始encodeURI只是将`%`变成了`%25`,
|
||||
根据我们刚才总结出的规律可知,在encodeURI两次的情况下,最后发送到浏览器中的数据为`%25E4%25BD%25A0%25E5%25A5%25BD%25E5%2585%25A8%25E4%25B8%2596%25E7%2595%258C`,
|
||||
理所当然的,web服务器将使用默认的字符集对其decode, 然而, 无论选择哪种字符集, 将`%25`转换成`%`总是不会出错的, decode之后,`%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C` 将完整地送到Servlet手上。
|
||||
|
||||
~~~java
|
||||
System.out.println(URLDecoder.decode(req.getParameter("param"),"utf-8"));
|
||||
~~~
|
||||
|
||||
~~~javascript
|
||||
window.location.href="http://localhost:8080/hsp?param=" + encodeURI(encodeURI('你好全世界'));
|
||||
~~~
|
||||
|
||||
![world][world]
|
||||
|
||||
[get]: {{"/servlet-encode/get.png" | prepend: site.imgrepo }}
|
||||
[post]: {{"/servlet-encode/post.png" | prepend: site.imgrepo }}
|
||||
[param]: {{"/servlet-encode/param.png" | prepend: site.imgrepo }}
|
||||
[body-utf]: {{"/servlet-encode/body-utf.png" | prepend: site.imgrepo }}
|
||||
[enctype]: http://www.w3school.com.cn/tags/att_form_enctype.asp
|
||||
[body-iso]: {{"/servlet-encode/body-iso.png" | prepend: site.imgrepo }}
|
||||
[fileupload]: http://blog.rainynight.top/2014-04-15/fileupload/
|
||||
[encodeURI]: {{"/servlet-encode/encodeURI.png" | prepend: site.imgrepo }}
|
||||
[encodeURI-link]: http://www.w3school.com.cn/jsref/jsref_encodeuri.asp
|
||||
[world]: {{"/servlet-encode/world.png" | prepend: site.imgrepo }}
|
||||
@@ -1,80 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: RMI
|
||||
tags: rmi Java
|
||||
categories: java
|
||||
---
|
||||
|
||||
Java RMI 指的是远程方法调用 (Remote Method Invocation)。RMI能够让在某个 Java 虚拟机上的对象调用另一个 Java 虚拟机中的对象上的方法, 其威力体现在它强大的开发分布式网络应用的能力上,它可以被看作是RPC的Java版本。
|
||||
|
||||
与WebService相比,RMI编写代码更加简单,在小型应用开发上更加合适,相对地,RMI只能在java中使用,而WebSerce可以跨平台。
|
||||
|
||||
RMI示意图:
|
||||
|
||||
![rmi][rmi]
|
||||
|
||||
# Demo
|
||||
|
||||
定义接口,必须继承Remote
|
||||
|
||||
~~~java
|
||||
import java.rmi.Remote;
|
||||
import java.rmi.RemoteException;
|
||||
|
||||
public interface HelloService extends Remote{
|
||||
String sayHello() throws RemoteException;
|
||||
}
|
||||
~~~
|
||||
|
||||
实现接口,必须继承UnicastRemoteObject并在空构造中抛出RemoteException, 方法的返回值必须为原语类型或者序列化类型.
|
||||
|
||||
~~~java
|
||||
import java.rmi.RemoteException;
|
||||
import java.rmi.server.UnicastRemoteObject;
|
||||
|
||||
public class HelloServiceImpl extends UnicastRemoteObject implements HelloService {
|
||||
|
||||
protected HelloServiceImpl() throws RemoteException {}
|
||||
|
||||
@Override
|
||||
public String sayHello() throws RemoteException {
|
||||
return "server says. 'Hey'";
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
注册服务
|
||||
|
||||
~~~java
|
||||
import java.net.MalformedURLException;
|
||||
import java.rmi.RemoteException;
|
||||
import java.rmi.registry.LocateRegistry;
|
||||
import java.rmi.registry.Registry;
|
||||
|
||||
public class RegistryBook {
|
||||
public static void main(String[] args) throws RemoteException, MalformedURLException {
|
||||
Registry r = LocateRegistry.createRegistry(Registry.REGISTRY_PORT);
|
||||
r.rebind("HelloService", new HelloServiceImpl());
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
在另一台虚拟机上运行客户端代码,需要获得服务接口文件
|
||||
|
||||
~~~java
|
||||
import java.net.MalformedURLException;
|
||||
import java.rmi.Naming;
|
||||
import java.rmi.NotBoundException;
|
||||
import java.rmi.RemoteException;
|
||||
|
||||
public class Client {
|
||||
public static void main(String args[]) throws RemoteException, MalformedURLException, NotBoundException {
|
||||
HelloService helloService = (HelloService) Naming.lookup("rmi://localhost:1099/HelloService");
|
||||
System.out.println(helloService.sayHello());
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
注意,如果你使用的较为古老的jdk,你可能需要通过jdk内置的`rmic`命令生成`stub`以及`skeleton`文件,并将`stub`文件提供给客户端使用。
|
||||
|
||||
[rmi]: {{"/rmi.jpg" | prepend: site.imgrepo }}
|
||||
@@ -1,648 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: 设计模式与原则
|
||||
tags: design pattern 设计模式 原则 面向对象
|
||||
categories: common
|
||||
---
|
||||
|
||||
设计模式的定义:在某情境下,针对某问题的某种解决方案。但是满足此定义的方案并不一定是设计模式,设计模式要求解决方案必须是可复用的。
|
||||
设计模式的作用大体上是:优化结构,消除依赖,将面向过程转为面向对象。按照功能,一般可以将设计模式分为`创建型`,`行为型`,`结构型`三大类。
|
||||
本文将列举这些设计模式,并对每个设计模式进行简要描述,描述格式为:名称,定义,案例,适用性,结构,效果,应用,相关。
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
设计模式是工程师们从工作中总结出来的经验之谈,这些经验除了设计模式,还有一些设计原则,严格来讲,这些东西都是教条,它告诉我们只要按照规矩来,就不容易犯错。当遇到一特殊情况时,打破原则也没什么大不了的。
|
||||
|
||||
这些原则包括:
|
||||
|
||||
>单一责任原则:一个类应该只有一个引起变化的原因。
|
||||
|
||||
>里氏替换原则:子类可以扩展父类的功能,但不能改变父类原有的功能。
|
||||
|
||||
>依赖倒置原则:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
|
||||
|
||||
>接口隔离原则:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
|
||||
|
||||
>最少知识原则:一个对象应该对其他对象保持最少的了解。
|
||||
|
||||
>开闭原则:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
|
||||
|
||||
以及一些叫不上名的原则:
|
||||
|
||||
>找出应用中可能需要变化之处,把他们独立出来,不要和那些不需要变化的代码混在一起。
|
||||
|
||||
>针对接口编程,而不是针对实现编程。
|
||||
|
||||
>多用组合少用继承。
|
||||
|
||||
# 创建型
|
||||
|
||||
## 单例模式
|
||||
|
||||
**定义**
|
||||
|
||||
确保一个类只有一个实例,并提供一个全局访问点。
|
||||
|
||||
**案例**
|
||||
|
||||
需要对系统的注册表进行操作,如果同时存在多个注册表对象的话,将无法对并发访问或者临界值进行控制。
|
||||
|
||||
建立一个注册表获取类,从其静态方法中获取注册表对象,单例采用双重检查法创建。
|
||||
|
||||
**适用性**
|
||||
|
||||
当对象的操作目标是当前环境中的唯一资源时
|
||||
|
||||
**结构**
|
||||
|
||||
![Singleton][Singleton]
|
||||
|
||||
**效果**
|
||||
|
||||
将可以进行并发访问控制
|
||||
|
||||
**应用**
|
||||
|
||||
Runtime
|
||||
|
||||
NumberFormat
|
||||
|
||||
**相关**
|
||||
|
||||
简单工厂
|
||||
|
||||
## 工厂模式
|
||||
|
||||
**分类**
|
||||
|
||||
工厂方法,抽象工厂,(简单工厂算工厂方法的特例)
|
||||
|
||||
**定义**
|
||||
|
||||
工厂方法:定义了一个创建对象的接口,但由子类决定需要实例化的类是哪一个。工厂方法将类的实例化推迟到子类。
|
||||
|
||||
抽象工厂:定义一个接口,用于创建相关或依赖对象的家族,而不用明确指定具体的类。
|
||||
|
||||
**案例**
|
||||
|
||||
现有系统需要获取一组批萨饼的调料,但是同样的调料在不同的地点会有不同,如海边的海鲜是新鲜的,而内地的海鲜是冷冻的,为了方便扩展,获取的调料不能依赖具体的地点。
|
||||
|
||||
解决方案:将获取调料的地点抽象,由运行时的具体地点生成一组调料。
|
||||
|
||||
**适用性**
|
||||
|
||||
当需要依赖运行时上下文来决定生成的产品家族时使用抽象工厂
|
||||
|
||||
**区别**
|
||||
|
||||
工厂方法:一个抽象产品,可以派生出多种具体产品;一个抽象工厂类,可以派生出多个具体工厂。
|
||||
|
||||
抽象工厂:多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类可以创建多个具体产品类的实例。
|
||||
|
||||
|
||||
**结构**
|
||||
|
||||
工厂方法
|
||||
|
||||
![fatocymethod][factorymethod]
|
||||
|
||||
抽象工厂
|
||||
|
||||
![absfactory][absfactory]
|
||||
|
||||
**效果**
|
||||
|
||||
能轻松方便地构造对象实例,而不必关心构造对象实例的细节和依赖条件。
|
||||
|
||||
类数量暴增
|
||||
|
||||
**应用**
|
||||
|
||||
基本装箱类
|
||||
|
||||
Collection的iterator()
|
||||
|
||||
log4j
|
||||
|
||||
|
||||
|
||||
# 行为型
|
||||
|
||||
## 策略模式
|
||||
|
||||
**定义**
|
||||
|
||||
定义了算法家族,分别封装起来,让他们之间可以相互替换,此模式让算法的变化独立于使用算法的客户。
|
||||
|
||||
**案例**
|
||||
|
||||
存在一个模拟鸭子的程序,现在需要为其增加飞翔的功能,在鸭子的抽象类上增加`fly()`方法后,飞翔能力将传播到所有的子类中。但是,本不应该会飞的 "模型鸭" 也继承了飞翔能力,如果将飞翔能力抽象为 `Flayable`接口,那么随着程序的扩展,那么所有子类都必须重新实现fly()方法,如此一来将出现大量的重复代码,如果已经现存很多扩展类,修改这些类也是很大的工作量。
|
||||
|
||||
此时的解决方案是:将飞翔行为抽象,并提供几个通用实现,将鸭子的飞翔委托给飞翔行为,在抽象类中增加set方法注册委托,这样的改动不会影响现有的结构。
|
||||
|
||||
**适用性**
|
||||
|
||||
当类的某个行为随着扩展不断发生变化,而且这种变化只有有限的几种时。
|
||||
|
||||
|
||||
|
||||
**结构**
|
||||
|
||||
![Strategy][Strategy]
|
||||
|
||||
**效果**
|
||||
|
||||
积极:
|
||||
|
||||
1.类与行为可以分别扩展,而且扩展类可以自由设置行为,甚至在运行时改变。
|
||||
|
||||
2.类预置了多个算法,需要要判断调用时上下文从而选择不同算法。策略模式可以消除代码中的 if lese 将选择权交给客户
|
||||
|
||||
|
||||
消极:
|
||||
|
||||
1.客户端必须知道所有的策略类,并自行决定使用哪一个策略类
|
||||
2.策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
|
||||
|
||||
|
||||
**应用**
|
||||
|
||||
`ThreadPoolExecutor`中的`RejectedExecutionHandler`
|
||||
|
||||
`SpringSecurity`中的`AccessDecisionManager`
|
||||
|
||||
**相关**
|
||||
|
||||
模板方法模式
|
||||
|
||||
命令模式
|
||||
|
||||
状态模式
|
||||
|
||||
## 模板方法
|
||||
|
||||
**定义**
|
||||
|
||||
在一个方法中一定一个算法的骨架,而将某些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。
|
||||
|
||||
**案例**
|
||||
|
||||
现有一个冲泡饮料的算法,泡咖啡和泡茶的步骤基本相同,但是在加调料的这一步有所区别,如何在不需要重写整个冲泡过程的前提下扩展?
|
||||
|
||||
解决方案:将冲泡过程中的放调料步骤抽象出来做成hook,待具体的实现者来补全算法,而不必重写整个冲泡过程。
|
||||
|
||||
**适用性**
|
||||
|
||||
当算法的整体骨架可被复用,只有其中某个步骤可变时
|
||||
|
||||
**结构**
|
||||
|
||||
![templatemethod][templatemethod]
|
||||
|
||||
**效果**
|
||||
|
||||
复用算法骨架
|
||||
|
||||
算法可变步骤中的每一个特例都要为其创建一个新类
|
||||
|
||||
**应用**
|
||||
|
||||
`Collections.sort`
|
||||
|
||||
**相关**
|
||||
|
||||
与策略模式不同,策略模式定义一个算法家族,算法可以互换,而模板方法定义一个算法大纲,其中个别的步骤可以有不同实现。
|
||||
|
||||
|
||||
## 状态模式
|
||||
|
||||
**定义**
|
||||
|
||||
允许对象内部状态改变时改变它的行为,对象看起来好像修改了它的类。
|
||||
|
||||
**案例**
|
||||
|
||||
需要模拟一个自动售货机程序,如果没有投币则只能投币;如果已投币则不能再投币,可以选择退币或者出货;选择出货后如果有货则出货并结束,如果断货则提示断货。
|
||||
|
||||
可以用大量的 if else 将如上描述写成过程话的判断语句以完成功能,然而现在需要增加一个功能,有十分之一的几率双倍出货。这样一来就需要在每个动作方法内判断当前操作者是不是幸运儿。
|
||||
|
||||
解决方案:将状态封装成独立的类,并将动作委托到代表当前状态的对象。省去了类中冗长的状态判断。
|
||||
|
||||
**适用性**
|
||||
|
||||
行为因为上下文的不同而需要随之变化
|
||||
|
||||
代码中包含大量与对象状态有关的条件语句:一个操作中含有庞大的多分支的条件(if else(或switch case)语句,且这些分支依赖于该对象的状态。
|
||||
|
||||
**结构**
|
||||
|
||||
![state][state]
|
||||
|
||||
|
||||
**效果**
|
||||
|
||||
它将与特定状态相关的行为局部化,并且将不同状态的行为分割开来
|
||||
|
||||
它使得状态转换显式化
|
||||
|
||||
状态对象可被共享
|
||||
|
||||
状态模式的使用必然会增加系统类和对象的个数。
|
||||
|
||||
状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
|
||||
|
||||
**应用**
|
||||
|
||||
java.util.Iterator
|
||||
|
||||
动作游戏连招
|
||||
|
||||
**相关**
|
||||
|
||||
是策略模式的增强版,区别在于意图,策略模式虽然也可以在运行时改变行为,但是策略模式通常有一个最适合的策略对象;而状态模式需要在多个状态对象中游走,没有所谓的最适合状态。
|
||||
|
||||
|
||||
## 命令模式
|
||||
|
||||
**定义**
|
||||
|
||||
将请求封装成对象,以便使用不同请求,队列或日志来参数化其他对象,命令模式也支持可撤销的操作。
|
||||
|
||||
**案例**
|
||||
|
||||
通用遥控器,当目标为电视时,上下键可以是换台,调整音量;当目标为空调时,上下键可以是调温或者调整定时;而且可以方便地扩展以兼容不同电器。
|
||||
|
||||
解决方案,将遥控器与电器接偶,将遥控器每个按钮抽象为一个命令,由使用者提供命令,遥控器呼叫此命令,由命令自身呼叫真实目标。
|
||||
|
||||
**适用性**
|
||||
|
||||
当请求的真实目标不明确,或者对请求进行不明确的处理时(如队列,宏命令,日志记录等)。
|
||||
|
||||
**结构**
|
||||
|
||||
![cmd][cmd]
|
||||
|
||||
**效果**
|
||||
|
||||
积极的:
|
||||
|
||||
降低系统的耦合度:Command模式将调用操作的对象与知道如何实现该操作的对象解耦。
|
||||
|
||||
组合命令:你可将多个命令装配成一个组合命令,即可以比较容易地设计一个命令队列和宏命令。一般说来,组合命令是Composite模式的一个实例。
|
||||
|
||||
增加新的Command很容易,因为这无需改变已有的类。
|
||||
|
||||
可以方便地实现对请求的Undo和Redo。用栈存储操作序列,可以实现多层次撤销。
|
||||
|
||||
消极的:
|
||||
|
||||
导致某些系统有过多的具体命令类
|
||||
|
||||
**应用**
|
||||
|
||||
java.lang.Runnable
|
||||
|
||||
javax.swing.Action
|
||||
|
||||
游戏中的自定义键位
|
||||
|
||||
**相关**
|
||||
|
||||
策略模式聚焦的是对相同请求更换解决方案的灵活性;而命令模式聚焦的是对多请求变化的封装以及对相同请求不同的请求形式解决方法的可复用性
|
||||
|
||||
组合模式
|
||||
|
||||
## 观察者模式
|
||||
|
||||
**定义**
|
||||
|
||||
定义了对象之间的一对多依赖,这样一来,当一个对象改变状态时,所有所有依赖者都会接到通知并自动更新
|
||||
|
||||
**案例**
|
||||
|
||||
需要在展板上实时显示当前温度,温度数据来自温度计。初步方案1,是定时询问温度计然后更新数据,这样就需要再开一个定时器线程,如果以后会有更多的功能需要获取温度计数据,那么线程数量将失去控制。数步方案2是当温度计数据发生变化时,直接通知这些数据请求者,但是当有新的请求者时,需要打开温度计类增加一个请求者。
|
||||
|
||||
结局方案:将需要获取温度计数据的请求者抽象,然后注册到温度计中形成一个列表,每当温度计数据发生变化,就依次通知这些注册的对象。
|
||||
|
||||
**适用性**
|
||||
|
||||
当一个抽象模型有两个方面, 其中一个方面依赖于另一方面的状态。将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
|
||||
|
||||
当对一个对象的改变需要同时改变其它对象 , 而不知道具体有多少对象有待改变。
|
||||
|
||||
当一个对象必须通知其它对象,而它又不能假定其它对象是谁。换言之 , 你不希望这些对象是紧密耦合的。
|
||||
|
||||
|
||||
**结构**
|
||||
|
||||
![Observer][Observer]
|
||||
|
||||
**效果**
|
||||
|
||||
Observer模式允许你独立的改变目标和观察者
|
||||
|
||||
观察者模式可以实现表示层和数据逻辑层的分离
|
||||
|
||||
支持广播通信
|
||||
|
||||
|
||||
**应用**
|
||||
|
||||
java.util.EventListener
|
||||
|
||||
**相关**
|
||||
|
||||
终结者模式
|
||||
|
||||
单例模式
|
||||
|
||||
## 迭代器模式
|
||||
|
||||
**定义**
|
||||
|
||||
提供一种方法顺序访问聚合对象中的每个元素,而又不暴露其内部表示。
|
||||
|
||||
**结构**
|
||||
|
||||
![Iterator][Iterator]
|
||||
|
||||
**效果**
|
||||
|
||||
封装性良好,用户只需要得到迭代器就可以遍历,而对于遍历算法则不用去关心。
|
||||
|
||||
增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加
|
||||
|
||||
**应用**
|
||||
|
||||
java.util.Iterator
|
||||
java.util.Enumeration
|
||||
|
||||
|
||||
**相关**
|
||||
|
||||
组合模式,常用来便利组合模式的对象图
|
||||
|
||||
备忘录模式
|
||||
|
||||
工厂方法模式,迭代器对象由实现类提供
|
||||
|
||||
# 结构型
|
||||
|
||||
## 装饰者模式
|
||||
|
||||
**定义**
|
||||
|
||||
动态地将职责附加到对象上,若要扩展功能,装饰者提供了比继承更有弹性的替代方案。
|
||||
|
||||
**案例**
|
||||
|
||||
模拟一个冲泡咖啡的程序,调料种类未知,而且以后可能增减,每种调料价格不同,客户可自行选择调料份量,现在需要计算该咖啡的价格。初步方案是列出所有可能的组合,然后计算组合的价格,但是如果调料种类较多,那么组合将会爆炸,考虑到调料的份量有无限种可能,列举组合方式不可行。
|
||||
|
||||
解决方案:将咖啡抽象,将每种调料对应一种咖啡,如加奶的咖啡,加摩卡的咖啡等,这些调料的咖啡成分由客户自己提供。
|
||||
|
||||
**适用性**
|
||||
|
||||
当需要对一个对象以可选的方式增强功能时
|
||||
|
||||
当无法使用继承的方式增强功能时
|
||||
|
||||
**结构**
|
||||
|
||||
![decorater][decorater]
|
||||
|
||||
抽象组件角色(Component):定义一个对象接口,以规范准备接受附加责任的对象,
|
||||
|
||||
即可以给这些对象动态地添加职责。
|
||||
|
||||
具体组件角色(ConcreteComponent) :被装饰者,定义一个将要被装饰增加功能的类。
|
||||
|
||||
可以给这个类的对象添加一些职责
|
||||
|
||||
抽象装饰器(Decorator):维持一个指向构件Component对象的实例,
|
||||
|
||||
并定义一个与抽象组件角色Component接口一致的接口
|
||||
|
||||
具体装饰器角色(ConcreteDecorator):向组件添加职责。
|
||||
|
||||
**效果**
|
||||
|
||||
运行时扩展现有对象,比继承灵活。
|
||||
|
||||
产生很多小类
|
||||
|
||||
|
||||
**应用**
|
||||
|
||||
java.io.BufferedInputStream(InputStream)
|
||||
|
||||
java.io.DataInputStream(InputStream)
|
||||
|
||||
java.io.BufferedOutputStream(OutputStream)
|
||||
|
||||
java.util.zip.ZipOutputStream(OutputStream)
|
||||
|
||||
java.util.Collections# checkedList|Map|Set|SortedSet|SortedMap
|
||||
|
||||
|
||||
**相关**
|
||||
|
||||
可与工厂模式和生成器模式配合使用
|
||||
|
||||
Decorator模式不同于Adapter模式,因为装饰仅改变对象的职责而不改变它的接口;而适配器将给对象一个全新的接口。
|
||||
|
||||
Strategy模式:用一个装饰你可以改变对象的外表;而Strategy模式使得你可以改变对象的内核。这是改变对象的两种途径。
|
||||
|
||||
|
||||
|
||||
## 适配器模式
|
||||
|
||||
**定义**
|
||||
|
||||
将一个类的接口,转换成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间。
|
||||
|
||||
**案例**
|
||||
|
||||
插座有插头型号对不上,用适配器抓换下。
|
||||
|
||||
**适用性**
|
||||
|
||||
想使用一个已经存在的类,而它的接口不符合需求时。
|
||||
|
||||
**结构**
|
||||
|
||||
类适配器
|
||||
|
||||
![adapter1][adapter1]
|
||||
|
||||
对象适配器
|
||||
|
||||
![adapter2][adapter2]
|
||||
|
||||
**应用**
|
||||
|
||||
java.util.Arrays# asList()
|
||||
|
||||
java.io.InputStreamReader(InputStream)
|
||||
|
||||
java.io.OutputStreamWriter(OutputStream)
|
||||
|
||||
**相关**
|
||||
|
||||
类似装饰者,而者都是包装对象,但是装饰者从不转换接口,只是增加职责,而适配器正是转换接口。
|
||||
|
||||
外观模式
|
||||
|
||||
## 代理模式
|
||||
|
||||
**定义**
|
||||
|
||||
为另一个对象提供一个替身或占位符以控制对这个对象的访问
|
||||
|
||||
**案例**
|
||||
|
||||
需要编写一个类来监控远程服务器上的一些数据,但是希望这个类易于使用。结局方案,将远程服务上的数据抽象成一个接口,用RMI进行通信,看起来就好象直接操纵了远程对象。
|
||||
|
||||
**适用性**
|
||||
|
||||
1) 远程代理(Remote Proxy)为一个位于不同的地址空间的对象提供一个本地的代理对象。这个不同的地址空间可以是在同一台主机中,也可是在另一台主机中,远程代理又叫做大使(Ambassador)
|
||||
|
||||
2) 虚拟代理(Virtual Proxy)根据需要创建开销很大的对象。如果需要创建一个资源消耗较大的对象,先创建一个消耗相对较小的对象来表示,真实对象只在需要时才会被真正创建。
|
||||
|
||||
3) 保护代理(Protection Proxy)控制对原始对象的访问。保护代理用于对象应该有不同的访问权限的时候。
|
||||
|
||||
4) 智能指引(Smart Reference)取代了简单的指针,它在访问对象时执行一些附加操作。
|
||||
|
||||
5) Copy-on-Write代理:它是虚拟代理的一种,把复制(克隆)操作延迟到只有在客户端真正需要时才执行。一般来说,对象的深克隆是一个开销较大的操作,Copy-on-Write代理可以让这个操作延迟,只有对象被用到的时候才被克隆。
|
||||
|
||||
|
||||
**结构**
|
||||
|
||||
![proxy][proxy]
|
||||
|
||||
**效果**
|
||||
|
||||
封装实现细节,只暴露数据抽象
|
||||
|
||||
延迟加载
|
||||
|
||||
权限控制
|
||||
|
||||
**应用**
|
||||
|
||||
java.lang.reflect.Proxy
|
||||
|
||||
RMI
|
||||
|
||||
**相关**
|
||||
|
||||
与装饰者很类似,然而目的不同,装饰者增加行为,代理模式控制访问
|
||||
|
||||
|
||||
## 外观模式
|
||||
|
||||
**定义**
|
||||
|
||||
提供了一个统一的接口,用来访问子系统中的一群接口。外观定义了一个高层接口,让子系统更容易使用。
|
||||
|
||||
**案例**
|
||||
|
||||
程序由多个子系统联合起来工作,而且这些子组件需要使用者自己组装,这样使用起来会很复杂,而且客户与子组件耦合较高。
|
||||
|
||||
解决方案,提供一套简化的接口,客户端可以直接操作此接口,而无需理会复杂的系统结构。
|
||||
|
||||
**适用性**
|
||||
|
||||
当需要为一个复杂子系统提供一个简单接口时。
|
||||
|
||||
|
||||
**结构**
|
||||
|
||||
![facade][facade]
|
||||
|
||||
**效果**
|
||||
|
||||
对客户屏蔽子系统组件,减少了客户处理的对象数目并使得子系统使用起来更加容易。
|
||||
|
||||
只是提供了一个访问子系统的统一入口,并不影响用户直接使用子系统类。
|
||||
|
||||
不能很好地限制客户使用子系统类
|
||||
|
||||
增加新的子系统可能需要修改外观类或客户端的源代码,违背了“开闭原则”。
|
||||
|
||||
**应用**
|
||||
|
||||
java.lang.Class
|
||||
|
||||
**相关**
|
||||
|
||||
适配器模式
|
||||
|
||||
## 组合模式
|
||||
|
||||
**定义**
|
||||
|
||||
允许你将对象组合成树形结构来表现“整体/部分”层次结构。组合能让客户以一致的方式处理个别对象以及对象组合。
|
||||
|
||||
**案例**
|
||||
|
||||
菜单中有很多道菜,而且其中甜点是个子菜单,现在需要打印整个菜单。
|
||||
|
||||
解决方案是:将子菜单与总顶层菜单的接口统一起来,都为Menu类型,大Menu内部维护菜单列表以及子Menu。
|
||||
|
||||
**适用性**
|
||||
|
||||
想表示对象的部分-整体层次结构
|
||||
|
||||
希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
|
||||
|
||||
需要注意的是,虽然通常情况下组合模式以树形结构体现,但其实不是一回事,组合模式拥有更抽象的语义,它是一种整体与部分一致的抽象。
|
||||
|
||||
**结构**
|
||||
|
||||
![composive][composive]
|
||||
|
||||
**效果**
|
||||
|
||||
定义了包含基本对象和组合对象的类层次结构 基本对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断的递归下去。
|
||||
|
||||
简化客户代码 客户可以一致地使用组合结构和单个对象。
|
||||
|
||||
使得更容易增加新类型的组件
|
||||
|
||||
更难以排除特定类型的组件
|
||||
|
||||
**应用**
|
||||
|
||||
javax.swing.JComponent# add(Component)
|
||||
|
||||
java.awt.Container# add(Component)
|
||||
|
||||
java.util.Map# putAll(Map)
|
||||
|
||||
java.util.List# addAll(Collection)
|
||||
|
||||
java.util.Set# addAll(Collection)
|
||||
|
||||
**相关**
|
||||
|
||||
可与迭代器模式搭配使用
|
||||
|
||||
|
||||
|
||||
|
||||
[Strategy]: http://my.csdn.net/uploads/201205/11/1336732187_4598.jpg
|
||||
[Singleton]: http://my.csdn.net/uploads/201204/26/1335439688_4086.jpg
|
||||
[factorymethod]: http://hi.csdn.net/attachment/201203/15/0_1331817716F3IJ.gif
|
||||
[absfactory]: http://my.csdn.net/uploads/201204/25/1335357105_2682.jpg
|
||||
[templatemethod]: http://my.csdn.net/uploads/201205/14/1336965093_1048.jpg
|
||||
[state]: http://my.csdn.net/uploads/201205/11/1336719144_5496.jpg
|
||||
[cmd]: http://my.csdn.net/uploads/201205/09/1336547877_9980.jpg
|
||||
[Observer]: http://my.csdn.net/uploads/201205/11/1336707179_9037.jpg
|
||||
[Iterator]: http://my.csdn.net/uploads/201205/28/1338213169_8415.jpg
|
||||
[decorater]: http://my.csdn.net/uploads/201205/03/1336034007_4657.jpg
|
||||
[adapter1]: http://my.csdn.net/uploads/201205/02/1335939433_8937.jpg
|
||||
[adapter2]: http://my.csdn.net/uploads/201205/02/1335939552_3860.jpg
|
||||
[proxy]: http://my.csdn.net/uploads/201205/07/1336371130_8874.jpg
|
||||
[facade]: http://my.csdn.net/uploads/201207/05/1341473411_7539.JPG
|
||||
[composive]: http://my.csdn.net/uploads/201205/03/1336015104_5713.jpg
|
||||
@@ -1,12 +0,0 @@
|
||||
---
|
||||
layout: post
|
||||
title: Javascript 总结
|
||||
tags: Javascript script
|
||||
categories: front-end
|
||||
---
|
||||
|
||||
超级长图,小心流量。
|
||||
|
||||
![javascript] [javascript]
|
||||
|
||||
[javascript]: {{"/JavaScriptMindMap.jpg" | prepend: site.imgrepo }}
|
||||
@@ -1,371 +0,0 @@
|
||||
---
|
||||
title: scheme 解释器
|
||||
tags: lisp scheme eval
|
||||
categories: lisp
|
||||
---
|
||||
|
||||
前段时间针对 [scheme][scheme] 语言写了一个解释器,现在就 fork 一下当时想法,整理一下其中的脉络,做一个思维快照,以期下次用C语言来实现时可以顺利地进行。
|
||||
成品在此:[scheme-bootstrap][scheme-bootstrap]。
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
# 词法作用域
|
||||
|
||||
一条语句,在不同的函数当中可能具备不同的含义,其中变量的值取决于具体的作用域,所以对一条语句进行解释时需要考虑当时的上下文。
|
||||
然而lisp是一种函数式的编程语言,函数可以被当成数据来进行传递,这会产生一个问题,如果函数体中存在自由变量,那么这个函数的行为将产生不可控的变化,
|
||||
问题重点不是变化,而是不可控,在语言的使用者不需要函数行为变化的时候,自由变量会从外部作用域取值,自动产生行为的变化。
|
||||
这种作用域叫做动态作用域 (Dynamic scope )。
|
||||
|
||||
像java,javascript之类的语言,都是在对象内部维护一个成员变量,函数中自由的局部变量根据这个成员变量的值来确定行为,虽然函数的行为都可变,但它是可控的。
|
||||
为了实现可控,我们需要让语言满足人的直觉,即作用域和手写的代码结构相同,即使一个函数会被传递,其内部变量的值也应当追溯到函数定义时的作用域中。
|
||||
这种作用域就叫做词法作用域 (Lexical scope)。
|
||||
|
||||
显然,实现词法作用域比动态作用域复杂些。实现动态作用域时,函数传递只要传递函数文本,然后插入到调用语句中进行解释就行了;
|
||||
而词法作用域需要为每个被传递的函数绑定一个定义时的作用域,通常将被传递函数体与定义时的作用域打包成一个数据结构,这个结构叫做`闭包`。
|
||||
javascript就是使用闭包传递函数的。
|
||||
|
||||
# 抽象语法树
|
||||
|
||||
语言被写下来之后只是一个文本,其内容是对某种数据结构的形式化描述,在对语言进行解释前,必须先对这个文本进行解析,让其描述的结构出现在内存中,这种结构叫做抽象语法树 (AST)。
|
||||
这个过程比较乏味,无非是对字符串进行扫描,发现嵌套括号就将其作为树中的一个节点。为了跳过这个过程,我选择用scheme来写解释器,lisp 天生就适合进行这样的表处理。
|
||||
类似这样用自己来解释自己的行为叫做自举。
|
||||
|
||||
# 语法
|
||||
|
||||
解释器逐行解释语句,那么碰到不同的语法关键字时应当触发不同的解释行为。
|
||||
|
||||
- **自求值表达式**
|
||||
|
||||
当碰到数字和字符串时,表示这是一个自求值表达式,即写下的文本就是值。
|
||||
|
||||
- **quote**
|
||||
|
||||
```scheme
|
||||
(quote foo)
|
||||
```
|
||||
引号表达式的值是去掉引号后的内容,其中 `'foo` 等价于 `(quote foo)`。
|
||||
|
||||
- **begin**
|
||||
|
||||
```scheme
|
||||
(begin s1 s2)
|
||||
```
|
||||
|
||||
begin 表达式表示其内容是顺序的多条语句,某些表达式只能支持单一的语句,用begin包裹这些语句后,就能当做一条语句使用。
|
||||
|
||||
- **if**
|
||||
|
||||
```scheme
|
||||
(if <predicate> <consequent> <alternative> )
|
||||
```
|
||||
|
||||
对if的处理是非常容易的,解释器先对 `predicate` 求值,如果值为真则对 `consequent` 求值,否则对 `alternative` 求值。
|
||||
|
||||
- **lambda**
|
||||
|
||||
```scheme
|
||||
(lambda (x y)
|
||||
(+ x y))
|
||||
```
|
||||
|
||||
lambda 表达式表示一个函数,对其求值就是将函数体,形参列表,作用域打包。
|
||||
|
||||
- **define**
|
||||
|
||||
```scheme
|
||||
(define var Foo)
|
||||
```
|
||||
|
||||
define 表达式表示定义,处理方式是求出 `Foo` 的值然后与 `var` 绑定,放入到当前作用域中。这个过程中隐含了对函数的定义,因为 `Foo` 可能就是一个lambda。
|
||||
|
||||
- **set!**
|
||||
|
||||
```scheme
|
||||
(set! var Foo)
|
||||
```
|
||||
|
||||
set! 语句提供了修改变量值的能力,如果没有这个关键字,scheme 就是纯粹的函数式语言,其函数将不会产生任何副作用,函数的行为将不可变。
|
||||
其处理方式类似于define,区别是一个新增,一个修改。需要注意 define 并不能代替 set!, define 定义的变量只能在某个作用域内屏蔽外部的同名变量;
|
||||
而set!将会沿着作用域链一直向上寻找匹配的变量名,然后进行修改。
|
||||
|
||||
- **变量**
|
||||
|
||||
```scheme
|
||||
foo
|
||||
```
|
||||
|
||||
对变量求值的过程与 set! 类似,解释器将沿着作用域链一直向上寻找匹配的变量名,然后取出变量的值。
|
||||
|
||||
- **函数调用**
|
||||
|
||||
```scheme
|
||||
(plus a b)
|
||||
((lambda (x y)
|
||||
(+ x y)) a b)
|
||||
```
|
||||
|
||||
函数调用看似有两种形式,其实本质是一种,对变量 `plus` 的求值和对 `lambda` 的求值都将得到一个闭包,所以函数求值的真实过程是,求参数的值,
|
||||
将参数传递给闭包,然后求闭包的值。对闭包求值的过程为,扩展作用域,将参数值与对应的形参名绑定并放入作用域,这个过程类似于define,
|
||||
然后返回闭包中的函数过程体,该过程体为一条或多条语句,每条语句都需要被进行解释,这便产生一个递归的解释过程。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# 基本操作和值
|
||||
|
||||
函数并不能从无到有定义出来,其过程总会使用一些其他的函数,例如加法,那么加法从何而来?事实上,这些非常基本的操作都是无法直接定义出来的,
|
||||
它们需要从解释器中直接映射的。为了实现方便,以下操作都直接从解释器中映射:
|
||||
- `+` `-` `*` `/` (其实减乘除可以用加法来实现,但是没这个必要),
|
||||
- `eq?`
|
||||
- `car`
|
||||
- `cdr`
|
||||
- `cons`
|
||||
|
||||
scheme中函数与数据的界限非常模糊,car cdr cons等看似基本的操作其实可以用函数来实现。
|
||||
|
||||
```scheme
|
||||
(define (cons x y)
|
||||
(define (dispatch tag)
|
||||
(cond [(= tag 0) x]
|
||||
[(= tag 1) y]))
|
||||
dispatch)
|
||||
|
||||
(define (car z)
|
||||
(z 0))
|
||||
|
||||
(define (cdr z)
|
||||
(z 1))
|
||||
```
|
||||
|
||||
基本值
|
||||
|
||||
- `true`
|
||||
- `false`
|
||||
|
||||
# 语法糖
|
||||
|
||||
语法糖并非增加什么新功能,而是让某些以有的功能写起来更舒服。对语法糖的处理也比较简单,就是将其结构变化成解释器能够认识的形式,然后发送给解释器重新解释。
|
||||
|
||||
- **define**
|
||||
|
||||
```scheme
|
||||
(define (foo bar)
|
||||
<body>)
|
||||
```
|
||||
|
||||
该表示法为函数定义的语法糖,用基本的define定义函数时,每次都要写出lambda,比较繁琐。
|
||||
该表示法等价于如下形式
|
||||
|
||||
```scheme
|
||||
(define foo (lambda (bar)
|
||||
<body>))
|
||||
```
|
||||
|
||||
- **cond**
|
||||
|
||||
```scheme
|
||||
(cond [<p1> <e1>]
|
||||
[<p2> <e2>]
|
||||
[else e ])
|
||||
```
|
||||
|
||||
cond 表达式类似于常见的switch结构,但是每个case自带break,所以无法进入多个case。cond 可以转换成嵌套的if,然后将转换后的表达式转发给解释函数重新解释。
|
||||
|
||||
```scheme
|
||||
(if p1
|
||||
e1
|
||||
(if p2
|
||||
e2
|
||||
e))
|
||||
```
|
||||
|
||||
- **and**
|
||||
|
||||
```scheme
|
||||
(and c1 c2)
|
||||
```
|
||||
|
||||
短路的逻辑与可以用嵌套的if来实现
|
||||
|
||||
```scheme
|
||||
(if c1
|
||||
(if c2
|
||||
true)
|
||||
false)
|
||||
```
|
||||
|
||||
- **or**
|
||||
|
||||
```scheme
|
||||
(or c1 c2)
|
||||
```
|
||||
|
||||
短路的逻辑或也可以用嵌套的if来实现
|
||||
|
||||
```scheme
|
||||
(if c1
|
||||
true
|
||||
(if c2
|
||||
true))
|
||||
```
|
||||
|
||||
|
||||
## let,let*,letrec
|
||||
|
||||
这三个语法糖提供了三种不同的方式来定义作用域,这三种表示法的作用各不相同,它们都建立在lambda的基础上。
|
||||
|
||||
- **let**
|
||||
|
||||
```scheme
|
||||
(let ([<var1> <exp1>]
|
||||
[<var2> <exp2>])
|
||||
<body>)
|
||||
```
|
||||
|
||||
let 表达式提供了定义一个作用域并绑定**互斥**变量的功能,var1 与 var2 在语义上没有先后之分,也不能相互访问。
|
||||
let 表达式等价于如下如下形式,这是一个普通的函数调用。
|
||||
|
||||
```scheme
|
||||
((lambda (<var1> <var2>)
|
||||
<body>)
|
||||
<exp1>
|
||||
<exp2>)
|
||||
```
|
||||
|
||||
- **let\***
|
||||
|
||||
```scheme
|
||||
(let* ([<var1> <exp1>]
|
||||
[<var2> <exp2>])
|
||||
<body>)
|
||||
```
|
||||
|
||||
let\* 表达式提供了定义一个作用域并**先后**绑定变量的功能,var1 与 var2 在语义上存在先后之分,var2 可以访问 var1,而 var1 不能访问 var2。
|
||||
let\* 表达式等价于如下形式
|
||||
|
||||
```scheme
|
||||
(let ([<var1> <exp1>])
|
||||
(let ([<var2> <exp2>])
|
||||
<body>))
|
||||
```
|
||||
|
||||
- **letrec**
|
||||
|
||||
```scheme
|
||||
(letrec ([<var1> <exp1>]
|
||||
[<var2> <exp2>])
|
||||
<body>)
|
||||
```
|
||||
|
||||
letrec 表达式提供了定义一个作用域并**同时**绑定变量的功能,var1 与 var2 在语义上为同时定义,var2 可以访问 var1,且 var1 可以访问 var2,
|
||||
letrec 的存在意义在于屏蔽外部同名变量,假定当前作用域外部存在一个变量 `var2`,那么let和let\* 中的var1求值时如果需要访问`var2`,那么将会访问这个外部的`var2`,
|
||||
而letrec不同,如果letrec的var1求值是需要访问var2,那么这个var2的值**同一作用域内**的那个`var2`的值。
|
||||
letrec 表达式等价于如下形式
|
||||
|
||||
```scheme
|
||||
(let ([<var1> **undefined**]
|
||||
[<var2> **undefined**])
|
||||
(set! var1 <exp1>)
|
||||
(set! var2 <exp2>
|
||||
<body>)
|
||||
```
|
||||
|
||||
解释器在对变量求值时会检查变量的值,如果其值为一个未定义标记,则会提示未定义错误。
|
||||
|
||||
|
||||
# 内部定义
|
||||
|
||||
函数的内部可以嵌套地使用define语句,但是define在写成文本时是存在先后的,但是函数内部定义的语义应当是同时定义,所以在对lambda进行解释时需要一些调整,
|
||||
调整内容如下,
|
||||
- 扫描出lambda体内的所有define语句,只扫描内部定义的第一层无需嵌套,然后将define的变量名和值表达式(无需求值)装配成`letrec`的kv绑定形式;
|
||||
- 扫描出lambda内部的所有非定义语句将这个序列作为`letrec`的`body`;
|
||||
- 用上面得到的两个部分组成一个`letrec`;
|
||||
- 用新得到的letrec作为body构造一个新的 lambda 来替换原来的lambda。
|
||||
|
||||
上文描述的含义为:
|
||||
|
||||
```scheme
|
||||
(lambda (foo)
|
||||
(define a <expa>)
|
||||
(define b <expb>)
|
||||
<body>)
|
||||
```
|
||||
|
||||
等价于如下形式
|
||||
|
||||
```scheme
|
||||
(lambda (foo)
|
||||
(letrec ([a <expa>]
|
||||
[b <expb>])
|
||||
<body>))
|
||||
```
|
||||
|
||||
# 惰性求值
|
||||
|
||||
为了实现惰性求值,需要提供一种延迟计算一个表达式的能力,实现方式有两种,一种是将解释器改造成惰性求值解释器,
|
||||
另一种是用一对关键字 `delay` `force` 提供局部的惰性和强制求值能力。
|
||||
|
||||
- **惰性求值解释器**
|
||||
|
||||
对任何一个表达式求值时,都不直接求值表达式而是创建一个代理的数据结构来包裹表达式和求值时的环境,这个代理可以作为该表达式值的许诺进行传递。
|
||||
当需要使用表达式的值时,再对这个代理进求值,解释器并不会完整地求出整个表达式的值,其实这个值依旧是一个代理,解释器很懒,最多只工作到刚刚满足需求的程度。
|
||||
|
||||
理论上来讲,惰性求值的效率应当高过普通的求值器,但是它有个缺陷,惰性求值与赋值语句配合使用时经常会出现意料之外的情况,因此 `haskell` 这种惰性求值的语言同时也是纯函数式的语言。
|
||||
|
||||
因为赋值产生问题例子如下,其函数的返回值并不会发生任何变化,因为赋值表达式被惰性了,并没有真正执行。
|
||||
要解决这个问题,必须提供一个机制让语言使用者主动地强制执行该表达式。
|
||||
|
||||
```scheme
|
||||
(define (f x)
|
||||
(set! x 998)
|
||||
x)
|
||||
```
|
||||
|
||||
- **delay/force**
|
||||
|
||||
用这种方式提供惰性功能并没什么理论上的变化,只是让普通的解释器增加两个case, 在碰到delay时生成代理,碰到force时强制执行。其优点是简单易用,同时缺点也非常明显,
|
||||
必须为高阶函数提供两个版本,一个版本普通,一个版本惰性,而且在使用惰性功能时,代码中会遍布这两个关键字。
|
||||
|
||||
在我写的解释器中用**delay/force**的方式提供了惰性求值的功能。
|
||||
|
||||
# 尾调用优化
|
||||
|
||||
scheme语言没有循环,循环的本质就是在递归时不断对一个变量进行读写,这个变量作为终止条件便可以控制递归的次数,在没有循环时,可以用在递归函数中传递这个变化的因子来代替。
|
||||
这种递归比较特殊,它在栈中只占一帧,并不会在栈空间累积数据,要使递归能够代替循环,必须进行尾调用优化。
|
||||
|
||||
因为我的解释器是自举的,scheme语言本身提供了对尾调用的优化,在对递归的函数进行解释时,保存当前一帧中的重要数据的负担被转嫁到了解释器中,
|
||||
如果编写解释器的语言恰好也支持尾调用优化,这一负担会消弭于无形。但是如果编写解释器的语言没有尾调用优化呢?那我们就需要自己处理这种优化。
|
||||
|
||||
处理尾调用优化比较复杂,需要将解释器写成寄存器风格,用栈来保存寄存器中的历史值。
|
||||
在解释一个表达式前,将寄存器值入栈,解释一个表达式后,栈中内容弹出到寄存器中,解释一个表达式的值不会在栈中留下任何数据。
|
||||
如果表达式中存在子表达式,那么这个过程也适用于子表达式,显而易见,子表达式解释前的数据入栈时将压在父表达式的数据之上。
|
||||
如果子表示的嵌套层数太深,数据将有可能撑满整个栈,递归函数通常极有可能嵌套太深。
|
||||
|
||||
基于这种解释器模型,可以选择让表达式序列中的最后一条语句在解释之前数据不入栈,这最后一条语句执行完毕后,直接修改寄存器,数据也不必出栈。
|
||||
如果最后一条语句仅仅为一个函数调用,那么这个语句将不会在栈中累积数据,即使这个函数是递归的也同样如此。
|
||||
|
||||
|
||||
# 垃圾回收
|
||||
|
||||
垃圾回收的目标是函数执行时扩展的作用域以及函数的闭包,判别一段内存是否可回收的方式是枚举根节点。
|
||||
从寄存器中的指针出发,经过一系列car,cdr能达到的对象,有可能影响未来的计算过程,那些不能达到的都是可回收的垃圾。
|
||||
|
||||
如果采用**停止并复制**的算法进行回收,其流程大致如下:
|
||||
|
||||
- GC开始之前,将所有寄存器内容保存到一个预先分配好的表里,并让root寄存器指向这个表的顶部序对。
|
||||
|
||||
- GC时,先从root表开始,一个一个地复制序对,原内存中被复制的序对,car标记为“破碎的心”,cdr放置一个前向指针,指向序对复制后的新位置。
|
||||
|
||||
- 状态控制,free,scan。
|
||||
free 指向下一段可用内存,内存分配时递增的地址就是通过它来实现,通过他可以知道当前内存的使用状态。
|
||||
|
||||
- GC循环,scan初始指向一个新内存区的对象A,而该对象car,cdr仍指向旧内存区的对象,假定scan正在扫描A对象的car,此时需要检查car指向的对象是否已被复制。
|
||||
如果未复制就将其复制到free所指的位置并更新free,同时在旧对象做标记,然后更新car使其指向复制后的对象。如果car指向的对象已被复制,则car更新为将该旧对象的cdr中的前向指针。
|
||||
当scan超过free时GC结束。
|
||||
|
||||
|
||||
|
||||
[scheme]:http://baike.baidu.com/link?url=wgd84RHmek_qWtVHP9uhUL97pPelbW1iiUjF39rRuIrSHeG5ekDywMoiyWXDFgkaz3sdkYS2TRXs29CzMa7paa
|
||||
[scheme-bootstrap]:https://github.com/dubuyuye/scheme-bootstrap
|
||||
@@ -1,56 +0,0 @@
|
||||
---
|
||||
title: 记一次在spring-mvc中踩坑的经历
|
||||
tags: spring mvc java
|
||||
categories: java
|
||||
---
|
||||
|
||||
今天打算在项目中加入数据验证功能,具体可参考 [数据验证][validator]
|
||||
|
||||
过程无须赘述
|
||||
|
||||
配置完成后,奇怪的现象发生了,`BindingResult.hasErrors()`永远返回false
|
||||
![hasErrors][hasErrors]
|
||||
|
||||
这是什么情况? validator 未指定?我赶紧检查配置:
|
||||
![notNull][notNull]
|
||||
|
||||
![driven][driven]
|
||||
配置没有问题,日志能够正常打印,且没有错误,排除类加载失败的可能。
|
||||
|
||||
上google搜索一下!
|
||||
![google][google]
|
||||
翻看了第一页的回复,大多来自stackoverflow,无非是让你引入包, 加配置, 我项目里配置符合这些回复的要求, 所以需要另想办法
|
||||
|
||||
自己动手吧!我加入如下代码,以验证validator是否被正确加载
|
||||
![initBinder][initBinder]
|
||||
validator果然为null, 且如果拿到validator对象并set进去,就可以解决`BindingResult.hasErrors()`永远返回false的问题,
|
||||
然而,这种处理方式需要在每个Controller中写一遍initBinder, 这种方式并不完美。
|
||||
|
||||
是什么原因造成validator丢失呢?
|
||||
我们知道`annotation-driven`会在spring中自动注册多个bean, 详情请移步[自动注册][自动注册]
|
||||
会不会是项目中存在某些配置覆盖了其中的bean,造成了validator丢失?
|
||||
仔细扫描一下配置文件, 发现果然如此, 项目中为了更换json转换器, 自定义了一个bean
|
||||
![adapter][adapter]
|
||||
|
||||
到了这个地步基本上找到原因了,解决方式很简单,将validator绑定起来就可以了
|
||||
![validator-config][validator-config]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[validator]:http://jinnianshilongnian.iteye.com/blog/1733708
|
||||
[自动注册]:https://my.oschina.net/HeliosFly/blog/205343
|
||||
[hasErrors]:{{"/mvc-validator/hasErrors.jpg" | prepend: site.imgrepo }}
|
||||
[validator-config]:{{"/mvc-validator/validator-config.jpg" | prepend: site.imgrepo }}
|
||||
[google]:{{"/mvc-validator/google.jpg" | prepend: site.imgrepo }}
|
||||
[initBinder]:{{"/mvc-validator/initBinder.jpg" | prepend: site.imgrepo }}
|
||||
[adapter]:{{"/mvc-validator/adapter.jpg" | prepend: site.imgrepo }}
|
||||
[driven]:{{"/mvc-validator/driven.jpg" | prepend: site.imgrepo }}
|
||||
[notNull]:{{"/mvc-validator/notNull.jpg" | prepend: site.imgrepo }}
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,164 +0,0 @@
|
||||
---
|
||||
title: 大对象引起的频繁FULL GC
|
||||
tags: java jvm
|
||||
categories: java
|
||||
---
|
||||
|
||||
最近发现了频繁FULL GC的情况,查看GC日志后,发现每次FULL GC后,老年代都能回收大半以上的空间,这意味着有很多临时对象被分配到了老年代。
|
||||
|
||||
用`jmap`命令导出堆转储文件,然后用jvisualvm导入后进行分析,发现char[]占据了最多了内存。
|
||||
|
||||
其中有大量的对象达到了3M,被直接担保分配进了老年代,因为暂时不知道这些对象是怎么产生的,最快的解决办法就是增大担保分配的阈值。
|
||||
|
||||
下面就是测试过程
|
||||
|
||||
~~~java
|
||||
/**
|
||||
-server
|
||||
-XX:+UseConcMarkSweepGC
|
||||
-Xms20M
|
||||
-Xmx20M
|
||||
-Xmn10M
|
||||
-XX:SurvivorRatio=8
|
||||
-XX:PretenureSizeThreshold=2000000
|
||||
-XX:+PrintGC
|
||||
-XX:+PrintGCDetails
|
||||
-XX:+PrintGCDateStamps
|
||||
-XX:+PrintHeapAtGC
|
||||
-Xloggc:/var/logs/PretenureSizeThreshold.log
|
||||
-XX:+HeapDumpOnOutOfMemoryError
|
||||
-XX:HeapDumpPath=/var/dumps/PretenureSizeThreshold.hprof
|
||||
*/
|
||||
public class PretenureSizeThreshold {
|
||||
|
||||
private static final int _1MB = 1000 * 1000;
|
||||
|
||||
public static void main(String[] args) throws Exception{
|
||||
RuntimeMXBean mxBean = ManagementFactory.getRuntimeMXBean();
|
||||
System.out.println(mxBean.getName());
|
||||
String pid = mxBean.getName().split("@")[0];
|
||||
|
||||
byte[] allocation = new byte[3*_1MB];
|
||||
|
||||
while (true){
|
||||
Thread.sleep(1000);
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
~~~text
|
||||
D:\Doc\MyRepo\learning-java>jmap -heap 14000
|
||||
Attaching to process ID 14000, please wait...
|
||||
Debugger attached successfully.
|
||||
Server compiler detected.
|
||||
JVM version is 25.121-b13
|
||||
|
||||
using parallel threads in the new generation.
|
||||
using thread-local object allocation.
|
||||
Concurrent Mark-Sweep GC
|
||||
|
||||
Heap Configuration:
|
||||
MinHeapFreeRatio = 40
|
||||
MaxHeapFreeRatio = 70
|
||||
MaxHeapSize = 20971520 (20.0MB)
|
||||
NewSize = 10485760 (10.0MB)
|
||||
MaxNewSize = 10485760 (10.0MB)
|
||||
OldSize = 10485760 (10.0MB)
|
||||
NewRatio = 2
|
||||
SurvivorRatio = 8
|
||||
MetaspaceSize = 21807104 (20.796875MB)
|
||||
CompressedClassSpaceSize = 1073741824 (1024.0MB)
|
||||
MaxMetaspaceSize = 17592186044415 MB
|
||||
G1HeapRegionSize = 0 (0.0MB)
|
||||
|
||||
Heap Usage:
|
||||
New Generation (Eden + 1 Survivor Space):
|
||||
capacity = 9437184 (9.0MB)
|
||||
used = 2748888 (2.6215438842773438MB)
|
||||
free = 6688296 (6.378456115722656MB)
|
||||
29.128265380859375% used
|
||||
Eden Space:
|
||||
capacity = 8388608 (8.0MB)
|
||||
used = 2748888 (2.6215438842773438MB)
|
||||
free = 5639720 (5.378456115722656MB)
|
||||
32.7692985534668% used
|
||||
From Space:
|
||||
capacity = 1048576 (1.0MB)
|
||||
used = 0 (0.0MB)
|
||||
free = 1048576 (1.0MB)
|
||||
0.0% used
|
||||
To Space:
|
||||
capacity = 1048576 (1.0MB)
|
||||
used = 0 (0.0MB)
|
||||
free = 1048576 (1.0MB)
|
||||
0.0% used
|
||||
concurrent mark-sweep generation:
|
||||
capacity = 10485760 (10.0MB)
|
||||
used = 3000016 (2.8610382080078125MB)
|
||||
free = 7485744 (7.1389617919921875MB)
|
||||
28.610382080078125% used
|
||||
|
||||
1815 interned Strings occupying 162040 bytes.
|
||||
~~~
|
||||
老年代占用的空间为3000016,这表示数组通过担保分配进入了老年代,多出来的16是对象头的体积
|
||||
|
||||
修改启动参数`-XX:PretenureSizeThreshold=4000000`
|
||||
|
||||
~~~text
|
||||
D:\Doc\MyRepo\learning-java>jmap -heap 2356
|
||||
Attaching to process ID 2356, please wait...
|
||||
Debugger attached successfully.
|
||||
Server compiler detected.
|
||||
JVM version is 25.121-b13
|
||||
|
||||
using parallel threads in the new generation.
|
||||
using thread-local object allocation.
|
||||
Concurrent Mark-Sweep GC
|
||||
|
||||
Heap Configuration:
|
||||
MinHeapFreeRatio = 40
|
||||
MaxHeapFreeRatio = 70
|
||||
MaxHeapSize = 20971520 (20.0MB)
|
||||
NewSize = 10485760 (10.0MB)
|
||||
MaxNewSize = 10485760 (10.0MB)
|
||||
OldSize = 10485760 (10.0MB)
|
||||
NewRatio = 2
|
||||
SurvivorRatio = 8
|
||||
MetaspaceSize = 21807104 (20.796875MB)
|
||||
CompressedClassSpaceSize = 1073741824 (1024.0MB)
|
||||
MaxMetaspaceSize = 17592186044415 MB
|
||||
G1HeapRegionSize = 0 (0.0MB)
|
||||
|
||||
Heap Usage:
|
||||
New Generation (Eden + 1 Survivor Space):
|
||||
capacity = 9437184 (9.0MB)
|
||||
used = 5748624 (5.4823150634765625MB)
|
||||
free = 3688560 (3.5176849365234375MB)
|
||||
60.91461181640625% used
|
||||
Eden Space:
|
||||
capacity = 8388608 (8.0MB)
|
||||
used = 5748624 (5.4823150634765625MB)
|
||||
free = 2639984 (2.5176849365234375MB)
|
||||
68.52893829345703% used
|
||||
From Space:
|
||||
capacity = 1048576 (1.0MB)
|
||||
used = 0 (0.0MB)
|
||||
free = 1048576 (1.0MB)
|
||||
0.0% used
|
||||
To Space:
|
||||
capacity = 1048576 (1.0MB)
|
||||
used = 0 (0.0MB)
|
||||
free = 1048576 (1.0MB)
|
||||
0.0% used
|
||||
concurrent mark-sweep generation:
|
||||
capacity = 10485760 (10.0MB)
|
||||
used = 0 (0.0MB)
|
||||
free = 10485760 (10.0MB)
|
||||
0.0% used
|
||||
|
||||
1815 interned Strings occupying 162040 bytes.
|
||||
|
||||
~~~
|
||||
此时,老年代占用0,这表示数组没有达到大对象的标准,直接分配在了新生代
|
||||
@@ -1,105 +0,0 @@
|
||||
---
|
||||
title: 大文件内容对比
|
||||
tags: java 算法 algorithm 排序
|
||||
categories: algorithm
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
最近接到一个需求,要对两个系统的订单进行对比,找出其中的差异,对比结果有4种:一致、不一致、丢失、多余。
|
||||
|
||||
如果数据量少,处理起来就很简单,例如要对A,B两份数据进行对比:
|
||||
1. 将数据A放入哈希表
|
||||
2. 遍历数据B,依据id从A中查找对应的订单
|
||||
3. 若从A中找到了对应的订单,则比较是否一致,并将此订单标记为已匹配
|
||||
4. 若从A中找不到对应的订单,则表示A丢失此订单
|
||||
5. 遍历A,筛选出所有未匹配的订单,这些订单都是A中多余的
|
||||
|
||||
但是如果数据量超大,在内存中处理就不合适了,数据需要放在磁盘上。
|
||||
基于哈希的对比算法,无法避免大量对磁盘的随机访问,因而无法使用buffer,完全的io读写性能太差,所以这个方案是不行的。
|
||||
|
||||
如果AB两个集合是有序的,那么对比将会变得容易,一次遍历就可以对比完成,例如以id排序
|
||||
1. 读取A指针对应的订单,读取B指针对应的订单
|
||||
2. 若两个订单id相等,则对比内容是否一致
|
||||
3. 若A指针订单id>B指针订单id,代表A中缺少B指针订单,记录结果,B指针移动到后一个
|
||||
4. 若A指针订单id<B指针订单id,代表A中多余了指针订单,记录结果,A指针移动到后一个
|
||||
|
||||
所以,这个问题可以拆分为:对A、B文件内容进行排序,双指针遍历 A、B。
|
||||
|
||||
# 大文件内容排序
|
||||
|
||||
对大文件的内容进行排序,可以使用拆分->排序->合并的思路
|
||||
1. 按行读取文件,将读到的行放入list
|
||||
2. 如果已读取的行达到了1万行,对list进行排序,将排序后的list逐行写入临时文件
|
||||
3. 打开多个临时文件,从每个文件的中逐行读取,选取其中订单id最小的行,写入新的临时文件
|
||||
4. 循环以上步骤,直至剩下一个文件
|
||||
|
||||
示例代码
|
||||
~~~java
|
||||
while (true){
|
||||
line = br.readLine();
|
||||
if(line != null){
|
||||
chunkRows.add(line);
|
||||
}
|
||||
if(line == null || chunkRows.size() >= initialChunkSize){
|
||||
if(chunkRows.size() > 0){
|
||||
chunkRows.sort(comparator);
|
||||
Chunk chunk = initialChunk(rowNum, chunkRows, file);
|
||||
chunkList.add(chunk);
|
||||
rowNum += chunkRows.size();
|
||||
chunkRows.clear();
|
||||
}
|
||||
}
|
||||
if(line == null){
|
||||
break;
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
~~~java
|
||||
while (true){
|
||||
List<Chunk> pollChunks = pollChunks(chunkQueue, currentLevel);
|
||||
if(CollectionUtils.isEmpty(pollChunks)){
|
||||
currentLevel++;
|
||||
continue;
|
||||
}
|
||||
//合并
|
||||
Chunk mergedChunk = merge(pollChunks, original);
|
||||
//chunkQueue 中没有后续的元素,表示此次合并是最终合并
|
||||
if(chunkQueue.size() == 0){
|
||||
chunkQueue.add(mergedChunk);
|
||||
break;
|
||||
} else {
|
||||
chunkQueue.add(mergedChunk);
|
||||
}
|
||||
}
|
||||
~~~
|
||||
|
||||
[完整代码](完整代码)
|
||||
|
||||
[完整代码]:https://github.com/bit-ranger/architecture/blob/93c189b0cc69f41dc9b030f75c812388e2e20d61/core/src/main/java/com/rainyalley/architecture/core/arithmetic/sort/FileSorter.java
|
||||
|
||||
|
||||
# 测试
|
||||
|
||||
在最后的多路合并中要考虑使用多少路进行合并,更少的路数,将产生更多的临时文件
|
||||
|
||||
拆分时需要考虑每个块的大小,过大的块将造成频繁的FULL GC
|
||||
|
||||
IO的缓冲容量区也要考虑,这将影响IO读写的速度,以及FULL GC的频率
|
||||
|
||||
以如下配置为例,在我的个人电脑上,
|
||||
cpu频率3.40GHZ,磁盘顺序读450MB/s,随机读190MB/s,顺序写250MB/s,数据宽度20为20字符
|
||||
对1千万条数据进行排序,耗时13秒。
|
||||
|
||||
~~~java
|
||||
FileSorter sorter = new FileSorter((p,n) -> p.compareTo(n),
|
||||
8, 50000, 1024*1024*2, new File("/var/tmp/fileSorter"), false);
|
||||
long start = System.currentTimeMillis();
|
||||
sorter.sort(file, dest);
|
||||
long end = System.currentTimeMillis();
|
||||
System.out.println(end - start);
|
||||
~~~
|
||||
|
||||
该排序算法既有CPU计算又有IO,CPU计算时IO空闲,IO时CPU空间,如果把该方法改写成多线程版本,理论上可以提升不少速度。
|
||||
@@ -1,97 +0,0 @@
|
||||
---
|
||||
title: 大文件内容对比多线程版本
|
||||
tags: java 算法 algorithm 排序 concurrent
|
||||
categories: algorithm
|
||||
---
|
||||
|
||||
* TOC
|
||||
{:toc}
|
||||
|
||||
这是[上一篇][上一篇]的续作,对于这个算法,其中可以同时进行的部分有
|
||||
1. 拆分后对每一个块的排序可以同时进行
|
||||
2. 合并时的不同范围之间可以同时进行,例如拆分为10个小块,那么1-5小块的合并跟6-10小块的合并过程可以同时进行
|
||||
3. 合并的不同阶段之间不可以同时进行,因为不同阶段之间有先后顺序
|
||||
4. 不存在对同一条数据的修改,所以无需进行并发控制
|
||||
|
||||
|
||||
# 线程池
|
||||
|
||||
~~~java
|
||||
this.threadPoolExecutor = new ThreadPoolExecutor(8, 8, 10L, TimeUnit.SECONDS,
|
||||
new LinkedBlockingQueue<>(8),
|
||||
new CustomizableThreadFactory("fileSorterTPE-"),
|
||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
||||
~~~
|
||||
|
||||
# 线程池消费拆分任务
|
||||
|
||||
~~~java
|
||||
List<Future<Chunk>> splitFutureList = new ArrayList<>();
|
||||
while (true){
|
||||
line = br.readLine();
|
||||
if(line != null){
|
||||
chunkRows.add(line);
|
||||
}
|
||||
if(line == null || chunkRows.size() >= initialChunkSize){
|
||||
if(chunkRows.size() > 0){
|
||||
final int rn = rowNum;
|
||||
final List<String> cr = chunkRows;
|
||||
rowNum += chunkRows.size();
|
||||
chunkRows = new ArrayList<>();
|
||||
Future<Chunk> chunk = threadPoolExecutor.submit(() -> {
|
||||
cr.sort(comparator);
|
||||
return initialChunk(rn, cr, file);
|
||||
});
|
||||
splitFutureList.add(chunk);
|
||||
}
|
||||
}
|
||||
if(line == null){
|
||||
break;
|
||||
}
|
||||
}
|
||||
chunkList = splitFutureList.stream().map(this::get).collect(Collectors.toList());
|
||||
~~~
|
||||
|
||||
|
||||
# 线程池消费合并任务
|
||||
|
||||
~~~java
|
||||
int currentLevel = INITIAL_CHUNK_LEVEL;
|
||||
List<Future<Chunk>> mergeFutureList = new ArrayList<>();
|
||||
while (true) {
|
||||
//从队列中获取一组chunk
|
||||
List<Chunk> pollChunks = pollChunks(chunkQueue, currentLevel);
|
||||
//未取到同级chunk, 表示此级别应合并完成
|
||||
if (CollectionUtils.isEmpty(pollChunks)) {
|
||||
mergeFutureList.stream().map(this::get).forEach(chunkQueue::add);
|
||||
mergeFutureList.clear();
|
||||
//chunkQueue 中只有一个元素,表示此次合并是最终合并
|
||||
if (chunkQueue.size() == 1) {
|
||||
break;
|
||||
} else {
|
||||
currentLevel++;
|
||||
continue;
|
||||
}
|
||||
}
|
||||
Future<Chunk> chunk = threadPoolExecutor.submit(() -> merge(pollChunks, original));
|
||||
mergeFutureList.add(chunk);
|
||||
}
|
||||
~~~
|
||||
|
||||
可以看到合并任务与拆分任务有些不同,拆分任务是在循环退出后才执行`Future.get`,因为拆分不用考虑先后;
|
||||
而合并任务在每次获取当前阶段的chunk结束时执行`Future.get`,这样才能避免不同的阶段之间产生混乱。
|
||||
|
||||
[完整代码][完整代码]
|
||||
|
||||
[上一篇]:https://bit-ranger.github.io/blog/algorithm/large-file-diff/
|
||||
[完整代码]:https://github.com/bit-ranger/architecture/blob/d9083d2fb71763557e6d4eb6875f9c001fd41596/core/src/main/java/com/rainyalley/architecture/core/arithmetic/sort/FileSorter.java
|
||||
|
||||
# 测试
|
||||
|
||||
在上一篇中,使用单线程,1千万条数据排序耗时13秒;
|
||||
在同一台电脑上,使用多线程后,耗时6秒,时间减少了一半。
|
||||
|
||||
在拆分过程中,每个线程都要在内存中进行排序,
|
||||
在拆分和合并过程中,每个线程都要持有自己的读写缓冲区,这无疑会增大内存的使用量。
|
||||
|
||||
究竟消耗了多少内存,我们可以使用`Java Mission Control`来观察,jdk8的bin目录下`jmc.exe`即为此工具。
|
||||
207
_posts/2019-06-02-document.md
Normal file
@@ -0,0 +1,207 @@
|
||||
---
|
||||
layout: post
|
||||
title: LOFFER文档
|
||||
date: 2019-06-02
|
||||
Author: 来自中世界
|
||||
tags: [sample, document]
|
||||
comments: true
|
||||
toc: true
|
||||
pinned: true
|
||||
---
|
||||
LOFFER是个可以帮助你get off from LOFTER的软件(我知道这个pun很烂)。
|
||||
|
||||
这是一个可以通过Fork直接发布在GitHub的Jekyll博客,你不需要编写代码或使用命令行即可获得一个部署在GitHub的博客。
|
||||
|
||||
## 更新内容
|
||||
|
||||
### 2019-07-25 V0.4.0
|
||||
|
||||
修订目录跳级会坏掉的问题,不算完美解决,但不会坏掉了。
|
||||
|
||||
增加对LaTeX渲染的支持,请见[这篇说明和示例](https://fromendworld.github.io/LOFFER/math-test/)。
|
||||
|
||||
增加置顶功能,只要在一个post的YAML Front Matter(就是文章头部的这段信息)中加入` pinned: true `,这篇文章就可以置顶了。
|
||||
|
||||
另外介绍一个给LOFFER更换主题颜色的手法。LOFFER用了一个开源的颜色表[Open Color](https://yeun.github.io/open-color/),该色表提供的可选颜色有:red, pink, grape, violet, indigo, blue, cyan, teal, green, lime, yellow。
|
||||
|
||||
LOFFER的默认状态是teal,要更换主题颜色,只要打开文件` _sass/_variables.scss `,将文件中所有的teal全部替换成你想要的颜色。例如,查找teal,替换indigo,全部替换,commit,完成!
|
||||
|
||||
### 2019-07-20 V0.3.0
|
||||
|
||||
新版本增加目录功能,在post的信息中心加入` toc: true `,这篇博文就会显示目录了。
|
||||
|
||||
这次没有对config的修改,因此应该可以通过[这个方法](https://github.com/KirstieJane/STEMMRoleModels/wiki/Syncing-your-fork-to-the-original-repository-via-the-browser),给自己提pull request来更新。
|
||||
|
||||
目录基于[jekyll-toc by allejo](https://github.com/allejo/jekyll-toc)制作。
|
||||
|
||||
目前我试用发现了一点小问题:如果你的标题级数不按套路变化,它就会搞不懂……
|
||||
|
||||
` # 一级标题 `下面必须是` ## 二级标题 `,如果是` ### 三级标题 `它就人工智障了【手动扶额】
|
||||
|
||||
注意:目前目录仅在桌面版显示。
|
||||
|
||||
|
||||
### 2019-06-30 V0.2.0
|
||||
|
||||
新版本进一步优化了一下样式,并且支持了基于GitHub Issues的评论Gitalk(请看下文的配置说明)。
|
||||
|
||||
如果你已经fork了LOFFER,想要更新到新版本的话,可以试试[这个方法](https://github.com/KirstieJane/STEMMRoleModels/wiki/Syncing-your-fork-to-the-original-repository-via-the-browser),或者你也可以干脆删掉重来,只要保留自己的大部分config设定和所有的post就好。
|
||||
|
||||
LOFFER只是容器,你的posts才是博客的核心。
|
||||
|
||||
|
||||
## 注意
|
||||
|
||||
LOFFER是一个**博客模板**,使用GitHub Pages发布个人博客是没有任何问题的。 **但是:**
|
||||
|
||||
- **请勿发布成人向内容**
|
||||
- **不要将大量图片上传到GitHub**
|
||||
|
||||
如有疑问,请阅读[GitHub Pages官方说明](https://pages.github.com/)。
|
||||
|
||||
另外,同人作品更好的发布平台是[AO3](https://archiveofourown.org/),你想你发在AO3还有tag还有kudos还有人看,是吧?
|
||||
|
||||
|
||||
## 如何使用
|
||||
|
||||
首先,这个博客主题适应手机阅读,但是,要使用它建立你自己的博客,你需要上电脑操作。
|
||||
|
||||
### 第一步 Fork到你的GitHub
|
||||
|
||||
请点击[GitHub](https://github.com/),注册一个GitHub账户。我们可以理解Git就是个文件版本管理系统,本身并不需要会代码即可使用。
|
||||
|
||||
现在你看到的LOFFER,是作为一个GitHub上的Repository(代码库)存在的,你可以把这个代码库复制到你自己的GitHub账户中,这个操作叫做Fork。
|
||||
|
||||
点击[LOFFER](https://github.com/FromEndWorld/LOFFER),进入LOFFER的GitHub Repository页面,然后点Fork:
|
||||
|
||||

|
||||
|
||||
然后你立刻就可以看到LOFFER再次出现,这次它已经属于你了,这里我建议你重命名它,点击settings,给你的博客起个名字(请尽量使用字母而非中文)。
|
||||
|
||||

|
||||
|
||||
然后,向下拉页面,你会看到“GitHub Pages”,这是GitHub内置的网站host服务,选择master,如图所示:
|
||||
|
||||

|
||||
|
||||
在几秒钟后,刷新此页面,你通常会看到这个绿色的东西(如果没看到,多等一会),你的网站已经发布成功,点击这个链接,即可查看:
|
||||
|
||||

|
||||
|
||||
你可能会看到网站长得很丑,请继续下一步.
|
||||
|
||||
### 第二步 设置站点信息
|
||||
|
||||
在你的博客的GitHub代码库页面里,选择Code,文件列表里选择_config.yml,点击打开,点击右上角笔形图标修改文档。
|
||||
|
||||
修改完成后,点击“Commit changes”。每次修改过代码库并且commit后,GitHub Pages都会自动重新发布网站,只要等上几分钟,再次刷新你的博客页面,就会看到你的修改了。
|
||||
|
||||
还有一点,**LOFFER使用的是MIT协议,大意就是全部开源随意使用,如果你要保留自己博文的权利,请编辑LICENSE文件,写上类似“_posts中的文档作者保留权利”这样的内容。**
|
||||
|
||||
### 第三步 发布博文
|
||||
|
||||
在你的博客的GitHub代码库页面里,点开_posts文件夹,这里面就是你的博客文章。
|
||||
|
||||
这些文章使用的格式是Markdown,文件后缀名是md,这是一种非常简单易用的有格式文本标记语言,你应该已经注意到,在LOFFER自带的示例性博文中有一篇中文的Markdown语法介绍。
|
||||
|
||||
更简单的办法是使用[Typora](https://typora.io/),这是一个全图形化界面,全实时预览的Markdown写作软件,非常轻量,而且免费。
|
||||
|
||||

|
||||
|
||||
在发布博文前,你需要在文章的头部添加这样的内容,包括你的文章标题,发布日期,作者名,和tag等。
|
||||
|
||||
---
|
||||
layout: post
|
||||
title: LOFFER文档
|
||||
date: 2019-06-02
|
||||
Author: 来自中世界
|
||||
categories:
|
||||
tags: [sample, document]
|
||||
comments: true
|
||||
---
|
||||
|
||||
完成后,保存为.md文件,文件名是date-标题,例如 2019-06-02-document.md (注意这里的标题会成为这个post的URL,所以推荐使用字母而非中文,它不影响页面上显示的标题),然后上传到_posts文件夹,commit,很快就可以在博客上看到新文章了。
|
||||
|
||||
### 可选:图片怎么办?
|
||||
|
||||
少量图片可以上传到images文件夹,然后在博文中添加。
|
||||
|
||||
但是GitHub用来当做图床有滥用之嫌,如果你的博客以图片为主,建议选择外链图床,例如[sm.ms](https://sm.ms/)就是和很好的选择。
|
||||
|
||||
如果想要寻找更适合自己的图床,敬请Google一下。
|
||||
|
||||
在博文中添加图片的Markdown语法是:``
|
||||
|
||||
### 可选:添加评论区
|
||||
|
||||
#### Disqus
|
||||
|
||||
LOFFER支持Disqus评论,虽然Disqus很丑,但是它是免费的,设置起来又方便,因此大家也就不要嫌弃它。
|
||||
|
||||
首先,注册一个[Disqus](https://disqus.com/)账户,我们可以选择这个免费方案:
|
||||
|
||||

|
||||
|
||||
注册成功后,新建一个站点(site),以LOFFER为例设置步骤如下:
|
||||
|
||||
首先站点名LOFFER,生成了shortname是loffer,类型可以随便选。
|
||||
|
||||

|
||||
|
||||
安装时选择Jekyll。
|
||||
|
||||

|
||||
|
||||
最后填入你的博客地址,语言可以选中文,点Complete,即可!
|
||||
|
||||

|
||||
|
||||
然后需要回到你的博客,修改_config.yml文件,在disqus字段填上你的shortname,commit,完成!
|
||||
|
||||
#### Gitalk
|
||||
|
||||
新增内容,LOFFER 0.2.0版本支持Gitalk评论区(在LOFFER示例站中仍然是Disqus,可以在[我的博客](https://himring.top/gitalk/)查看Gitalk的demo),设置方法如下:
|
||||
|
||||
首先,创建一个[OAuth application](https://github.com/settings/applications/new), 设置如图:
|
||||
|
||||

|
||||
|
||||
点Register后就会看到你所需要的两个值,clientID和clientSecret,把它们复制到你的_config.yml文件中相应的字段:
|
||||
|
||||
gitalk:
|
||||
clientID: <你的clientID>
|
||||
clientSecret: <你的clientSecret>
|
||||
repo: <你的repository名称>
|
||||
owner: <你的GitHub用户名>
|
||||
|
||||
然后commit,你的Gitalk评论区就会出现了。对于每一篇文章,都需要你来进入文章页,来初始化评论区,这一操作会在你的repository上创建一个Issue,此后的评论就是对这个Issue的回复。
|
||||
|
||||
你可以进入你的repository的Issue页面,点**Unsubscribe**来避免收到大量相关邮件。
|
||||
|
||||
注意:出于很明显的原因,最好不要同时添加Disqus和Gitalk评论区。
|
||||
|
||||
### 导入LOFTER的内容
|
||||
|
||||
这部分由于LOFTER的导出文件十分~~优秀~~,需要另外解决。
|
||||
|
||||
诸位可以使用[墨问非名太太的脚本](http://underdream.lofter.com/post/38ea7d_1c5d8a983),其中选择Jekyll输出即可。
|
||||
|
||||
我个人也在折腾一个脚本,目前还没有完全debug清楚,不管如何,请先在lofter里导出一下,存在本地也是好的,贴吧可以让2017以前所有内容全部消失,中国互联网,没什么不可能发生的。
|
||||
|
||||
## 致谢
|
||||
|
||||
* [Jekyll](https://github.com/jekyll/jekyll) - 这是本站存在的根基
|
||||
* [Kiko-now](<https://github.com/aweekj/kiko-now>) - 我首先是fork这个主题,然后再其上进行修改汉化,才有了LOFFER
|
||||
* [Font Awesome](<https://fontawesome.com/>) - 社交网络图标来自FontAwesome的免费开源内容
|
||||
|
||||
|
||||
|
||||
## 帮助这个项目
|
||||
|
||||
介绍更多人来使用它,摆脱lofter自由飞翔!
|
||||
|
||||
当然如果单说写同人的话,我还是建议大家都去AO3,但是自家博客自己架也很酷炫,你还可以选择很多其他的forkable Jeykll主题,GitHub上有很多,或者试试其他博客架设工具,例如Hexo,与代码斗其乐无穷。
|
||||
|
||||
最后,回到[LOFFER](https://github.com/FromEndWorld/LOFFER),给我点一个☆吧!
|
||||
|
||||

|
||||
47
_posts/2019-07-24-math-test.md
Normal file
@@ -0,0 +1,47 @@
|
||||
---
|
||||
layout: post
|
||||
title: LaTex渲染的说明和测试
|
||||
date: 2019-07-24
|
||||
Author: 来自中世界
|
||||
tags: [sample, document]
|
||||
comments: true
|
||||
---
|
||||
LaTeX渲染已经在全站头部文件引入,可以直接使用,公式块上下使用`$$`标明,内联公式则用`$`.
|
||||
|
||||
最好不要让公式出现在文章摘要里。
|
||||
|
||||
Jekyll的默认文章摘要是第一段,但是我在使用中发现它选取摘要不是很稳定,因此加入了手动摘要分割线,默认为`<!-- more -->`,并且加入了首页摘要的字符数限制。
|
||||
|
||||
因此有特殊符号、内容的文章,建议将这些内容折叠在摘要以下。例如本文
|
||||
|
||||
<!-- more -->
|
||||
|
||||
Block math test
|
||||
|
||||
```
|
||||
$$
|
||||
\begin{align*}
|
||||
y = y(x,t) &= A e^{i\theta} \\
|
||||
&= A (\cos \theta + i \sin \theta) \\
|
||||
&= A (\cos(kx - \omega t) + i \sin(kx - \omega t)) \\
|
||||
&= A\cos(kx - \omega t) + i A\sin(kx - \omega t) \\
|
||||
&= A\cos \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) + i A\sin \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) \\
|
||||
&= A\cos \frac{2\pi}{\lambda} (x - v t) + i A\sin \frac{2\pi}{\lambda} (x - v t)
|
||||
\end{align*}
|
||||
$$
|
||||
|
||||
```
|
||||
|
||||
$$
|
||||
\begin{align*}
|
||||
y = y(x,t) &= A e^{i\theta} \\
|
||||
&= A (\cos \theta + i \sin \theta) \\
|
||||
&= A (\cos(kx - \omega t) + i \sin(kx - \omega t)) \\
|
||||
&= A\cos(kx - \omega t) + i A\sin(kx - \omega t) \\
|
||||
&= A\cos \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) + i A\sin \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) \\
|
||||
&= A\cos \frac{2\pi}{\lambda} (x - v t) + i A\sin \frac{2\pi}{\lambda} (x - v t)
|
||||
\end{align*}
|
||||
$$
|
||||
|
||||
Inline math test `$\lim_{x \to \infty} \exp(-x) = 0$`, $\lim_{x \to \infty} \exp(-x) = 0$
|
||||
|
||||
791
_sass/_gitalk.scss
Normal file
@@ -0,0 +1,791 @@
|
||||
@font-face {
|
||||
font-family: octicons-link;
|
||||
src: url(data:font/woff;charset=utf-8;base64,d09GRgABAAAAAAZwABAAAAAACFQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABEU0lHAAAGaAAAAAgAAAAIAAAAAUdTVUIAAAZcAAAACgAAAAoAAQAAT1MvMgAAAyQAAABJAAAAYFYEU3RjbWFwAAADcAAAAEUAAACAAJThvmN2dCAAAATkAAAABAAAAAQAAAAAZnBnbQAAA7gAAACyAAABCUM+8IhnYXNwAAAGTAAAABAAAAAQABoAI2dseWYAAAFsAAABPAAAAZwcEq9taGVhZAAAAsgAAAA0AAAANgh4a91oaGVhAAADCAAAABoAAAAkCA8DRGhtdHgAAAL8AAAADAAAAAwGAACfbG9jYQAAAsAAAAAIAAAACABiATBtYXhwAAACqAAAABgAAAAgAA8ASm5hbWUAAAToAAABQgAAAlXu73sOcG9zdAAABiwAAAAeAAAAME3QpOBwcmVwAAAEbAAAAHYAAAB/aFGpk3jaTY6xa8JAGMW/O62BDi0tJLYQincXEypYIiGJjSgHniQ6umTsUEyLm5BV6NDBP8Tpts6F0v+k/0an2i+itHDw3v2+9+DBKTzsJNnWJNTgHEy4BgG3EMI9DCEDOGEXzDADU5hBKMIgNPZqoD3SilVaXZCER3/I7AtxEJLtzzuZfI+VVkprxTlXShWKb3TBecG11rwoNlmmn1P2WYcJczl32etSpKnziC7lQyWe1smVPy/Lt7Kc+0vWY/gAgIIEqAN9we0pwKXreiMasxvabDQMM4riO+qxM2ogwDGOZTXxwxDiycQIcoYFBLj5K3EIaSctAq2kTYiw+ymhce7vwM9jSqO8JyVd5RH9gyTt2+J/yUmYlIR0s04n6+7Vm1ozezUeLEaUjhaDSuXHwVRgvLJn1tQ7xiuVv/ocTRF42mNgZGBgYGbwZOBiAAFGJBIMAAizAFoAAABiAGIAznjaY2BkYGAA4in8zwXi+W2+MjCzMIDApSwvXzC97Z4Ig8N/BxYGZgcgl52BCSQKAA3jCV8CAABfAAAAAAQAAEB42mNgZGBg4f3vACQZQABIMjKgAmYAKEgBXgAAeNpjYGY6wTiBgZWBg2kmUxoDA4MPhGZMYzBi1AHygVLYQUCaawqDA4PChxhmh/8ODDEsvAwHgMKMIDnGL0x7gJQCAwMAJd4MFwAAAHjaY2BgYGaA4DAGRgYQkAHyGMF8NgYrIM3JIAGVYYDT+AEjAwuDFpBmA9KMDEwMCh9i/v8H8sH0/4dQc1iAmAkALaUKLgAAAHjaTY9LDsIgEIbtgqHUPpDi3gPoBVyRTmTddOmqTXThEXqrob2gQ1FjwpDvfwCBdmdXC5AVKFu3e5MfNFJ29KTQT48Ob9/lqYwOGZxeUelN2U2R6+cArgtCJpauW7UQBqnFkUsjAY/kOU1cP+DAgvxwn1chZDwUbd6CFimGXwzwF6tPbFIcjEl+vvmM/byA48e6tWrKArm4ZJlCbdsrxksL1AwWn/yBSJKpYbq8AXaaTb8AAHja28jAwOC00ZrBeQNDQOWO//sdBBgYGRiYWYAEELEwMTE4uzo5Zzo5b2BxdnFOcALxNjA6b2ByTswC8jYwg0VlNuoCTWAMqNzMzsoK1rEhNqByEyerg5PMJlYuVueETKcd/89uBpnpvIEVomeHLoMsAAe1Id4AAAAAAAB42oWQT07CQBTGv0JBhagk7HQzKxca2sJCE1hDt4QF+9JOS0nbaaYDCQfwCJ7Au3AHj+LO13FMmm6cl7785vven0kBjHCBhfpYuNa5Ph1c0e2Xu3jEvWG7UdPDLZ4N92nOm+EBXuAbHmIMSRMs+4aUEd4Nd3CHD8NdvOLTsA2GL8M9PODbcL+hD7C1xoaHeLJSEao0FEW14ckxC+TU8TxvsY6X0eLPmRhry2WVioLpkrbp84LLQPGI7c6sOiUzpWIWS5GzlSgUzzLBSikOPFTOXqly7rqx0Z1Q5BAIoZBSFihQYQOOBEdkCOgXTOHA07HAGjGWiIjaPZNW13/+lm6S9FT7rLHFJ6fQbkATOG1j2OFMucKJJsxIVfQORl+9Jyda6Sl1dUYhSCm1dyClfoeDve4qMYdLEbfqHf3O/AdDumsjAAB42mNgYoAAZQYjBmyAGYQZmdhL8zLdDEydARfoAqIAAAABAAMABwAKABMAB///AA8AAQAAAAAAAAAAAAAAAAABAAAAAA==) format('woff');
|
||||
}
|
||||
|
||||
.markdown-body {
|
||||
color: $base-color;
|
||||
font-family: $base-font;
|
||||
font-size: $small-font-size;
|
||||
line-height: 1.5;
|
||||
word-wrap: break-word;
|
||||
|
||||
.octicon {
|
||||
display: inline-block;
|
||||
vertical-align: text-top;
|
||||
fill: currentColor;
|
||||
vertical-align: text-bottom;
|
||||
}
|
||||
}
|
||||
// code highlight
|
||||
|
||||
.markdown-body{
|
||||
.pl-c{
|
||||
color: #6a737d;
|
||||
}
|
||||
.pl-c1,
|
||||
.pl-s .pl-v {
|
||||
color: $link-color;
|
||||
}
|
||||
.pl-e,
|
||||
.pl-en {
|
||||
color: #6f42c1;
|
||||
}
|
||||
.pl-smi,
|
||||
.pl-s .pl-s1 {
|
||||
color: #24292e;
|
||||
}
|
||||
.pl-ent {
|
||||
color: #22863a;
|
||||
}
|
||||
.pl-k {
|
||||
color: #d73a49;
|
||||
}
|
||||
.pl-s,
|
||||
.pl-pds,
|
||||
.pl-s .pl-pse .pl-s1,
|
||||
.pl-sr,
|
||||
.pl-sr .pl-cce,
|
||||
.pl-sr .pl-sre,
|
||||
.pl-sr .pl-sra {
|
||||
color: #032f62;
|
||||
}
|
||||
.pl-v,
|
||||
.pl-smw {
|
||||
color: #e36209;
|
||||
}
|
||||
.pl-bu {
|
||||
color: #b31d28;
|
||||
}
|
||||
.pl-ii {
|
||||
color: #fafbfc;
|
||||
background-color: #b31d28;
|
||||
}
|
||||
.pl-c2 {
|
||||
color: #fafbfc;
|
||||
background-color: #d73a49;
|
||||
}
|
||||
.pl-c2::before {
|
||||
content: "^M";
|
||||
}
|
||||
.pl-sr .pl-cce {
|
||||
font-weight: bold;
|
||||
color: #22863a;
|
||||
}
|
||||
.pl-ml {
|
||||
color: #735c0f;
|
||||
}
|
||||
.pl-mh,
|
||||
.pl-mh .pl-en,
|
||||
.pl-ms {
|
||||
font-weight: bold;
|
||||
color: $link-color;
|
||||
}
|
||||
.pl-mi {
|
||||
font-style: italic;
|
||||
color: #24292e;
|
||||
}
|
||||
.pl-mb {
|
||||
font-weight: bold;
|
||||
color: #24292e;
|
||||
}
|
||||
.pl-md {
|
||||
color: #b31d28;
|
||||
background-color: #ffeef0;
|
||||
}
|
||||
.pl-mi1 {
|
||||
color: #22863a;
|
||||
background-color: #f0fff4;
|
||||
}
|
||||
.pl-mc {
|
||||
color: #e36209;
|
||||
background-color: #ffebda;
|
||||
}
|
||||
.pl-mi2 {
|
||||
color: #f6f8fa;
|
||||
background-color: $link-color;
|
||||
}
|
||||
.pl-mdr {
|
||||
font-weight: bold;
|
||||
color: #6f42c1;
|
||||
}
|
||||
.pl-ba {
|
||||
color: #586069;
|
||||
}
|
||||
.pl-sg {
|
||||
color: #959da5;
|
||||
}
|
||||
.pl-corl {
|
||||
text-decoration: underline;
|
||||
color: #032f62;
|
||||
}
|
||||
.pl-0 {
|
||||
padding-left: 0 !important;
|
||||
}
|
||||
.pl-1 {
|
||||
padding-left: 4px !important;
|
||||
}
|
||||
.pl-2 {
|
||||
padding-left: 8px !important;
|
||||
}
|
||||
.pl-3 {
|
||||
padding-left: 16px !important;
|
||||
}
|
||||
.pl-4 {
|
||||
padding-left: 24px !important;
|
||||
}
|
||||
.pl-5 {
|
||||
padding-left: 32px !important;
|
||||
}
|
||||
.pl-6 {
|
||||
padding-left: 40px !important;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
.markdown-body kbd {
|
||||
display: inline-block;
|
||||
padding: 3px 5px;
|
||||
font-size: 11px;
|
||||
line-height: 10px;
|
||||
color: #444d56;
|
||||
vertical-align: middle;
|
||||
background-color: #fafbfc;
|
||||
border: solid 1px #c6cbd1;
|
||||
border-bottom-color: #959da5;
|
||||
border-radius: 3px;
|
||||
-webkit-box-shadow: inset 0 -1px 0 #959da5;
|
||||
box-shadow: inset 0 -1px 0 #959da5;
|
||||
}
|
||||
|
||||
|
||||
|
||||
.markdown-body code {
|
||||
padding: 0;
|
||||
padding-top: 0.2em;
|
||||
padding-bottom: 0.2em;
|
||||
margin: 0;
|
||||
font-size: 85%;
|
||||
background-color: rgba(27,31,35,0.05);
|
||||
border-radius: 3px;
|
||||
}
|
||||
|
||||
.markdown-body code::before,
|
||||
.markdown-body code::after {
|
||||
letter-spacing: -0.2em;
|
||||
content: "\A0";
|
||||
}
|
||||
|
||||
.markdown-body pre {
|
||||
word-wrap: normal;
|
||||
}
|
||||
|
||||
.markdown-body pre>code {
|
||||
padding: 0;
|
||||
margin: 0;
|
||||
font-size: 100%;
|
||||
word-break: normal;
|
||||
white-space: pre;
|
||||
background: transparent;
|
||||
border: 0;
|
||||
}
|
||||
|
||||
.markdown-body .highlight {
|
||||
margin-bottom: 16px;
|
||||
}
|
||||
|
||||
.markdown-body .highlight pre {
|
||||
margin-bottom: 0;
|
||||
word-break: normal;
|
||||
}
|
||||
|
||||
.markdown-body .highlight pre,
|
||||
.markdown-body pre {
|
||||
padding: 16px;
|
||||
overflow: auto;
|
||||
-webkit-overflow-scrolling: touch;
|
||||
font-size: 85%;
|
||||
line-height: 1.45;
|
||||
background-color: #f6f8fa;
|
||||
border-radius: 3px;
|
||||
}
|
||||
|
||||
.markdown-body pre code {
|
||||
display: inline;
|
||||
max-width: auto;
|
||||
padding: 0;
|
||||
margin: 0;
|
||||
overflow: visible;
|
||||
line-height: inherit;
|
||||
word-wrap: normal;
|
||||
background-color: transparent;
|
||||
border: 0;
|
||||
}
|
||||
|
||||
.markdown-body pre code::before,
|
||||
.markdown-body pre code::after {
|
||||
content: normal;
|
||||
}
|
||||
|
||||
.markdown-body .full-commit .btn-outline:not(:disabled):hover {
|
||||
color: $link-color;
|
||||
border-color: $link-color;
|
||||
}
|
||||
|
||||
.markdown-body kbd {
|
||||
display: inline-block;
|
||||
padding: 3px 5px;
|
||||
font: 11px "SFMono-Regular", Consolas, "Liberation Mono", Menlo, Courier, monospace;
|
||||
line-height: 10px;
|
||||
color: #444d56;
|
||||
vertical-align: middle;
|
||||
background-color: #fafbfc;
|
||||
border: solid 1px #d1d5da;
|
||||
border-bottom-color: #c6cbd1;
|
||||
border-radius: 3px;
|
||||
-webkit-box-shadow: inset 0 -1px 0 #c6cbd1;
|
||||
box-shadow: inset 0 -1px 0 #c6cbd1;
|
||||
}
|
||||
|
||||
.markdown-body :checked+.radio-label {
|
||||
position: relative;
|
||||
z-index: 1;
|
||||
border-color: $link-color;
|
||||
}
|
||||
|
||||
.markdown-body .task-list-item {
|
||||
list-style-type: none;
|
||||
}
|
||||
|
||||
.markdown-body .task-list-item+.task-list-item {
|
||||
margin-top: 3px;
|
||||
}
|
||||
|
||||
.markdown-body .task-list-item input {
|
||||
margin: 0 0.2em 0.25em -1.6em;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
/*
|
||||
.markdown-body hr {
|
||||
border-bottom-color: #eee;
|
||||
}
|
||||
*/
|
||||
/* variables */
|
||||
/* functions & mixins */
|
||||
/* variables - calculated */
|
||||
/* styles */
|
||||
.gt-container {
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
font-size: $base-font-size;
|
||||
/* loader */
|
||||
/* error */
|
||||
/* initing */
|
||||
/* no int */
|
||||
/* link */
|
||||
/* meta */
|
||||
/* popup */
|
||||
/* header */
|
||||
/* comments */
|
||||
/* comment */
|
||||
}
|
||||
.gt-container * {
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
.gt-container a {
|
||||
color: $link-color;
|
||||
}
|
||||
.gt-container a:hover {
|
||||
color: $link-lighten-color;
|
||||
}
|
||||
|
||||
/*
|
||||
.gt-container a.is--active {
|
||||
color: #333;
|
||||
cursor: default !important;
|
||||
}
|
||||
.gt-container a.is--active:hover {
|
||||
color: #333;
|
||||
}
|
||||
*/
|
||||
.gt-container .hide {
|
||||
display: none !important;
|
||||
}
|
||||
.gt-container .gt-svg {
|
||||
display: inline-block;
|
||||
width: 1em;
|
||||
height: 1em;
|
||||
vertical-align: sub;
|
||||
}
|
||||
.gt-container .gt-svg svg {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
fill: $link-color;
|
||||
}
|
||||
.gt-container .gt-ico {
|
||||
display: inline-block;
|
||||
}
|
||||
.gt-container .gt-ico-text {
|
||||
margin-left: 0.3125em;
|
||||
}
|
||||
.gt-container .gt-ico-github {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
.gt-container .gt-ico-github .gt-svg {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
.gt-container .gt-ico-github svg {
|
||||
fill: inherit;
|
||||
}
|
||||
.gt-container .gt-spinner {
|
||||
position: relative;
|
||||
}
|
||||
.gt-container .gt-spinner::before {
|
||||
content: '';
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
position: absolute;
|
||||
top: 3px;
|
||||
width: 0.75em;
|
||||
height: 0.75em;
|
||||
margin-top: -0.1875em;
|
||||
margin-left: -0.375em;
|
||||
border-radius: 50%;
|
||||
border: 1px solid $oc-white;
|
||||
border-top-color: $link-color;
|
||||
-webkit-animation: gt-kf-rotate 0.6s linear infinite;
|
||||
animation: gt-kf-rotate 0.6s linear infinite;
|
||||
}
|
||||
.gt-container .gt-loader {
|
||||
position: relative;
|
||||
border: 1px solid $gray;
|
||||
-webkit-animation: ease gt-kf-rotate 1.5s infinite;
|
||||
animation: ease gt-kf-rotate 1.5s infinite;
|
||||
display: inline-block;
|
||||
font-style: normal;
|
||||
width: 1.75em;
|
||||
height: 1.75em;
|
||||
line-height: 1.75em;
|
||||
border-radius: 50%;
|
||||
}
|
||||
.gt-container .gt-loader:before {
|
||||
content: '';
|
||||
position: absolute;
|
||||
display: block;
|
||||
top: 0;
|
||||
left: 50%;
|
||||
margin-top: -0.1875em;
|
||||
margin-left: -0.1875em;
|
||||
width: 0.375em;
|
||||
height: 0.375em;
|
||||
background-color: $gray;
|
||||
border-radius: 50%;
|
||||
}
|
||||
.gt-container .gt-avatar {
|
||||
display: inline-block;
|
||||
width: 3.125em;
|
||||
height: 3.125em;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-avatar {
|
||||
width: 2em;
|
||||
height: 2em;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-avatar img {
|
||||
width: 100%;
|
||||
height: auto;
|
||||
border-radius: 3px;
|
||||
}
|
||||
.gt-container .gt-avatar-github {
|
||||
width: 3em;
|
||||
height: 3em;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-avatar-github {
|
||||
width: 1.875em;
|
||||
height: 1.875em;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-btn {
|
||||
padding: 0.75em 1.25em;
|
||||
display: inline-block;
|
||||
line-height: 1;
|
||||
text-decoration: none;
|
||||
white-space: nowrap;
|
||||
cursor: pointer;
|
||||
border: 1px solid $link-color;
|
||||
border-radius: 5px;
|
||||
background-color: $link-color;
|
||||
color:$white;
|
||||
outline: none;
|
||||
font-size: 0.75em;
|
||||
}
|
||||
.gt-container .gt-btn-text {
|
||||
font-weight: 400;
|
||||
}
|
||||
.gt-container .gt-btn-loading {
|
||||
position: relative;
|
||||
margin-left: 0.5em;
|
||||
display: inline-block;
|
||||
width: 0.75em;
|
||||
height: 1em;
|
||||
vertical-align: top;
|
||||
}
|
||||
.gt-container .gt-btn.is--disable {
|
||||
cursor: not-allowed;
|
||||
opacity: 0.5;
|
||||
}
|
||||
.gt-container .gt-btn-login {
|
||||
margin-right: 0;
|
||||
}
|
||||
.gt-container .gt-btn-preview {
|
||||
background-color: $oc-white;
|
||||
color: $link-color;
|
||||
}
|
||||
.gt-container .gt-btn-preview:hover {
|
||||
background-color: $background-lighten-color;
|
||||
border-color: $link-lighten-color;
|
||||
}
|
||||
.gt-container .gt-btn-public:hover {
|
||||
background-color: $link-lighten-color;
|
||||
border-color: $link-lighten-color;
|
||||
}
|
||||
.gt-container .gt-error {
|
||||
text-align: center;
|
||||
margin: 0.625em;
|
||||
color: $error-color;
|
||||
}
|
||||
.gt-container .gt-initing {
|
||||
padding: 1.25em 0;
|
||||
text-align: center;
|
||||
}
|
||||
.gt-container .gt-initing-text {
|
||||
margin: 0.625em auto;
|
||||
font-size: 92%;
|
||||
}
|
||||
.gt-container .gt-no-init {
|
||||
padding: 1.25em 0;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
/*
|
||||
.gt-container .gt-link {
|
||||
border-bottom: 1px dotted $link-color;
|
||||
}*/
|
||||
.gt-container .gt-link-counts,
|
||||
.gt-container .gt-link-project {
|
||||
text-decoration: none;
|
||||
}
|
||||
.gt-container .gt-meta {
|
||||
margin: 1.25em 0;
|
||||
padding: 1em 0;
|
||||
position: relative;
|
||||
border-bottom: 1px solid $divider-color;
|
||||
font-size: 1em;
|
||||
position: relative;
|
||||
z-index: 10;
|
||||
}
|
||||
.gt-container .gt-meta:before,
|
||||
.gt-container .gt-meta:after {
|
||||
content: " ";
|
||||
display: table;
|
||||
}
|
||||
.gt-container .gt-meta:after {
|
||||
clear: both;
|
||||
}
|
||||
.gt-container .gt-counts {
|
||||
margin: 0 0.625em 0 0;
|
||||
}
|
||||
.gt-container .gt-user {
|
||||
float: right;
|
||||
margin: 0;
|
||||
font-size: 92%;
|
||||
}
|
||||
.gt-container .gt-user-pic {
|
||||
width: 16px;
|
||||
height: 16px;
|
||||
vertical-align: top;
|
||||
margin-right: 0.5em;
|
||||
}
|
||||
.gt-container .gt-user-inner {
|
||||
display: inline-block;
|
||||
cursor: pointer;
|
||||
}
|
||||
.gt-container .gt-user .gt-ico {
|
||||
margin: 0 0 0 0.3125em;
|
||||
}
|
||||
.gt-container .gt-user .gt-ico svg {
|
||||
fill: inherit;
|
||||
}
|
||||
.gt-container .gt-user .is--poping .gt-ico svg {
|
||||
fill: $link-color;
|
||||
}
|
||||
.gt-container .gt-version {
|
||||
color: $base-lightener-color;
|
||||
margin-left: 0.375em;
|
||||
}
|
||||
.gt-container .gt-copyright {
|
||||
margin: 0 0.9375em 0.5em;
|
||||
border-top: 1px solid $divider-color;
|
||||
padding-top: 0.5em;
|
||||
}
|
||||
.gt-container .gt-popup {
|
||||
position: absolute;
|
||||
right: 0;
|
||||
top: 2.375em;
|
||||
background: $oc-white;
|
||||
display: inline-block;
|
||||
border: 1px solid $divider-color;
|
||||
padding: 0.625em 0;
|
||||
font-size: 0.875em;
|
||||
letter-spacing: 0.5px;
|
||||
}
|
||||
.gt-container .gt-popup .gt-action {
|
||||
cursor: pointer;
|
||||
display: block;
|
||||
margin: 0.5em 0;
|
||||
padding: 0 1.125em;
|
||||
position: relative;
|
||||
text-decoration: none;
|
||||
}
|
||||
.gt-container .gt-popup .gt-action.is--active:before {
|
||||
content: '';
|
||||
width: 0.25em;
|
||||
height: 0.25em;
|
||||
background: $link-color;
|
||||
position: absolute;
|
||||
left: 0.5em;
|
||||
top: 0.4375em;
|
||||
}
|
||||
.gt-container .gt-header {
|
||||
position: relative;
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
}
|
||||
.gt-container .gt-header-comment {
|
||||
-webkit-box-flex: 1;
|
||||
-ms-flex: 1;
|
||||
flex: 1;
|
||||
margin-left: 1.25em;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-header-comment {
|
||||
margin-left: 0.875em;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-header-textarea {
|
||||
padding: 0.75em;
|
||||
display: block;
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
width: 100%;
|
||||
min-height: 5.125em;
|
||||
max-height: 15em;
|
||||
border-radius: 5px;
|
||||
border: 1px solid $divider-color;
|
||||
font-size: 0.875em;
|
||||
word-wrap: break-word;
|
||||
resize: vertical;
|
||||
background-color: $background-color;
|
||||
outline: none;
|
||||
-webkit-transition: all 0.25s ease;
|
||||
transition: all 0.25s ease;
|
||||
}
|
||||
.gt-container .gt-header-textarea:hover {
|
||||
background-color: $background-lighten-color;
|
||||
}
|
||||
.gt-container .gt-header-preview {
|
||||
padding: 0.75em;
|
||||
border-radius: 5px;
|
||||
border: 1px solid $divider-color;
|
||||
background-color: $background-color;
|
||||
}
|
||||
.gt-container .gt-header-controls {
|
||||
position: relative;
|
||||
margin: 0.75em 0 0;
|
||||
}
|
||||
.gt-container .gt-header-controls:before,
|
||||
.gt-container .gt-header-controls:after {
|
||||
content: " ";
|
||||
display: table;
|
||||
}
|
||||
.gt-container .gt-header-controls:after {
|
||||
clear: both;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-header-controls {
|
||||
margin: 0;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-header-controls-tip {
|
||||
font-size: 0.875em;
|
||||
color: $link-color;
|
||||
text-decoration: none;
|
||||
vertical-align: sub;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-header-controls-tip {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-header-controls .gt-btn {
|
||||
float: right;
|
||||
margin-left: 1.25em;
|
||||
}
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-header-controls .gt-btn {
|
||||
float: none;
|
||||
width: 100%;
|
||||
margin: 0.75em 0 0;
|
||||
}
|
||||
}
|
||||
.gt-container:after {
|
||||
content: '';
|
||||
position: fixed;
|
||||
bottom: 100%;
|
||||
left: 0;
|
||||
right: 0;
|
||||
top: 0;
|
||||
opacity: 0;
|
||||
}
|
||||
.gt-container.gt-input-focused {
|
||||
position: relative;
|
||||
}
|
||||
.gt-container.gt-input-focused:after {
|
||||
content: '';
|
||||
position: fixed;
|
||||
bottom: 0%;
|
||||
left: 0;
|
||||
right: 0;
|
||||
top: 0;
|
||||
background: $black;
|
||||
opacity: 0.6;
|
||||
-webkit-transition: opacity 0.3s, bottom 0s;
|
||||
transition: opacity 0.3s, bottom 0s;
|
||||
z-index: 9999;
|
||||
}
|
||||
.gt-container.gt-input-focused .gt-header-comment {
|
||||
z-index: 10000;
|
||||
}
|
||||
.gt-container .gt-comments {
|
||||
padding-top: 1.25em;
|
||||
}
|
||||
.gt-container .gt-comments-null {
|
||||
text-align: center;
|
||||
}
|
||||
.gt-container .gt-comments-controls {
|
||||
margin: 1.25em 0;
|
||||
text-align: center;
|
||||
}
|
||||
.gt-container .gt-comment {
|
||||
position: relative;
|
||||
padding: 0.625em 0;
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
}
|
||||
.gt-container .gt-comment-content {
|
||||
-webkit-box-flex: 1;
|
||||
-ms-flex: 1;
|
||||
flex: 1;
|
||||
margin-left: 1.25em;
|
||||
padding: 0.75em 1em;
|
||||
background-color: $background-lighten-color;
|
||||
border-radius: 5px;
|
||||
border: 1px solid $divider-color;
|
||||
overflow: auto;
|
||||
-webkit-overflow-scrolling: touch;
|
||||
-webkit-transition: all ease 0.25s;
|
||||
transition: all ease 0.25s;
|
||||
|
||||
&:hover {
|
||||
background-color: $white;
|
||||
}
|
||||
}
|
||||
|
||||
@media (max-width: 479px) {
|
||||
.gt-container .gt-comment-content {
|
||||
margin-left: 0.875em;
|
||||
padding: 0.625em 0.75em;
|
||||
}
|
||||
}
|
||||
.gt-container .gt-comment-header {
|
||||
margin-bottom: 0.5em;
|
||||
font-size: 0.875em;
|
||||
position: relative;
|
||||
}
|
||||
.gt-container .gt-comment-username {
|
||||
font-weight: 500;
|
||||
color: $link-color;
|
||||
text-decoration: none;
|
||||
}
|
||||
|
||||
/*
|
||||
.gt-container .gt-comment-username:hover {
|
||||
text-decoration: underline;
|
||||
}*/
|
||||
|
||||
.gt-container .gt-comment-text {
|
||||
margin-left: 0.5em;
|
||||
color: $base-lightener-color;
|
||||
}
|
||||
.gt-container .gt-comment-date {
|
||||
margin-left: 0.5em;
|
||||
color: $base-lightener-color;
|
||||
}
|
||||
.gt-container .gt-comment-like,
|
||||
.gt-container .gt-comment-edit,
|
||||
.gt-container .gt-comment-reply {
|
||||
position: absolute;
|
||||
height: 1.375em;
|
||||
}
|
||||
.gt-container .gt-comment-like:hover,
|
||||
.gt-container .gt-comment-edit:hover,
|
||||
.gt-container .gt-comment-reply:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
.gt-container .gt-comment-like {
|
||||
top: 0;
|
||||
right: 2em;
|
||||
}
|
||||
.gt-container .gt-comment-edit,
|
||||
.gt-container .gt-comment-reply {
|
||||
top: 0;
|
||||
right: 0;
|
||||
}
|
||||
|
||||
/* .gt-container .gt-comment-admin .gt-comment-content {
|
||||
background-color: $background-lighten-color;
|
||||
|
||||
& :hover{
|
||||
background-color:$background-lightener-color;
|
||||
}
|
||||
} */
|
||||
|
||||
@-webkit-keyframes gt-kf-rotate {
|
||||
0% {
|
||||
-webkit-transform: rotate(0);
|
||||
transform: rotate(0);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@keyframes gt-kf-rotate {
|
||||
0% {
|
||||
-webkit-transform: rotate(0);
|
||||
transform: rotate(0);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@@ -1,63 +1,82 @@
|
||||
pre, code {
|
||||
font-family: $code-font;
|
||||
}
|
||||
|
||||
code.highlighter-rouge {
|
||||
font-size: 90%;
|
||||
color: $oc-indigo-9;
|
||||
background-color: $oc-gray-1;
|
||||
padding: .1em .2em;
|
||||
border-radius: 3px;
|
||||
}
|
||||
|
||||
pre.highlight {
|
||||
font-size: $small-font-size;
|
||||
padding: .45em .45em .45em .625em;
|
||||
border: 1px solid $oc-gray-3;
|
||||
border-radius: 3px;
|
||||
margin: 1em 0;
|
||||
overflow: auto;
|
||||
-webkit-overflow-scrolling: touch;
|
||||
}
|
||||
|
||||
.highlight { background: $oc-gray-0; }
|
||||
.highlight .c { color: #999988; font-style: italic } /* Comment */
|
||||
.highlight .err { color: #a61717; background-color: #e3d2d2 } /* Error */
|
||||
.highlight .k { color: #000000; font-weight: bold } /* Keyword */
|
||||
.highlight .o { color: #000000; font-weight: bold } /* Operator */
|
||||
.highlight .k { font-weight: bold } /* Keyword */
|
||||
.highlight .o { font-weight: bold } /* Operator */
|
||||
.highlight .cm { color: #999988; font-style: italic } /* Comment.Multiline */
|
||||
.highlight .cp { color: #999999; font-weight: bold; font-style: italic } /* Comment.Preproc */
|
||||
.highlight .cp { color: #999999; font-weight: bold } /* Comment.Preproc */
|
||||
.highlight .c1 { color: #999988; font-style: italic } /* Comment.Single */
|
||||
.highlight .cs { color: #999999; font-weight: bold; font-style: italic } /* Comment.Special */
|
||||
.highlight .gd { color: #000000; background-color: #ffdddd } /* Generic.Deleted */
|
||||
.highlight .ge { color: #000000; font-style: italic } /* Generic.Emph */
|
||||
.highlight .gd .x { color: #000000; background-color: #ffaaaa } /* Generic.Deleted.Specific */
|
||||
.highlight .ge { font-style: italic } /* Generic.Emph */
|
||||
.highlight .gr { color: #aa0000 } /* Generic.Error */
|
||||
.highlight .gh { color: #999999 } /* Generic.Heading */
|
||||
.highlight .gi { color: #000000; background-color: #ddffdd } /* Generic.Inserted */
|
||||
.highlight .gi .x { color: #000000; background-color: #aaffaa } /* Generic.Inserted.Specific */
|
||||
.highlight .go { color: #888888 } /* Generic.Output */
|
||||
.highlight .gp { color: #555555 } /* Generic.Prompt */
|
||||
.highlight .gs { font-weight: bold } /* Generic.Strong */
|
||||
.highlight .gu { color: #aaaaaa } /* Generic.Subheading */
|
||||
.highlight .gt { color: #aa0000 } /* Generic.Traceback */
|
||||
.highlight .kc { color: #000000; font-weight: bold } /* Keyword.Constant */
|
||||
.highlight .kd { color: #000000; font-weight: bold } /* Keyword.Declaration */
|
||||
.highlight .kn { color: #000000; font-weight: bold } /* Keyword.Namespace */
|
||||
.highlight .kp { color: #000000; font-weight: bold } /* Keyword.Pseudo */
|
||||
.highlight .kr { color: #000000; font-weight: bold } /* Keyword.Reserved */
|
||||
.highlight .kc { font-weight: bold } /* Keyword.Constant */
|
||||
.highlight .kd { font-weight: bold } /* Keyword.Declaration */
|
||||
.highlight .kp { font-weight: bold } /* Keyword.Pseudo */
|
||||
.highlight .kr { font-weight: bold } /* Keyword.Reserved */
|
||||
.highlight .kt { color: #445588; font-weight: bold } /* Keyword.Type */
|
||||
.highlight .m { color: #009999 } /* Literal.Number */
|
||||
.highlight .s { color: #d01040 } /* Literal.String */
|
||||
.highlight .s { color: #d14 } /* Literal.String */
|
||||
.highlight .na { color: #008080 } /* Name.Attribute */
|
||||
.highlight .nb { color: #0086B3 } /* Name.Builtin */
|
||||
.highlight .nc { color: #445588; font-weight: bold } /* Name.Class */
|
||||
.highlight .no { color: #008080 } /* Name.Constant */
|
||||
.highlight .nd { color: #3c5d5d; font-weight: bold } /* Name.Decorator */
|
||||
.highlight .ni { color: #800080 } /* Name.Entity */
|
||||
.highlight .ne { color: #990000; font-weight: bold } /* Name.Exception */
|
||||
.highlight .nf { color: #990000; font-weight: bold } /* Name.Function */
|
||||
.highlight .nl { color: #990000; font-weight: bold } /* Name.Label */
|
||||
.highlight .nn { color: #555555 } /* Name.Namespace */
|
||||
.highlight .nt { color: #000080 } /* Name.Tag */
|
||||
.highlight .nv { color: #008080 } /* Name.Variable */
|
||||
.highlight .ow { color: #000000; font-weight: bold } /* Operator.Word */
|
||||
.highlight .ow { font-weight: bold } /* Operator.Word */
|
||||
.highlight .w { color: #bbbbbb } /* Text.Whitespace */
|
||||
.highlight .mf { color: #009999 } /* Literal.Number.Float */
|
||||
.highlight .mh { color: #009999 } /* Literal.Number.Hex */
|
||||
.highlight .mi { color: #009999 } /* Literal.Number.Integer */
|
||||
.highlight .mo { color: #009999 } /* Literal.Number.Oct */
|
||||
.highlight .sb { color: #d01040 } /* Literal.String.Backtick */
|
||||
.highlight .sc { color: #d01040 } /* Literal.String.Char */
|
||||
.highlight .sd { color: #d01040 } /* Literal.String.Doc */
|
||||
.highlight .s2 { color: #d01040 } /* Literal.String.Double */
|
||||
.highlight .se { color: #d01040 } /* Literal.String.Escape */
|
||||
.highlight .sh { color: #d01040 } /* Literal.String.Heredoc */
|
||||
.highlight .si { color: #d01040 } /* Literal.String.Interpol */
|
||||
.highlight .sx { color: #d01040 } /* Literal.String.Other */
|
||||
.highlight .sb { color: #d14 } /* Literal.String.Backtick */
|
||||
.highlight .sc { color: #d14 } /* Literal.String.Char */
|
||||
.highlight .sd { color: #d14 } /* Literal.String.Doc */
|
||||
.highlight .s2 { color: #d14 } /* Literal.String.Double */
|
||||
.highlight .se { color: #d14 } /* Literal.String.Escape */
|
||||
.highlight .sh { color: #d14 } /* Literal.String.Heredoc */
|
||||
.highlight .si { color: #d14 } /* Literal.String.Interpol */
|
||||
.highlight .sx { color: #d14 } /* Literal.String.Other */
|
||||
.highlight .sr { color: #009926 } /* Literal.String.Regex */
|
||||
.highlight .s1 { color: #d01040 } /* Literal.String.Single */
|
||||
.highlight .s1 { color: #d14 } /* Literal.String.Single */
|
||||
.highlight .ss { color: #990073 } /* Literal.String.Symbol */
|
||||
.highlight .bp { color: #999999 } /* Name.Builtin.Pseudo */
|
||||
.highlight .vc { color: #008080 } /* Name.Variable.Class */
|
||||
.highlight .vg { color: #008080 } /* Name.Variable.Global */
|
||||
.highlight .vi { color: #008080 } /* Name.Variable.Instance */
|
||||
.highlight .il { color: #009999 } /* Literal.Number.Integer.Long */
|
||||
.highlight .lineno{ color: rgba(0,0,0,0.3); border-right: solid 1px rgba(0,0,0,0.3); padding-right: 5px;}
|
||||
|
||||
|
||||
.highlight .il { color: #009999 } /* Literal.Number.Integer.Long */
|
||||
398
_sass/_open-color.scss
Normal file
@@ -0,0 +1,398 @@
|
||||
//
|
||||
// 𝗖 𝗢 𝗟 𝗢 𝗥
|
||||
// v 1.5.1
|
||||
// https://github.com/yeun/open-color/blob/master/open-color.scss
|
||||
// ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
|
||||
|
||||
|
||||
// General
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-white: #ffffff;
|
||||
$oc-black: #000000;
|
||||
|
||||
|
||||
// Gray
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-gray-list: (
|
||||
"0": #f8f9fa,
|
||||
"1": #f1f3f5,
|
||||
"2": #e9ecef,
|
||||
"3": #dee2e6,
|
||||
"4": #ced4da,
|
||||
"5": #adb5bd,
|
||||
"6": #868e96,
|
||||
"7": #495057,
|
||||
"8": #343a40,
|
||||
"9": #212529
|
||||
);
|
||||
|
||||
$oc-gray-0: map-get($oc-gray-list, "0");
|
||||
$oc-gray-1: map-get($oc-gray-list, "1");
|
||||
$oc-gray-2: map-get($oc-gray-list, "2");
|
||||
$oc-gray-3: map-get($oc-gray-list, "3");
|
||||
$oc-gray-4: map-get($oc-gray-list, "4");
|
||||
$oc-gray-5: map-get($oc-gray-list, "5");
|
||||
$oc-gray-6: map-get($oc-gray-list, "6");
|
||||
$oc-gray-7: map-get($oc-gray-list, "7");
|
||||
$oc-gray-8: map-get($oc-gray-list, "8");
|
||||
$oc-gray-9: map-get($oc-gray-list, "9");
|
||||
|
||||
|
||||
// Red
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-red-list: (
|
||||
"0": #fff5f5,
|
||||
"1": #ffe3e3,
|
||||
"2": #ffc9c9,
|
||||
"3": #ffa8a8,
|
||||
"4": #ff8787,
|
||||
"5": #ff6b6b,
|
||||
"6": #fa5252,
|
||||
"7": #f03e3e,
|
||||
"8": #e03131,
|
||||
"9": #c92a2a
|
||||
);
|
||||
|
||||
$oc-red-0: map-get($oc-red-list, "0");
|
||||
$oc-red-1: map-get($oc-red-list, "1");
|
||||
$oc-red-2: map-get($oc-red-list, "2");
|
||||
$oc-red-3: map-get($oc-red-list, "3");
|
||||
$oc-red-4: map-get($oc-red-list, "4");
|
||||
$oc-red-5: map-get($oc-red-list, "5");
|
||||
$oc-red-6: map-get($oc-red-list, "6");
|
||||
$oc-red-7: map-get($oc-red-list, "7");
|
||||
$oc-red-8: map-get($oc-red-list, "8");
|
||||
$oc-red-9: map-get($oc-red-list, "9");
|
||||
|
||||
|
||||
// Pink
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-pink-list: (
|
||||
"0": #fff0f6,
|
||||
"1": #ffdeeb,
|
||||
"2": #fcc2d7,
|
||||
"3": #faa2c1,
|
||||
"4": #f783ac,
|
||||
"5": #f06595,
|
||||
"6": #e64980,
|
||||
"7": #d6336c,
|
||||
"8": #c2255c,
|
||||
"9": #a61e4d
|
||||
);
|
||||
|
||||
$oc-pink-0: map-get($oc-pink-list, "0");
|
||||
$oc-pink-1: map-get($oc-pink-list, "1");
|
||||
$oc-pink-2: map-get($oc-pink-list, "2");
|
||||
$oc-pink-3: map-get($oc-pink-list, "3");
|
||||
$oc-pink-4: map-get($oc-pink-list, "4");
|
||||
$oc-pink-5: map-get($oc-pink-list, "5");
|
||||
$oc-pink-6: map-get($oc-pink-list, "6");
|
||||
$oc-pink-7: map-get($oc-pink-list, "7");
|
||||
$oc-pink-8: map-get($oc-pink-list, "8");
|
||||
$oc-pink-9: map-get($oc-pink-list, "9");
|
||||
|
||||
|
||||
// Grape
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-grape-list: (
|
||||
"0": #f8f0fc,
|
||||
"1": #f3d9fa,
|
||||
"2": #eebefa,
|
||||
"3": #e599f7,
|
||||
"4": #da77f2,
|
||||
"5": #cc5de8,
|
||||
"6": #be4bdb,
|
||||
"7": #ae3ec9,
|
||||
"8": #9c36b5,
|
||||
"9": #862e9c
|
||||
);
|
||||
|
||||
$oc-grape-0: map-get($oc-grape-list, "0");
|
||||
$oc-grape-1: map-get($oc-grape-list, "1");
|
||||
$oc-grape-2: map-get($oc-grape-list, "2");
|
||||
$oc-grape-3: map-get($oc-grape-list, "3");
|
||||
$oc-grape-4: map-get($oc-grape-list, "4");
|
||||
$oc-grape-5: map-get($oc-grape-list, "5");
|
||||
$oc-grape-6: map-get($oc-grape-list, "6");
|
||||
$oc-grape-7: map-get($oc-grape-list, "7");
|
||||
$oc-grape-8: map-get($oc-grape-list, "8");
|
||||
$oc-grape-9: map-get($oc-grape-list, "9");
|
||||
|
||||
|
||||
// Violet
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-violet-list: (
|
||||
"0": #f3f0ff,
|
||||
"1": #e5dbff,
|
||||
"2": #d0bfff,
|
||||
"3": #b197fc,
|
||||
"4": #9775fa,
|
||||
"5": #845ef7,
|
||||
"6": #7950f2,
|
||||
"7": #7048e8,
|
||||
"8": #6741d9,
|
||||
"9": #5f3dc4
|
||||
);
|
||||
|
||||
$oc-violet-0: map-get($oc-violet-list, "0");
|
||||
$oc-violet-1: map-get($oc-violet-list, "1");
|
||||
$oc-violet-2: map-get($oc-violet-list, "2");
|
||||
$oc-violet-3: map-get($oc-violet-list, "3");
|
||||
$oc-violet-4: map-get($oc-violet-list, "4");
|
||||
$oc-violet-5: map-get($oc-violet-list, "5");
|
||||
$oc-violet-6: map-get($oc-violet-list, "6");
|
||||
$oc-violet-7: map-get($oc-violet-list, "7");
|
||||
$oc-violet-8: map-get($oc-violet-list, "8");
|
||||
$oc-violet-9: map-get($oc-violet-list, "9");
|
||||
|
||||
|
||||
// Indigo
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-indigo-list: (
|
||||
"0": #edf2ff,
|
||||
"1": #dbe4ff,
|
||||
"2": #bac8ff,
|
||||
"3": #91a7ff,
|
||||
"4": #748ffc,
|
||||
"5": #5c7cfa,
|
||||
"6": #4c6ef5,
|
||||
"7": #4263eb,
|
||||
"8": #3b5bdb,
|
||||
"9": #364fc7
|
||||
);
|
||||
|
||||
$oc-indigo-0: map-get($oc-indigo-list, "0");
|
||||
$oc-indigo-1: map-get($oc-indigo-list, "1");
|
||||
$oc-indigo-2: map-get($oc-indigo-list, "2");
|
||||
$oc-indigo-3: map-get($oc-indigo-list, "3");
|
||||
$oc-indigo-4: map-get($oc-indigo-list, "4");
|
||||
$oc-indigo-5: map-get($oc-indigo-list, "5");
|
||||
$oc-indigo-6: map-get($oc-indigo-list, "6");
|
||||
$oc-indigo-7: map-get($oc-indigo-list, "7");
|
||||
$oc-indigo-8: map-get($oc-indigo-list, "8");
|
||||
$oc-indigo-9: map-get($oc-indigo-list, "9");
|
||||
|
||||
|
||||
// Blue
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-blue-list: (
|
||||
"0": #e8f7ff,
|
||||
"1": #ccedff,
|
||||
"2": #a3daff,
|
||||
"3": #72c3fc,
|
||||
"4": #4dadf7,
|
||||
"5": #329af0,
|
||||
"6": #228ae6,
|
||||
"7": #1c7cd6,
|
||||
"8": #1b6ec2,
|
||||
"9": #1862ab
|
||||
);
|
||||
|
||||
$oc-blue-0: map-get($oc-blue-list, "0");
|
||||
$oc-blue-1: map-get($oc-blue-list, "1");
|
||||
$oc-blue-2: map-get($oc-blue-list, "2");
|
||||
$oc-blue-3: map-get($oc-blue-list, "3");
|
||||
$oc-blue-4: map-get($oc-blue-list, "4");
|
||||
$oc-blue-5: map-get($oc-blue-list, "5");
|
||||
$oc-blue-6: map-get($oc-blue-list, "6");
|
||||
$oc-blue-7: map-get($oc-blue-list, "7");
|
||||
$oc-blue-8: map-get($oc-blue-list, "8");
|
||||
$oc-blue-9: map-get($oc-blue-list, "9");
|
||||
|
||||
|
||||
// Cyan
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-cyan-list: (
|
||||
"0": #e3fafc,
|
||||
"1": #c5f6fa,
|
||||
"2": #99e9f2,
|
||||
"3": #66d9e8,
|
||||
"4": #3bc9db,
|
||||
"5": #22b8cf,
|
||||
"6": #15aabf,
|
||||
"7": #1098ad,
|
||||
"8": #0c8599,
|
||||
"9": #0b7285
|
||||
);
|
||||
|
||||
$oc-cyan-0: map-get($oc-cyan-list, "0");
|
||||
$oc-cyan-1: map-get($oc-cyan-list, "1");
|
||||
$oc-cyan-2: map-get($oc-cyan-list, "2");
|
||||
$oc-cyan-3: map-get($oc-cyan-list, "3");
|
||||
$oc-cyan-4: map-get($oc-cyan-list, "4");
|
||||
$oc-cyan-5: map-get($oc-cyan-list, "5");
|
||||
$oc-cyan-6: map-get($oc-cyan-list, "6");
|
||||
$oc-cyan-7: map-get($oc-cyan-list, "7");
|
||||
$oc-cyan-8: map-get($oc-cyan-list, "8");
|
||||
$oc-cyan-9: map-get($oc-cyan-list, "9");
|
||||
|
||||
|
||||
// Teal
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-teal-list: (
|
||||
"0": #e6fcf5,
|
||||
"1": #c3fae8,
|
||||
"2": #96f2d7,
|
||||
"3": #63e6be,
|
||||
"4": #38d9a9,
|
||||
"5": #20c997,
|
||||
"6": #12b886,
|
||||
"7": #0ca678,
|
||||
"8": #099268,
|
||||
"9": #087f5b
|
||||
);
|
||||
|
||||
$oc-teal-0: map-get($oc-teal-list, "0");
|
||||
$oc-teal-1: map-get($oc-teal-list, "1");
|
||||
$oc-teal-2: map-get($oc-teal-list, "2");
|
||||
$oc-teal-3: map-get($oc-teal-list, "3");
|
||||
$oc-teal-4: map-get($oc-teal-list, "4");
|
||||
$oc-teal-5: map-get($oc-teal-list, "5");
|
||||
$oc-teal-6: map-get($oc-teal-list, "6");
|
||||
$oc-teal-7: map-get($oc-teal-list, "7");
|
||||
$oc-teal-8: map-get($oc-teal-list, "8");
|
||||
$oc-teal-9: map-get($oc-teal-list, "9");
|
||||
|
||||
|
||||
// Green
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-green-list: (
|
||||
"0": #ebfbee,
|
||||
"1": #d3f9d8,
|
||||
"2": #b2f2bb,
|
||||
"3": #8ce99a,
|
||||
"4": #69db7c,
|
||||
"5": #51cf66,
|
||||
"6": #40c057,
|
||||
"7": #37b24d,
|
||||
"8": #2f9e44,
|
||||
"9": #2b8a3e
|
||||
);
|
||||
|
||||
$oc-green-0: map-get($oc-green-list, "0");
|
||||
$oc-green-1: map-get($oc-green-list, "1");
|
||||
$oc-green-2: map-get($oc-green-list, "2");
|
||||
$oc-green-3: map-get($oc-green-list, "3");
|
||||
$oc-green-4: map-get($oc-green-list, "4");
|
||||
$oc-green-5: map-get($oc-green-list, "5");
|
||||
$oc-green-6: map-get($oc-green-list, "6");
|
||||
$oc-green-7: map-get($oc-green-list, "7");
|
||||
$oc-green-8: map-get($oc-green-list, "8");
|
||||
$oc-green-9: map-get($oc-green-list, "9");
|
||||
|
||||
|
||||
// Lime
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-lime-list: (
|
||||
"0": #f4fce3,
|
||||
"1": #e9fac8,
|
||||
"2": #d8f5a2,
|
||||
"3": #c0eb75,
|
||||
"4": #a9e34b,
|
||||
"5": #94d82d,
|
||||
"6": #82c91e,
|
||||
"7": #74b816,
|
||||
"8": #66a80f,
|
||||
"9": #5c940d
|
||||
);
|
||||
|
||||
$oc-lime-0: map-get($oc-lime-list, "0");
|
||||
$oc-lime-1: map-get($oc-lime-list, "1");
|
||||
$oc-lime-2: map-get($oc-lime-list, "2");
|
||||
$oc-lime-3: map-get($oc-lime-list, "3");
|
||||
$oc-lime-4: map-get($oc-lime-list, "4");
|
||||
$oc-lime-5: map-get($oc-lime-list, "5");
|
||||
$oc-lime-6: map-get($oc-lime-list, "6");
|
||||
$oc-lime-7: map-get($oc-lime-list, "7");
|
||||
$oc-lime-8: map-get($oc-lime-list, "8");
|
||||
$oc-lime-9: map-get($oc-lime-list, "9");
|
||||
|
||||
|
||||
// Yellow
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-yellow-list: (
|
||||
"0": #fff9db,
|
||||
"1": #fff3bf,
|
||||
"2": #ffec99,
|
||||
"3": #ffe066,
|
||||
"4": #ffd43b,
|
||||
"5": #fcc419,
|
||||
"6": #fab005,
|
||||
"7": #f59f00,
|
||||
"8": #f08c00,
|
||||
"9": #e67700
|
||||
);
|
||||
|
||||
$oc-yellow-0: map-get($oc-yellow-list, "0");
|
||||
$oc-yellow-1: map-get($oc-yellow-list, "1");
|
||||
$oc-yellow-2: map-get($oc-yellow-list, "2");
|
||||
$oc-yellow-3: map-get($oc-yellow-list, "3");
|
||||
$oc-yellow-4: map-get($oc-yellow-list, "4");
|
||||
$oc-yellow-5: map-get($oc-yellow-list, "5");
|
||||
$oc-yellow-6: map-get($oc-yellow-list, "6");
|
||||
$oc-yellow-7: map-get($oc-yellow-list, "7");
|
||||
$oc-yellow-8: map-get($oc-yellow-list, "8");
|
||||
$oc-yellow-9: map-get($oc-yellow-list, "9");
|
||||
|
||||
|
||||
// Orange
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-orange-list: (
|
||||
"0": #fff4e6,
|
||||
"1": #ffe8cc,
|
||||
"2": #ffd8a8,
|
||||
"3": #ffc078,
|
||||
"4": #ffa94d,
|
||||
"5": #ff922b,
|
||||
"6": #fd7e14,
|
||||
"7": #f76707,
|
||||
"8": #e8590c,
|
||||
"9": #d9480f
|
||||
);
|
||||
|
||||
$oc-orange-0: map-get($oc-orange-list, "0");
|
||||
$oc-orange-1: map-get($oc-orange-list, "1");
|
||||
$oc-orange-2: map-get($oc-orange-list, "2");
|
||||
$oc-orange-3: map-get($oc-orange-list, "3");
|
||||
$oc-orange-4: map-get($oc-orange-list, "4");
|
||||
$oc-orange-5: map-get($oc-orange-list, "5");
|
||||
$oc-orange-6: map-get($oc-orange-list, "6");
|
||||
$oc-orange-7: map-get($oc-orange-list, "7");
|
||||
$oc-orange-8: map-get($oc-orange-list, "8");
|
||||
$oc-orange-9: map-get($oc-orange-list, "9");
|
||||
|
||||
|
||||
// Color list
|
||||
// ───────────────────────────────────
|
||||
|
||||
$oc-color-spectrum: 9;
|
||||
|
||||
$oc-color-list: (
|
||||
$oc-gray-list: "gray",
|
||||
$oc-red-list: "red",
|
||||
$oc-pink-list: "pink",
|
||||
$oc-grape-list: "grape",
|
||||
$oc-violet-list: "violet",
|
||||
$oc-indigo-list: "indigo",
|
||||
$oc-blue-list: "blue",
|
||||
$oc-cyan-list: "cyan",
|
||||
$oc-teal-list: "teal",
|
||||
$oc-green-list: "green",
|
||||
$oc-lime-list: "lime",
|
||||
$oc-yellow-list: "yellow",
|
||||
$oc-orange-list: "orange"
|
||||
);
|
||||
53
_sass/_reset.scss
Normal file
@@ -0,0 +1,53 @@
|
||||
|
||||
/***************/
|
||||
/* MEYER RESET */
|
||||
/***************/
|
||||
|
||||
html, body, div, span, applet, object, iframe,
|
||||
h1, h2, h3, h4, h5, h6, p, blockquote, pre,
|
||||
a, abbr, acronym, address, big, cite, code,
|
||||
del, dfn, em, img, ins, kbd, q, s, samp,
|
||||
small, strike, strong, sub, sup, tt, var,
|
||||
b, u, i, center,
|
||||
dl, dt, dd, ol, ul, li,
|
||||
fieldset, form, label, legend,
|
||||
table, caption, tbody, tfoot, thead, tr, th, td,
|
||||
article, aside, canvas, details, embed,
|
||||
figure, figcaption, footer, header, hgroup,
|
||||
menu, nav, output, ruby, section, summary,
|
||||
time, mark, audio, video {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
border: 0;
|
||||
font-size: 100%;
|
||||
font: inherit;
|
||||
vertical-align: baseline;
|
||||
}
|
||||
// HTML5 display-role reset for older browsers
|
||||
article, aside, details, figcaption, figure,
|
||||
footer, header, hgroup, menu, nav, section {
|
||||
display: block;
|
||||
}
|
||||
body {
|
||||
line-height: 1;
|
||||
}
|
||||
ol, ul, dl {
|
||||
list-style: none;
|
||||
}
|
||||
blockquote, q {
|
||||
quotes: none;
|
||||
}
|
||||
blockquote:before, blockquote:after,
|
||||
q:before, q:after {
|
||||
content: '';
|
||||
content: none;
|
||||
}
|
||||
table {
|
||||
border-collapse: collapse;
|
||||
border-spacing: 0;
|
||||
}
|
||||
// Apply a natural box layout model to all elements
|
||||
// from: http://www.paulirish.com/2012/box-sizing-border-box-ftw/
|
||||
*, *:before, *:after {
|
||||
-moz-box-sizing: border-box; -webkit-box-sizing: border-box; box-sizing: border-box;
|
||||
}
|
||||
95
_sass/_variables.scss
Normal file
@@ -0,0 +1,95 @@
|
||||
|
||||
//
|
||||
// VARIABLES
|
||||
//
|
||||
|
||||
// 颜色使用opencolor https://yeun.github.io/open-color/
|
||||
// 主题色可选 red, pink, grape, violet, indigo, blue, cyan, teal, green, lime, yellow
|
||||
// 默认为teal,如果需要更换,可以直接将teal并替换成你想要的颜色,例如,查找teal,替换indigo,全部替换,保存,push,完成!
|
||||
|
||||
|
||||
// Colors
|
||||
$blue: $oc-teal-8;
|
||||
|
||||
// Grays
|
||||
$black: #000;
|
||||
$darkerGray: #222;
|
||||
$darkGray: #333;
|
||||
$gray: #666;
|
||||
$lightGray: #eee;
|
||||
$white: #fff;
|
||||
|
||||
// Font stacks
|
||||
$helvetica: Helvetica, Arial, sans-serif;
|
||||
$helveticaNeue: "Helvetica Neue", Helvetica, Arial, sans-serif;
|
||||
$georgia: Georgia, serif;
|
||||
|
||||
// Fonts
|
||||
$base-font: "Noto Serif","PT Serif",source-han-serif-sc, "Source Han Serif SC", "Source Han Serif CN", "Source Han Serif TC", "Source Han Serif TW", "Source Han Serif","Songti SC", SimSon, serif;
|
||||
$code-font: 'Menlo', 'Courier New', 'Monaco', 'Spoqa Han Sans', monospace;
|
||||
|
||||
// Font sizes
|
||||
$base-font-size: 16px;
|
||||
$small-font-size: 14px;
|
||||
|
||||
// Colors
|
||||
$base-color: $oc-gray-8;
|
||||
$base-lighten-color: $oc-gray-6;
|
||||
$base-lightener-color: $oc-gray-4;
|
||||
|
||||
$background-color: $oc-gray-0;
|
||||
$background-lighten-color: hsla(210, 17%, 98%, 0.42);
|
||||
|
||||
$text-color: $base-color;
|
||||
$link-color: $oc-teal-8;
|
||||
$link-lighten-color: $oc-teal-6;
|
||||
$link-bghv-color: $oc-teal-0;
|
||||
$divider-color: $oc-gray-1;
|
||||
|
||||
$error-color:$oc-red-8;
|
||||
|
||||
$table-border-color: $oc-gray-2;
|
||||
$table-background-color: $oc-gray-1;
|
||||
|
||||
$blockquote-color: $base-lighten-color;
|
||||
$blockquote-border-color: $oc-gray-3;
|
||||
|
||||
$footnote-link-border-color: $oc-gray-1;
|
||||
$footnote-link-background-over-color: $oc-gray-1;
|
||||
|
||||
// $selection-color: $oc-black;
|
||||
$selection-background-color: $oc-gray-3;
|
||||
|
||||
$tag-index-label-background-color: $oc-gray-2;
|
||||
$tag-index-count-background-color: hsla(210, 7%, 56%, 0.102);
|
||||
|
||||
$footer-border-color: $oc-gray-2;
|
||||
$footer-background-color: $oc-gray-0;
|
||||
|
||||
// List
|
||||
$li-bottom-space: 0.4em;
|
||||
$li-bullets-width: 1.4em;
|
||||
$li-line-height: 1.55;
|
||||
|
||||
$ul-bullets-font: inherit;
|
||||
$ul-bullets-font-size: 1.4em;
|
||||
$ul-bullets-font-line-height: 1.2;
|
||||
$ul-bullets-right-space: .3em;
|
||||
|
||||
$ol-bullets-font: inherit;
|
||||
$ol-bullets-font-size: 1em;
|
||||
$ol-bullets-font-line-height: inherit;
|
||||
$ol-bullets-right-space: .3em;
|
||||
|
||||
$li-child-size-ratio: 0.95;
|
||||
|
||||
$dt-width: 180px;
|
||||
$dt-dd-space: 20px;
|
||||
$dd-position: $dt-width+$dt-dd-space;
|
||||
|
||||
// Mobile breakpoints
|
||||
@mixin mobile {
|
||||
@media screen and (max-width: 1200px) {
|
||||
@content;
|
||||
}
|
||||
}
|
||||
7
about.md
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
layout: page
|
||||
title: 关于
|
||||
permalink: /about/
|
||||
---
|
||||
|
||||
这是一个关于页面,请编辑about.md以介绍你的博客。
|
||||
34
archive/index.html
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
layout: page
|
||||
title: 归档
|
||||
permalink: /archive/
|
||||
---
|
||||
|
||||
{% if site.posts.size == 0 %}
|
||||
<h2>No post found</h2>
|
||||
{% endif %}
|
||||
|
||||
<ul class="archive">
|
||||
{% for post in site.posts %}
|
||||
{% unless post.next %}
|
||||
<h2>{{ post.date | date: '%Y' }}</h2>
|
||||
{% else %}
|
||||
{% capture year %}{{ post.date | date: '%Y' }}{% endcapture %}
|
||||
{% capture nyear %}{{ post.next.date | date: '%Y' }}{% endcapture %}
|
||||
{% if year != nyear %}
|
||||
<h2>{{ post.date | date: '%Y' }}</h2>
|
||||
{% endif %}
|
||||
{% endunless %}
|
||||
|
||||
<li>
|
||||
{% if post.link %}
|
||||
<a href="{{ post.link }}">
|
||||
{% else %}
|
||||
<a href="{{ site.baseurl }}{{ post.url }}">
|
||||
{% endif %}
|
||||
{{ post.title }}
|
||||
</a>
|
||||
<time>{{ post.date | date: "%Y-%m-%d" }}</time>
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
BIN
favicon.ico
|
Before Width: | Height: | Size: 1.1 KiB |
30
feed.xml
@@ -1,30 +0,0 @@
|
||||
---
|
||||
layout: null
|
||||
---
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
|
||||
<channel>
|
||||
<title>{{ site.title | xml_escape }}</title>
|
||||
<description>{{ site.description | xml_escape }}</description>
|
||||
<link>{{ site.url }}{{ site.baseurl }}/</link>
|
||||
<atom:link href="{{ "/feed.xml" | prepend: site.baseurl | prepend: site.url }}" rel="self" type="application/rss+xml"/>
|
||||
<pubDate>{{ site.time | date_to_rfc822 }}</pubDate>
|
||||
<lastBuildDate>{{ site.time | date_to_rfc822 }}</lastBuildDate>
|
||||
<generator>Jekyll v{{ jekyll.version }}</generator>
|
||||
{% for post in site.posts limit:10 %}
|
||||
<item>
|
||||
<title>{{ post.title | xml_escape }}</title>
|
||||
<description>{{ post.content | xml_escape }}</description>
|
||||
<pubDate>{{ post.date | date_to_rfc822 }}</pubDate>
|
||||
<link>{{ post.url | prepend: site.baseurl | prepend: site.url }}</link>
|
||||
<guid isPermaLink="true">{{ post.url | prepend: site.baseurl | prepend: site.url }}</guid>
|
||||
{% for tag in post.tags %}
|
||||
<category>{{ tag | xml_escape }}</category>
|
||||
{% endfor %}
|
||||
{% for cat in post.categories %}
|
||||
<category>{{ cat | xml_escape }}</category>
|
||||
{% endfor %}
|
||||
</item>
|
||||
{% endfor %}
|
||||
</channel>
|
||||
</rss>
|
||||
BIN
images/404.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 54 KiB |
BIN
images/Disqus-1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 50 KiB |
BIN
images/Disqus-2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 120 KiB |
BIN
images/Disqus-3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
images/Disqus-plan.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 73 KiB |
BIN
images/Typora.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
BIN
images/application_settings.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
BIN
images/favicon.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.7 KiB |
BIN
images/fork.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
BIN
images/givemefive.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
images/logo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
BIN
images/pages.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
images/published.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
BIN
images/rename.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 51 KiB |
142
index.html
@@ -1,60 +1,96 @@
|
||||
---
|
||||
layout: default
|
||||
---
|
||||
<link rel="stylesheet" type="text/css" href="{{ '/static/css/article-list.css' | prepend: site.baseurl | prepend: site.url}}" />
|
||||
<script src="https://unpkg.com/feather-icons"></script>
|
||||
|
||||
<div class="row index">
|
||||
<div class="col-sm-10 col-sm-offset-1 col-lg-9 col-lg-offset-1_5">
|
||||
<div>
|
||||
<section class="category-slice" post-cate="All">
|
||||
{% for post in paginator.posts %}
|
||||
<article>
|
||||
<header>
|
||||
<a href="{{ site.baseurl | prepend: site.url }}/archive/#{{ post.date | date: '%Y-%m-%d' }}"><span class="octicon octicon-calendar"></span> <span>{{ post.date | date: "%Y-%m-%d" }}</span></a>
|
||||
</header>
|
||||
<div class="module">
|
||||
<a class="title" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">
|
||||
{{ post.title }}
|
||||
</a>
|
||||
<p>{% if post.excerpt.size > 32 %}{{ post.excerpt }}{% else %}{{ post.content | strip_html | strip_newlines | truncate: 160 }}{% endif %}</p>
|
||||
<a class="readmore" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">Read More</a>
|
||||
<footer>
|
||||
{% for tag in post.tags %}
|
||||
<a class="word-keep" href="{{ site.baseurl | prepend: site.url }}/tags/#{{ tag }}"><span class="octicon octicon-tag"></span> {{ tag }}</a>
|
||||
{% endfor %}
|
||||
<span class="word-keep pull-right">
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-comment"><span class="octicon octicon-comment"></span> Comment</a>
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-share"><span class="octicon octicon-file-symlink-file"></span> Share</a>
|
||||
</span>
|
||||
</footer>
|
||||
</div>
|
||||
</article>
|
||||
{% if site.posts.size == 0 %}
|
||||
<h2>No post found</h2>
|
||||
{% endif %}
|
||||
|
||||
<div class="posts">
|
||||
|
||||
{% for post in paginator.posts %}
|
||||
{% if post.pinned==true %}
|
||||
<article class="post pinned">
|
||||
<h1>
|
||||
<span title="pinned"><i data-feather="anchor"></i></span><a href="{{ site.baseurl }}{{ post.url }}">{{ post.title }}</a>
|
||||
</h1>
|
||||
|
||||
<div clsss="meta">
|
||||
<span class="date">
|
||||
{{ post.date | date: "%Y-%m-%d" }}
|
||||
</span>
|
||||
|
||||
<ul class="tag">
|
||||
{% for tag in post.tags %}
|
||||
<li>
|
||||
<a href="{{ site.url }}{{ site.baseurl }}/tags#{{ tag }}">
|
||||
{{ tag }}
|
||||
</a>
|
||||
</li>
|
||||
{% endfor %}
|
||||
</section>
|
||||
</ul>
|
||||
|
||||
<div class="pad-mid"></div>
|
||||
|
||||
<nav class="text-center">
|
||||
<ul class="pagination">
|
||||
{% if paginator.total_pages > 1 %}
|
||||
{% if paginator.previous_page %}
|
||||
<li><a href="{{ paginator.previous_page_path | prepend: site.baseurl | prepend: site.url }}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>
|
||||
{% endif %}
|
||||
{% for page in (1..paginator.total_pages) %}
|
||||
{% if page == paginator.page %}
|
||||
<li class="active"><span>{{ page }}</span></li>
|
||||
{% elsif page == 1 %}
|
||||
<li><a href="{{ '/' | prepend: site.baseurl | prepend: site.url }}">{{ page }}</a></li>
|
||||
{% else %}
|
||||
<li><a href="{{ page | prepend: '/page/' | prepend: site.baseurl | prepend: site.url }}">{{ page }}</a></li>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{% if paginator.next_page %}
|
||||
<li><a href="{{ paginator.next_page_path | prepend: site.baseurl | prepend: site.url }}" aria-label="Next"><span aria-hidden="true">»</span></a></li>
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
</ul>
|
||||
</nav>
|
||||
<script>
|
||||
feather.replace()
|
||||
</script>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="entry">
|
||||
{{ post.excerpt | truncate: 200 }}
|
||||
</div>
|
||||
|
||||
<a href="{{ site.baseurl }}{{ post.url }}" class="read-more">Read More</a>
|
||||
</article>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
|
||||
{% for post in paginator.posts %}
|
||||
{% unless post.pinned %}
|
||||
<article class="post">
|
||||
<h1>
|
||||
<a href="{{ site.baseurl }}{{ post.url }}">{{ post.title }}</a>
|
||||
</h1>
|
||||
|
||||
<div clsss="meta">
|
||||
<span class="date">
|
||||
{{ post.date | date: "%Y-%m-%d" }}
|
||||
</span>
|
||||
|
||||
<ul class="tag">
|
||||
{% for tag in post.tags %}
|
||||
<li>
|
||||
<a href="{{ site.url }}{{ site.baseurl }}/tags#{{ tag }}">
|
||||
{{ tag }}
|
||||
</a>
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<div class="entry">
|
||||
{{ post.excerpt | truncate: 200 }}
|
||||
</div>
|
||||
|
||||
<a href="{{ site.baseurl }}{{ post.url }}" class="read-more">Read More</a>
|
||||
</article>
|
||||
{% endunless %}
|
||||
{% endfor %}
|
||||
</div>
|
||||
|
||||
<div class="pagination">
|
||||
{% if paginator.previous_page %}
|
||||
<span class="prev">
|
||||
<a href="{{ site.baseurl }}{{ paginator.previous_page_path }}" class="prev">
|
||||
← 上一页
|
||||
</a>
|
||||
</span>
|
||||
{% endif %}
|
||||
{% if paginator.next_page %}
|
||||
<span class="next">
|
||||
<a href="{{ site.baseurl}}{{ paginator.next_page_path }}" class="next">
|
||||
下一页 →
|
||||
</a>
|
||||
</span>
|
||||
{% endif %}
|
||||
</div>
|
||||
|
||||
@@ -1,23 +0,0 @@
|
||||
---
|
||||
layout: page
|
||||
title: Archive
|
||||
permalink: /archive/
|
||||
icon: octicon-repo
|
||||
isNavItem: true
|
||||
styles: archive.css
|
||||
---
|
||||
|
||||
<section id="cd-timeline" class="cd-container">
|
||||
{% for post in site.posts %}
|
||||
<div class="cd-timeline-block" id="{{ post.date | date: '%Y-%m-%d' }}">
|
||||
<div class="cd-timeline-img cd-picture">
|
||||
<img src="{{ '/icon-picture.svg' | prepend: site.imgrepo }}" alt="Picture">
|
||||
</div>
|
||||
|
||||
<div class="cd-timeline-content">
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}"><h4>{{ post.title }}</h4></a>
|
||||
<span class="cd-date">{{ post.date | date: '%Y-%m-%d' }}</span>
|
||||
</div>
|
||||
</div>
|
||||
{% endfor %}
|
||||
</section>
|
||||
@@ -1,101 +0,0 @@
|
||||
---
|
||||
layout: default
|
||||
title: Category
|
||||
permalink: /category/
|
||||
icon: octicon-list-unordered
|
||||
isNavItem: true
|
||||
styles : [article-list.css,category.css]
|
||||
scripts: [category.js]
|
||||
---
|
||||
|
||||
<div class="row index">
|
||||
|
||||
|
||||
<div class="col-sm-10 col-sm-offset-1 col-lg-9 col-lg-offset-1_5">
|
||||
|
||||
<div class="dropdown">
|
||||
<button class="btn btn-default dropdown-toggle" type="button" id="dropdownMenu1" data-toggle="dropdown" aria-haspopup="true" aria-expanded="true">
|
||||
<span class="octicon octicon-list-unordered"></span> Categories
|
||||
<span class="caret"></span>
|
||||
</button>
|
||||
<ul class="dropdown-menu" aria-labelledby="dropdownMenu1">
|
||||
<li>
|
||||
<a href="javascript:void(0);" class="categories-item" cate="All">
|
||||
All <span class="categories-badge"> {{site.posts | size}}</span>
|
||||
</a>
|
||||
</li>
|
||||
{% for category in site.categories %}
|
||||
<li>
|
||||
<a href="javascript:void(0);" class="categories-item" cate="{{ category | first }}">
|
||||
{{ category | first }} <span class="categories-badge">{{ category | last | size }}</span>
|
||||
</a>
|
||||
</li>
|
||||
|
||||
{% endfor %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
|
||||
<div>
|
||||
<section class="category-slice" post-cate="All">
|
||||
{% for post in site.posts %}
|
||||
<article>
|
||||
<header>
|
||||
<a href="{{ site.baseurl | prepend: site.url }}/archive/#{{ post.date | date: '%Y-%m-%d' }}"><span class="octicon octicon-calendar"></span> <span>{{ post.date | date: "%Y-%m-%d" }}</span></a>
|
||||
</header>
|
||||
<div class="module">
|
||||
<a class="title" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">
|
||||
{{ post.title }}
|
||||
</a>
|
||||
<p>{% if post.excerpt.size > 32 %}{{ post.excerpt }}{% else %}{{ post.content | strip_html | strip_newlines | truncate: 160 }}{% endif %}</p>
|
||||
<a class="readmore" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">Read More</a>
|
||||
<footer>
|
||||
{% for tag in post.tags %}
|
||||
<a class="word-keep" href="{{ site.baseurl | prepend: site.url }}/tags/#{{ tag }}"><span class="octicon octicon-tag"></span> {{ tag }}</a>
|
||||
{% endfor %}
|
||||
<span class="word-keep pull-right">
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-comment"><span class="octicon octicon-comment"></span> Comment</a>
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-share"><span class="octicon octicon-file-symlink-file"></span> Share</a>
|
||||
</span>
|
||||
</footer>
|
||||
</div>
|
||||
</article>
|
||||
{% endfor %}
|
||||
</section>
|
||||
|
||||
|
||||
{% for category in site.categories %}
|
||||
<section class="category-slice" post-cate="{{category | first}}">
|
||||
{% for posts in category %}
|
||||
{% for post in posts %}
|
||||
{% if post.url %}
|
||||
<article>
|
||||
<header>
|
||||
<a href="{{ site.baseurl | prepend: site.url }}/archive/#{{ post.date | date: '%Y-%m-%d' }}"><span class="octicon octicon-calendar"></span> <span>{{ post.date | date: "%Y-%m-%d" }}</span></a>
|
||||
</header>
|
||||
<div class="module">
|
||||
<a class="title" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">
|
||||
{{ post.title }}
|
||||
</a>
|
||||
<p>{% if post.excerpt.size > 32 %}{{ post.excerpt }}{% else %}{{ post.content | strip_html | strip_newlines | truncate: 160 }}{% endif %}</p>
|
||||
<a class="readmore" href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">Read More</a>
|
||||
<footer>
|
||||
{% for tag in post.tags %}
|
||||
<a class="word-keep" href="{{ site.baseurl | prepend: site.url }}/tags/#{{ tag }}"><span class="octicon octicon-tag"></span> {{ tag }}</a>
|
||||
{% endfor %}
|
||||
<span class="word-keep pull-right">
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-comment"><span class="octicon octicon-comment"></span> Comment</a>
|
||||
<a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}#post-share"><span class="octicon octicon-file-symlink-file"></span> Share</a>
|
||||
</span>
|
||||
</footer>
|
||||
</div>
|
||||
</article>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{% endfor %}
|
||||
</section>
|
||||
{% endfor %}
|
||||
</div>
|
||||
|
||||
</div>
|
||||
</div>
|
||||
@@ -1,36 +0,0 @@
|
||||
---
|
||||
layout: page
|
||||
title: Tag
|
||||
permalink: /tags/
|
||||
icon: octicon-tag
|
||||
isNavItem: true
|
||||
styles: [tagCloud.css,tags.css]
|
||||
scripts: [tagCloud.js,tags.js]
|
||||
---
|
||||
|
||||
<div class="tagCloud">
|
||||
{% for tag in site.tags %}
|
||||
<a href="#{{ tag | first }}">{{ tag | first }}</a>
|
||||
{% endfor %}
|
||||
</div>
|
||||
|
||||
<div>
|
||||
<ul class="tag-box inline">
|
||||
{% for tag in site.tags %}
|
||||
<li><a href="#{{ tag | first }}">{{ tag | first }}<span>{{ tag | last | size }}</span></a></li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<div>
|
||||
{% for tag in site.tags %}
|
||||
<h2 id="{{ tag | first }}">{{ tag | first }}</h2>
|
||||
<ul>
|
||||
{% for posts in tag %}{% for post in posts %}{% if post.title != null %}
|
||||
<li itemscope><span class="entry-date"><time datetime="{{ post.date | date_to_xmlschema }}" itemprop="datePublished">{{ post.date | date_to_string }}</time></span> » <a href="{{ post.url | prepend: site.baseurl | prepend: site.url }}">{{ post.title }}</a></li>
|
||||
{% endif %}{% endfor %}{% endfor %}
|
||||
</ul>
|
||||
{% endfor %}
|
||||
</div>
|
||||
|
||||
|
||||
@@ -1,8 +0,0 @@
|
||||
---
|
||||
layout: page
|
||||
title: About
|
||||
permalink: /about/
|
||||
icon: octicon-heart
|
||||
---
|
||||
|
||||
自我介绍什么的,最讨厌了!
|
||||
@@ -1,9 +0,0 @@
|
||||
---
|
||||
layout: page
|
||||
title: Link
|
||||
permalink: /link/
|
||||
icon: octicon-link-external
|
||||
|
||||
---
|
||||
|
||||
### [github](https://github.com/bit-ranger/blog)
|
||||
24
sitemap.xml
@@ -1,24 +0,0 @@
|
||||
---
|
||||
layout: null
|
||||
---
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
|
||||
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
|
||||
{% for post in site.posts %}
|
||||
<url>
|
||||
<loc>{{ post.url | prepend: site.baseurl | prepend: site.url }}</loc>
|
||||
<lastmod>{{ site.time | date_to_xmlschema }}</lastmod>
|
||||
<changefreq>weekly</changefreq>
|
||||
</url>
|
||||
{% endfor %}
|
||||
{% for post in site.pages %}{% if post.isNavItem %}
|
||||
<url>
|
||||
<loc>{{ post.url | prepend: site.baseurl | prepend: site.url }}</loc>
|
||||
<lastmod>{{ site.time | date_to_xmlschema }}</lastmod>
|
||||
<changefreq>weekly</changefreq>
|
||||
</url>
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
</urlset>
|
||||
BIN
static/bg.jpg
{kind=link}
|
Before Width: | Height: | Size: 2.0 KiB |