del pic
11
README.md
@@ -1,9 +1,14 @@
|
|||||||
lemonchann的个人博客仓库。
|
这是一个可 fork 的博客模板仓库,帮助你快速搭建自己的博客,可以参考[这篇文章](https://github.com/lemonchann/lemonchann.github.io/blob/master/_posts/2019-11-22-create_blog_with_github_pages.md)详细指导搭建步骤。
|
||||||
|
|
||||||
### 文章版权
|
### 文章版权
|
||||||
|
|
||||||
**[_posts](https://github.com/lemonchann/lemonchann.github.io/tree/master/_posts)** 文件夹内所有文章若无特别声明均使用[CC BY-SA 4.0 International License(知识共享署名-相同方式共享 4.0 国际许可协议)](http://creativecommons.org/licenses/by-sa/4.0/)授权。
|
`_posts` 文件夹内所有文章版权归我所有,转载需联系我获得授权。
|
||||||
|
|
||||||
### 致谢
|
### 致谢
|
||||||
|
|
||||||
本站原始主题来自Jekyll主题[LOFFER](https://fromendworld.github.io/LOFFER/)
|
感谢Jekyll主题[LOFFER](https://fromendworld.github.io/LOFFER/)模提供了原始主题模板,我在其上进行的二次开发。
|
||||||
|
|
||||||
|
如果搭建过程中有什么问题,也可以在我的个人技术公众号「后端技术学堂」讨论交流,扫码添加。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
20
_config.yml
@@ -3,16 +3,16 @@
|
|||||||
#
|
#
|
||||||
|
|
||||||
# Name of your site (displayed in the header)
|
# Name of your site (displayed in the header)
|
||||||
name: "lemonchann's blog"
|
name: "lemon's blog"
|
||||||
# Short bio or description (displayed in the header)
|
# Short bio or description (displayed in the header)
|
||||||
description: "learning and practicing make skillfull"
|
description: "个人技术公众号「后端技术学堂」分享、记录、成长"
|
||||||
|
|
||||||
#
|
#
|
||||||
# Flags below are optional
|
# Flags below are optional
|
||||||
#
|
#
|
||||||
|
|
||||||
# URL of your avatar or profile pic (you could use your GitHub profile pic)
|
# URL of your avatar or profile pic (you could use your GitHub profile pic)
|
||||||
avatar: https://github.com/lemonchann/lemonchann.github.io/raw/master/images/blog.jpg
|
avatar: https://upload-images.jianshu.io/upload_images/7842464-15f939ec039690f6.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240
|
||||||
|
|
||||||
# 你的favicon(出现在浏览器tab上)图片URL,建议使用较小(64px × 64px)的图片
|
# 你的favicon(出现在浏览器tab上)图片URL,建议使用较小(64px × 64px)的图片
|
||||||
favicon: https://github.com/lemonchann/lemonchann.github.io/raw/master/images/favicon.ico
|
favicon: https://github.com/lemonchann/lemonchann.github.io/raw/master/images/favicon.ico
|
||||||
@@ -21,13 +21,13 @@ favicon: https://github.com/lemonchann/lemonchann.github.io/raw/master/images/fa
|
|||||||
# and URL Link(e.g. 'Theme' tab below) tabs. If you don't need one, just delete
|
# and URL Link(e.g. 'Theme' tab below) tabs. If you don't need one, just delete
|
||||||
# it from the list(Delete '- name: ' and 'url: ', too!)
|
# it from the list(Delete '- name: ' and 'url: ', too!)
|
||||||
navigation:
|
navigation:
|
||||||
- name: Blog
|
- name: 首页
|
||||||
url: /
|
url: /
|
||||||
- name: About
|
- name: 关于
|
||||||
url: /about
|
url: /about
|
||||||
- name: Archive
|
- name: 归档
|
||||||
url: /archive
|
url: /archive
|
||||||
- name: Tags
|
- name: 标签
|
||||||
url: /tags
|
url: /tags
|
||||||
|
|
||||||
# Pagination
|
# Pagination
|
||||||
@@ -40,7 +40,7 @@ footer-links:
|
|||||||
#weibo: frommidworld #请输入你的微博个性域名 https://www.weibo.com/<thispart>
|
#weibo: frommidworld #请输入你的微博个性域名 https://www.weibo.com/<thispart>
|
||||||
behance: # https://www.behance.net/<username>
|
behance: # https://www.behance.net/<username>
|
||||||
dribbble:
|
dribbble:
|
||||||
zhihu: ll-chen-2
|
zhihu: ning-meng-cheng-31-94
|
||||||
email: lemonchann@foxmail.com
|
email: lemonchann@foxmail.com
|
||||||
facebook:
|
facebook:
|
||||||
flickr:
|
flickr:
|
||||||
@@ -56,7 +56,7 @@ footer-links:
|
|||||||
youtube:
|
youtube:
|
||||||
|
|
||||||
# Text under the icons in footer
|
# Text under the icons in footer
|
||||||
footer-text: Copyright (c) 2019 lemonchann
|
footer-text: Copyright (c) 2019 lemon
|
||||||
|
|
||||||
# Enter your Disqus shortname (not your username) to enable commenting on posts
|
# Enter your Disqus shortname (not your username) to enable commenting on posts
|
||||||
# You can find your shortname on the Settings page of your Disqus account
|
# You can find your shortname on the Settings page of your Disqus account
|
||||||
@@ -70,7 +70,7 @@ gitalk:
|
|||||||
owner: lemonchann
|
owner: lemonchann
|
||||||
|
|
||||||
# Enter your Google Analytics web tracking code (e.g. UA-2110908-2) to activate tracking
|
# Enter your Google Analytics web tracking code (e.g. UA-2110908-2) to activate tracking
|
||||||
google_analytics: UA-152888548-1
|
#google_analytics:
|
||||||
|
|
||||||
# Your website URL (e.g. http://barryclark.github.io or http://www.barryclark.co)
|
# Your website URL (e.g. http://barryclark.github.io or http://www.barryclark.co)
|
||||||
# Used for Sitemap.xml and your RSS feed
|
# Used for Sitemap.xml and your RSS feed
|
||||||
|
|||||||
@@ -1,92 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "玩转vscode支持PlantUML绘制预览流程图"
|
|
||||||
date: 2018-10-12
|
|
||||||
tags: [vscode]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
软件设计过程中,有好几种图需要画,比如流程图、类图、组件图等,我知道大部分人画流程图一般都会用微软的viso绘制,我之前也是这个习惯,viso画图有个不好的地方是需要时刻去调整线条和边框已达到简洁美观,今天我给大家介绍一款程序员画图神器PlantUML,一款你用了就爱上的画图软件!
|
|
||||||
|
|
||||||
VsCode以插件的形式支持了这款画图神器,还不知道VsCode?
|
|
||||||
|
|
||||||
> VsCode 强大地自定义功能,已经成为程序员最爱编辑器。
|
|
||||||
> Microsoft在2015年4月30日Build 开发者大会上正式宣布了 Visual Studio Code 项目:一个运行于 Mac OS X、Windows和Linux之上的,针对于编写现代 Web 和云应用的跨平台源代码编辑器。
|
|
||||||
|
|
||||||
> 该编辑器也集成了所有一款现代编辑器所应该具备的特性,包括语法高亮(syntax high lighting),可定制的热键绑定(customizable keyboard bindings),括号匹配(bracket matching)以及代码片段收集(snippets)。Somasegar 也告诉笔者这款编辑器也拥有对 Git 的开箱即用的支持。引用[360百科](https://baike.so.com/doc/24428308-25261478.html)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 主角出场
|
|
||||||
|
|
||||||
### PlantUML
|
|
||||||
|
|
||||||
**PlantUML是一个开源项目,支持快速绘制:**
|
|
||||||
|
|
||||||
>时序图
|
|
||||||
用例图
|
|
||||||
类图
|
|
||||||
活动图 (旧版语法在此处)
|
|
||||||
组件图
|
|
||||||
状态图
|
|
||||||
对象图
|
|
||||||
部署图
|
|
||||||
定时图
|
|
||||||
|
|
||||||
**同时还支持以下非UML图:**
|
|
||||||
>线框图形界面
|
|
||||||
架构图
|
|
||||||
规范和描述语言 (SDL)
|
|
||||||
Ditaa diagram
|
|
||||||
甘特图
|
|
||||||
MindMap diagram
|
|
||||||
以 AsciiMath 或 JLaTeXMath 符号的数学公式
|
|
||||||
|
|
||||||
通过简单直观的语言来定义这些示意图,与MarkDown有相似的作用,这两种语言一个主要面向文本渲染一个主要用于图形绘制。
|
|
||||||
#### 语法
|
|
||||||
语法简单明了,查看以下[官方教程](http://plantuml.com/zh/sequence-diagram)
|
|
||||||
**我截取几个官网的事例图片在这里:**
|
|
||||||
|
|
||||||
- 活动图
|
|
||||||
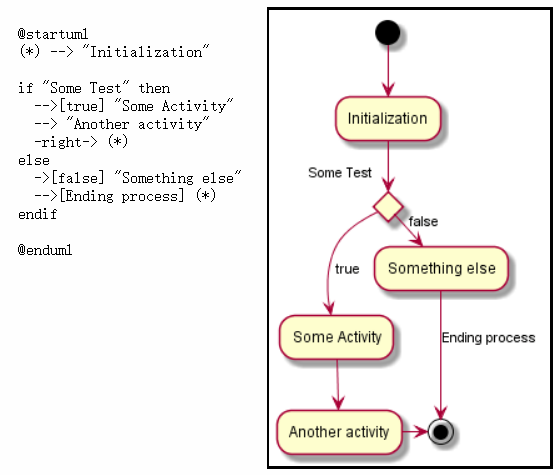
|
|
||||||
- 类图
|
|
||||||
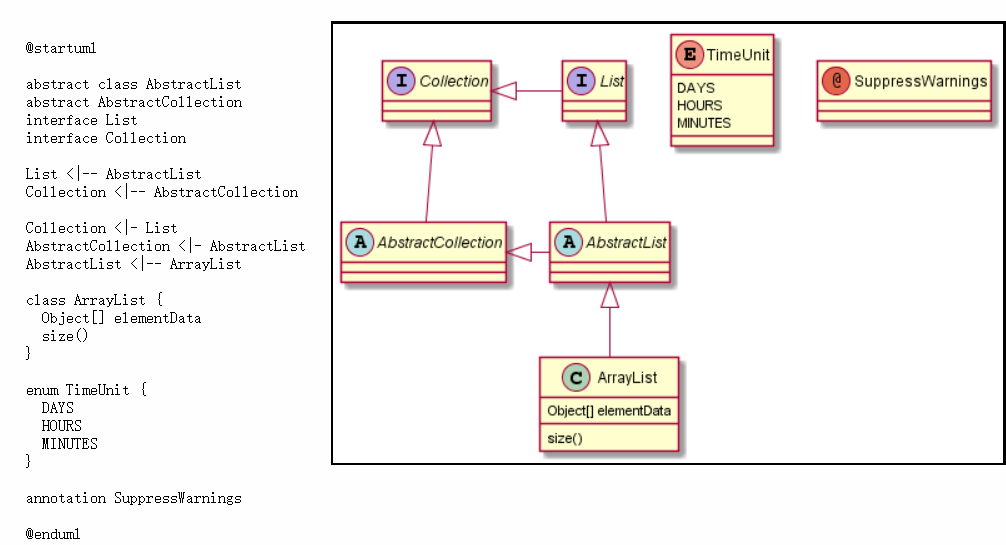
|
|
||||||
- 时序图
|
|
||||||
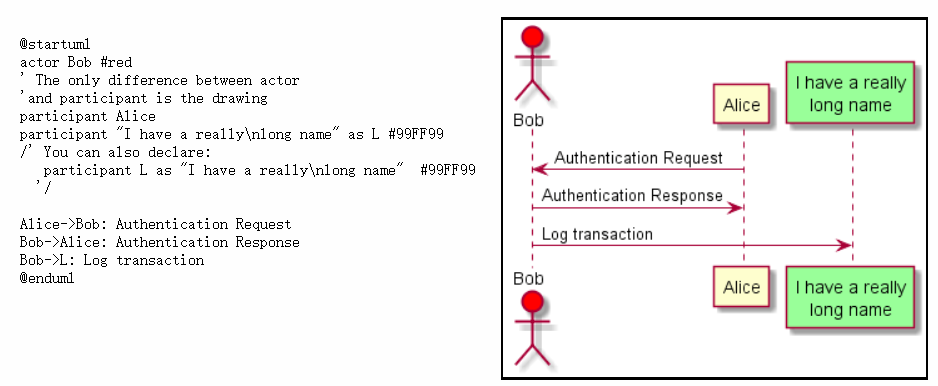
|
|
||||||
- 用例图
|
|
||||||
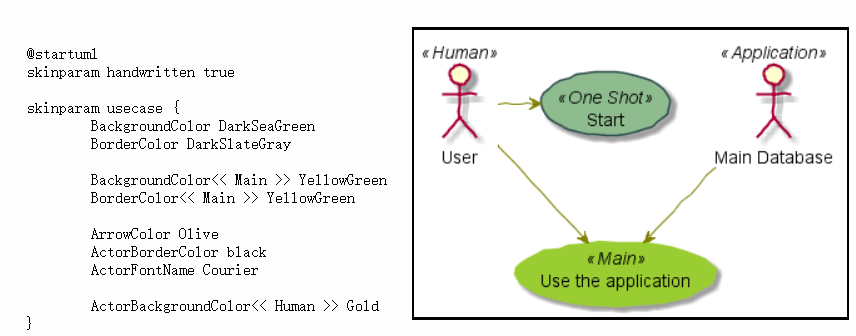
|
|
||||||
- 状态图
|
|
||||||
|
|
||||||
|
|
||||||
#### 图中的图片都是用源代码' '写'' 出来的哦!是不是很cool
|
|
||||||
|
|
||||||
|
|
||||||
### PlantUML遇上VsCode
|
|
||||||
#### 安装
|
|
||||||
- 安装graphviz-2.38.msi
|
|
||||||
- 安装2个vscode插件:
|
|
||||||
> PlantUML、Graphviz Preview
|
|
||||||
|
|
||||||
#### 例子
|
|
||||||
```plantUML
|
|
||||||
@startuml
|
|
||||||
Alice -> Bob: Authentication Request
|
|
||||||
Bob --> Alice: Authentication Response
|
|
||||||
|
|
||||||
Alice -> Bob: Another authentication Request
|
|
||||||
Alice <-- Bob: another authentication Response
|
|
||||||
@enduml
|
|
||||||
```
|
|
||||||
#### 预览
|
|
||||||
> Alt+D
|
|
||||||
|
|
||||||
#### 文件格式
|
|
||||||
> .wsd, .pu, .puml, .plantuml, .iuml
|
|
||||||
|
|
||||||
#### 如何导出
|
|
||||||
> F1/ctrl+shift+p; PlantUML:导出当前图表;选择导出格式png;导出即可。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 好了,这么好用工具赶紧用起来吧!
|
|
||||||
@@ -1,54 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "性能调优ulimit增加TCP连接最大限制"
|
|
||||||
date: 2018-11-1
|
|
||||||
tags: [linux]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
Linux系统中tcp连接数是有最大限制的,即是进程可打开的最大文件描述个数,通过命令`ulimit -n`查看
|
|
||||||
|
|
||||||
<!-- more -->
|
|
||||||
|
|
||||||
## TCP连接数限制
|
|
||||||
|
|
||||||
高负载的服务器通过修改ulimit参数达到合理规划用户使用资源和系统资源的目的。
|
|
||||||
|
|
||||||
## 用户级别
|
|
||||||
|
|
||||||
#### 修改最大连接数
|
|
||||||
- 修改系统参数实现
|
|
||||||
|
|
||||||
> ulimit -SHn 65535
|
|
||||||
|
|
||||||
> -H硬限制是实际的限制,-S软限制是warnning限制,只会做出warning.
|
|
||||||
如果运行ulimit命令修改的时候没有加上SH,就是两个参数一起改变.
|
|
||||||
|
|
||||||
- 修改pam模块配置实现
|
|
||||||
|
|
||||||
1. session required /lib/security/pam_limits.so
|
|
||||||
|
|
||||||
2. 修改/etc/security/limits.conf如下举例
|
|
||||||
|
|
||||||
`* soft nofile 65536`
|
|
||||||
`* hard nofile 65536`
|
|
||||||
`*代表所有用户,当然也可以指定用户如root`
|
|
||||||
|
|
||||||
#### 确认修改是否生效
|
|
||||||
项目中遇到修改后虽然命令查看已经是修改后的值,但是进程连接的tcp个数还是系统默认的1024导致接入拒绝
|
|
||||||
|
|
||||||
##### 查看进程实际的最大连接数
|
|
||||||
`cat /proc/进程pid/limits`
|
|
||||||
`Max open files 就是当前进程的实际值`
|
|
||||||
|
|
||||||
## 系统级别
|
|
||||||
查看总的系统打开文件限制
|
|
||||||
> cat /proc/sys/fs/file-max
|
|
||||||
|
|
||||||
若要修改可以在rc.local加
|
|
||||||
> echo 你要的 > /proc/sys/fs/file-max
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -1,121 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "Markdown 语法简明笔记"
|
|
||||||
date: 2018-6-21
|
|
||||||
tags: [markdown]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
toc: true
|
|
||||||
---
|
|
||||||
**Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式。markdown是为那些需要经常码字或者进行文字排版的、对码字手速和排版顺畅度有要求的人群设计的,他们希望用键盘把文字内容打出来后就已经排版好了,最好从头到尾都不要使用鼠标。这些人包括经常需要写文档的码农、博客写手、网站小编、出版业人士等等** 参考[**百度百科**](https://baike.baidu.com/item/markdown/3245829?fr=aladdin)
|
|
||||||
|
|
||||||
<!-- more -->
|
|
||||||
|
|
||||||
### markdown语法
|
|
||||||
开始学习markdown就有必要了解一下基本的语法,这里罗列一些基本的语法,这些语法是非常简单且常用的,能够帮助你快速掌握这门轻量的标记语言并且能够动手写自己的小博客,动手写起博客之后一些高级的用法可以边用边学。
|
|
||||||
|
|
||||||
- **标题样式**
|
|
||||||
在Markdown中,若一段文字被定义为标题,只要在这段文字前加 # 号即可。注意这里#号后面是有空格的。
|
|
||||||
>'# '一级标题, '## '二级标题, '### '三级标题
|
|
||||||
- **列表**
|
|
||||||
1. 无序列表使用`*`、+和-来做为列表的项目标记,这些符号是都可以使用的,注意符号与字符间**必须有一个空格**。
|
|
||||||
>* Candy.
|
|
||||||
>* Gum.
|
|
||||||
>* Booze.
|
|
||||||
>- Candy.
|
|
||||||
>- Gum.
|
|
||||||
>- Booze.
|
|
||||||
>+ Candy.
|
|
||||||
>+ Gum.
|
|
||||||
>+ Booze.
|
|
||||||
|
|
||||||
2. 有序的列表则是使用一般的数字接着一个英文句点作为项目标记:
|
|
||||||
>1. Red
|
|
||||||
>2. Green
|
|
||||||
>3. Blue
|
|
||||||
- **目录**
|
|
||||||
>用`[TOC]`生成目录
|
|
||||||
- **加粗** 用双*号
|
|
||||||
>`**xxx**` **xxx**
|
|
||||||
- **引用** 由'>'开头
|
|
||||||
>`>`
|
|
||||||
- **斜体**单*号
|
|
||||||
>`*x*` *x*
|
|
||||||
- **删除线** 双波浪线
|
|
||||||
>`~~xx~~` ~~xx~~
|
|
||||||
- **分割线** 另起一行输入三个连续*
|
|
||||||
>`***`
|
|
||||||
|
|
||||||
- **下划线** ++ 开头 ++结尾
|
|
||||||
>`++下划线++` ++下划线++
|
|
||||||
|
|
||||||
- **高亮标记** ==开头 ==结尾
|
|
||||||
>`==高亮标记==` ==高亮标记==
|
|
||||||
|
|
||||||
- **换行** 在末尾敲击两个以上空白,然后回车
|
|
||||||
|
|
||||||
- **插入链接**
|
|
||||||
>语法:`[链接说明](uri)`
|
|
||||||
|
|
||||||
- **插入图片**
|
|
||||||
>语法: `` 语法上和插入链接只是多了个! 插入图片的方法有很多种,csdn markdown提供插入图片功能,也可以注册各种图床(网上搜索说是七牛云最好用,没用过不发表)我这里说一种脑回路清奇的用GitHub当图床插入图片的方法。原链接参考[知乎](https://www.zhihu.com/question/21065229/answer/61070700?utm_medium=social&utm_source=wechat_session)
|
|
||||||
|
|
||||||
- **插入表情**
|
|
||||||
|
|
||||||
> :smile: :smile_cat:
|
|
||||||
|
|
||||||
### 以我的实践举个图片插入的栗子:
|
|
||||||
|
|
||||||
1. 将markdown需要用的图片放到git仓库中,发布到github上
|
|
||||||
2. 访问我的github仓库https://github.com/lemonchann/cloud_image
|
|
||||||
3. 访问图片cloud_image/Markdown语法简明笔记1.png
|
|
||||||
4. 点 download 按钮,在地址栏可以复制图片地址,或者在Download按钮上直接右键 "复制链接地址"
|
|
||||||
5. 拷贝链接地址https://raw.githubusercontent.com/lemonchann/cloud_image/master/Markdown%E8%AF%AD%E6%B3%95%E7%AE%80%E6%98%8E%E7%AC%94%E8%AE%B01.png
|
|
||||||
6. 在Markdown中引用图片
|
|
||||||
7. 这是这篇博客我在markdown编辑器里的编辑的内容
|
|
||||||
|
|
||||||

|
|
||||||
- **插入图片2**
|
|
||||||
> 图片还可以用相对路径的方法插入,必须和markdown文件相同目录下的文件或文件夹,但这种方法不适合写单篇的csdn或知乎文章,可以用于写书写个人博客。
|
|
||||||
> 语法示例:
|
|
||||||
> ` 或 `
|
|
||||||
|
|
||||||
- **程序员必备代码段** 以三个 ` 开头带程序类型和 ``` 结尾,中间包含代码段
|
|
||||||
```c++
|
|
||||||
#include<iostream>
|
|
||||||
using namespace std;
|
|
||||||
class test
|
|
||||||
{
|
|
||||||
int a;
|
|
||||||
string str;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
- **代码框** 用两个 ` 把代码框在中间就是代码段,也可以用于防止markdown语法生效(类似转义符)
|
|
||||||
|
|
||||||
>`it is code`
|
|
||||||
|
|
||||||
- **表格**
|
|
||||||
|
|
||||||
header 1 | header 2
|
|
||||||
---|---
|
|
||||||
row 1 col 1 | row 1 col 2
|
|
||||||
row 2 col 1 | row 2 col 2
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 编辑器推荐
|
|
||||||
|
|
||||||
推荐编辑器
|
|
||||||
|
|
||||||
- typora,谁用谁知道。
|
|
||||||
|
|
||||||
- vscode+markdown
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 参考文章
|
|
||||||
- [Markdown: Basics (快速入门)](http://wowubuntu.com/markdown/basic.html)
|
|
||||||
- [Markdown中插入图片有什么技巧?](https://www.zhihu.com/question/21065229/answer/61070700?utm_medium=social&utm_source=wechat_session)
|
|
||||||
|
|
||||||
- [【进阶版】有道云笔记Markdown指南](http://note.youdao.com/iyoudao/?p=2445)
|
|
||||||
- [【简明版】有道云笔记Markdown指南](http://note.youdao.com/iyoudao/?p=2411)it
|
|
||||||
@@ -1,104 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "新版本gitbook配置图书预览和生成"
|
|
||||||
date: 2019-11-18
|
|
||||||
tags: [tool]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
什么是Gitbook? 简单说就是可以把用md写的多个文档组织成**书**发布,md你可以放在github管理,配置gitbook关联github可以实现实时commit的预览生成。也可本地预览,甚至生成各种格式文档输出的强大工具。
|
|
||||||
|
|
||||||
<!-- more -->
|
|
||||||
|
|
||||||
## 安装Gitbook
|
|
||||||
* 安装nodejs可以去[官网](http://nodejs.cn/download/)下载对应版本 , Gitbook 只支持 node 6.x.x版本 。参考: https://www.jianshu.com/p/57b46db0564e
|
|
||||||
* 安装gitbook,打开win cmd输入npm install gitbook-cli -g
|
|
||||||
> 常用命令:
|
|
||||||
> **gitbook -V 查看版本**
|
|
||||||
> **gitbook serve 生成网页localhost:4000预览** - 命令输入要进到SUMMARY.md所在目录
|
|
||||||
> gitbook init //初始化目录文件
|
|
||||||
> gitbook help //列出gitbook所有的命令
|
|
||||||
> gitbook --help //输出gitbook-cli的帮助信息
|
|
||||||
> gitbook build //生成静态网页
|
|
||||||
> gitbook serve //生成静态网页并运行服务器
|
|
||||||
> gitbook build --gitbook=2.0.1 //生成时指定gitbook的版本, 本地没有会先下载
|
|
||||||
> gitbook ls //列出本地所有的gitbook版本
|
|
||||||
> gitbook ls-remote //列出远程可用的gitbook版本
|
|
||||||
> gitbook fetch 标签/版本号 //安装对应的gitbook版本
|
|
||||||
> gitbook update //更新到gitbook的最新版本
|
|
||||||
> gitbook uninstall 2.0.1 //卸载对应的gitbook版本
|
|
||||||
> gitbook build --log=debug //指定log的级别
|
|
||||||
> gitbook builid --debug //输出错误信息
|
|
||||||
|
|
||||||
## 用Gitbook转换markdown文件生成PDF
|
|
||||||
|
|
||||||
### 安装calibre
|
|
||||||
* 电子书生成下载依赖calibre否则会报错,建议先安装,[下载地址](https://calibre-ebook.com/download)
|
|
||||||
* 配置calibre环境变量,我的目录是C:\Program Files\Calibre2
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 生成PDF
|
|
||||||
|
|
||||||
打开win cmd命令行,到SUMMARY.md所在目录执行 **gitbook pdf 生成pdf**
|
|
||||||
> 转换PDF失败原因:
|
|
||||||
1. 没有安装calibre
|
|
||||||
2. 安装calibre之后需要设置环境变量C:\Program Files\Calibre2
|
|
||||||
3. [报错1](http://xcoding.tech/2018/08/08/hexo/%E5%A6%82%E4%BD%95%E4%BB%8E%E6%A0%B9%E6%9C%AC%E8%A7%A3%E5%86%B3hexo%E4%B8%8D%E5%85%BC%E5%AE%B9%7B%7B%7D%7D%E6%A0%87%E7%AD%BE%E9%97%AE%E9%A2%98/)
|
|
||||||
|
|
||||||
## Gitbook关联github
|
|
||||||
|
|
||||||
**Gitbook上同步github的配置界面已经发生了变化,新界面操作如下:**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 发布到github pages
|
|
||||||
#### 关于 GitHub Pages
|
|
||||||
>GitHub Pages 是一项静态站点托管服务,它直接从 GitHub 上的仓库获取 HTML、CSS 和 JavaScript 文件,(可选)通过构建过程运行文件,然后发布网站。 您可以在 GitHub Pages 示例集合中查看 GitHub Pages 站点的示例。
|
|
||||||
|
|
||||||
您可以在 GitHub 的 github.io 域或自己的自定义域上托管站点。 更多信息请参阅“对 GitHub Pages 使用自定义域”。
|
|
||||||
|
|
||||||
要开始使用,请参阅“创建 GitHub Pages 站点”。
|
|
||||||
|
|
||||||
#### GitHub Pages 站点的类型
|
|
||||||
有三种类型的 GitHub Pages 站点:项目、用户和组织。 项目站点连接到 GitHub 上托管的特定项目,例如 JavaScript 库或配方集合。 用户和组织站点连接到特定的 GitHub 帐户。
|
|
||||||
|
|
||||||
用户和组织站点始终从名为 <user>.github.io 或 <organization>.github.io 的仓库发布。 除非您使用自定义域,否则用户和组织站点位于 http(s)://<username>.github.io 或 http(s)://<organization>.github.io。
|
|
||||||
|
|
||||||
项目站点的源文件与其项目存储在同一个仓库中。 除非您使用自定义域,否则项目站点位于 http(s)://<user>.github.io/<repository> 或 http(s)://<organization>.github.io/<repository>。
|
|
||||||
[更多](https://help.github.com/cn/github/working-with-github-pages/about-github-pages)
|
|
||||||
|
|
||||||
#### [这里](http://www.chengweiyang.cn/gitbook/github-pages/README.html)也包含推送到**github.page**的方法
|
|
||||||
- master, 保存书籍的源码
|
|
||||||
- gh-pages, 保存书籍编译后的 HTML 文件
|
|
||||||
|
|
||||||
**步骤:**
|
|
||||||
|
|
||||||
- `gitbook build` 将书籍内容输出到默认目录,也就是当前目录下的 _book 目录
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
- 创建gh-pages分支,并且删除不需要的文件,仅保留git目录和 _book目录
|
|
||||||
> $ git checkout --orphan gh-pages
|
|
||||||
$ git rm --cached -r .
|
|
||||||
$ git clean -df
|
|
||||||
$ rm -rf *~`
|
|
||||||
- 然后,加入 _book 下的内容到分支中:
|
|
||||||
> $ cp -r _book/* .
|
|
||||||
$ git add .
|
|
||||||
$ git commit -m "Publish book"
|
|
||||||
- 将编译好的书籍内容上传到 GitHub 项目的 远程gh-pages 分支了
|
|
||||||
> $git push -u origin gh-pages
|
|
||||||
|
|
||||||
|
|
||||||
### 参考
|
|
||||||
[详细教程](https://jackchan1999.github.io/2017/05/01/gitbook/GitBook%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B/)
|
|
||||||
[官方指引-integrations-Github](https://docs.gitbook.com/integrations/github)
|
|
||||||
[Github的GitBook项目](https://github.com/GitbookIO/gitbook/blob/master/docs/setup.md)
|
|
||||||
[github pages中文帮助](https://help.github.com/cn/github/working-with-github-pages/about-github-pages)
|
|
||||||
@@ -7,16 +7,22 @@ comments: true
|
|||||||
author: lemonchann
|
author: lemonchann
|
||||||
---
|
---
|
||||||
|
|
||||||
作为一个程序员怎么能没有自己的个人博客呢,这里详细记录和分享我的博客搭建经验,让你轻轻松松拥有自己的博客网站。 傻瓜式一站式教你用github pages 来搭建博客,详细记录全过程。
|
作为一个程序员怎么能没有自己的个人博客呢,这里详细记录和分享我的博客搭建经验,让你轻轻松松拥有自己的博客网站。傻瓜式一站式教你用 github pages 来搭建博客,详细记录全过程,保证你能学会。
|
||||||
|
|
||||||
|
如果你是非程序员或者不关系技术细节,只需花 3 分钟阅读前面 5 个章节内容,就能轻松拥有自己的博客。
|
||||||
|
|
||||||
<!-- more -->
|
<!-- more -->
|
||||||
|
|
||||||
## 开始
|
## 开始
|
||||||
|
|
||||||
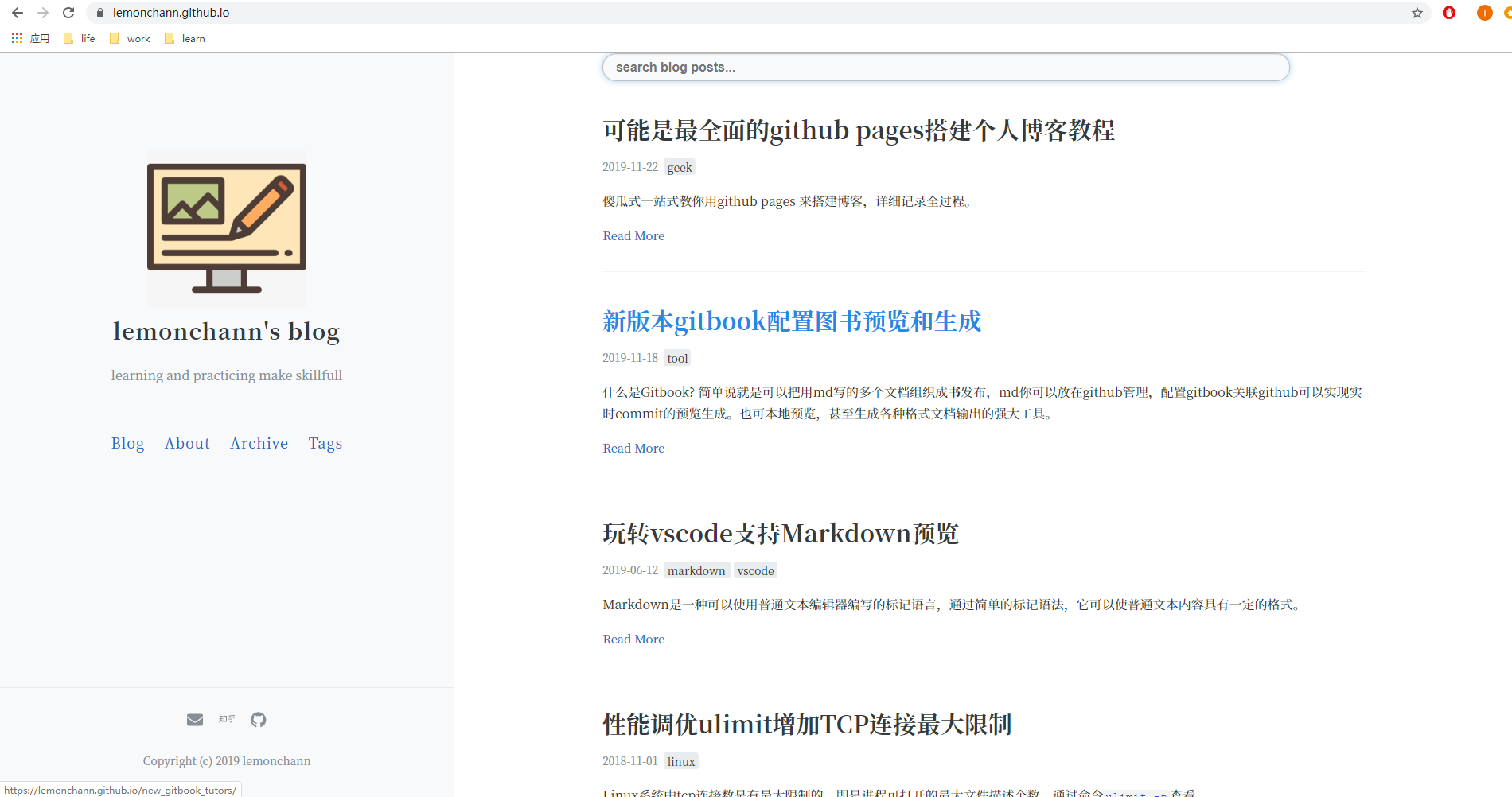
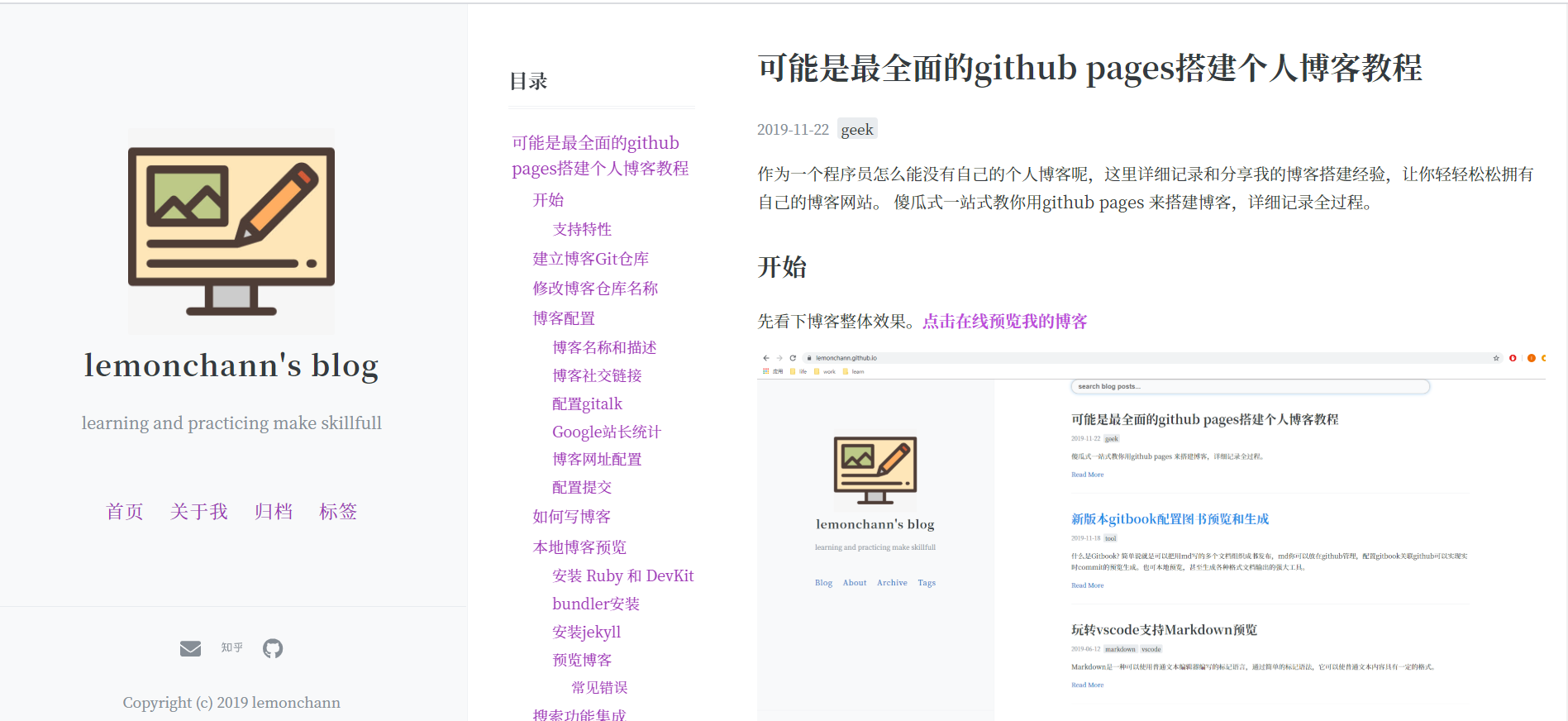
先看下博客整体效果。[**点击在线预览我的博客**]( https://lemonchann.github.io/ )
|
话不多说,直接上图先来看下我的博客整体效果。[**点击在线预览我的博客**]( https://lemonchann.github.io/blog/),个人比较喜欢这种简约的博客风格,不要花里胡哨但该有的功也都有。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
下面列举这个博客具有的功能特性,其中我比较看重归档和搜索能力。
|
||||||
|
|
||||||
### 支持特性
|
### 支持特性
|
||||||
|
|
||||||
- 简约风格博客
|
- 简约风格博客
|
||||||
@@ -39,25 +45,31 @@ author: lemonchann
|
|||||||
|
|
||||||
- 支持归档与标签
|
- 支持归档与标签
|
||||||
|
|
||||||
|
- 支持改变主题颜色
|
||||||
|
|
||||||
|
- 支持添加文章目录
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 建立博客Git仓库
|
## 建立博客Git仓库
|
||||||
|
|
||||||
首先你要在[github](https://github.com/)上有自己博客仓库,用来生成和存放博客文章。你可以直接fork我的博客仓库。这样你马上有了自己的博客仓库。
|
首先你要在[github](https://github.com/)上有自己博客仓库,用来生成和存放博客文章。你可以直接fork我的博客仓库。这样你马上有了自己的博客仓库。
|
||||||
|
|
||||||
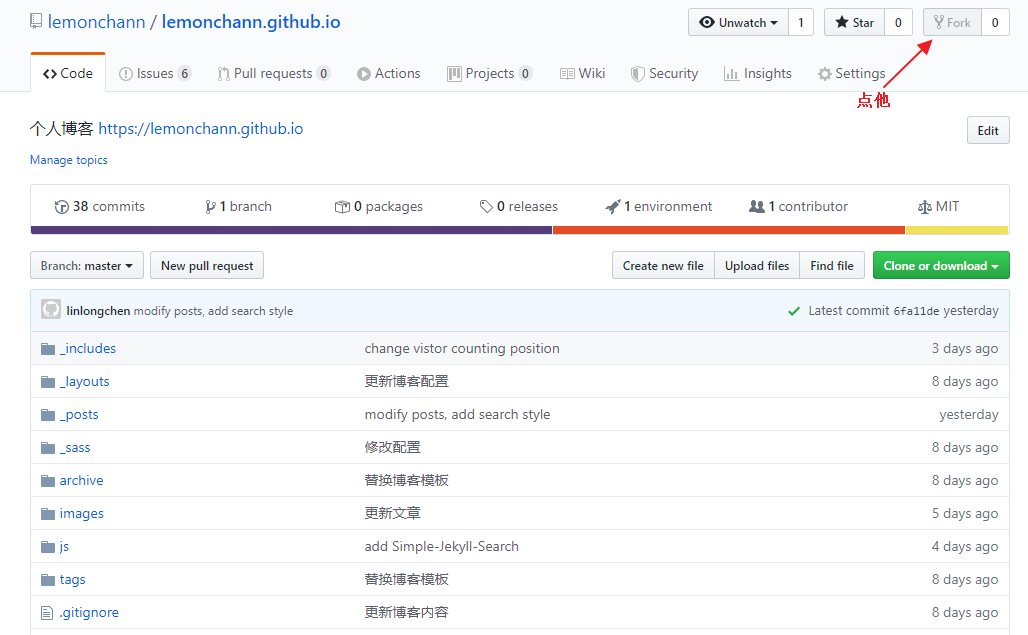
[点这里我的博客地址](https://github.com/lemonchann/lemonchann.github.io)进去fork,之后在你自己的仓库下会看到刚复制的仓库。以后的操作都在你自己的仓库进行。
|
[点这里我的博客地址](https://github.com/lemonchann/lemonchann.github.io)进去点击 fork,之后在你自己的仓库下会看到刚复制的仓库,以后的操作都在你自己的仓库进行,当然想感谢我写这个教程就帮我点个 start 吧!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
**版权声明: fork之后_posts文件夹内容是我的博客文章,版权归我所有。你可以选择删除里面的文章替换上自己的或者转载附上链接注明出处。 **
|
**版权声明: fork之后_posts文件夹内容是我的博客文章,版权归我所有。你可以选择删除里面的文章替换上自己的博客文章,如需转载需要与我联系授权 **。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 修改博客仓库名称
|
## 修改博客仓库名称
|
||||||
|
|
||||||
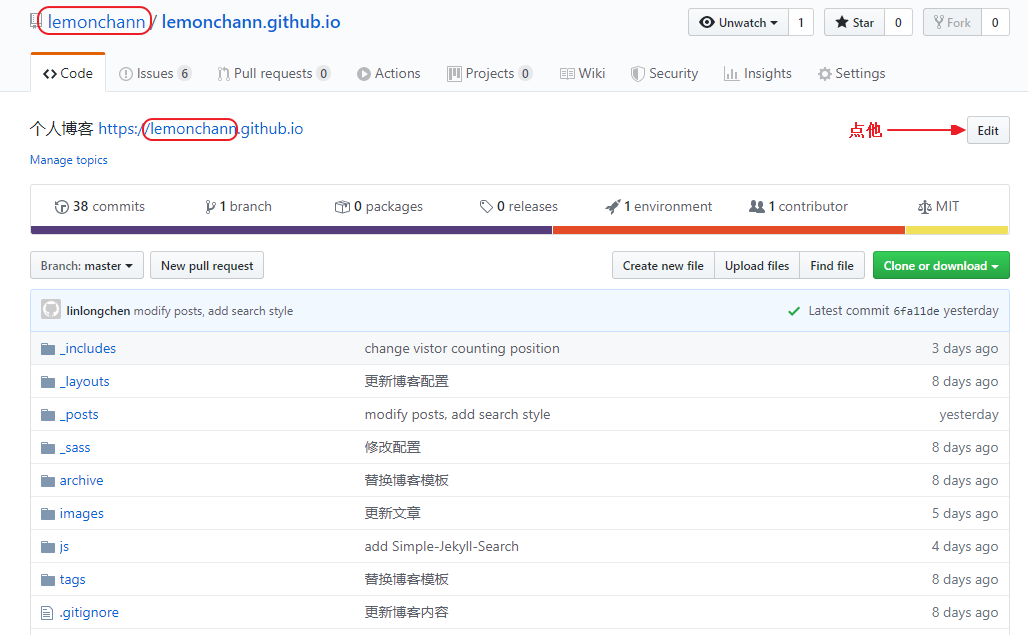
进到你自己的博客仓库,修改博客仓库名称成你自己的用户名。github page解析的时候找的是这个 username.github.io的仓库名。
|
进到你自己的博客仓库,**修改博客仓库名称成你自己的用户名**。因为 github page 解析的时候找的是这个 username.github.io的仓库名,**这一步非常重要**。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
此时,不出意外的话,打开域名https://username.github.io 就能看到你刚搭建的博客了。*注意替换username成你自己的github用户名*。
|
此时,不出意外的话,打开域名 https://username.github.io 就能看到你刚搭建的博客了。*注意替换 username成你自己的github 用户名*。
|
||||||
|
|
||||||
## 博客配置
|
## 博客配置
|
||||||
|
|
||||||
@@ -134,6 +146,8 @@ url: https://yourname.github.io
|
|||||||
|
|
||||||
**done! 现在输入上面提到的博客地址,回车,你拥有了自己的博客。**
|
**done! 现在输入上面提到的博客地址,回车,你拥有了自己的博客。**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 如何写博客
|
## 如何写博客
|
||||||
|
|
||||||
好了,博客有了。如何更新文章呢?
|
好了,博客有了。如何更新文章呢?
|
||||||
@@ -142,7 +156,13 @@ url: https://yourname.github.io
|
|||||||
|
|
||||||
关于文章的**命名格式**:博客文章必须按照统一的命名格式 `yyyy-mm-dd-blogName.md` 比如我这篇博客的名字是`2019-11-22-create_blog_with_github_pages.md`
|
关于文章的**命名格式**:博客文章必须按照统一的命名格式 `yyyy-mm-dd-blogName.md` 比如我这篇博客的名字是`2019-11-22-create_blog_with_github_pages.md`
|
||||||
|
|
||||||
**看到这里,如果只是简单的想写博客,后面的不看也可以了,后面章节是记录一些DIY的过程。**
|
**看到这里,如果只是简单的想写博客,后面的不看也可以了,你已经拥有了自己的博客!后面章节是记录一些DIY的过程。**
|
||||||
|
|
||||||
|
另外,发现最近用我这个模板的同学越来越多,如果搭建过程中有什么问题,可以在我的公众号「后端技术学堂」讨论交流。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 本地博客预览
|
## 本地博客预览
|
||||||
|
|
||||||
@@ -343,6 +363,20 @@ footer-links:
|
|||||||
|
|
||||||
eg. `style="font-family:arial;color:Gainsboro;font-size:10px; text-align:right;width:200px;background-color:gray;`
|
eg. `style="font-family:arial;color:Gainsboro;font-size:10px; text-align:right;width:200px;background-color:gray;`
|
||||||
|
|
||||||
|
## 修改博客主题颜色
|
||||||
|
|
||||||
|
博客使用开源的颜色表[Open Color](https://yeun.github.io/open-color/),博客主题的可选颜色有:
|
||||||
|
|
||||||
|
`red, pink, grape, violet, indigo, blue, cyan, teal, green, lime, yellow`
|
||||||
|
|
||||||
|
修改文件`_sass/_variables.scss`,将文件中当前颜色,比如当前是 `grape` 全部替换成你想要的颜色即可。
|
||||||
|
|
||||||
|
## 显示文章目录
|
||||||
|
|
||||||
|
在文章开头信息中心增加 `toc: true` 描述即可打开文章目录显示。效果如下:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 如何传图片
|
## 如何传图片
|
||||||
@@ -359,6 +393,8 @@ PicGo支持图片上传github、SM.MS图床、阿里云、腾讯云等主流图
|
|||||||
|
|
||||||
[好用的github插件](https://blog.csdn.net/u012702547/article/details/100533763)
|
[好用的github插件](https://blog.csdn.net/u012702547/article/details/100533763)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 网站结构
|
## 网站结构
|
||||||
|
|
||||||
根目录的index.html生成blog首页
|
根目录的index.html生成blog首页
|
||||||
@@ -367,8 +403,14 @@ _include/footer.html生成侧边栏
|
|||||||
|
|
||||||
_include/svg-icons.html生成社交头像的链接
|
_include/svg-icons.html生成社交头像的链接
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 致谢
|
## 致谢
|
||||||
|
|
||||||
感谢Jekyll提供的技术支持才能有这个博客。
|
感谢 [Jekyll](https://www.jekyll.com.cn/) 提供的技术支持才能有这个博客。
|
||||||
|
|
||||||
感谢[LOFFER](https://fromendworld.github.io/LOFFER/document/)提供的原始模板,我在其上进行的二次开发。
|
感谢 [LOFFER ](https://fromendworld.github.io/LOFFER/document/)提供的原始模板,我在其上进行的二次开发。
|
||||||
|
|
||||||
|
**我的个人技术公众号「后端技术学堂」分享、记录、成长,扫码添加,一起学习,共同成长。**
|
||||||
|
|
||||||
|

|
||||||
@@ -1,984 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "腾讯后台开发面试笔试C++知识点参考笔记"
|
|
||||||
date: 2019-12-29
|
|
||||||
tags: [c++]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
**文章是由我笔试面试腾讯笔记整理而来,主要是针对面试的C++后台开发岗位,涵盖了大部分C++后台开发相关的,可能会考察和被问到的技术点。**
|
|
||||||
|
|
||||||
**自认为这篇笔记比较全面的涵盖了,后台开发C++笔试面试大部分知识点,不管你是已经工作准备参加社招,还是在校学生准备参加校招,笔记都可以作为技术面试准备阶段参考查阅,查缺补漏。**
|
|
||||||
|
|
||||||
笔记是基础C++知识点总结,没有过多的阐述后台开发的系统架构,和分布式后台服务设计相关内容,以及C++11新特性,这些在笔试面试也会被问到但不在这篇讨论范围,可以关注我后面有机会补上。
|
|
||||||
|
|
||||||
### 阅读提示
|
|
||||||
|
|
||||||
文章约12839字,阅读时长预计33分钟。建议关注收藏方便回头查阅。
|
|
||||||
|
|
||||||
### gdb调试命令
|
|
||||||
|
|
||||||
#### step和next的区别?
|
|
||||||
|
|
||||||
当前line有函数调用的时候,next会直接执行到下一句 ,step会进入函数.
|
|
||||||
|
|
||||||
#### 查看内存
|
|
||||||
|
|
||||||
> (gdb)p &a //打印变量地址
|
|
||||||
|
|
||||||
> (gdb)x 0xbffff543 //查看内存单元内变量
|
|
||||||
|
|
||||||
> 0xbffff543: 0x12345678
|
|
||||||
|
|
||||||
> (gdb) x /4xb 0xbffff543 //单字节查看4个内存单元变量的值
|
|
||||||
|
|
||||||
> 0xbffff543: 0x78 0x56 0x34 0x12
|
|
||||||
|
|
||||||
#### 多线程调试
|
|
||||||
|
|
||||||
> (gdb) info threads:查看GDB当前调试的程序的各个线程的相关信息
|
|
||||||
|
|
||||||
> (gdb) thread threadno:切换当前线程到由threadno指定的线程
|
|
||||||
|
|
||||||
> break filename:linenum thread all 在所有线程相应行设置断点,注意如果主线程不会执行到该行,并且启动all-stop模式,主线程执行n或s会切换过去
|
|
||||||
|
|
||||||
> set scheduler-locking off|on\step 默认off,执行s或c其它线程也同步执行。on,只有当前相称执行。step,只有当前线程执行
|
|
||||||
|
|
||||||
> show scheduler-locking 显示当前模式
|
|
||||||
|
|
||||||
> thread apply all command 每个线程执行同意命令,如bt。或者thread apply 1 3 bt,即线程1,3执行bt。
|
|
||||||
|
|
||||||
#### 查看调用堆栈
|
|
||||||
|
|
||||||
> (gdb)bt
|
|
||||||
|
|
||||||
> (gdb)f 1 //帧简略信息
|
|
||||||
|
|
||||||
> (gdb)info f 1 //帧详细信息
|
|
||||||
|
|
||||||
#### 断点
|
|
||||||
|
|
||||||
> b test.cpp:11
|
|
||||||
|
|
||||||
> b test.cpp:main
|
|
||||||
|
|
||||||
gdb attach 调试方法:
|
|
||||||
|
|
||||||
> gdb->file xxxx->attach pid->**这时候进程是停止的**->c 继续运行
|
|
||||||
|
|
||||||
#### 带参数调试
|
|
||||||
|
|
||||||
输入参数命令set args 后面加上程序所要用的参数,注意,不再带有程序名,直接加参数,如:
|
|
||||||
|
|
||||||
> (gdb)set args -l a -C abc
|
|
||||||
|
|
||||||
#### list命令
|
|
||||||
|
|
||||||
> list linenum //显示程序第linenum行的周围的程序
|
|
||||||
|
|
||||||
> list function //显示程序名为function的函数的源程序
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### static关键字的作用
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 软硬链接
|
|
||||||
|
|
||||||
ln -s 源文件 目标文件, ln -s / /home/good/linkname链接根目录/到/home/good/linkname
|
|
||||||
|
|
||||||
1. 软链接就是:“ln –s 源文件 目标文件”,只会在选定的位置上生成一个文件的镜像,不会占用磁盘空间,类似与windows的快捷方式。
|
|
||||||
|
|
||||||
2. 硬链接ln源文件目标文件,没有参数-s, 会在选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 函数指针
|
|
||||||
|
|
||||||
int (*func)(int, int) //函数指针
|
|
||||||
|
|
||||||
int (*funcArry[10])(int, int) //函数指针数组
|
|
||||||
|
|
||||||
const int* p; //指向const int的指针
|
|
||||||
|
|
||||||
int const* p; //同上
|
|
||||||
|
|
||||||
int* const p; //const指针
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 设计模式
|
|
||||||
|
|
||||||
[单例模式](http://blog.csdn.net/wuzhekai1985/article/details/6665869)
|
|
||||||
|
|
||||||
[观察者模式(也叫发布订阅模式](http://blog.csdn.net/wuzhekai1985/article/details/6674984))
|
|
||||||
|
|
||||||
[工厂模式](http://blog.csdn.net/wuzhekai1985/article/details/6660462) 三种:简单工厂模式、工厂方法模式、抽象工厂模式
|
|
||||||
|
|
||||||
为什么要用工厂模式?原因就是对上层的使用者隔离对象创建的过程;或者是对象创建的过程复杂,
|
|
||||||
|
|
||||||
使用者不容易掌握;或者是对象创建要满足某种条件,这些条件是业务的需求也好,是系统约束也好
|
|
||||||
|
|
||||||
,没有必要让上层使用者掌握,增加别人开发的难度。所以,到这时我们应该清楚了,无论是工厂模式,
|
|
||||||
|
|
||||||
还是上面的战友说的开闭原则,都是为了隔离一些复杂的过程,使得这些复杂的过程不向外暴露,
|
|
||||||
|
|
||||||
如果暴露了这些过程,会对使用者增加麻烦,这也就是所谓的团队合作。
|
|
||||||
|
|
||||||
### 数据结构
|
|
||||||
|
|
||||||
#### [各种排序算法](http://blog.csdn.net/daguairen/article/details/52611874)
|
|
||||||
|
|
||||||
#### [堆排序](https://www.cnblogs.com/0zcl/p/6737944.html)
|
|
||||||
|
|
||||||
关键:1.初始建堆从最后一个非叶节点开始调整 2.筛选从顶点开始往下调整
|
|
||||||
|
|
||||||
#### [通俗易懂的快排]( http://blog.csdn.net/vayne_xiao/article/details/53508973)
|
|
||||||
|
|
||||||
#### 二叉树定理
|
|
||||||
|
|
||||||
度为2节点数 = 叶子节点数 - 1
|
|
||||||
|
|
||||||
证明:树枝数=节点数-1, n0*0 +n1*1 +n2*2 = n0+n1+n2-1 (n0代表度为0的节点数,以此类推)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 互斥锁
|
|
||||||
|
|
||||||
```c
|
|
||||||
pthread_mutex_t m_mutex;
|
|
||||||
pthread_mutex_init(&m_mutex, NULL)等效于pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
|
|
||||||
pthread_mutex_lock(&m_mutex);
|
|
||||||
pthread_mutex_unlock(&m_mutex)
|
|
||||||
pthread_mutex_destroy(&m_mutex)
|
|
||||||
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
|
|
||||||
bool g_flag = false;
|
|
||||||
void* t1(void* arg)
|
|
||||||
{
|
|
||||||
cout << "create t1 thread success" << endl;
|
|
||||||
pthread_mutex_lock(&m_mutex);
|
|
||||||
g_flag = true;
|
|
||||||
pthread_mutex_unlock(&m_mutex);
|
|
||||||
}
|
|
||||||
|
|
||||||
void* t2(void* arg)
|
|
||||||
{
|
|
||||||
cout << "create t2 thread success" << endl;
|
|
||||||
pthread_mutex_lock(&m_mutex);
|
|
||||||
g_flag = false;
|
|
||||||
pthread_mutex_unlock(&m_mutex);
|
|
||||||
}
|
|
||||||
|
|
||||||
int main(int argc, char* argv[])
|
|
||||||
{
|
|
||||||
pthread_t tid1, tid2;
|
|
||||||
pthread_create(&tid1, NULL, t1, NULL);
|
|
||||||
sleep(2);
|
|
||||||
pthread_create(&tid2, NULL, t2, NULL);
|
|
||||||
pthread_join(tid1, NULL);
|
|
||||||
pthread_join(tid2, NULL);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 大小端转换
|
|
||||||
|
|
||||||
```c
|
|
||||||
#define BigLittleSwap32(A) ((((uint32)(A) & 0xff000000) >> 24) | \
|
|
||||||
(((uint32)(A) & 0x00ff0000) >> 8) | \
|
|
||||||
(((uint32)(A) & 0x0000ff00) << 8) | \
|
|
||||||
(((uint32)(A) & 0x000000ff) << 24))
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### io多路复用
|
|
||||||
|
|
||||||
[为什么 IO 多路复用要搭配非阻塞IO]( https://www.zhihu.com/question/37271342)
|
|
||||||
|
|
||||||
设置非阻塞 `io fcntl(sockfd, F_SETFL, O_NONBLOCK); `
|
|
||||||
|
|
||||||
#### select
|
|
||||||
|
|
||||||
```c
|
|
||||||
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
|
|
||||||
|
|
||||||
void FD_CLR(int fd, fd_set *set);
|
|
||||||
|
|
||||||
int FD_ISSET(int fd, fd_set *set);
|
|
||||||
|
|
||||||
void FD_SET(int fd, fd_set *set);
|
|
||||||
|
|
||||||
void FD_ZERO(fd_set *set);
|
|
||||||
|
|
||||||
fd_set rdfds;
|
|
||||||
struct timeval tv;
|
|
||||||
int ret;
|
|
||||||
FD_ZERO(&rdfds);
|
|
||||||
FD_SET(socket, &rdfds);
|
|
||||||
tv.tv_sec = 1;
|
|
||||||
tv.tv_uses = 500;
|
|
||||||
ret = select (socket + 1, %rdfds, NULL, NULL, &tv);
|
|
||||||
if(ret < 0) perror (“select”);
|
|
||||||
else if (ret = = 0) printf(“time out”);
|
|
||||||
else
|
|
||||||
{
|
|
||||||
printf(“ret = %d/n”,ret);
|
|
||||||
if(FD_ISSET(socket, &rdfds)){
|
|
||||||
/* 读取socket句柄里的数据 */
|
|
||||||
}注意select函数的第一个参数,是所有加入集合的句柄值的最大那个那个值还要加1.比如我们创建了3个句柄;
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### poll实现
|
|
||||||
|
|
||||||
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
|
|
||||||
|
|
||||||
#### epoll原理
|
|
||||||
|
|
||||||
https://www.cnblogs.com/Anker/archive/2013/08/17/3263780.html
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <sys/epoll.h>
|
|
||||||
int epoll_create(int size);
|
|
||||||
|
|
||||||
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
|
|
||||||
|
|
||||||
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
|
|
||||||
```
|
|
||||||
|
|
||||||
**epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:**
|
|
||||||
|
|
||||||
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
|
|
||||||
|
|
||||||
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
|
|
||||||
|
|
||||||
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,
|
|
||||||
|
|
||||||
必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
|
|
||||||
|
|
||||||
Epoll ET模型下,为什么每次EPOLLIN事件都会带一次EPOLLOUT事件: https://bbs.csdn.net/topics/390630226
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### udp套接字
|
|
||||||
|
|
||||||
[ref1](http://blog.csdn.net/chenhanzhun/article/details/41914029)
|
|
||||||
|
|
||||||
[ref1](https://www.cnblogs.com/bleopard/p/4004916.html)
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <sys/socket.h>
|
|
||||||
|
|
||||||
ssize_t sendto(int sockfd, void *buff, size_t nbytes, int flags, const struct sockaddr *destaddr, socklen_t addrlen);
|
|
||||||
|
|
||||||
ssize_t recvfrom(int sockfd, void *buff, size_t nbytes, int flags, struct sockaddr *addr, socklen_t *addrlen);
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 网络套接字
|
|
||||||
|
|
||||||
#### udp原理与套接字
|
|
||||||
|
|
||||||
udp服务端:
|
|
||||||
|
|
||||||
```c
|
|
||||||
sockListener=socket(AF_INET,SOCK_DGRAM,0)
|
|
||||||
|
|
||||||
bind(sockListener,(struct sockaddr*)&addrListener,sizeof(addrListener))
|
|
||||||
|
|
||||||
nMsgLen=recvfrom(sockListener,szBuf,1024,0,(struct sockaddr*)&addrClient,&addrLen)
|
|
||||||
```
|
|
||||||
|
|
||||||
udp客户端
|
|
||||||
|
|
||||||
```c
|
|
||||||
sockClient=socket(AF_INET,SOCK_DGRAM,0);
|
|
||||||
bind(sockClient,(struct sockaddr*)&addrLocal,sizeof(addrLocal))
|
|
||||||
FD_ZERO(&setHold);
|
|
||||||
FD_SET(STDIN_FILENO,&setHold);
|
|
||||||
FD_SET(sockClient,&setHold);
|
|
||||||
cout<<"you can type in sentences any time"<<endl;
|
|
||||||
while(true)
|
|
||||||
{
|
|
||||||
setTest=setHold;
|
|
||||||
nReady=select(sockClient+1,&setTest,NULL,NULL,NULL);
|
|
||||||
if(FD_ISSET(0,&setTest))
|
|
||||||
{
|
|
||||||
nMsgLen=read(0,szMsg,1024);
|
|
||||||
write(sockClient,szMsg,nMsgLen);
|
|
||||||
}
|
|
||||||
if(FD_ISSET(sockClient,&setTest))
|
|
||||||
{
|
|
||||||
nMsgLen=read(sockClient,szRecv,1024);
|
|
||||||
szRecv[nMsgLen]='\0';
|
|
||||||
cout<<"read:"<<szRecv<<endl;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**UDP中使用 connect 函数成为已连接的套接字**
|
|
||||||
|
|
||||||
已连接 UDP 套接字 相对于 未连接 UDP 套接字 会有以下的变化:
|
|
||||||
|
|
||||||
1. 不能给输出操作指定目的 IP 地址和端口号(因为调用 connect 函数时已经指定),即不能使用 sendto 函数,而是使用 write 或 send 函数。写到已连接 UDP 套接字上的内容都会自动发送到由 connect 指定的协议地址;
|
|
||||||
|
|
||||||
2. 不必使用 recvfrom 函数以获悉数据报的发送者,而改用 read、recv 或 recvmsg 函数。在一个已连接 UDP 套接字上,由内核为输入操作返回的数据报只有那些来自 connect 函数所指定的协议地址的数据报。目的地为这个已连接 UDP 套接字的本地协议地址,发源地不是该套接字早先 connect 到的协议地址的数据报,不会投递到该套接字。即只有发源地的协议地址与 connect 所指定的地址相匹配才可以把数据报传输到该套接字。这样已连接 UDP 套接字只能与一个对端交换数据报;
|
|
||||||
|
|
||||||
3. 由已连接 UDP 套接字引发的异步错误会返回给它们所在的进程,而未连接 UDP 套接字不会接收任何异步错误;
|
|
||||||
|
|
||||||
#### [tcp套接字](http://blog.csdn.net/fly_yr/article/details/50387065)
|
|
||||||
|
|
||||||
服务端:
|
|
||||||
|
|
||||||
```c
|
|
||||||
listenfd = socket(AF_INET , SOCK_STREAM , 0)
|
|
||||||
|
|
||||||
bind(listenfd , (struct sockaddr*)&servaddr , sizeof(servaddr))
|
|
||||||
|
|
||||||
listen(listenfd , LISTENQ)
|
|
||||||
|
|
||||||
connfd = accept(listenfd , (struct sockaddr *)&cliaddr , &clilen))
|
|
||||||
|
|
||||||
n = read(connfd , buff , MAX_LINE)
|
|
||||||
|
|
||||||
write(connfd , buff , n)
|
|
||||||
```
|
|
||||||
|
|
||||||
客户端:
|
|
||||||
|
|
||||||
```c
|
|
||||||
sockfd = socket(AF_INET , SOCK_STREAM , 0)
|
|
||||||
|
|
||||||
connect(sockfd , (struct sockaddr *)&servaddr , sizeof(servaddr))
|
|
||||||
|
|
||||||
write(sockfd , sendline , strlen(sendline))
|
|
||||||
```
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### IP分片与重组
|
|
||||||
|
|
||||||
[参考1](blog.csdn.net/snowsnowsnow1991/article/details/52511280)
|
|
||||||
|
|
||||||
[参考2](https://www.cnblogs.com/glacierh/p/3653442.html)
|
|
||||||
|
|
||||||
MTU是1500是指的以太网的MTU,可以用 netstat -i 命令查看这个值。如果IP层有数据包要传,而且数据包的长度超过了MTU,
|
|
||||||
|
|
||||||
那么IP层就要对数据包进行分片(fragmentation)操作,使每一片的长度都小于或等于MTU。
|
|
||||||
|
|
||||||
我们假设要传输一个UDP数据包,以太网的MTU为1500字节,一般IP首部为20字节,UDP首部为8字节,数据的净荷(payload)
|
|
||||||
|
|
||||||
部分预留是1500-20-8=1472字节。如果数据部分大于1472字节,就会出现分片现象,
|
|
||||||
|
|
||||||
偏移量的单位为8Byte
|
|
||||||
|
|
||||||
以ID标示是不是同一个分片,以偏移量标示在保文里的位置,每个不完整的ID报文有一个等待计时器,到时丢弃IP层不保证能够送达,
|
|
||||||
|
|
||||||
如果丢了上层自己处理参考rfc 791
|
|
||||||
|
|
||||||
IP报文长度单位口诀
|
|
||||||
|
|
||||||
> 4字节单位- 首部长度单位 1字节单位-总长度单位 8字节单位-片偏移单位
|
|
||||||
|
|
||||||
### STL容器
|
|
||||||
|
|
||||||
#### vector与list
|
|
||||||
|
|
||||||
1.vector数据结构
|
|
||||||
|
|
||||||
vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。
|
|
||||||
|
|
||||||
因此能高效的进行随机存取,时间复杂度为o(1);
|
|
||||||
|
|
||||||
但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。
|
|
||||||
|
|
||||||
另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。
|
|
||||||
|
|
||||||
2.list数据结构
|
|
||||||
|
|
||||||
list是由双向链表实现的,因此内存空间是不连续的。
|
|
||||||
|
|
||||||
只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);
|
|
||||||
|
|
||||||
但由于链表的特点,能高效地进行插入和删除。
|
|
||||||
|
|
||||||
#### [Vector动态内存分配]( https://blog.csdn.net/xnmc2014/article/details/86748138)
|
|
||||||
|
|
||||||
这个问题其实很简单,在调用push_back时,若当前容量已经不能够放入心得元素(capacity=size),那么vector会重新申请一块内存,把之前的内存里的元素拷贝到新的内存当中,然后把push_back的元素拷贝到新的内存中,最后要析构原有的vector并释放原有的内存。所以说这个过程的效率是极低的,为了避免频繁的分配内存,C++每次申请内存都会成倍的增长,例如之前是4,那么重新申请后就是8,以此类推。当然不一定是成倍增长,比如在我的编译器环境下实测是0.5倍增长,之前是4,重新申请后就是6
|
|
||||||
|
|
||||||
[TinySTL]( https://github.com/zouxiaohang/TinySTL/tree/master/TinySTL)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 预处理指令
|
|
||||||
|
|
||||||
\#pragma once 防止头文件重复引用
|
|
||||||
|
|
||||||
一字节对齐
|
|
||||||
|
|
||||||
\#pragma pack(push, 1)
|
|
||||||
|
|
||||||
\#pragma pack(pop)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### class面向对象
|
|
||||||
|
|
||||||
#### 类继承
|
|
||||||
|
|
||||||
class LayerManager : public ILayerManager{};
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 为什么析构函数要是虚函数?
|
|
||||||
|
|
||||||
基类指针可以指向派生类的对象(多态性),如果删除该指针delete []p;就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。如果析构函数不被声明成虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样就会造成派生类对象析构不完全。所以,将析构函数声明为虚函数是十分必要的。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 覆盖虚函数机制
|
|
||||||
|
|
||||||
在某些情况下,希望覆盖虚函数机制并强制函数调用使用虚函数的特定版
|
|
||||||
|
|
||||||
本,这里可以使用作用域操作符:
|
|
||||||
|
|
||||||
```c++
|
|
||||||
Item_base *baseP = &derived;
|
|
||||||
|
|
||||||
// calls version from the base class regardless of the dynamic type of baseP
|
|
||||||
double d = baseP->Item_base::net_price(42);
|
|
||||||
```
|
|
||||||
|
|
||||||
这段代码强制将 net_price 调用确定为 Item_base 中定义的版本,该调用
|
|
||||||
|
|
||||||
将在编译时确定。**只有成员函数中的代码才应该使用作用域操作符覆盖虚函数机制。**
|
|
||||||
|
|
||||||
**为什么会希望覆盖虚函数机制?最常见的理由是为了派生类虚函数调用基类中的版本。**在这种情况下,基类版本可以完成继承层次中所有类型的公共任务,而每个派生类型只添加自己的特殊工作。
|
|
||||||
|
|
||||||
例如,可以定义一个具有虚操作的 Camera 类层次。Camera 类中的 display函数可以显示所有的公共信息,派生类(如 PerspectiveCamera)可能既需要显示公共信息又需要显示自己的独特信息。可以显式调用 Camera 版本以显示公共信息,而不是在 PerspectiveCamera 的 display 实现中复制 Camera 的操作。
|
|
||||||
|
|
||||||
在这种情况下,已经确切知道调用哪个实例,因此,不需要通过虚函数机制。派生类虚函数调用基类版本时,必须显式使用作用域操作符。如果派生类函数忽略了这样做,则函数调用会在运行时确定并且将是一个自身调用,从而导致无穷递归。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 名字冲突与继承
|
|
||||||
|
|
||||||
虽然可以直接访问基类成员,就像它是派生类成员一样,但是成员保留了它
|
|
||||||
|
|
||||||
的基类成员资格。一般我们并不关心是哪个实际类包含成员,通常只在基类和派
|
|
||||||
|
|
||||||
生类共享同一名字时才需要注意。
|
|
||||||
|
|
||||||
与基类成员同名的派生类成员将屏蔽对基类成员的直接访问。
|
|
||||||
|
|
||||||
```c
|
|
||||||
struct Base
|
|
||||||
{
|
|
||||||
Base(): mem(0) { }
|
|
||||||
protected:
|
|
||||||
int mem;
|
|
||||||
};
|
|
||||||
|
|
||||||
struct Derived : Base
|
|
||||||
{
|
|
||||||
Derived(int i): mem(i) { } // initializes Derived::mem
|
|
||||||
int get_mem() { return mem; } // returns Derived::mem
|
|
||||||
protected:
|
|
||||||
int mem; // hides mem in the base
|
|
||||||
};
|
|
||||||
|
|
||||||
get_mem 中对 mem 的引用被确定为使用 Derived 中的名字。如果编写如下代码:
|
|
||||||
Derived d(42);
|
|
||||||
cout << d.get_mem() << endl; // prints 42
|
|
||||||
```
|
|
||||||
|
|
||||||
则输出将是 42。
|
|
||||||
|
|
||||||
使用作用域操作符访问被屏蔽成员
|
|
||||||
|
|
||||||
可以使用作用域操作符访问被屏蔽的基类成员:
|
|
||||||
|
|
||||||
```c
|
|
||||||
struct Derived : Base
|
|
||||||
{
|
|
||||||
int get_base_mem() { return Base::mem; }
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
作用域操作符指示编译器在 Base 中查找 mem。
|
|
||||||
|
|
||||||
设计派生类时,只要可能,最好避免与基类数据成员的名字相同
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 类成员函数的重载、覆盖和隐藏区别?
|
|
||||||
|
|
||||||
a.成员函数被重载的特征:
|
|
||||||
|
|
||||||
(1)相同的范围(在同一个类中);
|
|
||||||
|
|
||||||
(2)函数名字相同;
|
|
||||||
|
|
||||||
(3)参数不同;
|
|
||||||
|
|
||||||
(4)virtual 关键字可有可无。
|
|
||||||
|
|
||||||
b.覆盖是指派生类函数覆盖基类函数,特征是:
|
|
||||||
|
|
||||||
(1)不同的范围(分别位于派生类与基类);
|
|
||||||
|
|
||||||
(2)函数名字相同;
|
|
||||||
|
|
||||||
(3)参数相同;
|
|
||||||
|
|
||||||
(4)基类函数必须有virtual 关键字。
|
|
||||||
|
|
||||||
c.“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
|
|
||||||
|
|
||||||
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆,仅同名就可以)。
|
|
||||||
|
|
||||||
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual 关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 纯虚函数
|
|
||||||
|
|
||||||
```c
|
|
||||||
class Disc_item : public Item_base
|
|
||||||
|
|
||||||
{
|
|
||||||
public:
|
|
||||||
double net_price(std::size_t) const = 0;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
含有(或继承)一个或多个纯虚函数的类是抽象基类。除了作
|
|
||||||
|
|
||||||
为抽象基类的派生类的对象的组成部分,甚至不能创建抽象类型Disc_item的对象。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 模板编程
|
|
||||||
|
|
||||||
#### 函数模板
|
|
||||||
|
|
||||||
```c
|
|
||||||
template <typename T>
|
|
||||||
int compare(const T &v1, const T &v2)
|
|
||||||
{
|
|
||||||
if (v1 < v2) return -1;
|
|
||||||
if (v2 < v1) return 1;
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
使用compare(1, 2)
|
|
||||||
|
|
||||||
#### 类模板
|
|
||||||
|
|
||||||
```c
|
|
||||||
template <class Type> class Queue
|
|
||||||
|
|
||||||
{
|
|
||||||
|
|
||||||
public:
|
|
||||||
|
|
||||||
Queue (); // default constructor
|
|
||||||
Type &front (); // return element from head of Queue
|
|
||||||
const Type &front () const;
|
|
||||||
void push (const Type &); // add element to back of Queue
|
|
||||||
void pop(); // remove element from head of Queue
|
|
||||||
bool empty() const; // true if no elements in the Queue
|
|
||||||
private:
|
|
||||||
// ...
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
使用Queue<int> qi;
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 操作符重载
|
|
||||||
|
|
||||||
#### 输出操作符
|
|
||||||
|
|
||||||
输出操作符通常是非成员函数,定义成类的友元
|
|
||||||
|
|
||||||
```c
|
|
||||||
friend ostream& operator<<(ostream& out, const Sales_item& s)
|
|
||||||
{
|
|
||||||
out << s.isbn << "\t" << s.units_sold << "\t"
|
|
||||||
<< s.revenue << "\t" << s.avg_price();
|
|
||||||
return out;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 算术和关系操作
|
|
||||||
|
|
||||||
算术和关系操作符定义为非成员函数
|
|
||||||
|
|
||||||
为了与内置操作符保持一致,加法返回一个右值,而不是一个引用。
|
|
||||||
|
|
||||||
```c
|
|
||||||
Sales_item operator+(const Sales_item& lhs, const Sales_item& rhs)
|
|
||||||
|
|
||||||
{
|
|
||||||
|
|
||||||
Sales_item ret(lhs); // copy lhs into a local object that we'll
|
|
||||||
ret += rhs; // add in the contents of rhs
|
|
||||||
return ret; // return ret by value
|
|
||||||
}
|
|
||||||
|
|
||||||
int operator<(const TableIndex2D& right) const;
|
|
||||||
|
|
||||||
friend bool operator== (const UEContext& info1,const UEContext& info2) const
|
|
||||||
{
|
|
||||||
if(info1.ContextID != info2.ContextID) return false;
|
|
||||||
return true;
|
|
||||||
}
|
|
||||||
|
|
||||||
friend bool operator!= (const UEContext& info1,const UEContext& info2) const
|
|
||||||
{
|
|
||||||
return !(info1 == info2);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 复制控制
|
|
||||||
|
|
||||||
**包括,一个拷贝构造函数,一个赋值运算符,一个析构函数,一对取址运算符**
|
|
||||||
|
|
||||||
如果你这么写:`class Empty{};`
|
|
||||||
|
|
||||||
和你这么写是一样的:
|
|
||||||
|
|
||||||
```c
|
|
||||||
class Empty
|
|
||||||
{
|
|
||||||
public:
|
|
||||||
Empty(); // 缺省构造函数
|
|
||||||
Empty(const Empty& rhs); // 拷贝构造函数
|
|
||||||
~Empty(); // 析构函数 ---- 是否
|
|
||||||
// 为虚函数看下文说明
|
|
||||||
Empty& operator=(const Empty& rhs); // 赋值运算符
|
|
||||||
Empty* operator&(); // 取址运算符
|
|
||||||
const Empty* operator&() const;
|
|
||||||
};
|
|
||||||
|
|
||||||
Empty(const Empty& rhs)
|
|
||||||
{
|
|
||||||
a = rhs.a
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
类赋值操作符必须是类的成员,以便编译器可以知道是否需要合成一个, 赋值必须返回对 *this 的引用。
|
|
||||||
|
|
||||||
一般而言,赋值操作符与复合赋值操作符应返回操作符的引用
|
|
||||||
|
|
||||||
```c
|
|
||||||
Guti& Guti::operator=( const Guti& rhs )
|
|
||||||
{
|
|
||||||
mtmsi_m = rhs.mtmsi_m;
|
|
||||||
mmeCode_m = rhs.mmeCode_m;
|
|
||||||
mmeGid_m = rhs.mmeGid_m;
|
|
||||||
plmnId_m = rhs.plmnId_m;
|
|
||||||
return *this;
|
|
||||||
};
|
|
||||||
|
|
||||||
注意,检查对自己赋值的情况
|
|
||||||
c& c::operator=(const c& rhs)
|
|
||||||
{
|
|
||||||
// 检查对自己赋值的情况
|
|
||||||
if (this == &rhs) return *this;
|
|
||||||
...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 构造函数初始化式
|
|
||||||
|
|
||||||
初始化const对象和引用对象的唯一机会。P389 C++ Primer 5th
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 协议
|
|
||||||
|
|
||||||
#### RTP/RTSP/RTCP
|
|
||||||
|
|
||||||
RTP协议RFC1889和RFC3550 G711 PCMU
|
|
||||||
|
|
||||||
#### HTTP
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Linux基础
|
|
||||||
|
|
||||||
Linux shell之数组:https://www.cnblogs.com/Joke-Shi/p/5705856.html
|
|
||||||
|
|
||||||
Linux expr命令:http://www.runoob.com/linux/linux-comm-expr.html
|
|
||||||
|
|
||||||
shell中变量类型:local,global,export关键字: https://www.cnblogs.com/kaishirenshi/p/10274179.html
|
|
||||||
|
|
||||||
Linux let 命令:http://www.runoob.com/linux/linux-comm-let.html
|
|
||||||
|
|
||||||
vim修改tab成4个空格写python: http://www.cnblogs.com/wi100sh/p/4938996.html
|
|
||||||
|
|
||||||
python判断文件是否存在的几种方法: https://www.cnblogs.com/jhao/p/7243043.html
|
|
||||||
|
|
||||||
python--文件操作删除某行: https://www.cnblogs.com/nopnog/p/7026390.html
|
|
||||||
|
|
||||||
pytho3字典遍历的几种操作: https://www.jb51.net/article/138414.htm
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
chmod
|
|
||||||
|
|
||||||
命令名称: chmod
|
|
||||||
|
|
||||||
执行权限: 所有用户
|
|
||||||
|
|
||||||
功能描述: 改变文件或目录权限
|
|
||||||
|
|
||||||
语法: 第一种方法 chmod [{ugoa}{+-=}{rwx}] [文件或目录]
|
|
||||||
|
|
||||||
备注: u:所有者 g:所属组 o:其他人 a:所有人
|
|
||||||
|
|
||||||
+:为用户增加权限 -:为用户减少权限 =:为用户赋予权限
|
|
||||||
|
|
||||||
r:读权限 w:写权限 x:执行权限
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
第二种方法 chmod -R [mode=421] [文件或目录] ←(这种方法用的比较多)
|
|
||||||
|
|
||||||
备注: r:4 w:2 x:1
|
|
||||||
|
|
||||||
r为读权限,可以用4来表示,
|
|
||||||
|
|
||||||
w为写权限,可以用2来表示,
|
|
||||||
|
|
||||||
x为执行权限,可以用1来表示。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### new操作
|
|
||||||
|
|
||||||
动态分配数组int *pia = new int[10]; // array of 10 uninitialized ints
|
|
||||||
|
|
||||||
释放分配的数组 delete [] pia;
|
|
||||||
|
|
||||||
#### new数组
|
|
||||||
|
|
||||||
```c
|
|
||||||
int *arr = new int[1024]
|
|
||||||
delte [] a
|
|
||||||
# 堆上new 对象
|
|
||||||
class MyClass
|
|
||||||
{
|
|
||||||
MyClass(int a) {};
|
|
||||||
int empty() {return 0;};
|
|
||||||
};
|
|
||||||
|
|
||||||
MyClass *p = new MyClass(1);
|
|
||||||
delete p;
|
|
||||||
|
|
||||||
# 栈上分配 对象
|
|
||||||
MyClass test(1);
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 放置式new
|
|
||||||
|
|
||||||
区分以下几种操作符号:
|
|
||||||
|
|
||||||
new operator-普通的new关键字
|
|
||||||
|
|
||||||
operator new-仅仅申请内存返回void*
|
|
||||||
|
|
||||||
placement new-在指定内存调用构造函数初始化类
|
|
||||||
|
|
||||||
new [] operator-如果是类对象,会在首部多申请4字节内存用于保存对象个数
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
深入探究 new 和 delete https://blog.csdn.net/codedoctor/article/details/76187567
|
|
||||||
|
|
||||||
当我们使用关键字new在堆上动态创建一个对象A时,比如 A* p = new A(),它实际上做了三件事:
|
|
||||||
|
|
||||||
向堆上申请一块内存空间(做够容纳对象A大小的数据)(operator new)
|
|
||||||
|
|
||||||
调用构造函数 (调用A的构造函数(如果A有的话))(placement new)
|
|
||||||
|
|
||||||
返回正确的指针
|
|
||||||
|
|
||||||
当然,如果我们创建的是简单类型的变量,那么第二步会被省略。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
当我们delete的时候也是如此,比如我们delete p 的时候,其行为如下:
|
|
||||||
|
|
||||||
定位到指针p所指向的内存空间,然后根据其类型,调用其自带的析构函数(内置类型不用)
|
|
||||||
|
|
||||||
然后释放其内存空间(将这块内存空间标志为可用,然后还给操作系统)
|
|
||||||
|
|
||||||
将指针标记为无效(指向NULL)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
https://blog.csdn.net/rain_qingtian/article/details/14225211
|
|
||||||
|
|
||||||
```c
|
|
||||||
|
|
||||||
|
|
||||||
void* p=::operator new (sizeof(Buffer)); //创建一块内存;冒号表示全局的new
|
|
||||||
Buffer* bp= start_cast<Buffer*>(p); //指针进行装换
|
|
||||||
Buffer* buf3=new(bp) Buffer(128); //把bp指针指向的内存租借buf3,
|
|
||||||
buf3->put('c');
|
|
||||||
buf3->~Buffer(); //这里析够函数要显示调用
|
|
||||||
::operator delete(p);
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
[放置new构造对象数组](https://bbs.csdn.net/topics/392271390)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
在栈上分配类内存: https://www.cnblogs.com/weekbo/p/8533368.html
|
|
||||||
|
|
||||||
new与malloc区别
|
|
||||||
|
|
||||||
b. new和malloc最大区别: new会调用类的构造函数,malloc不会;
|
|
||||||
|
|
||||||
c. delete和free同理;new/delete是运算符,malloc/free函数。所以new/delete效率应该会高点。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### [Linux IPC机制汇总](https://www.cnblogs.com/Jimmy1988/p/7744659.html)
|
|
||||||
|
|
||||||
#### 管道
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <unistd.h>
|
|
||||||
|
|
||||||
无名管道: int pipe(int pipedes[2])
|
|
||||||
|
|
||||||
有名管道:int mkfifo(const char *pathname, mode_t mode)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 消息队列
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <sys/msg.h>
|
|
||||||
|
|
||||||
int msgget(key_t key, int msgflg) //创建
|
|
||||||
|
|
||||||
int msgctl(int msqid, int cmd, struct msqid_ds *buf) //设置/获取消息队列的属性值
|
|
||||||
|
|
||||||
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg) //发送消息到消息队列(添加到尾端)
|
|
||||||
|
|
||||||
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg) //接收消息
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 共享内存
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <sys/shm.h>
|
|
||||||
|
|
||||||
int shmget(key_t key, size_t size, int shmflg) //创建一个共享内存空间
|
|
||||||
|
|
||||||
int shmctl(int shmid, int cmd, struct shmid_ds *buf) //对共享内存进程操作,包括:读取/设置状态,删除操作
|
|
||||||
|
|
||||||
void *shmat(int shmid, const void *shmaddr, int shmflg) //将共享内存空间挂载到进程中
|
|
||||||
|
|
||||||
int shmdt(const void *shmaddr) //将进程与共享内存空间分离 **(****只是与共享内存不再有联系,并没有删除共享内存****)**
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 信号
|
|
||||||
|
|
||||||
` #include</usr/include/bits/signum.h>`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 手动实现strcpy
|
|
||||||
|
|
||||||
```c
|
|
||||||
char *strcpy(char *strDest, const char *strSrc)
|
|
||||||
{
|
|
||||||
if ( strDest == NULL || strSrc == NULL)
|
|
||||||
return NULL ;
|
|
||||||
if ( strDest == strSrc)
|
|
||||||
return strDest ;
|
|
||||||
char *tempptr = strDest ;
|
|
||||||
while( (*strDest++ = *strSrc++) != ‘/0’)
|
|
||||||
return tempptr ;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### C++对象内存布局
|
|
||||||
|
|
||||||
这部分详细内容可以参考[深度探索C++对象模型](https://book.douban.com/subject/10427315/)
|
|
||||||
|
|
||||||
#### 虚函数多态机制
|
|
||||||
|
|
||||||
通过虚表指针访问虚成员函数,对普通成员函数的访问区别于虚成员函数。具体如下:
|
|
||||||
|
|
||||||
virtual member function虚成员函数normalize()的调用实际上转换成:
|
|
||||||
|
|
||||||
(*ptr->vpter[1])(ptr)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
函数指针也有差别,下面第一个是普通函数指针或者static member function。第二个是non-static member function成员函数指针。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 不同继承层次的对象内存布局
|
|
||||||
|
|
||||||
##### 单一继承
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
##### 多重继承
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 参考
|
|
||||||
|
|
||||||
[常见C++笔试题](http://blog.csdn.net/dongfengsun/article/details/1541926)
|
|
||||||
@@ -1,30 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "玩转vscode支持Markdown预览"
|
|
||||||
date: 2019-6-12
|
|
||||||
tags: [markdown,vscode]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式。
|
|
||||||
|
|
||||||
<!-- more -->
|
|
||||||
|
|
||||||
### Markdown
|
|
||||||
|
|
||||||
Markdown具有一系列衍生版本,用于扩展Markdown的功能(如表格、脚注、内嵌HTML等等),这些功能原初的Markdown尚不具备,它们能让Markdown转换成更多的格式,例如LaTeX,Docbook。Markdown增强版中比较有名的有Markdown Extra、MultiMarkdown、 Maruku等。这些衍生版本要么基于工具,如Pandoc;要么基于网站,如GitHub和Wikipedia,在语法上基本兼容,但在一些语法和渲染效果上有改动。来自[360百科](https://baike.so.com/doc/6949586-7171987.html)
|
|
||||||
|
|
||||||
### VsCode
|
|
||||||
强大地自定义功能,已经成为程序员最爱编辑器。
|
|
||||||
Microsoft在2015年4月30日Build 开发者大会上正式宣布了 Visual Studio Code 项目:一个运行于 Mac OS X、Windows和Linux之上的,针对于编写现代 Web 和云应用的跨平台源代码编辑器。
|
|
||||||
该编辑器也集成了所有一款现代编辑器所应该具备的特性,包括语法高亮(syntax high lighting),可定制的热键绑定(customizable keyboard bindings),括号匹配(bracket matching)以及代码片段收集(snippets)。Somasegar 也告诉笔者这款编辑器也拥有对 Git 的开箱即用的支持。引用[360百科](https://baike.so.com/doc/24428308-25261478.html)
|
|
||||||
|
|
||||||
### MarkDown遇上VsCode
|
|
||||||
#### 有两种方法预览markdown渲染效果
|
|
||||||
* Ctrl+Shift+P 打开命令框输入Markdown即可匹配到一系列的MarkDown命令,选择其中的打开预览或打开侧边预览
|
|
||||||
* 直接使用快捷键。打开侧边预览
|
|
||||||
> Ctrl+K 松开接 V
|
|
||||||
* 打开预览
|
|
||||||
>Ctrl+shift V
|
|
||||||
|
|
||||||
@@ -1,257 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "redis分布式锁3种实现方式对比分析总结"
|
|
||||||
date: 2020-1-28
|
|
||||||
tags: [后台开发]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
大家春节在家抢红包玩的不亦乐乎,抢红包服务看起来非常简单,实际上要做好这个服务,特别是money相关服务是不允许出错的,想想看每个红包的数字都是真金白银,要求服务的鲁棒性非常高,背后包含着很多后台服务技术细节。
|
|
||||||
|
|
||||||
<!-- more -->
|
|
||||||
|
|
||||||
## 什么是锁
|
|
||||||
|
|
||||||
后台开发中锁的概念是「实现多个进程或线程互斥的访问共享资源的一种机制」,这里的计算机术语我举个栗子你就能理解:
|
|
||||||
|
|
||||||
> 小王家只有卧室一台电视机。小王他爸喜欢看篮球NBA,小王他妈喜欢追综艺,如果小王他爸妈一起抢着看就会打架谁都看不好,这就是「死锁」。
|
|
||||||
>
|
|
||||||
> 怎么办?小王他爸每次进入房间看电视第一件事就是把房门锁上,同样的小王他妈每次进房间看综艺第一件事也是把房门锁上,这就是「加锁」。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
在计算机中公共资源可以是一块公共的内存,或者是一个公共的文件,对于这类共享资源的访问都是需要「加锁」保证各个进程或线程的资源访问互相不干扰。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 什么是分布式锁
|
|
||||||
|
|
||||||
分布式锁是在分布式系统中提出的概念,所谓分布式是指由很多功能对等的节点,提供相同的服务,各个节点如果需要访问「共享资源」,为了保证数据一致性也需要「加锁」,这个锁可以放在「公共存储数据库」,访问共享资源之前先去公共存储数据库拿锁,拿到锁才能访问共享资源。
|
|
||||||
|
|
||||||
还是拿上面的小王来举例子:
|
|
||||||
|
|
||||||
> 现在小王的村里只有一个电视(小王村真穷),现在这个电视不是属于小王家,整个村的人都看这一个电视,并且要求一家在看的时候其他家不能看(这是看的啥电视),以前小王家的锁不能锁村里的电视,那怎么办呢?
|
|
||||||
>
|
|
||||||
> 村里每个家庭就是一个「分布式节点」,一个解决方案是把电视放在村长家「公共存储数据库」,各家轮流去村长家看电视,并且在进去看的时候让村长关门「加锁」,这就是分布式锁。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 分布式锁实现
|
|
||||||
|
|
||||||
今天就来说说其中一个技术细节,也是在我另一篇文章[Linux后台开发C++学习路线技能加点](https://zhuanlan.zhihu.com/p/102048769)中提到但没展开讲的,高并发服务编程中的**redis分布式锁**。
|
|
||||||
|
|
||||||
这里罗列出**3种redis实现的分布式锁**,并分别对比说明各自特点。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Redis单实例分布式锁
|
|
||||||
|
|
||||||
### 实现一: SETNX实现的分布式锁
|
|
||||||
|
|
||||||
setnx用法参考redis[官方文档](https://redis.io/commands/setnx)
|
|
||||||
|
|
||||||
#### 语法
|
|
||||||
|
|
||||||
`SETNX key value`
|
|
||||||
|
|
||||||
将`key`设置值为`value`,如果`key`不存在,这种情况下等同SET命令。 当`key`存在时,什么也不做。`SETNX`是”**SET** if **N**ot e**X**ists”的简写。
|
|
||||||
|
|
||||||
返回值:
|
|
||||||
|
|
||||||
- 1 设置key成功
|
|
||||||
- 0 设置key失败
|
|
||||||
|
|
||||||
#### 加锁步骤
|
|
||||||
|
|
||||||
1. ```SETNX lock.foo <current Unix time + lock timeout + 1>```
|
|
||||||
|
|
||||||
如果客户端获得锁,`SETNX`返回`1`,加锁成功。
|
|
||||||
|
|
||||||
如果`SETNX`返回`0`,那么该键已经被其他的客户端锁定。
|
|
||||||
|
|
||||||
2. 接上一步,`SETNX`返回`0`加锁失败,此时,调用`GET lock.foo`获取时间戳检查该锁是否已经过期:
|
|
||||||
|
|
||||||
- 如果没有过期,则休眠一会重试。
|
|
||||||
|
|
||||||
- 如果已经过期,则可以获取该锁。具体的:调用`GETSET lock.foo <current Unix timestamp + lock timeout + 1>`基于当前时间设置新的过期时间。
|
|
||||||
|
|
||||||
**注意**: 这里设置的时候因为在`SETNX`与`GETSET`之间有个窗口期,在这期间锁可能已被其他客户端抢去,所以这里需要判断`GETSET`的返回值,他的返回值是SET之前旧的时间戳:
|
|
||||||
|
|
||||||
- 若旧的时间戳已过期,则表示加锁成功。
|
|
||||||
- 若旧的时间戳还未过期(说明被其他客户端抢去并设置了时间戳),代表加锁失败,需要等待重试。
|
|
||||||
|
|
||||||
#### 解锁步骤
|
|
||||||
|
|
||||||
解锁相对简单,只需`GET lock.foo`时间戳,判断是否过期,过期就调用删除`DEL lock.foo`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 实现二:SET实现的分布式锁
|
|
||||||
|
|
||||||
set用法参考[官方文档](https://redis.io/commands/set)
|
|
||||||
|
|
||||||
#### 语法
|
|
||||||
|
|
||||||
`SET key value [EX seconds|PX milliseconds] [NX|XX]`
|
|
||||||
|
|
||||||
将键`key`设定为指定的“字符串”值。如果 `key` 已经保存了一个值,那么这个操作会直接覆盖原来的值,并且忽略原始类型。当`set`命令执行成功之后,之前设置的过期时间都将失效。
|
|
||||||
|
|
||||||
从2.6.12版本开始,redis为`SET`命令增加了一系列选项:
|
|
||||||
|
|
||||||
- `EX` *seconds* – Set the specified expire time, in seconds.
|
|
||||||
- `PX` *milliseconds* – Set the specified expire time, in milliseconds.
|
|
||||||
- `NX` – Only set the key if it does not already exist.
|
|
||||||
- `XX` – Only set the key if it already exist.
|
|
||||||
- `EX` *seconds* – 设置键key的过期时间,单位时秒
|
|
||||||
- `PX` *milliseconds* – 设置键key的过期时间,单位是毫秒
|
|
||||||
- `NX` – 只有键key不存在的时候才会设置key的值
|
|
||||||
- `XX` – 只有键key存在的时候才会设置key的值
|
|
||||||
|
|
||||||
版本\>= 6.0
|
|
||||||
|
|
||||||
- `KEEPTTL` -- 保持 key 之前的有效时间TTL
|
|
||||||
|
|
||||||
#### 加锁步骤
|
|
||||||
|
|
||||||
一条命令即可加锁: `SET resource_name my_random_value NX PX 30000`
|
|
||||||
|
|
||||||
The command will set the key only if it does not already exist (NX option), with an expire of 30000 milliseconds (PX option). The key is set to a value “my*random*value”. This value must be unique across all clients and all lock requests.
|
|
||||||
|
|
||||||
这个命令只有当`key` 对应的键不存在resource_name时(NX选项的作用)才生效,同时设置30000毫秒的超时,成功设置其值为my_random_value,这是个在所有redis客户端加锁请求中全局唯一的随机值。
|
|
||||||
|
|
||||||
#### 解锁步骤
|
|
||||||
|
|
||||||
解锁时需要确保my_random_value和加锁的时候一致。下面的Lua脚本可以完成
|
|
||||||
|
|
||||||
```lau
|
|
||||||
if redis.call("get",KEYS[1]) == ARGV[1] then
|
|
||||||
return redis.call("del",KEYS[1])
|
|
||||||
else
|
|
||||||
return 0
|
|
||||||
end
|
|
||||||
```
|
|
||||||
|
|
||||||
这段Lua脚本在执行的时候要把前面的`my_random_value`作为`ARGV[1]`的值传进去,把`resource_name`作为`KEYS[1]`的值传进去。释放锁其实包含三步操作:’GET’、判断和’DEL’,用Lua脚本来实现能保证这三步的原子性。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Redis集群分布式锁
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 实现三:Redlock
|
|
||||||
|
|
||||||
前面两种分布式锁的实现都是针对单redis master实例,既不是有互为备份的slave节点也不是多master集群,如果是redis集群,每个redis master节点都是独立存储,这种场景用前面两种加锁策略有锁的安全性问题。
|
|
||||||
|
|
||||||
比如下面这种场景:
|
|
||||||
|
|
||||||
> 1. 客户端1从Master获取了锁。
|
|
||||||
> 2. Master宕机了,存储锁的key还没有来得及同步到Slave上。
|
|
||||||
> 3. Slave升级为Master。
|
|
||||||
> 4. 客户端2从新的Master获取到了对应同一个资源的锁。
|
|
||||||
>
|
|
||||||
> 于是,客户端1和客户端2同时持有了同一个资源的锁。锁的安全性被打破。
|
|
||||||
|
|
||||||
针对这种多redis服务实例的场景,redis作者antirez设计了**Redlock** (Distributed locks with Redis)算法,就是我们接下来介绍的。
|
|
||||||
|
|
||||||
### 加锁步骤
|
|
||||||
|
|
||||||
**集群加锁的总体思想是尝试锁住所有节点,当有一半以上节点被锁住就代表加锁成功。集群部署你的数据可能保存在任何一个redis服务节点上,一旦加锁必须确保集群内任意节点被锁住,否则也就失去了加锁的意义。**
|
|
||||||
|
|
||||||
具体的:
|
|
||||||
|
|
||||||
1. 获取当前时间(毫秒数)。
|
|
||||||
2. 按顺序依次向N个Redis节点执行**获取锁**的操作。这个获取操作跟前面基于单Redis节点的**获取锁**的过程相同,包含随机字符串`my_random_value`,也包含过期时间(比如`PX 30000`,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个**获取锁**的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
|
|
||||||
3. 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
|
|
||||||
4. 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
|
|
||||||
5. 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起**释放锁**的操作(即前面介绍的Redis Lua脚本)。
|
|
||||||
|
|
||||||
### 解锁步骤
|
|
||||||
|
|
||||||
客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
|
|
||||||
|
|
||||||
### 算法实现
|
|
||||||
|
|
||||||
上面描述的算法已经有现成的实现,各种语言版本。
|
|
||||||
|
|
||||||
- [Redlock-rb](https://github.com/antirez/redlock-rb) (Ruby implementation). There is also a [fork of Redlock-rb](https://github.com/leandromoreira/redlock-rb) that adds a gem for easy distribution and perhaps more.
|
|
||||||
- [Redlock-py](https://github.com/SPSCommerce/redlock-py) (Python implementation).
|
|
||||||
- [Aioredlock](https://github.com/joanvila/aioredlock) (Asyncio Python implementation).
|
|
||||||
- [Redlock-php](https://github.com/ronnylt/redlock-php) (PHP implementation).
|
|
||||||
- [PHPRedisMutex](https://github.com/malkusch/lock#phpredismutex) (further PHP implementation)
|
|
||||||
- [cheprasov/php-redis-lock](https://github.com/cheprasov/php-redis-lock) (PHP library for locks)
|
|
||||||
- [Redsync](https://github.com/go-redsync/redsync) (Go implementation).
|
|
||||||
- [Redisson](https://github.com/mrniko/redisson) (Java implementation).
|
|
||||||
- [Redis::DistLock](https://github.com/sbertrang/redis-distlock) (Perl implementation).
|
|
||||||
- [Redlock-cpp](https://github.com/jacket-code/redlock-cpp) (C++ implementation).
|
|
||||||
- [Redlock-cs](https://github.com/kidfashion/redlock-cs) (C#/.NET implementation).
|
|
||||||
- [RedLock.net](https://github.com/samcook/RedLock.net) (C#/.NET implementation). Includes async and lock extension support.
|
|
||||||
- [ScarletLock](https://github.com/psibernetic/scarletlock) (C# .NET implementation with configurable datastore)
|
|
||||||
- [Redlock4Net](https://github.com/LiZhenNet/Redlock4Net) (C# .NET implementation)
|
|
||||||
- [node-redlock](https://github.com/mike-marcacci/node-redlock) (NodeJS implementation). Includes support for lock extension.
|
|
||||||
|
|
||||||
### 比如我用的C++实现
|
|
||||||
|
|
||||||
[源码在这](https://github.com/jacket-code/redlock-cpp)
|
|
||||||
|
|
||||||
#### 创建分布式锁管理类CRedLock
|
|
||||||
|
|
||||||
```c++
|
|
||||||
CRedLock * dlm = new CRedLock();
|
|
||||||
dlm->AddServerUrl("127.0.0.1", 5005);
|
|
||||||
dlm->AddServerUrl("127.0.0.1", 5006);
|
|
||||||
dlm->AddServerUrl("127.0.0.1", 5007);
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 加锁并设置超时时间
|
|
||||||
|
|
||||||
```c++
|
|
||||||
CLock my_lock;
|
|
||||||
bool flag = dlm->Lock("my_resource_name", 1000, my_lock);
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 加锁并保持直到释放
|
|
||||||
|
|
||||||
```c++
|
|
||||||
CLock my_lock;
|
|
||||||
bool flag = dlm->ContinueLock("my_resource_name", 1000, my_lock);
|
|
||||||
```
|
|
||||||
|
|
||||||
`my_resource_name`是加锁标识;`1000`是锁的有效期,单位毫秒。
|
|
||||||
|
|
||||||
#### 加锁失败返回false, 加锁成功返回`Lock`结构如下
|
|
||||||
|
|
||||||
```c++
|
|
||||||
class CLock {
|
|
||||||
public:
|
|
||||||
int m_validityTime; => 9897.3020019531 // 当前锁可以存活的时间, 毫秒
|
|
||||||
sds m_resource; => my_resource_name // 要锁住的资源名称
|
|
||||||
sds m_val; => 53771bfa1e775 // 锁住资源的进程随机名字
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 解锁
|
|
||||||
|
|
||||||
```c++
|
|
||||||
dlm->Unlock(my_lock);
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
综上所述,三种实现方式。
|
|
||||||
|
|
||||||
- 单redis实例场景,分布式锁实现一和实现二都可以,实现二更简洁推荐用实现二,用实现三也可以,但是实现三有点复杂略显笨重。
|
|
||||||
- 多redis实例场景推荐用实现三最安全,不过实现三也不是完美无瑕,也有针对这种算法缺陷的讨论(节点宕机同步时延、时间同步假设),大家还需要根据自身业务场景灵活选择或定制自己的分布式锁。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[Distributed locks with Redis](https://redis.io/topics/distlock)
|
|
||||||
|
|
||||||
[How to do distributed locking](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html)
|
|
||||||
|
|
||||||
[基于Redis的分布式锁到底安全吗](http://zhangtielei.com/posts/blog-redlock-reasoning.html)
|
|
||||||
@@ -1,92 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "后台服务高并发编程-抢红包"
|
|
||||||
date: 2020-1-27
|
|
||||||
tags: [后台开发]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
今年春节响应国家号召在家宅着抵抗疫情,拜年也改用微信红包,春节发了很多也抢了很多微信红包,也算支持了公司业务,想到WXG的小伙伴丰厚的年终奖我柠檬了,微信支付融入生活,抢红包已经是非常平常的事情。
|
|
||||||
|
|
||||||
抢红包这一简单的动作,每一次都是对红包服务后台的一次请求,在春节期间海量的服务请求下,其实是一个很典型的高并发编程模型。后台开发程序员都有一个共识:**实现一个功能很容易,难的是大量请求下提高服务性能**。
|
|
||||||
|
|
||||||
在程序员眼里,大家抢的不是红包,是红包后台服务的**锁** !这里的**锁**不是我们日常生活中的锁,后台服务编程中锁的概念:
|
|
||||||
|
|
||||||
> 实现多个进程或线程互斥的访问共享资源的一种机制
|
|
||||||
|
|
||||||
### 今天和大家聊聊后台服务编程中的锁。
|
|
||||||
|
|
||||||
## 业务模型
|
|
||||||
|
|
||||||
为便于说明,我们简化模型,约定抢红包服务是多线程服务,抢红包操作包含以下3个步骤:
|
|
||||||
|
|
||||||
1. 查询数据库内红包余额
|
|
||||||
2. 扣除抢到的红包金额
|
|
||||||
3. 更新红包余额到数据库
|
|
||||||
|
|
||||||
假设发了100块钱红包,1000个人1秒内同时来抢(高并发),如果不加锁是这样的情况:
|
|
||||||
|
|
||||||
- 第一个人查余额得到100元,他在此基础上扣除抢到的假设2元,准备步骤3更新到数据库。
|
|
||||||
- 在第一个人更新进去之前,此时剩下的人查到的余额也是100,他们各自扣除抢到的金额,准备按步骤3更新。
|
|
||||||
- 导致最后的红包余额只记录了最后一次更新的数据。
|
|
||||||
- 很明显,这就可能出现1000个人都抢到红包,但是红包余额还没分完的情况,这就乱了。
|
|
||||||
|
|
||||||
怎么解决这个问题呢? 就用到我们上面说的**加锁**来解决。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 有哪些锁
|
|
||||||
|
|
||||||
实现锁的方式有很多,这里列举几种常见的分类
|
|
||||||
|
|
||||||
### 悲观锁
|
|
||||||
|
|
||||||
> 顾名思义就是悲观的做最坏打算的锁机制,占有锁期间独占资源。
|
|
||||||
|
|
||||||
悲观锁把抢红包这三个步骤打包成一个整体做成互斥操作,**“在我抢了没更新数据之前你别来查余额,查到也不准确”**。也可以类比数据库的**事务**来理解。
|
|
||||||
|
|
||||||
> **事务必须具备以下四个属性,简称ACID 属性:**
|
|
||||||
> `原子性(Atomicity)`:事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执 行,要么都不执行
|
|
||||||
> `一致性(Consistency)`:当事务完成时,数据必须处于一致状态
|
|
||||||
> `隔离性(Isolation)`:对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务
|
|
||||||
> `永久性(Durability)`:事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性
|
|
||||||
|
|
||||||
它悲观的认为你每次去抢红包必然有其他人也同时在抢,所以你这条线程在抢的时候要独占资源,其他线程需要阻塞挂起等待你抢完才能进来抢,挂起的线程就干不了其他事了。
|
|
||||||
|
|
||||||
> 鲁迅先生说过,浪费CPU资源就是浪费生命!
|
|
||||||
|
|
||||||
而一旦你抢完红包释放了锁,其他在等待中的线程又要抢占资源、抢到了还要恢复线程上下文。
|
|
||||||
|
|
||||||
CPU不断的切换线程上下文非常浪费服务器资源,严重的会导致不能及时处理后续抢红包请求,需要想办法提高效率,于是有了**乐观锁**
|
|
||||||
|
|
||||||
### 乐观锁
|
|
||||||
|
|
||||||
> 乐观锁是对悲观锁的改进,乐观的认为加锁的时候没有竞争,乐观锁不阻塞线程。
|
|
||||||
|
|
||||||
一种实现乐观锁的方法是**数据库内红包余额增加版本号**,初始版本号是0,每次抢完红包版本号加1后再去更新余额,**只有更新的版本号大于数据库内的版本号才认为是合法的,予以更新;否则不予更新,线程不阻塞可以稍后重试,**避免频繁切换线程上下文。
|
|
||||||
|
|
||||||
乐观锁在抢红包的步骤1、2不做加锁判断,在步骤3的时候才做加锁判断版本号。
|
|
||||||
|
|
||||||
- 第一个人抢到版本号是0的红包,第二个人也抢到版本号是0的红包
|
|
||||||
- 第一个人更新红包余额并设置版本号为1
|
|
||||||
- 第二个人更新红包余额设置版本号为1的时候发现余额版本号已经为1,更新失败
|
|
||||||
- 第二个人更新失败后,**线程不阻塞,继续处理其他抢红包抢请求**,按**一定策略重试**(超时重试、有限次数重试)第二个人的更新操作
|
|
||||||
- 其他请求以此类推
|
|
||||||
|
|
||||||
可以看到,乐观锁在加锁失败的时候不挂起线程等待,避免了线程上下文频繁的切换,提高红包服务处理性能。
|
|
||||||
|
|
||||||
### 分布式锁
|
|
||||||
|
|
||||||
上面两种锁的形式都是基于对数据库的更新来做的,在大请求高并发的时候,频繁的存取数据库,尤其是乐观锁重试会对数据库产生很大的冲击,在实际生产环境要尽量减少对数据库的访问。
|
|
||||||
|
|
||||||
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。也可以用redis实现**分布式锁**,与数据库交互两次:第一次获取红包余额,第二次抢完更新红包状态。抢红包和中间过程更新操作都在内存中进行,这可比数据库操作快了几个数量级,显著改善服务并发性能。
|
|
||||||
|
|
||||||
redis分布式锁:
|
|
||||||
|
|
||||||
> 利用Redis的SET操作在内存中保存key-value键值对,加锁就是获取这个键值对的值,解锁就是删除这个键值对。
|
|
||||||
|
|
||||||
分布式锁也不阻塞线程,关于这种分布式锁的实现不在这里展开说明,参考我另一篇公众号文章,[redis分布式锁3种实现方式分析](1)
|
|
||||||
|
|
||||||
#### 更多原创技术干货分享在我的公众号:柠檬橙学编程 欢迎关注。
|
|
||||||
|
|
||||||
@@ -1,261 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "Linux后台开发C++学习路线技能加点"
|
|
||||||
date: 2020-1-1
|
|
||||||
tags: [c++]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
最近在知乎经常被邀请回答类似如何学习C++和C++后台开发应该具体储备哪些基础技能的问题。
|
|
||||||
|
|
||||||
本身我从事的的C++后台开发的工作,目前在腾讯负责社交产品相关后台开发,所以写这篇文章,分享自己的C++后台开发学习路径和点过的技能树,希望能给想从事后台开发的同学一点参考,若能帮你少走些弯路就更好。
|
|
||||||
|
|
||||||
工欲善其事必先利其器,好的书籍能让学习事半功倍,所以每个技能点之后我会推荐一些书,都是我读过且口碑不错的书,供参考。
|
|
||||||
|
|
||||||
**分享的是我的学习路径,如果你也能顺着这个学习路径认真学一遍,我想在后台开发技术上你已经有一个很不错的技术积累,加上项目练习通过大部分大厂面试是没有问题的。后续还会继续分享关于C++编程和后台开发技术,感兴趣的同学可以关注我和专栏。**
|
|
||||||
|
|
||||||
## 计算机基础综合
|
|
||||||
|
|
||||||
考过CS或者软件工程研究生的同学可能对这个标题不陌生,是的,我说的就是专业课代号408的**计算机基础综合**。这门专业课包含:数据结构、计算机组成原理、计算机网路、操作系统。
|
|
||||||
|
|
||||||
为什么提起这门课程呢,因为基础知识太重要了!这是科班区别于培训班的最大不同,理论知识不一定马上能用于项目上,但当与人讨论起某个技术问题时你能够知道它深层次的原因,看问题的角度会更加全面和系统。
|
|
||||||
|
|
||||||
打个比方,你可能听过堆栈的名词,但知道它的具体结构和不同吗?学完数据结构就明白了;你知道计算机会算加减乘除,但具体是如何实现的呢?组成原理会告诉你;知道程序执行的时候怎么区分指令地址和数据地址的吗?操作系统会告诉你答案。
|
|
||||||
|
|
||||||
所以如果你大学不是计算机相关专业,或者是本专业但是没有完全吃透基础的话,强烈建议你务必抽时间好好学习这几门课程。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
**计算机基础综合**推荐看大学的计算机专业教材就可以:数据结构、计算机组成原理、计算机网路、操作系统。
|
|
||||||
|
|
||||||
- 数据结构
|
|
||||||
|
|
||||||
> 1.教材:[《数据结构》](https://www.baidu.com/s?wd=《数据结构》&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)[严蔚敏](https://www.baidu.com/s?wd=严蔚敏&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao) 清华大学出版社
|
|
||||||
>
|
|
||||||
> 2.辅导书:《算法与数据结构考研试题精析(第二版)》[机械工业出版社](https://www.baidu.com/s?wd=机械工业出版社&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)
|
|
||||||
|
|
||||||
- 计算机组成原理
|
|
||||||
|
|
||||||
> 教材:[《计算机组成原理》](https://www.baidu.com/s?wd=《计算机组成原理》&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)[唐朔飞](https://www.baidu.com/s?wd=唐朔飞&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao) [高等教育出版社](https://www.baidu.com/s?wd=高等教育出版社&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)
|
|
||||||
>
|
|
||||||
> 辅导书:
|
|
||||||
>
|
|
||||||
> [《计算机组成原理考研指导》](https://www.baidu.com/s?wd=《计算机组成原理考研指导》&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)徐爱萍 清华大学出版社
|
|
||||||
>
|
|
||||||
> 《计算机组成原理--学习指导与习题解答》[唐朔飞](https://www.baidu.com/s?wd=唐朔飞&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao) [高等教育出版社](https://www.baidu.com/s?wd=高等教育出版社&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)
|
|
||||||
|
|
||||||
- 操作系统
|
|
||||||
|
|
||||||
> 教材:[《计算机操作系统(修订版)》](https://www.baidu.com/s?wd=《计算机操作系统(修订版)》&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)汤子瀛 [西安电子科技大学出版社](https://www.baidu.com/s?wd=西安电子科技大学出版社&tn=SE_PcZhidaonwhc_ngpagmjz&rsv_dl=gh_pc_zhidao)
|
|
||||||
>
|
|
||||||
> 辅导书:《操作系统考研辅导教程(计算机专业研究生入学考试全真题解) 》电子科技大学出版社
|
|
||||||
>
|
|
||||||
> 《操作系统考研指导》清华大学出版社
|
|
||||||
|
|
||||||
- 计算机网络
|
|
||||||
|
|
||||||
> 教材:《计算机网络(第五版)》谢希仁 电子工业出版社
|
|
||||||
>
|
|
||||||
> 辅导书:《计算机网络知识要点与习题解析》哈尔滨工程大学出版社
|
|
||||||
|
|
||||||
#### 视频教材
|
|
||||||
|
|
||||||
看上面的课本教程估计非常枯燥,下面是我觉得讲的不错的国内大学公开课我听过一部分,讲的都是计算机专业的基础内容,如果你没有系统的学过或者学的不好,都是非常建议刷一遍视频课的。
|
|
||||||
|
|
||||||
[武汉大学-数据结构 MOOC网络课程 ](https://www.icourse163.org/course/WHU-1001539003)
|
|
||||||
|
|
||||||
[华中科技大学-计算机组成原理](https://www.icourse163.org/course/HUST-1003159001)
|
|
||||||
|
|
||||||
[电子科技大学-计算机组成原理](https://www.icourse163.org/course/UESTC-1001543002)
|
|
||||||
|
|
||||||
[华中科技大学-操作系统原理](https://www.icourse163.org/course/HUST-1003405007)
|
|
||||||
|
|
||||||
[哈尔滨工业大学-计算机网络](https://www.icourse163.org/course/HIT-154005)
|
|
||||||
|
|
||||||
**这一小节写的有点多,因为基础实在是太重要了!科班和非科班的差距不是谁学的编程语言多,也不是谁框架用的溜,本质区别是理论知识储备差别和用CS思维独立思考分析解决问题的能力。**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## C++和C语法基础
|
|
||||||
|
|
||||||
**语法是一门语言的基础。**C++的基础语句和语法和C是很像的,最大的不同在class和异常处理机制,还有模板的应用,所以有C基础语法学起来是很快,没有C基础也没关系,啃完下面推荐的书也差不多,光说不练假把式,看完之后趁热把课后习题敲一遍并且自己编译通过才算看完。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《C++ Primer 中文版(第 5 版)》](https://book.douban.com/subject/25708312/) 经典的入门书籍,不要拿大学教材XX强来对比,不是一个等级。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 标准库STL学习
|
|
||||||
|
|
||||||
**STL提供了丰富的算法库支持和各种容器。**C++标准库提供了包括最基础的标准输入输出`iostrem`、各种容器`vector、set、string` ,熟练掌握标准库,不用重复造轮子(练手学习目的的造轮子除外)写出更C++的代码。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《C++ Primer 中文版(第 5 版)》](https://book.douban.com/subject/25708312/)
|
|
||||||
|
|
||||||
[《STL源码剖析》]( https://book.douban.com/subject/1110934/ )
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## C++进阶
|
|
||||||
|
|
||||||
**学完了上面的C++基础只是会用,要用好还需要不断学习进阶。**站在巨人的肩膀上写出更健壮高效的代码,你没踩过的坑前人已经踩过一遍,关于一些语言细节和更好的编码习惯,有很多优秀的书籍可以学习。
|
|
||||||
|
|
||||||
#### 推荐书
|
|
||||||
|
|
||||||
[《Effective C++》](https://book.douban.com/subject/1842426/) 改善程序与设计的55个具体做法,非常值得一看,老手和新手的差别由此产生!
|
|
||||||
|
|
||||||
[《More Effective C++(中文版》](https://book.douban.com/subject/5908727/)
|
|
||||||
|
|
||||||
> 同一个作者,继Effective C++之后,Scott Meyers于1996推出这本《More Effective C++(35个改善编程与设计的有效方法)》“续集”。条款变得比较少,页数倒是多了一些,原因是这次选材比“一集”更高阶,尤其是第5章。Meyers将此章命名为技术。
|
|
||||||
|
|
||||||
[《Inside the C++ Object Model》](https://book.douban.com/subject/1484262/) 这本书还有中文版本,翻译质量也很高[《深度探索C++对象模型》](https://book.douban.com/subject/1091086/)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## C++11新标准
|
|
||||||
|
|
||||||
**新标准提供了解决现有问题更优雅、更C++的实现**。现行的大部分C++软件还是C++98的标准,C++98是C++的第一个标准,经历这么多年的发展,从前你需要从Boost库(一个在C++98年代的准C++标准)获得的对C++的扩充支持的大部分功能已经纳入了C++11和甚至C++2X更新的标准当中,与时俱进拿起更先进的生产工具,工具就是效率。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《深入理解C++11》](https://book.douban.com/subject/24738301/)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Linux系统基础和shell script
|
|
||||||
|
|
||||||
**如今几乎所有的互联网服务都是跑在linux系统上面的。**对Linux系统一无所知那更加谈不上后台开发了,所以要先学习linux系统操作,不如文件管理,系统命令,文件系统,权限管理,系统服务等。
|
|
||||||
|
|
||||||
至于shell script 就类似win的批处理脚本,相信我,你在linux下干活早晚会需要它,所以趁早系统学起来。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《鸟哥的Linux私房菜基础学习篇》](https://book.douban.com/subject/4889838/) 这个系列还有一个服务器架设篇,前期学习个人感觉没必要看
|
|
||||||
|
|
||||||
[《Linux Shell脚本攻略》](https://book.douban.com/subject/6889456/)
|
|
||||||
|
|
||||||
[《Shell脚本学习指南》](https://read.douban.com/ebook/124173616/?dcs=subject-rec&dcm=douban&dct=6889456)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Linux环境高级编程
|
|
||||||
|
|
||||||
**普通用户只需懂系统操作,软件开发人员还要懂编程接口。**上一阶段你已经能够完成熟练操作Linux系统,知道一些常规的系统命令和服务,并且能够利用shell script写一些小工具提高日常开发效率。
|
|
||||||
|
|
||||||
我们的目标是星辰大海,作为软件工程师,还需要更加深入的掌握linux系统编程技巧,**学习系统编程接口、系统调用API、内存管理、进程间通信(IPC)**,这是本阶段的学习目的。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《UNIX环境高级编程》](https://book.douban.com/subject/1788421/) 这本是linux编程必看的APUE,强烈推荐通读一遍,后续值得反复翻阅。
|
|
||||||
|
|
||||||
[《Linux/UNIX系统编程手册》](https://book.douban.com/subject/25809330/) 这本书和APUE有点重复,我看完APUE这本就跳着看了,平常可以看目录查阅。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## TCP/IP协议
|
|
||||||
|
|
||||||
目前网络通信中应用最广泛的协议就是IP TCP协议,后面Unix提供的TCP套接字也是基于协议实现,所以很有必要系统的学习 TCP/IP 协议。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
大学的计算机网络教程
|
|
||||||
|
|
||||||
[《TCP/IP详解 卷1:协议》](https://book.douban.com/subject/1088054/)
|
|
||||||
|
|
||||||
[《TCP/IP详解 卷2:实现》](https://book.douban.com/subject/1087767/)
|
|
||||||
|
|
||||||
[《TCP/IP详解 卷3:TCP事务协议、HTTP、NNTP和UNIX域协议》](https://book.douban.com/subject/1058634/)
|
|
||||||
|
|
||||||
这几本书很厚,可以先看卷1、卷3
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Linux网络编程套接字
|
|
||||||
|
|
||||||
在同一台机器上进程间的通信(IPC)有多种方式,可以是通过**消息队列、FIFO、共享内存**等方式。网络编程套接字是指:分布在不同机器上的程序通过系统提供的网络通信接口,跨越网络将不同机器上的进程连接起来,实现跨机器的网络通信。一般有**UDP套接字、TCP套接字、Unix Domain,当然,如果你是通信从业者对SCTP套接字肯定也不会陌生。**
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《UNIX网络编程 卷1:套接字联网API(第3版)》](https://book.douban.com/subject/4859464/)
|
|
||||||
|
|
||||||
[《UNIX网络编程 卷2:进程间通信(第2版)》](https://book.douban.com/subject/26434599/)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 数据库和存储
|
|
||||||
|
|
||||||
**程序运行数据都在易失性的内存中,需要持久化存储时就需要数据库。**一个后台服务系统一般来说都需要考虑数据落地和持久性存储的问题,这时就会涉及到数据库选型和应用,数据库分为关系型数据库和非关系型数据库。
|
|
||||||
|
|
||||||
**关系型数据库:**指采用了关系模型来组织数据的数据库,代表是MySql。
|
|
||||||
关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
|
|
||||||
|
|
||||||
**非关系型数据库:**以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。代表有redis、memcached,腾讯内部组件ckv也是非关系型数据库。
|
|
||||||
|
|
||||||
#### 推荐书:
|
|
||||||
|
|
||||||
[《SQL必知必会》](https://book.douban.com/subject/24250054/)
|
|
||||||
|
|
||||||
[《高性能MySQL》](https://book.douban.com/subject/23008813/)
|
|
||||||
|
|
||||||
[redis官方文档](https://redis.io/documentation) [redis中文网](http://redis.cn/)
|
|
||||||
|
|
||||||
> 关于redis还有很多应用,比如基于redis的分布式锁的应用,高并发抢红包模型等,这个后面可以写一篇关于分布式锁的原理和应用文章。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 算法基础
|
|
||||||
|
|
||||||
**计算机算法就是利用编程语言编写出计算机能理解的解决问题的方法。**
|
|
||||||
|
|
||||||
好的算法能更简洁高效的解决问题,如今不论是校招还是社招,大厂笔试都会考察算法,即使不是为了笔试作为软件从业者也应该经常练习算法,保持手感。学习算法是学习解决问题的通用性方法有助于提高逻辑思维能力。
|
|
||||||
|
|
||||||
#### 学习方法
|
|
||||||
|
|
||||||
**就我个人经验来说,不推荐直接啃书的方式学习算法,建议看书的同时结合刷在线编程算法题的方式。**
|
|
||||||
|
|
||||||
具体的:边看数据结构或算法导论,同时在[牛客](https://www.nowcoder.com/activity/oj)或者 [leetcode](https://leetcode-cn.com/ )上刷题,因为看书太枯燥很容易失去耐心,在线刷题的好处是你可以每天定目标,享受每个题目通过的快感,有正向反馈更容易坚持下来。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 架构能力
|
|
||||||
|
|
||||||
**架构能力是利用已有知识来设计整个后台服务系统的能力。**不仅要求掌握技能的维度还要深度,需要能根据不同需求和系统约束,制定不同的设计方案。
|
|
||||||
|
|
||||||
这时候考虑的东西会更多,包括服务模型的设计:是多进程还是多线程甚至协程微线程,分布式还是集中式;
|
|
||||||
|
|
||||||
存储的选型:考虑数据库选型用哪个?需要根据存储的数据特征和应用场景来区分,如果是社交应用的数据用非关系型数据库来存储可能更好,如果是电商订单类型的数据,那么用关系型数据库来存储可能更好;
|
|
||||||
|
|
||||||
当然,还有后台系统的其他方方面面需要考虑,不一一举例了。
|
|
||||||
|
|
||||||
## 更多的练习
|
|
||||||
|
|
||||||
**说了这么多,最最重要的还是练习练习练习。**理论知识储备是必要条件,移动互联网时代大家接触到的碎片化信息太杂太乱,我个人经验,高浓度的知识精华还是需要在大师的书本中汲取,所以看书是最正确和快速的学习路径,没有捷径可走。
|
|
||||||
|
|
||||||
不过光看书也是不行,编程能力和技术是也是一门现代手艺活,还需要日常不断的打磨手艺,正如**一万小时定律**:
|
|
||||||
|
|
||||||
> 人们眼中的天才之所以卓越非凡,并非天资超人一等,而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成世界级大师的必要条件。要成为某个领域的专家,需要10000小时,按比例计算就是:如果每天工作八个小时,一周工作五天,那么成为一个领域的专家至少需要五年。这就是一万小时定律。
|
|
||||||
|
|
||||||
怎么打磨提高编程技术能力呢?找项目,**找感兴趣的**东西用代码去实现它,兴趣是最好的老师,这点在编程和技术学习上也完全适用。
|
|
||||||
|
|
||||||
人们总倾向于去做快速获得的愉悦感的事情,比如打一盘游戏30分钟就能获得快感。相反,技术碎片的提高是一个长期的过程,三分钟热度肯定是难以成功的。
|
|
||||||
|
|
||||||
所以要用技术做自己感兴趣的东西和带趣味性的编程,比如写个爬虫小程序抓取网站数据或者写个小游戏,再或者自己造轮子给自己用,并乐此不疲的优化轮子。这样每走一步都能获得一点成就感,激励自己继续走下去,慢慢的一定会有质的飞跃。
|
|
||||||
|
|
||||||
## 一个网站
|
|
||||||
|
|
||||||
这个网站一定要告诉大家,网站就是个C++百科全书,类似Linux的man手册,平常开发查忘记了函数名或者容器用法直接搜索非常方便。
|
|
||||||
|
|
||||||
网址:C++参考: [cppreference](https://en.cppreference.com/w/cpp)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 待续
|
|
||||||
|
|
||||||
一口气写下来肯定还不够完善,文章会保持更新和修改,想到了再补充吧。感兴趣可以关注我的微信公众号 **后端技术学堂** 更多干货和有趣的技术分享。
|
|
||||||
|
|
||||||
**我整理了文中提到和推荐的电子书与视频教材**,都是好几年学习过程中收集的,关注微信公众号 **后端技术学堂** 回复 【**1024**】 免费分享给大家。
|
|
||||||
|
|
||||||
|
|
||||||
@@ -1,210 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "多面手linux date命令"
|
|
||||||
date: 2020-1-27
|
|
||||||
tags: [后台开发]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
今天给项目写了个脚本需要获取前一天的时间,本来先获取今天的然后减一下,如果是1号的话还要考虑大小月份挺复杂的,于是去查了一下手册`date`命令原生支持,喜出望外,今天就详细说说这个看起来不起眼的`date`命令。
|
|
||||||
|
|
||||||
使用Linux的同学应该对linux的`date`命令不会陌生,经常需要在命令行敲一下这个命令获取当前时间。然而这只是他的能力冰山一角。
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date
|
|
||||||
2020年 02月 12日 星期三 19:51:46 CST
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 常规操作
|
|
||||||
|
|
||||||
#### 获取时间戳,1970年1月1日0点0分0秒到现在历经的秒数
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date +%s
|
|
||||||
1581508426
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 时间戳还原,把刚才的秒数还原成时间字符串
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d "@1581508426"
|
|
||||||
2020年 02月 12日 星期三 19:53:46 CST
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 指定的时间字符串转换成时间戳
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d '02/22/2222 07:21:22' +%s
|
|
||||||
7956832882
|
|
||||||
#或者
|
|
||||||
[lemon@localhost ~]$ date -d '2222-02-22 07:21:22' +"%s"
|
|
||||||
7956832882
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 格式化输出时间格式
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date "+%Y-%m-%d"
|
|
||||||
2020-02-12
|
|
||||||
[lemon@localhost ~]$ date "+%H:%M:%S"
|
|
||||||
20:01:53
|
|
||||||
[lemon@localhost ~]$ date "+%Y-%m-%d %H:%M:%S"
|
|
||||||
2020-02-12 20:02:06
|
|
||||||
```
|
|
||||||
|
|
||||||
具体的格式参考man手册:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
格式 FORMAT 控制着输出格式. 仅当选项指定为全球时间时本格式才有效。 分别解释如下:
|
|
||||||
|
|
||||||
%% 文本的 %
|
|
||||||
|
|
||||||
%a 当前区域的星期几的简写 (Sun..Sat)
|
|
||||||
|
|
||||||
%A 当前区域的星期几的全称 (不同长度) (Sunday..Saturday)
|
|
||||||
|
|
||||||
%b 当前区域的月份的简写 (Jan..Dec)
|
|
||||||
|
|
||||||
%B 当前区域的月份的全称(变长) (January..December)
|
|
||||||
|
|
||||||
%c 当前区域的日期和时间 (Sat Nov 04 12:02:33 EST 1989)
|
|
||||||
|
|
||||||
%d (月份中的)几号(用两位表示) (01..31)
|
|
||||||
|
|
||||||
%D 日期(按照 月/日期/年 格式显示) (mm/dd/yy)
|
|
||||||
|
|
||||||
%e (月份中的)几号(去零表示) ( 1..31)
|
|
||||||
|
|
||||||
%h 同 %b
|
|
||||||
|
|
||||||
%H 小时(按 24 小时制显示,用两位表示) (00..23)
|
|
||||||
|
|
||||||
%I 小时(按 12 小时制显示,用两位表示) (01..12)
|
|
||||||
|
|
||||||
%j (一年中的)第几天(用三位表示) (001..366)
|
|
||||||
|
|
||||||
%k 小时(按 24 小时制显示,去零显示) ( 0..23)
|
|
||||||
|
|
||||||
%l 小时(按 12 小时制显示,去零表示) ( 1..12)
|
|
||||||
|
|
||||||
%m 月份(用两位表示) (01..12)
|
|
||||||
|
|
||||||
%M 分钟数(用两位表示) (00..59)
|
|
||||||
|
|
||||||
%n 换行
|
|
||||||
|
|
||||||
%p 当前时间是上午 AM 还是下午 PM
|
|
||||||
|
|
||||||
%r 时间,按 12 小时制显示 (hh:mm:ss [A/P]M)
|
|
||||||
|
|
||||||
%s 从 1970年1月1日0点0分0秒到现在历经的秒数 (GNU扩充)
|
|
||||||
|
|
||||||
%S 秒数(用两位表示)(00..60)
|
|
||||||
|
|
||||||
%t 水平方向的 tab 制表符
|
|
||||||
|
|
||||||
%T 时间,按 24 小时制显示(hh:mm:ss)
|
|
||||||
|
|
||||||
%U (一年中的)第几个星期,以星期天作为一周的开始(用两位表示) (00..53)
|
|
||||||
|
|
||||||
%V (一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (01..52)
|
|
||||||
|
|
||||||
%w 用数字表示星期几 (0..6); 0 代表星期天
|
|
||||||
|
|
||||||
%W (一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (00..53)
|
|
||||||
|
|
||||||
%x 按照 (mm/dd/yy) 格式显示当前日期
|
|
||||||
|
|
||||||
%X 按照 (%H:%M:%S) 格式显示当前时间
|
|
||||||
|
|
||||||
%y 年的后两位数字 (00..99)
|
|
||||||
|
|
||||||
%Y 年(用 4 位表示) (1970...)
|
|
||||||
|
|
||||||
%z 按照 RFC-822 中指定的数字时区显示(如, -0500) (为非标准扩充)
|
|
||||||
|
|
||||||
%Z 时区(例如, EDT (美国东部时区)), 如果不能决定是哪个时区则为空
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 下面就是比较骚的操作,我今天用到了。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对当前时间的明天的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d next-day
|
|
||||||
2020年 02月 13日 星期四 20:08:35 CST
|
|
||||||
|
|
||||||
#你可以指定输出格式,比如
|
|
||||||
[lemon@localhost ~]$ date -d next-day +%Y%m%d
|
|
||||||
20200213
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对于当前时间的昨天的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d last-day
|
|
||||||
2020年 02月 11日 星期二 20:11:35 CST
|
|
||||||
|
|
||||||
#你也可以指定输出格式,比如
|
|
||||||
[lemon@localhost ~]$ date -d last-day +%Y%m%d
|
|
||||||
20200211
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对当前时间的上个月的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d last-month
|
|
||||||
2020年 01月 12日 星期日 20:13:20 CST
|
|
||||||
|
|
||||||
#同样的你也可以指定输出格式,比如
|
|
||||||
[lemon@localhost ~]$ date -d last-month +%Y-%m-%d
|
|
||||||
2020-01-12
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对当前时间的下个月的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d next-month
|
|
||||||
2020年 03月 12日 星期四 20:15:44 CST
|
|
||||||
|
|
||||||
[lemon@localhost ~]$ date -d next-month "+%Y-%m-%d %H:%M:%S"
|
|
||||||
2020-03-12 20:15:38
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对当前时间的明年的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d next-year
|
|
||||||
2021年 02月 12日 星期五 20:17:21 CST
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 获取相对当前时间的上一年的时间
|
|
||||||
|
|
||||||
```bash
|
|
||||||
[lemon@localhost ~]$ date -d last-year
|
|
||||||
2019年 02月 12日 星期二 20:17:29 CST
|
|
||||||
```
|
|
||||||
|
|
||||||
@@ -1,68 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "推荐一款github代码在线浏览神器sourcegraph"
|
|
||||||
date: 2020-1-27
|
|
||||||
tags: [后台开发]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
程序员逛github已经是每日必须项目,看到感兴趣的项目都会点进去看一下,github全球最大的同性交友平台,这里有海量的开源代码库,作为开源代码管理平台github是非常专业的。
|
|
||||||
|
|
||||||
但是,你要在上面看代码就不是那么舒服了,特别是点进去每个文件夹浏览文件非常的不方便,大工程文件之间的切换有时候网页加载特别慢非常不方便。
|
|
||||||
|
|
||||||
推荐这款我用的这款Google浏览器插件,安装之后让在线浏览github项目源码,查找引用和定义如同在IDE看代码一样,体验如丝滑般舒爽。
|
|
||||||
|
|
||||||
## 安装
|
|
||||||
|
|
||||||
进入[Google应用商店](https://chrome.google.com/webstore/category/extensions?utm_source=chrome-ntp-icon) 搜索sourcegraph下载安装插件,如下图:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
点击,**添加至Chrome**,即可在项目中使用。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 使用
|
|
||||||
|
|
||||||
打开github上任意一个项目,点击项目上方的Sourcegraph图标,即可进入代码浏览界面。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
代码浏览界面的左侧是代码目录结构,就跟一般的IDE工程视图一样,你可以很轻松的在各个文件夹中查看文件,不用像在github那样来回前进后退,望着网页加载进度发呆。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
鼠标单击相应的函数,出现的选项框可以选择跳转到定义
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
也可选择查找所有引用
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 离线安装
|
|
||||||
|
|
||||||
鉴于有些同学由于众所周知的原因,不方便去Google应用商店下载,这里再说说离线安装的方法
|
|
||||||
|
|
||||||
- 进入Chrome插件中心,浏览器输入 [chrome://extensions/](chrome://extensions/)
|
|
||||||
- 打开开发者模式开关
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
- 下载我提供的插件安装包 `20.2.5.1810_0.rar` ,安装包在公众号【柠檬的编程学堂】回复【插件】获取,解压放到插件文件夹路径,比如我的路径:
|
|
||||||
|
|
||||||
`C:\Users\替换成你的电脑用户名\AppData\Local\Google\Chrome\User Data\Default\Extensions`
|
|
||||||
|
|
||||||
- 打开浏览器插件中心,打开 **开发者模式**,选择 **加载已解压的扩展程序**,即可完成安装。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
以上,这款好用的插件分享给大家,愉快的在github玩耍吧!
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -1,160 +0,0 @@
|
|||||||
---
|
|
||||||
layout: post
|
|
||||||
title: "我分析几个一线城市的近千份岗位招聘需求,得出应该这么准备找工作"
|
|
||||||
date: 2020-1-27
|
|
||||||
tags: [后台开发]
|
|
||||||
comments: true
|
|
||||||
author: lemonchann
|
|
||||||
---
|
|
||||||
|
|
||||||
每年的三四月份是招聘高峰,也常被大家称为金三银四黄金求职期,这时候上一年的总结做完了,奖金拿到了,职场人开始谋划着年初的找工作大戏。
|
|
||||||
|
|
||||||
作为IT人要发挥自己的专业特长,如何让伯乐和千里马更快相遇?我利用大数据分析了北京、广州、深圳三个一线城市的C++招聘岗位信息,篇幅限制文中只拿出北京和深圳的数据展示,让我们来看看岗位的招聘现状,以及如何科学提高应聘成功率。
|
|
||||||
|
|
||||||
文末可以获取本次分析的高清图表,需要的同学自取。同时分享完整源码用于学习交流,若对其他岗位感兴趣也可以自行运行源码分析。
|
|
||||||
|
|
||||||
### 需求分析
|
|
||||||
|
|
||||||
通过大数据分析招聘网站发布的招聘数据,得出岗位分布区域、薪资水平、岗位关键技能需求、匹配的人才具有哪些特点、学历要求。从而帮助应聘者提高自身能力,补齐短板,有的放矢的应对校招社招,达成终极目标获得心仪的offer。
|
|
||||||
|
|
||||||
### 软件设计
|
|
||||||
|
|
||||||
数据分析是Python的强项,项目用Python实现。软件分为两大模块:数据获取 和 数据分析
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 详细实现
|
|
||||||
|
|
||||||
#### 数据获取
|
|
||||||
|
|
||||||
request库构造请求获取数据
|
|
||||||
|
|
||||||
```py
|
|
||||||
cookie = s.cookies
|
|
||||||
req = requests.post(self.baseurl, headers=self.header, data={'first': True, 'pn': i, 'kd':self.keyword}, params={'px': 'default', 'city': self.city, 'needAddtionalResult': 'false'}, cookies=cookie, timeout=3)
|
|
||||||
text = req.json()
|
|
||||||
```
|
|
||||||
|
|
||||||
数据csv格式存储
|
|
||||||
|
|
||||||
```py
|
|
||||||
with open(os.path.join(self.path, '招聘_关键词_{}_城市_{}.csv'.format(self.keyword, self.city)), 'w',newline='', encoding='utf-8-sig') as f:
|
|
||||||
f_csv = csv.DictWriter(f, self.csv_header)
|
|
||||||
f_csv.writeheader()
|
|
||||||
f_csv.writerows(data_list)
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 数据分析
|
|
||||||
|
|
||||||
字段预处理
|
|
||||||
|
|
||||||
```py
|
|
||||||
df_all.rename({'职位名称': 'position'}, axis=1, inplace=True) #axis=1代表index; axis=0代表column
|
|
||||||
df_all.rename({'详细链接': 'url'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'工作地点': 'region'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'薪资': 'salary'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'公司名称': 'company'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'经验要求': 'experience'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'学历': 'edu'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'福利': 'welfare'}, axis=1, inplace=True)
|
|
||||||
df_all.rename({'职位信息': 'detail'}, axis=1, inplace=True)
|
|
||||||
df_all.drop_duplicates(inplace=True)
|
|
||||||
df_all.index = range(df_all.shape[0])
|
|
||||||
```
|
|
||||||
|
|
||||||
数据图表展示
|
|
||||||
|
|
||||||
```py
|
|
||||||
from pyecharts.charts import Bar
|
|
||||||
regBar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
|
|
||||||
regBar.add_xaxis(region.index.tolist())
|
|
||||||
regBar.add_yaxis("区域", region.values.tolist())
|
|
||||||
regBar.set_global_opts(title_opts=opts.TitleOpts(title="工作区域分布"),
|
|
||||||
toolbox_opts=opts.ToolboxOpts(),
|
|
||||||
visualmap_opts=opts.VisualMapOpts())
|
|
||||||
|
|
||||||
from pyecharts.commons.utils import JsCode
|
|
||||||
shBar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
|
|
||||||
shBar.add_xaxis(sala_high.index.tolist())
|
|
||||||
shBar.add_yaxis("区域", sala_high.values.tolist())
|
|
||||||
shBar.set_series_opts(itemstyle_opts={
|
|
||||||
"normal": {
|
|
||||||
"color": JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
|
|
||||||
offset: 0,
|
|
||||||
color: 'rgba(0, 244, 255, 1)'
|
|
||||||
}, {
|
|
||||||
offset: 1,
|
|
||||||
color: 'rgba(0, 77, 167, 1)'
|
|
||||||
}], false)"""),
|
|
||||||
"barBorderRadius": [30, 30, 30, 30],
|
|
||||||
"shadowColor": 'rgb(0, 160, 221)',
|
|
||||||
}})
|
|
||||||
shBar.set_global_opts(title_opts=opts.TitleOpts(title="最高薪资范围分布"), toolbox_opts=opts.ToolboxOpts())
|
|
||||||
|
|
||||||
word.add("", [*zip(key_words.words, key_words.num)],
|
|
||||||
word_size_range=[20, 200], shape='diamond')
|
|
||||||
word.set_global_opts(title_opts=opts.TitleOpts(title="岗位技能关键词云图"),
|
|
||||||
toolbox_opts=opts.ToolboxOpts())
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 数据分析
|
|
||||||
|
|
||||||
#### 区域分布
|
|
||||||
|
|
||||||
C++岗位区域分布,北京 VS 深圳
|
|
||||||

|
|
||||||
|
|
||||||
北京的C++岗位数量比深圳更多,首都buff加持,并且集中分布在海淀区和朝阳区这两个区域,中关村位于海淀区,还有位于海淀区西北旺镇的后厂村,腾讯、滴滴、百度、新浪、网易这些互联网巨头扎堆,自然能提供更多的岗位。
|
|
||||||
|
|
||||||
深圳的岗位则集中在南山区,猜测鹅厂C++大厂在南山区贡献了重大份额,第二竟然在宝安区。
|
|
||||||
|
|
||||||
#### 学历分布
|
|
||||||
|
|
||||||
C++岗位学历分布,北京 VS 深圳
|
|
||||||

|
|
||||||
|
|
||||||
学历上两个城市的本科学历占比都是85%以上,北京岗位需求研究生占比和大专相当。可见大部分岗位本科学历即可胜任,或许能给即将毕业纠结考不考研的你一些参考。
|
|
||||||
|
|
||||||
如果你的学历是专科,那么需要加倍的努力,因为留给你的职位并不是很多。同时,从图表数据来看,深圳的岗位对大专生需求10%而对硕士仅占2%,或许专科生去深圳比去北京更加友好,emmm...仅供参考。
|
|
||||||
|
|
||||||
#### 薪资分布
|
|
||||||
|
|
||||||
C++岗位薪资分布,薪资单位K。
|
|
||||||
|
|
||||||
北京最高薪资 VS 最低薪资
|
|
||||||

|
|
||||||
|
|
||||||
深圳最高薪资 VS 最低薪资
|
|
||||||

|
|
||||||
|
|
||||||
薪资对比没啥好说的,大家看图说话,只想说帝都果然财大气粗。
|
|
||||||
|
|
||||||
#### 技能储备
|
|
||||||
|
|
||||||
C++岗位关键技能词云,北京 VS 深圳
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
首先在脱离开发走上管理岗位之前,编程解决问题能力是最重要,可以看到「编程」能力在技能词云中占比最大。
|
|
||||||
|
|
||||||
大部分岗位要求较高的「算法、数据结构、Linux、数据库(存储)、多线程(操作系统)」这些计算机基础素养,所以不管你是在校学生准备校招或者职场老人准备跳槽,都需要储备好这些计算机基础能力,无论哪种个方向,硬实力的储备都很重要。
|
|
||||||
|
|
||||||
值得一提的是除去硬核技术要求外,岗位对候选人的软实力也有要求,比如更加偏爱具备「团队、协作、学习、沟通」这些能力的候选人,大家在提高技术能力的同时,也要注重这些软实力的培养。
|
|
||||||
|
|
||||||
一个彩蛋。Linux和window下都有C++开发岗位需求,相对而言Linux下C++开发占比更多,词云更大,如果你对这两个平台没有特殊偏爱,那么学Linux下开发大概能加大应聘成功率,毕竟岗位需求更大。
|
|
||||||
|
|
||||||
关注公众号「柠檬的编程学堂」回复 「分析」获取本文程序完整源码以及高清分析图表。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 69 KiB |
{kind=link}
|
Before Width: | Height: | Size: 70 KiB |
{kind=link}
|
Before Width: | Height: | Size: 33 KiB |
@@ -1,281 +0,0 @@
|
|||||||
前面几周陆陆续续写了一些后端技术的文章,包括数据库、微服务、内存管理等等,我比较倾向于成体系的学习,所以数据库和微服务还有后续系列文章补充。
|
|
||||||
|
|
||||||
最近工作上比较多的 Golang 编程,现在很多互联网公司都在转向 Golang 开发,所以打算写一写有关 Go 语言学习的系列文章,目标是从 Go 基础到进阶输出一系列文章,沉淀下这些知识同时也给大家做参考,力求做到通俗易懂,即使你是 `Golang` 小白也能看懂,如果你是老手也能温故知新。
|
|
||||||
|
|
||||||
本文将要和你分享 linux 下安装 Golang 环境,并且讲解如何通过配置 VSCode 远程开发调试 Golang 程序。
|
|
||||||
|
|
||||||
## 下载源码
|
|
||||||
|
|
||||||
你可以用系统自带的包管理工具比如 `yum` 或 `apt-get` 来安装Golang开发环境。不过,为了通用性,我选择通过源码的方式来安装和讲解,在官网下载源码,下载地址 https://golang.org/dl/
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 手动安装
|
|
||||||
|
|
||||||
### 解压安装
|
|
||||||
|
|
||||||
我这里下载下来的源码包 `go1.14.2.linux-amd64.tar.gz` 放到远程 Linux 服务器目录下。执行以下命令安装到 /usr/local 目录。
|
|
||||||
|
|
||||||
```
|
|
||||||
tar -zxvf -C /usr/local/ `go1.14.2.linux-amd64.tar.gz`
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 创建工作空间
|
|
||||||
|
|
||||||
工作空间是你Go项目的「工作目录」,挑选一个合适目录,执行下面操作:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
mkdir GoPath
|
|
||||||
mkdir -p GoPath/src
|
|
||||||
mkdir -p GoPath/bin
|
|
||||||
mkdir -p GoPath/pkg
|
|
||||||
```
|
|
||||||
|
|
||||||
三个目录含义:
|
|
||||||
|
|
||||||
```css
|
|
||||||
src: 源码路径(例如:.go、.c、.h、.s 等)
|
|
||||||
pkg: 编译包时,生成的.a文件存放路径
|
|
||||||
bin: 编译生成的可执行文件路径
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 配置环境变量
|
|
||||||
|
|
||||||
安装过程中有这么几个环境变量需要配置,先来了解一下:
|
|
||||||
|
|
||||||
GOROOT:Go的安装路径,也就是前面我们解压到的目录 `/usr/local/go`。
|
|
||||||
|
|
||||||
GOBIN:Go项目的二进制文件存放目录。
|
|
||||||
|
|
||||||
GOPATH:Go的工作空间。前面有介绍的工作空间目录。
|
|
||||||
|
|
||||||
在 `/etc/profile` 文件追加以下内容完成设置。
|
|
||||||
|
|
||||||
```shell
|
|
||||||
export GOROOT=/usr/local/go
|
|
||||||
export GOPATH=/yourpath/GoPath # 设置你自己的GoPath路径
|
|
||||||
export GOBIN=$GOPATH/bin
|
|
||||||
export PATH=$PATH:$GOROOT/bin # 加入到PATH环境变量
|
|
||||||
export PATH=$PATH:$GOPATH/bin
|
|
||||||
```
|
|
||||||
|
|
||||||
```shell
|
|
||||||
# source /etc/profile #立即生效
|
|
||||||
```
|
|
||||||
|
|
||||||
### 验证安装
|
|
||||||
|
|
||||||
```shell
|
|
||||||
# go version #检查版本
|
|
||||||
# go version go1.14.2 linux/amd64 # 输出版本号
|
|
||||||
```
|
|
||||||
|
|
||||||
如果看到版本信息就代表安装成功了!
|
|
||||||
|
|
||||||
## 远程开发
|
|
||||||
|
|
||||||
上面我们在 Linux 环境下安装好了 Golang 开发环境,但我不想每次打开终端登录服务器编写调试程序,怎么才能在本地PC开发调试Golang程序呢?
|
|
||||||
|
|
||||||
看过我上一篇Vscode远程开发的小伙伴应该能想到方法,我们就要用Vscode搭建Golang远程开发环境。具体的远程开发配置可以查看我的另一篇文章。
|
|
||||||
|
|
||||||
### Golang开发插件
|
|
||||||
|
|
||||||
首先安装官方推荐的 Go 开发插件,如下,点他安装。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
接着还会出现如下的提示,是因为缺少其他 Go 开发相关插件,点 `install all` 全都装上就行。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Hello World
|
|
||||||
|
|
||||||
编程界有个惯例,什么语言开始学习都是从 Hello World 开始。现在,我们就用 Golang 编写第一个 `HelloWorld` 程序吧。
|
|
||||||
|
|
||||||
上代码:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main // 所有Go程序从main包开始运行
|
|
||||||
|
|
||||||
import "fmt" // 导入fmt包
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
fmt.Print("hello world", " i am ready to go :)\n")
|
|
||||||
fmt.Println("hello world", "i am ready to go :)")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
### 格式化 包
|
|
||||||
|
|
||||||
`fmt` 实现了类似 C++/C 语言的格式IO库功能。
|
|
||||||
|
|
||||||
`Print` 和 `Println` 都可用于打印输出,但是功能略有不同。可以看到我在`Print` 函数中,对后一个字符串加了空格和换行符,这样两个打印出来的结果是相同的。
|
|
||||||
|
|
||||||
### Print
|
|
||||||
|
|
||||||
```
|
|
||||||
func Print(a ...interface{}) (n int, err error)
|
|
||||||
```
|
|
||||||
|
|
||||||
Print采用默认格式将其参数格式化并写入标准输出。如果两个相邻的参数都不是字符串,会在它们的输出之间添加空格。返回写入的字节数和遇到的任何错误。
|
|
||||||
|
|
||||||
### Println
|
|
||||||
|
|
||||||
```
|
|
||||||
func Println(a ...interface{}) (n int, err error)
|
|
||||||
```
|
|
||||||
|
|
||||||
Println采用默认格式将其参数格式化并写入标准输出。总是会在相邻参数的输出之间添加空格并在输出结束后添加换行符。返回写入的字节数和遇到的任何错误。
|
|
||||||
|
|
||||||
## 调试
|
|
||||||
|
|
||||||
### 终端调试
|
|
||||||
|
|
||||||
在终端命令行源码所在目录输入`go run` 运行程序。
|
|
||||||
|
|
||||||
```shell
|
|
||||||
|
|
||||||
# go run HelloWorld.go
|
|
||||||
//输出
|
|
||||||
hello world i am ready to go :)
|
|
||||||
hello world i am ready to go :)
|
|
||||||
```
|
|
||||||
|
|
||||||
也可以先编译`go build` 得到可执行文件后再运行。
|
|
||||||
|
|
||||||
```shell
|
|
||||||
# go build HelloWorld.go
|
|
||||||
# ls
|
|
||||||
HelloWorld HelloWorld.go
|
|
||||||
# ./HelloWorld
|
|
||||||
hello world i am ready to go :)
|
|
||||||
hello world i am ready to go :)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Vscode调试
|
|
||||||
|
|
||||||
按`F5`启动调试,编辑与调试控制台输出如下:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 命令行参数获取
|
|
||||||
|
|
||||||
命令行参数可以通过`os` 包的 `Args` 函数获取,代码如下:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
|
|
||||||
import (
|
|
||||||
"fmt"
|
|
||||||
"os"
|
|
||||||
"strconv"
|
|
||||||
)
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
// 命令行参数获取,os.Args第一个参数是程序自身
|
|
||||||
fmt.Println(os.Args)
|
|
||||||
for idx, args := range os.Args {
|
|
||||||
fmt.Println("参数"+strconv.Itoa(idx)+":", args)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 终端设置
|
|
||||||
|
|
||||||
|
|
||||||
以下是带参数argv1 argv2 运行golang程序和输出。
|
|
||||||
```shell
|
|
||||||
# go run basic.go argv1 argv2
|
|
||||||
|
|
||||||
# 输出
|
|
||||||
[/tmp/go-build441686724/b001/exe/basic argv1 argv2]
|
|
||||||
参数0: /tmp/go-build441686724/b001/exe/basic
|
|
||||||
参数1: argv1
|
|
||||||
参数2: argv2
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### VSCode设置
|
|
||||||
|
|
||||||
launch.json文件的 `args` 属性配置可以设置程序启动调试的参数。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
设置之后,按`F5` 启动调试,就会在调试控制台输出配置的参数。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 环境变量获取
|
|
||||||
|
|
||||||
命令行参数可以通过`os` 包的 `Getenv` 函数获取,代码如下:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
|
|
||||||
import (
|
|
||||||
"fmt"
|
|
||||||
"os"
|
|
||||||
)
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
// 获取环境变量
|
|
||||||
fmt.Println(os.Getenv("type"), os.Getenv("name"), os.Getenv("GOROOT"))
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### VSCode设置环境变量
|
|
||||||
|
|
||||||
`launch.json` 文件的 `args` 属性配置可以设置 VSCode 调试的 Golang 程序环境变量。
|
|
||||||
|
|
||||||
设置的格式是:name:vaule 形式,注意都是字符串。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 终端设置环境变量
|
|
||||||
|
|
||||||
终端的环境变量设置就是可以用 Linux 的 `export` 命令设置,之后就可以用 `os.Getenv` 函数读取。
|
|
||||||
|
|
||||||
比如我们最初设置 `GOROOT` 环境变量的命令
|
|
||||||
|
|
||||||
```export GOROOT=/usr/local/go```
|
|
||||||
|
|
||||||
就可以用 `os.Getenv("GOROOT") ` 读取。比较简单,这里就不多说了。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
现在,你有了一个可以远程开发调试 Golang 的环境,赶紧去写个 `hello world` 体验一下吧!今天的分享就到这,下一篇文章讲解基础语法。
|
|
||||||
|
|
||||||
老规矩,感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
**原创不易,看到这里,如果在我这有一点点收获,就动动手指「转发」和「在看」是对我持续创作的最大支持。**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Reference
|
|
||||||
|
|
||||||
[设置GOPATH]( https://studygolang.com/articles/17598 )
|
|
||||||
|
|
||||||
[Visual Studio Code变量参考](https://blog.csdn.net/acktomas/article/details/102851702)
|
|
||||||
|
|
||||||
[Golang 获取系统环境变量](https://studygolang.com/articles/3387)
|
|
||||||
|
|
||||||
[os库获取命令行参数](https://studygolang.com/articles/21438)
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 46 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 42 KiB |
{kind=link}
|
Before Width: | Height: | Size: 43 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 90 KiB |
{kind=link}
|
Before Width: | Height: | Size: 46 KiB |
@@ -1,337 +0,0 @@
|
|||||||
对于一般的语言使用者来说 ,20% 的语言特性就能够满足 80% 的使用需求,剩下在使用中掌握。
|
|
||||||
|
|
||||||
基于这一理论,Go 基础系列的文章不会刻意追求面面俱到,但该有知识点都会覆盖,目的是带你快跑赶上 Golang 这趟新车。
|
|
||||||
|
|
||||||
**Hurry up , Let's go !**
|
|
||||||
|
|
||||||
## 一个好消息一个坏消息一个潜规则
|
|
||||||
|
|
||||||
Go 的语法类似 C 语言,你是从 C/C++ 语言过来的话学习成本很低,其他语言过来甚至没有编程基础也没关系,这门语言入门很轻松。
|
|
||||||
|
|
||||||
**好消息**是你的键盘得救了,在 Go 的世界里不用在每个语句后面加分号了,C 和C++ 程序员听了喜大普奔,键盘不那么容易磨损了。
|
|
||||||
|
|
||||||
**坏消息**带给习惯花括号换行的朋友,在 Go 中第一个花括号 `{` 不能换行写,必须写在同一行,否则编译不过!
|
|
||||||
|
|
||||||
**潜规则**是任何在 Go 中定义的变量必须使用,如果定义了变量不使用,编译不过!
|
|
||||||
|
|
||||||
怎么样?是不是感觉到满满的霸道总裁味道?
|
|
||||||
|
|
||||||
其实约束多了,程序员自由发挥的空间变少,出错的概率也会大大降低,Google 的大佬们怕你犯错,操碎了心。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 包
|
|
||||||
|
|
||||||
### 概念
|
|
||||||
|
|
||||||
Go 语言程序都由包构成,类似其他语言中的模块概念,主程序都从 main 包开始运行。
|
|
||||||
|
|
||||||
所以一个程序开头是下面的语句:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
```
|
|
||||||
|
|
||||||
在程序中也可以导入其他包,这样就可以使用其他包定义的函数或变量。
|
|
||||||
|
|
||||||
### 导入
|
|
||||||
|
|
||||||
导入包语法有多种姿势。
|
|
||||||
|
|
||||||
#### 导入姿势一:单独导入
|
|
||||||
|
|
||||||
```go
|
|
||||||
import os // 导入 os 包
|
|
||||||
import fmt /* 导入 fmt 包*/
|
|
||||||
```
|
|
||||||
|
|
||||||
**fmt 包**:包内有格式化 IO 函数,类似 C 中的 `stdio.h` 和 C++ 中的 `iostream` ,初学者必备,导它!
|
|
||||||
|
|
||||||
**os 包** :中实现了一些 操作系统函数,不依赖平台的接口
|
|
||||||
|
|
||||||
**另外,关于注释,如你所见,完全就是 C 语言里的注释形式,**`//` 或 `/**/ ` 都是允许的。
|
|
||||||
|
|
||||||
#### 导入姿势二:分组导入
|
|
||||||
|
|
||||||
```go
|
|
||||||
import (
|
|
||||||
"fmt"
|
|
||||||
"os"
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
可以把需要的包,用括号放在一起导入。
|
|
||||||
|
|
||||||
#### 导入姿势三:指定别名导入
|
|
||||||
|
|
||||||
可以在导入的时候指定导入包的别名,这样在调用包函数的时候,可以直接使用包别名。
|
|
||||||
|
|
||||||
```go
|
|
||||||
import f "fmt" // 用别名f 代替 fmt
|
|
||||||
f.Println("go go go") // 用 f 代替了 fmt 调用 Println 函数
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 包导出名称约定
|
|
||||||
|
|
||||||
包中定义的函数或变量,如果是大写字母开头,那么它就是可以导出的,外部使用包的用户可以访问到,类似 C++ 中的 `public` 标识。相反,小写字母开头的名字外部无法使用,使用会报错。
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 如下,Println 和 Getenv 都是大写的名字
|
|
||||||
fmt.Println(os.Getenv("GOPATH"))
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 基本类型
|
|
||||||
|
|
||||||
#### 内置类型
|
|
||||||
|
|
||||||
Go 语言内建的数据类型有下面这些,其实基本上看类型名字,就差不多能知道是什么类型了。
|
|
||||||
|
|
||||||
```go
|
|
||||||
int int8 int16 int32 int64
|
|
||||||
uint uint8 uint16 uint32 uint64 uintptr
|
|
||||||
float32 float64 complex128 complex64
|
|
||||||
bool byte rune string error
|
|
||||||
```
|
|
||||||
|
|
||||||
平常用的最多的类型:
|
|
||||||
|
|
||||||
`int` 代表整型,在 32 位系统上通常为 32 位,在 64 位系统上则为 64 位。
|
|
||||||
|
|
||||||
`string` 字符串类型
|
|
||||||
|
|
||||||
`bool` 布尔类型,分 `true` 和 `false` 两种值。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 创建类型
|
|
||||||
|
|
||||||
下面的语法创建一个新的类型,类似C++中的typedef语法。
|
|
||||||
|
|
||||||
`type 新类型名字 底层类型`
|
|
||||||
|
|
||||||
```go
|
|
||||||
type ProgramType string // 定义新类型 ProgramType
|
|
||||||
var t1 ProgramType = "Golang"
|
|
||||||
var t2 ProgramType = "C++"
|
|
||||||
```
|
|
||||||
|
|
||||||
不过Go中创建的新类型即使底层类型是一致的也不能相互操作,**这样起到很好的类型隔离作用**。
|
|
||||||
|
|
||||||
比如下面的代码,虽然`ProgramType` 和 `CompanyType` 都是` string` 类型,但是不能相互操作,下面举例说明:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type ProgramType string // 定义新类型 ProgramType
|
|
||||||
type CompanyType string // 定义新类型 ProgramType
|
|
||||||
var t2, t2 ProgramType = "Golang", "C++"
|
|
||||||
var c1, c2 CompanyType = "Google", "Tencent"
|
|
||||||
fmt.Println(t1+t2) // 同类型相加合法
|
|
||||||
fmt.Println(t1+c1) // 不同类型相加非法
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 类型转换
|
|
||||||
|
|
||||||
不像 C 中有隐式类型转换,**在 Go 中 不同类型的项之间赋值时需要显式转换,否则编译会报错**!语法上,相对于 C 语言的强制转换语法换了下括号的位置,Go 语法如下。
|
|
||||||
|
|
||||||
```
|
|
||||||
T(v) // 把值 v 转换为类型 T
|
|
||||||
```
|
|
||||||
|
|
||||||
举例:
|
|
||||||
|
|
||||||
```go
|
|
||||||
var varint int = 66
|
|
||||||
var varf float32 = float32(varint) // int 转换 float32
|
|
||||||
fmt.Printf("%T %v %T %v \n", varint, varint, varf, varf) // %T输出值的类型 %v输出值
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 变量
|
|
||||||
|
|
||||||
### 声明
|
|
||||||
|
|
||||||
Go 里面的变量声明其实和 C 语言差不多,唯一的区别是把变量类型放在在变量名字后面,另外多了一个 `var` 关键字标识。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar int // 声明了一个 int 类型的 imVar 变量
|
|
||||||
```
|
|
||||||
|
|
||||||
当然也可以多个同类型变量一起声明
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar1, imVar2, imVar3 int // 一口气声明了三个 int 类型的变量
|
|
||||||
```
|
|
||||||
|
|
||||||
或者,多个不同类型的变量声明分组一起声明
|
|
||||||
|
|
||||||
```go
|
|
||||||
var (
|
|
||||||
i int
|
|
||||||
b bool
|
|
||||||
s string
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 初始化
|
|
||||||
|
|
||||||
#### 未初始化
|
|
||||||
|
|
||||||
未初始化的对象会被赋予**零值**,也就是默认值。
|
|
||||||
|
|
||||||
- 数值类型初始值 `0`
|
|
||||||
- 布尔类型初始值 `false`
|
|
||||||
- 字符串为初始值 `""`(空字符串)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 普通初始化
|
|
||||||
|
|
||||||
可以声明之后单个初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar int
|
|
||||||
imVar = 6
|
|
||||||
```
|
|
||||||
|
|
||||||
也可以声明和初始化一步到位
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar0 int = 7
|
|
||||||
```
|
|
||||||
|
|
||||||
还可以批量声明加初始化一步到位
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar4, imVar5 int = 4, 5
|
|
||||||
```
|
|
||||||
|
|
||||||
多个不同类型的变量声明和初始化可以分组同时进行,像下面这样。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var (
|
|
||||||
i int = 1
|
|
||||||
b bool = false
|
|
||||||
s string = "golang"
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 偷懒初始化
|
|
||||||
|
|
||||||
##### 类型自动推导
|
|
||||||
|
|
||||||
如果初始化式右边的值是已存在确定类型的值,可以偷懒省略变量类型,聪明的 Go 会自动推导类型。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var imVar4, imVar5 = 4, 5 // 省略了左边的 int 类型,自动推导imVar4, imVar5是int类型
|
|
||||||
```
|
|
||||||
|
|
||||||
####
|
|
||||||
|
|
||||||
##### 简短初始化
|
|
||||||
|
|
||||||
**在函数内部**,可以使用简短赋值语句` := `来代替 `var` 关键字**声明并初始化**变量。
|
|
||||||
|
|
||||||
```go
|
|
||||||
imVar6, imVar7 := 8, 9 // 声明并初始化了 imVar6, imVar7
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 常量
|
|
||||||
|
|
||||||
常量用 `const` 关键字声明,并且声明之后必须紧接着赋值,常量可以是字符、字符串、布尔值或数值 ,注意:**常量不能用 `:=` 语法声明** 。
|
|
||||||
|
|
||||||
```go
|
|
||||||
const imCnt int = 1 // 带类型的常量定义
|
|
||||||
const imCnt1 = 1 // 省略类型的常量定义,自动推导类型
|
|
||||||
```
|
|
||||||
|
|
||||||
Go 语言内建下面几种常量
|
|
||||||
|
|
||||||
```go
|
|
||||||
true false iota nil // 内建常量
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 函数
|
|
||||||
|
|
||||||
### 声明
|
|
||||||
|
|
||||||
函数用关键字 `func` 来声明,带参数列表,把返回值类型放在最后,下面定义了一个简单的乘法函数,带两个整型参数,返回值也是整型。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func mult(i int, j int) int {
|
|
||||||
return i * j
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
当函数参数类型相同时,可以只写最后一个参数的类型,下面这样简写也是可以的。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func mult(i, j int) int {
|
|
||||||
return i * j
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 返回值
|
|
||||||
|
|
||||||
#### 多返回值
|
|
||||||
|
|
||||||
函数返回值可以是一个,也可以是多个,下面的函数就返回了 `i` 的平凡和 `j` 的平方两个返回值。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func more(i, j int) (int, int) {
|
|
||||||
return i * i, j * j
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 返回值命名
|
|
||||||
|
|
||||||
前面例子只指定了返回值类型,可以指定返回值名称,这样更加便于理解,同时,指定的名称可在函数内使用。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func retName(i, j int) (x, y int) {
|
|
||||||
x = i * i
|
|
||||||
y = j * j
|
|
||||||
return x, y // 可用 return 代替,表示返回所有已命名的返回值。
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
通过本文的学习,我们掌握了 Golang 中的几个基础概念和用法:包、基本数据类型、变量、常量、函数。这些语法基础是Golang 的下层建筑,万丈高楼平地起,本节为后续学习打下了基础。
|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习.
|
|
||||||
|
|
||||||
今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
-----
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**原创不易,不想被白票,如果在我这有收获,就动动手指点个「在看」或给个「转发」是对我持续创作的最大支持。**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
@@ -1,275 +0,0 @@
|
|||||||
对于一般的语言使用者来说 ,20% 的语言特性就能够满足 80% 的使用需求,剩下在使用中掌握。基于这一理论,Go 基础系列的文章不会刻意追求面面俱到,但该有知识点都会覆盖,目的是带你快跑赶上 Golang 这趟新车。
|
|
||||||
|
|
||||||
控制语句是程序的灵魂,有了它们程序才能完成各种逻辑,今天我们就来学习 Go 中的各种控制语句。
|
|
||||||
|
|
||||||
通过本文的学习你将掌握以下知识:
|
|
||||||
|
|
||||||
- if 条件语句
|
|
||||||
- for 循环语句
|
|
||||||
- switch 语句
|
|
||||||
- defer 延迟调用
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## if 条件语句
|
|
||||||
|
|
||||||
与大多数编程语言一样,`if` 用于条件判断,当条件表达式 `expr` 为 `true` 执行 `{}` 包裹的消息体语句,否则不执行。
|
|
||||||
|
|
||||||
语法是这样的:
|
|
||||||
|
|
||||||
```go
|
|
||||||
if expr {
|
|
||||||
// some code
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**注意:**语法上和 `c` 语言不同的是不用在条件表达式 `expr` 外带括号,和 `python` 的语法类似。
|
|
||||||
|
|
||||||
当然,如果想在条件不满足的时候做点啥,就可以 `if` 后带 `else` 语句。语法:
|
|
||||||
|
|
||||||
```go
|
|
||||||
if expr {
|
|
||||||
// some code
|
|
||||||
} else {
|
|
||||||
// another code
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 不仅仅是 if
|
|
||||||
|
|
||||||
除了可以在 `if` 中做条件判断之外,在 Golang 中你甚至可以在 `if` 的条件表达式前执行一个简单的语句。
|
|
||||||
|
|
||||||
举个例子:
|
|
||||||
|
|
||||||
```go
|
|
||||||
if x2 := 1; x2 > 10 {
|
|
||||||
fmt.Println("x2 great than 10")
|
|
||||||
} else {
|
|
||||||
fmt.Println("x2 less than 10", x2)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
上面的例子在 `if` 语句中先声明并赋值了 `x2`,之后对 `x2` 做条件判断。
|
|
||||||
|
|
||||||
**注意:**此处在 `if` 内声明的变量 `x2` 作用域仅限于 if 和else 语句。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## for循环语句
|
|
||||||
|
|
||||||
当需要重复执行的时候需要用到循环语句,**Go 中只有 `for` 这一种循环语句。**
|
|
||||||
|
|
||||||
标准的for循环语法:
|
|
||||||
|
|
||||||
```go
|
|
||||||
for 初始化语句; 条件表达式; 后置语句 {
|
|
||||||
// some code
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这种语法形式和 C 语言中 `for` 循环写法还是很像的,不同的是不用把这三个部分用 `()` 括起来。循环执行逻辑:
|
|
||||||
|
|
||||||
- 初始化语句:初始循环时执行一次,做一些初始化工作,一般是循环变量的声明和赋值。
|
|
||||||
- 条件表达式:在每次循环前对条件表达式求值操作,若求值结果是 `true` 则执行循环体内语句,否则不执行。
|
|
||||||
- 后置语句:在每次循环的结尾执行,一般是做循环变量的自增操作。
|
|
||||||
|
|
||||||
举个例子:
|
|
||||||
|
|
||||||
```go
|
|
||||||
sum := 0
|
|
||||||
for i := 0; i < 10; i++ {
|
|
||||||
sum += i // i作用域只在for语句内
|
|
||||||
fmt.Println(i, sum)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
注意:循环变量` i` 的作用域只在 `for` 语句内,超出这个范围就不能使用了。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### while循环怎么写?
|
|
||||||
|
|
||||||
前面说了,Golang 中只有 `for` 这一种循环语法,那有没有类似 C 语言中 `while` 循环的写法呢?答案是有的:把 `for` 语句的前后两部分省略,只留中间的「条件表达式」的 `for` 语句等价于 `while` 循环。
|
|
||||||
|
|
||||||
像下面这样:
|
|
||||||
|
|
||||||
```go
|
|
||||||
sum1 := 0
|
|
||||||
for ;sum1 < 10; { // 可以省略初始化语句和后置语句
|
|
||||||
sum1++
|
|
||||||
fmt.Println(sum1)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
上面的示例没有初始化语句和后置语句,会循环执行 10 次后退出。
|
|
||||||
|
|
||||||
当然你要是觉得前后的分号也不想写了,也可以省略不写,上面的代码和下面是等效的:
|
|
||||||
|
|
||||||
```go
|
|
||||||
sum1 := 0
|
|
||||||
for sum1 < 10 { // 可以省略初始化语句和后置语句,分号也能省略
|
|
||||||
sum1++
|
|
||||||
fmt.Println(sum1)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
在 Golang 中死循环可以这样写,相当于 C 语言中的 `while(true)`
|
|
||||||
|
|
||||||
```go
|
|
||||||
for { // 死循环
|
|
||||||
// your code
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## switch 语句
|
|
||||||
|
|
||||||
`switch` 语句可以简化多个 `if-else` 条件判断写法,避免代码看起来杂乱。
|
|
||||||
|
|
||||||
可以先定义变量,然后在 `switch` 中使用这个变量。
|
|
||||||
|
|
||||||
```go
|
|
||||||
a := 1
|
|
||||||
switch a {
|
|
||||||
case 1:
|
|
||||||
fmt.Println("case 1") // 不用写break 执行到这自动跳出
|
|
||||||
case 2:
|
|
||||||
fmt.Println("case 2")
|
|
||||||
default:
|
|
||||||
fmt.Printf("unexpect case")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```shell
|
|
||||||
输出:case 1
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
从 C 语言过来的朋友一定有这样的经历:经常会在 case 语句中漏掉 break 导致程序继续往下执行,从而产生奇奇怪怪的 `bug` ,这种问题在 Golang 中不复存在了。Golang 在每个 case 后面隐式提供 `break` 语句。 除非以 `fallthrough` 语句结束,否则分支会自动终止。
|
|
||||||
|
|
||||||
```go
|
|
||||||
switch a := 1; a { //这里有分号
|
|
||||||
case 1: // case 无需为常量,且取值不必为整数。
|
|
||||||
fmt.Println("case 1") // 不用写break 执行到自动跳出 除非以 fallthrough 语句结束
|
|
||||||
fallthrough
|
|
||||||
case 2:
|
|
||||||
fmt.Println("case 2")
|
|
||||||
default:
|
|
||||||
fmt.Printf("unexpect case")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
输出:
|
|
||||||
case 1
|
|
||||||
case 2
|
|
||||||
```
|
|
||||||
|
|
||||||
还可以直接在 `switch` 中定义变量后使用,**但是要注意变量定义之后又分号**,比如下面这样:
|
|
||||||
|
|
||||||
```go
|
|
||||||
switch b :=1; b { //注意这里有分号
|
|
||||||
case 1:
|
|
||||||
fmt.Println("case 1")
|
|
||||||
case 2:
|
|
||||||
fmt.Println("case 2")
|
|
||||||
default:
|
|
||||||
fmt.Printf("unexpect case")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 没有条件的switch
|
|
||||||
|
|
||||||
没有条件的 switch 同 `switch true` 一样,只有当 `case` 中的表达式值为「真」时才执行,这种形式能简化复杂的 `if-else-if else ` 语法。
|
|
||||||
|
|
||||||
下面是用 `if` 来写多重条件判断,这里写的比较简单若是再多几个 `else if` 代码结构看起来会更糟糕。
|
|
||||||
|
|
||||||
```go
|
|
||||||
a := 1
|
|
||||||
if a > 0 {
|
|
||||||
fmt.Println("case 1")
|
|
||||||
} else if a < 0 {
|
|
||||||
fmt.Println("case 2")
|
|
||||||
} else {
|
|
||||||
fmt.Printf("unexpect case")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
如果用上不带条件的 `switch` 语句,写出来就会简洁很多,像下面这样。
|
|
||||||
|
|
||||||
```go
|
|
||||||
a := 1
|
|
||||||
switch { // 相当于switch true
|
|
||||||
case a > 0: // 若表达式为「真」则执行
|
|
||||||
fmt.Println("case 1")
|
|
||||||
case a < 0:
|
|
||||||
fmt.Println("case 2")
|
|
||||||
default:
|
|
||||||
fmt.Printf("unexpect case")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## defer 语句
|
|
||||||
|
|
||||||
`defer` 语句有延迟调用的效果。具体来说`defer`后面的函数调用会被**压入堆栈**,当外层函数返回才会对压栈的函数按后进先出顺序调用。说起来有点抽象,举个例子:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
|
|
||||||
import "fmt"
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
fmt.Println("entry main")
|
|
||||||
for i := 0; i < 6; i++ {
|
|
||||||
defer fmt.Println(i)
|
|
||||||
}
|
|
||||||
fmt.Println("exit main")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
`fmt.Println(i)` 不会每次立即执行,而是在 `main` 函数返回之后才依次调用,编译运行上述程序的输出:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
entry main
|
|
||||||
exit main //外层函数返回
|
|
||||||
5
|
|
||||||
4
|
|
||||||
3
|
|
||||||
2
|
|
||||||
1
|
|
||||||
0
|
|
||||||
```
|
|
||||||
|
|
||||||
上面是简单的使用示例,实际使用中**`defer` 通常用来释放函数内部变量,因为它可以在外层函数 `return` 之后继续执行一些清理动作。**这在文件类操作异常处理中非常实用,比如用于释放文件描述符,我们以后会讲解这块应用,总之先记住 `defer` 延迟调用的特点。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
通过本文的学习,我们掌握了 Golang 中基本的控制流语句,利用这些控制语句加上一节介绍的变量等基础知识,可以构成丰富的程序逻辑,你就能用 Golang 来做一些有意思的事情了。
|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习.
|
|
||||||
|
|
||||||
今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
-----
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**创作不易,白票不是好习惯,如果有收获,动动手指点个「在看」或给个「转发」是对我持续创作的最大支持**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## reference
|
|
||||||
|
|
||||||
[golang中defer的使用规则](https://studygolang.com/articles/10167)
|
|
||||||
|
|
||||||
[GO 匿名函数和闭包](https://segmentfault.com/a/1190000018689134)
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
@@ -1,374 +0,0 @@
|
|||||||
> 对于一般的语言使用者来说 ,20% 的语言特性就能够满足 80% 的使用需求,剩下在使用中掌握。基于这一理论,Go 基础系列的文章不会刻意追求面面俱到,但该有知识点都会覆盖,目的是带你快跑赶上 Golang 这趟新车。
|
|
||||||
|
|
||||||
前面我们学习了 Golang 中基础数据类型,比如内置类型 `int` `string` `bool` 等,还有一些复杂一点点,但很好用的复合类型,类似 C 中的数组和 `struct`、C++ 中的 `map` ,今天我们就来学习 Go 中的复合类型。
|
|
||||||
|
|
||||||
通过本文的学习你将掌握以下知识:
|
|
||||||
|
|
||||||
- 结构体
|
|
||||||
- 指针类型
|
|
||||||
- 数组和切片
|
|
||||||
- 映射类型
|
|
||||||
- 遍历切片和映射
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 结构体
|
|
||||||
|
|
||||||
结构体是一种聚合的数据类型,与 C 中的结构体类似,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员,看例子:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Test struct {
|
|
||||||
a int
|
|
||||||
b int
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
语法上的不同看到了吗? 每个结构体字段之后没有分号(还记得前面文章说过 Go 会自动加分号吧)没有分号写起来还是很舒服的。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 初始化
|
|
||||||
|
|
||||||
可以在定义的时候初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
test := Test{1, 2} // 定义结构体变量并初始化
|
|
||||||
```
|
|
||||||
|
|
||||||
初始化部分结构体字段
|
|
||||||
|
|
||||||
```go
|
|
||||||
t2 = Test{a: 3} //指定赋值Test.a为3 Test.b隐式赋值0
|
|
||||||
```
|
|
||||||
|
|
||||||
隐式初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
t3 = Test{} // .a .b都隐式赋值0
|
|
||||||
```
|
|
||||||
|
|
||||||
多个变量可以分组一起赋值
|
|
||||||
|
|
||||||
```go
|
|
||||||
var (
|
|
||||||
t1 = Test{8, 6}
|
|
||||||
t2 = Test{a: 3} //指定赋值Test.a Test.b隐式赋值0
|
|
||||||
t3 = Test{} // .a .b都隐式赋值0
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 访问成员
|
|
||||||
|
|
||||||
通过 `.` 运算来访问结构体成员,「不区分结构体类型或是结构体指针类型」都可以用 `.` 号来访问。
|
|
||||||
|
|
||||||
```go
|
|
||||||
fmt.Println("struct", st0.a, st0.b) // 通过 . 运算来访问结构体成员
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
对于只声明没赋值的结构体,其内部变量被赋予零值。下面我们声明了 `st0` 但没有对其赋值,成员 a 和 b 自动赋零值。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var st0 Test
|
|
||||||
fmt.Println("struct", st0.a, st0.b) //输出:struct 0 0
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 指针
|
|
||||||
|
|
||||||
指针不保存实际数据的内容,而是保存了指向值的内存地址 。用 `&` 对变量取内存地址,用 `*` 来访问指向的内存,这点和 C 中的指针是一样,唯一不同的是 Go 中的指针不能运算。
|
|
||||||
|
|
||||||
```go
|
|
||||||
a := 3
|
|
||||||
pa := &a // 用 `&` 对变量取内存地址
|
|
||||||
fmt.Println("point", a, *pa) // 用 `*` 来访问指向的内存
|
|
||||||
```
|
|
||||||
|
|
||||||
只声明没赋值的指针值是 `nil` ,代表空指针。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var a0 *int // 只声明没赋值的指针是nil
|
|
||||||
if a0 == nil {
|
|
||||||
fmt.Println("point", "it is nil point")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 数组
|
|
||||||
|
|
||||||
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。 数组可以用下标访问元素,下标从 0 开始。
|
|
||||||
|
|
||||||
数组声明后赋值
|
|
||||||
|
|
||||||
```go
|
|
||||||
var strarr [2]string // 数组声明语法
|
|
||||||
strarr[0] = "ready"
|
|
||||||
strarr[1] = "go"
|
|
||||||
```
|
|
||||||
|
|
||||||
声明赋值同时完成
|
|
||||||
|
|
||||||
```go
|
|
||||||
intarr := [5]int{6, 8, 9, 10, 7} // 声明赋值同时完成
|
|
||||||
```
|
|
||||||
|
|
||||||
对于确定初始值个数的数组,可以省略数组长度用 `...` 代替。
|
|
||||||
|
|
||||||
```go
|
|
||||||
intarr := [...]int{6, 8, 9, 10, 7} // 声明赋值同时完成
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Slice 切片
|
|
||||||
|
|
||||||
切片是变长的序列,序列中每个元素都有相同的类型。`slice` 语法和数组很像,只是没有固定长度而已,「切片底层引用一个数组对象」修改切片会修改原数组。
|
|
||||||
|
|
||||||
通过切片可以访问数组的部分或全部元素,正因为切片长度不是固定的,因此切片比数组更加的常用。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 声明与初始化
|
|
||||||
|
|
||||||
#### 常规初始化
|
|
||||||
|
|
||||||
简短声明并初始化切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
s0 := []int{1, 2, 3, 4, 5, 6} // 简短声明加赋值
|
|
||||||
```
|
|
||||||
|
|
||||||
声明后再初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
var s []int // 声明切片s
|
|
||||||
s = s0 // 用切片s0初始化切片s
|
|
||||||
```
|
|
||||||
|
|
||||||
声明并初始化切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
var s00 []int = s0 // 用切片s0初始化切片s
|
|
||||||
```
|
|
||||||
|
|
||||||
切片的零值是 `nil`
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 切片的零值是nil 空切片长度和容量都是0
|
|
||||||
var nilslice []int
|
|
||||||
if nilslice == nil {
|
|
||||||
fmt.Println("slice", "nilslice is nil ", len(nilslice), cap(nilslice))
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
#### make初始化
|
|
||||||
|
|
||||||
除了上述的常规初始化方法,还可以用 `make` 内置函数来创建切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 内建函数make创建切片,指定切片长度和容量
|
|
||||||
// make 函数会分配一个元素为零值的数组并返回一个引用了它的切片
|
|
||||||
s2 := make([]int, 4, 6) //创建元素都是0的切片s2, 长度为4,容量为6 第三个参数可以省略
|
|
||||||
fmt.Println("slice", len(s2), cap(s2), s2)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 切片长度和容量
|
|
||||||
|
|
||||||
切片长度表示切片中元素的数目,可用内置函数 `len` 函数得到。
|
|
||||||
|
|
||||||
容量表示切片中第一个元素到引用的底层数组结尾所包含元素个数,可用内置函数 `cap` 求得。
|
|
||||||
|
|
||||||
```go
|
|
||||||
s0 := []int{1, 2, 3, 4, 5, 6} // 简短声明加赋值
|
|
||||||
len1, cap1 := len(s0), cap(s0)
|
|
||||||
len2, cap2 := len(s0[:4]), cap(s0[:4])
|
|
||||||
len3, cap3 := len(s0[2:]), cap(s0[2:])
|
|
||||||
fmt.Println("slice", len1, cap1, len2, cap2, len3, cap3) // 6 6 4 6 4 4
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 切片区间
|
|
||||||
|
|
||||||
切片区间遵循「左闭右开」原则,
|
|
||||||
|
|
||||||
```go
|
|
||||||
s0 := [5]int{6, 8, 9, 10, 7} // 数组定义
|
|
||||||
var slice []int = intarr[1:4] // 创建切片slice 包含数组子序列
|
|
||||||
```
|
|
||||||
|
|
||||||
默认上下界。切片下界的默认值为 0,上界默认是该切片的长度。
|
|
||||||
|
|
||||||
```go
|
|
||||||
fmt.Println("slice", s0[:], s0[0:], s0[:5], s0[0:5]) // 这四个切片相同
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 切片append操作
|
|
||||||
|
|
||||||
append 函数用于在切片末尾追加新元素。
|
|
||||||
|
|
||||||
添加元素也分两种情况。
|
|
||||||
|
|
||||||
#### 添加之后长度还在原切片容量范围内
|
|
||||||
|
|
||||||
```go
|
|
||||||
s2 := make([]int, 4, 6) // 创建元素都是0的切片s2, 长度为4,容量为6 第三个参数可以省略
|
|
||||||
s21 := append(s2, 1)
|
|
||||||
s22 := append(s2, 2) // append每次都是在最后添加,此时,s21 s22指向同一个底层数组;但s2不改变!
|
|
||||||
fmt.Println(s2, s21, s22) // [0 0 0 0] [0 0 0 0 2] [0 0 0 0 2]
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
#### 添加元素之后长度超出原切片容量
|
|
||||||
|
|
||||||
此时会分配新的数组空间,并返回指向这个新分配的数组的切片。
|
|
||||||
|
|
||||||
下面例子中 s24 切片已经指向新分配的数组,s22 依然指向的是原来的数组空间,而 s24 已经指向了新的底层数组。
|
|
||||||
|
|
||||||
```go
|
|
||||||
s24 := append(s2, 1, 2, 3)
|
|
||||||
fmt.Println(s24, s22) // s24 [0 0 0 0 1 2 3] [0 0 0 0 2]
|
|
||||||
```
|
|
||||||
|
|
||||||
### 二维切片
|
|
||||||
|
|
||||||
可以定义切片的切片,类似其他语言中的二维数组用法。参考代码:
|
|
||||||
|
|
||||||
```go
|
|
||||||
s3 := [][]int{
|
|
||||||
{1, 1, 1},
|
|
||||||
{2, 2, 2},
|
|
||||||
}
|
|
||||||
fmt.Println(s3, s3[0], len(s3), cap(s3)) // 输出: [[1 1 1] [2 2 2]] [1 1 1] 2 2
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## map 映射类型
|
|
||||||
|
|
||||||
在 Go 中 `map` 是键值对类型,代表 `key` 和` value` 的映射关系,一个 map 就是一个哈希表的引用 。
|
|
||||||
|
|
||||||
### 定义和初始化
|
|
||||||
|
|
||||||
下面这样定义并初始化一个 map 变量
|
|
||||||
|
|
||||||
```go
|
|
||||||
m0 := map[int]string{
|
|
||||||
0: "0",
|
|
||||||
1: "1",
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
也可以用内置 make 函数来初始化一个 map 变量,后续再向其中添加键值对。像下面这样:
|
|
||||||
|
|
||||||
```go
|
|
||||||
m1 := make(map[int]string) // make 函数会返回给定类型的映射,并将其初始化备用
|
|
||||||
if m1 != nil {
|
|
||||||
fmt.Println("map", "m1 is not nil", m1) // m1 不是nil
|
|
||||||
}
|
|
||||||
m1[0] = "1"
|
|
||||||
m1[1] = "2"
|
|
||||||
```
|
|
||||||
|
|
||||||
注意:只声明不初始化的map变量是 `nil` 映射,不能直接拿来用!
|
|
||||||
|
|
||||||
```go
|
|
||||||
var m map[int]string // 未初始化的m零值是nil映射
|
|
||||||
if m == nil {
|
|
||||||
fmt.Println("map", "m is nil", m)
|
|
||||||
}
|
|
||||||
//m[0] = "1" // 这句引发panic异常, 映射的零值为 nil 。nil映射既没有键,也不能添加键。
|
|
||||||
```
|
|
||||||
|
|
||||||
### 元素读取
|
|
||||||
|
|
||||||
使用语法:`vaule= m[key]` 获取键 key 对应的元素 vaule 。
|
|
||||||
|
|
||||||
上面我们只用了一个变量来获取元素,其实这个操作会返回两个值,第一个返回值代表读书的元素,第二个返回值是代表键是否存在的 bool 类型,举例说明:
|
|
||||||
|
|
||||||
```go
|
|
||||||
v, st := m1[0] // v是元素值,下标对应的元素存在st=true 否则st=false
|
|
||||||
_, st1 := m1[0] // _ 符号表示忽略第一个元素
|
|
||||||
v1, _ := m1[0] // _ 符号表示忽略第二个元素
|
|
||||||
fmt.Println(v, st, v1, st1, m1[2]) // m1[2]不存在,返回元素string的零值「空字符」
|
|
||||||
```
|
|
||||||
|
|
||||||
### 删除元素
|
|
||||||
|
|
||||||
内置函数 `delete` 可以删除 map 元素,举例:
|
|
||||||
|
|
||||||
```
|
|
||||||
delete(m1, 1) // 删除键是 1 的元素
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## range 遍历
|
|
||||||
|
|
||||||
range 用于遍历 切片 或 映射。
|
|
||||||
|
|
||||||
### 数组或切片遍历
|
|
||||||
|
|
||||||
当使用` for` 循环和 `range` 遍历数组或切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
|
|
||||||
|
|
||||||
```go
|
|
||||||
s1 := []int{1, 2, 3, 4, 5, 6}
|
|
||||||
for key, vaule := range s1 {
|
|
||||||
fmt.Println("range", key, vaule)
|
|
||||||
}
|
|
||||||
|
|
||||||
for key := range s1 { // 只需要索引,忽略第二个变量即可
|
|
||||||
fmt.Println("range", key)
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, vaule := range s1 { // 只需要元素值,用'_'忽略索引
|
|
||||||
fmt.Println("range", vaule)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### map 遍历
|
|
||||||
|
|
||||||
当使用` for` 循环和 `range` 遍历` map` 时,每次迭代都会返回两个值。第一个值为当前元素 `key` , 第二个值是 `value`。
|
|
||||||
|
|
||||||
```go
|
|
||||||
m0 := map[int]string{
|
|
||||||
0: "0",
|
|
||||||
1: "1",
|
|
||||||
}
|
|
||||||
fmt.Println("map", m0)
|
|
||||||
|
|
||||||
for k, v := range m0 { // range遍历映射,返回key 和 vaule
|
|
||||||
fmt.Println("map", "m0 key:", k, "vaule:", v)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
通过本文的学习,我们掌握了 Golang 中复合类型的学习,这些复合类型代表的数据结构都比较常见,比如切片和数组可以用于模仿队列或堆栈,`map` 的底层实现是 `hash` 表,当然初学者可以不必在意这些底层实现,先用起来已经领先大部分观望者。
|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习.
|
|
||||||
|
|
||||||
今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
-----
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**创作不易,白票不是好习惯,如果有收获,动动手指点个「在看」或给个「转发」是对我持续创作的最大支持**
|
|
||||||
|
|
||||||
##
|
|
||||||
|
|
||||||
@@ -1,368 +0,0 @@
|
|||||||
> 文章每周持续更新,原创不易,「三连」让更多人看到是对我最大的肯定。可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇)
|
|
||||||
|
|
||||||
对于一般的语言使用者来说 ,20% 的语言特性就能够满足 80% 的使用需求,剩下在使用中掌握。基于这一理论,Go 基础系列的文章不会刻意追求面面俱到,但该有知识点都会覆盖,目的是带你快跑赶上 Golang 这趟新车。
|
|
||||||
|
|
||||||
**Hurry up , Let's go !**
|
|
||||||
|
|
||||||
前面我们学习过 Golang 中基础数据类型,比如内置类型 `int` `string` `bool` 等,其实还有一些复杂一点点,但很好用的复合类型,类似 C 中的数组和 `struct`、C++ 中的 `map` ,今天我们就来学习 Go 中的复合类型。
|
|
||||||
|
|
||||||
通过本文的学习你将掌握以下知识:
|
|
||||||
|
|
||||||
- 结构体
|
|
||||||
- 指针类型
|
|
||||||
- 数组和切片
|
|
||||||
- 映射类型
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 指针
|
|
||||||
|
|
||||||
指针不保存实际数据的内容,而是保存了指向值的内存地址 。用 `&` 对变量取内存地址,用 `*` 来访问指向的内存。这点和 C 中的指针是一样,唯一不同的是 Go 中的指针不能运算。
|
|
||||||
|
|
||||||
```go
|
|
||||||
a := 3
|
|
||||||
pa := &a // 用 `&` 对变量取内存地址
|
|
||||||
fmt.Println("point", a, *pa) // 用 `*` 来访问指向的内存
|
|
||||||
```
|
|
||||||
|
|
||||||
只声明没赋值的指针值是 `nil` ,代表空指针。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var a0 *int // 只声明没赋值的指针是nil
|
|
||||||
if a0 == nil {
|
|
||||||
fmt.Println("point", "it is nil point")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 结构体
|
|
||||||
|
|
||||||
与C中的结构体类似, 结构体是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员,看例子:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Test struct {
|
|
||||||
a int
|
|
||||||
b int
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
语法上的不同看到了吗? 每个结构体字段之后没有分号,没有分号写起来还是很舒服的。
|
|
||||||
|
|
||||||
### 初始化
|
|
||||||
|
|
||||||
可以在定义的时候初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
test := Test{1, 2} // 定义结构体变量并初始化
|
|
||||||
```
|
|
||||||
|
|
||||||
初始化部分结构体字段
|
|
||||||
|
|
||||||
```go
|
|
||||||
t2 = Test{a: 3} //指定赋值Test.a为3 Test.b隐式赋值0
|
|
||||||
```
|
|
||||||
|
|
||||||
隐式初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
t3 = Test{} // .a .b都隐式赋值0
|
|
||||||
```
|
|
||||||
|
|
||||||
多个变量可以分组一起赋值
|
|
||||||
|
|
||||||
```go
|
|
||||||
var (
|
|
||||||
t1 = Test{8, 6}
|
|
||||||
t2 = Test{a: 3} //指定赋值Test.a Test.b隐式赋值0
|
|
||||||
t3 = Test{} // .a .b都隐式赋值0
|
|
||||||
pt4 = &Test{8, 6} // 指针
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 访问成员
|
|
||||||
|
|
||||||
通过 `.` 运算来访问结构体成员,不区分结构体类型或是结构体指针类型。
|
|
||||||
|
|
||||||
```go
|
|
||||||
fmt.Println("struct", st0.a, st0.b) // 通过 . 运算来访问结构体成员
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
对于只声明没赋值的结构体,其内部变量被赋予零值,下面我们声明了 `st0` 但没有对其赋值。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var st0 Test
|
|
||||||
fmt.Println("struct", st0.a, st0.b) //输出:struct 0 0
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 数组
|
|
||||||
|
|
||||||
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。 数组可以用下标访问元素,下标从 0 开始。
|
|
||||||
|
|
||||||
数组声明后赋值
|
|
||||||
|
|
||||||
```go
|
|
||||||
var strarr [2]string // 数组声明语法
|
|
||||||
strarr[0] = "ready"
|
|
||||||
strarr[1] = "go"
|
|
||||||
```
|
|
||||||
|
|
||||||
声明赋值同时完成
|
|
||||||
|
|
||||||
```go
|
|
||||||
intarr := [5]int{6, 8, 9, 10, 7} // 声明赋值同时完成
|
|
||||||
```
|
|
||||||
|
|
||||||
对于确定初始值个数的数组,可以省略数组长度
|
|
||||||
|
|
||||||
```go
|
|
||||||
intarr := [...]int{6, 8, 9, 10, 7} // 声明赋值同时完成
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Slice 切片
|
|
||||||
|
|
||||||
切片是变长的序列,序列中每个元素都有相同的类型。`slice` 语法和数组很像,只是没有固定长度而已,切片底层引用一个数组对象,修改切片会修改原数组。
|
|
||||||
|
|
||||||
通过切片可以访问数组的部分或全部元素,正因为切片长度不是固定的,因此切片比数组更加的常用。
|
|
||||||
|
|
||||||
### 声明与初始化
|
|
||||||
|
|
||||||
#### 常规初始化
|
|
||||||
|
|
||||||
简短声明并初始化切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
s0 := []int{1, 2, 3, 4, 5, 6} // 简短声明加赋值
|
|
||||||
```
|
|
||||||
|
|
||||||
声明后再初始化
|
|
||||||
|
|
||||||
```go
|
|
||||||
var s []int // 声明切片s
|
|
||||||
s = s0 // 用切片s0初始化切片s
|
|
||||||
```
|
|
||||||
|
|
||||||
声明并初始化切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
var s00 []int = s0 // 用切片s0初始化切片s
|
|
||||||
```
|
|
||||||
|
|
||||||
切片的零值是 `nil`
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 切片的零值是nil 空切片长度和容量都是0
|
|
||||||
var nilslice []int
|
|
||||||
if nilslice == nil {
|
|
||||||
fmt.Println("slice", "nilslice is nil ", len(nilslice), cap(nilslice))
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
#### make初始化
|
|
||||||
|
|
||||||
除了上述的常规初始化方法,还可以用 `make` 内置函数来创建切片
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 内建函数make创建切片,指定切片长度和容量
|
|
||||||
// make 函数会分配一个元素为零值的数组并返回一个引用了它的切片
|
|
||||||
s2 := make([]int, 4, 6) //创建元素都是0的切片s2, 长度为4,容量为6 第三个参数可以省略
|
|
||||||
fmt.Println("slice", len(s2), cap(s2), s2)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 切片长度
|
|
||||||
|
|
||||||
长度表示切片中元素的数目,可用内置函数 `len` 函数得到。
|
|
||||||
|
|
||||||
#### 切片容量
|
|
||||||
|
|
||||||
容量表示切片中第一个元素到引用的底层数组结尾所包含元素个数,可用内置函数 `cap` 求得。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 切片区间
|
|
||||||
|
|
||||||
切片区间遵循「左闭右开」原则,
|
|
||||||
|
|
||||||
```go
|
|
||||||
s0 := [5]int{6, 8, 9, 10, 7} // 数组定义
|
|
||||||
var slice []int = intarr[1:4] // 创建切片slice 包含数组子序列
|
|
||||||
```
|
|
||||||
|
|
||||||
默认上下界。切片下界的默认值为 0,上界默认是该切片的长度。
|
|
||||||
|
|
||||||
```go
|
|
||||||
fmt.Println("slice", s0[:], s0[0:], s0[:5], s0[0:5]) // 这四个切片相同
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 切片append操作
|
|
||||||
|
|
||||||
append 函数用于在切片末尾追加新元素。
|
|
||||||
|
|
||||||
添加元素也分两种情况。
|
|
||||||
|
|
||||||
#### 添加之后长度还在原切片容量范围内
|
|
||||||
|
|
||||||
```go
|
|
||||||
s2 := make([]int, 4, 6) //创建元素都是0的切片s2, 长度为4,容量为6 第三个参数可以省略
|
|
||||||
s22 := append(s2, 2) // append每次都是在最后添加,所以此时,s21 s22指向同一个底层数组
|
|
||||||
fmt.Println(s21, s22) // [0 0 0 0 2] [0 0 0 0 2]
|
|
||||||
```
|
|
||||||
#### 添加元素之后长度超出原切片容量
|
|
||||||
|
|
||||||
此时会分配新的数组空间,并返回指向这个新分配的数组的切片。
|
|
||||||
|
|
||||||
下面例子中 s24 切片已经指向新分配的数组,s22 依然指向的是原来的数组空间,而 s24 已经指向了新的底层数组。
|
|
||||||
|
|
||||||
```go
|
|
||||||
s24 := append(s2, 1, 2, 3)
|
|
||||||
fmt.Println(s24, s22) // s24 [0 0 0 0 1 2 3] [0 0 0 0 2]
|
|
||||||
```
|
|
||||||
|
|
||||||
### 二维切片
|
|
||||||
|
|
||||||
可以定义切片的切片,类似其他语言中的二维数组用法。参考代码:
|
|
||||||
|
|
||||||
```go
|
|
||||||
s3 := [][]int{
|
|
||||||
{1, 1, 1},
|
|
||||||
{2, 2, 2},
|
|
||||||
}
|
|
||||||
fmt.Println(s3, s3[0], len(s3), cap(s3)) // 输出: [[1 1 1] [2 2 2]] [1 1 1] 2 2
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## map 映射类型
|
|
||||||
|
|
||||||
在 Go 中 `map` 是键值对类型,代表 `key` 和` value` 的映射关系,一个map就是一个哈希表的引用 。
|
|
||||||
|
|
||||||
### 定义和初始化
|
|
||||||
|
|
||||||
下面这样定义并初始化一个 map 变量
|
|
||||||
|
|
||||||
```go
|
|
||||||
m0 := map[int]string{
|
|
||||||
0: "0",
|
|
||||||
1: "1",
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
也可以用内置 make 函数来初始化一个 map 变量,后续再向其中添加键值对。像下面这样:
|
|
||||||
|
|
||||||
```go
|
|
||||||
m1 := make(map[int]string) // make 函数会返回给定类型的映射,并将其初始化备用
|
|
||||||
if m1 != nil {
|
|
||||||
fmt.Println("map", "m1 is not nil", m1) // m1 不是nil
|
|
||||||
}
|
|
||||||
m1[0] = "1"
|
|
||||||
m1[1] = "2"
|
|
||||||
```
|
|
||||||
|
|
||||||
注意:只声明不初始化的map变量是 `nil` 映射,不能直接拿来用!
|
|
||||||
|
|
||||||
```go
|
|
||||||
var m map[int]string // 未初始化的m零值是nil映射
|
|
||||||
if m == nil {
|
|
||||||
fmt.Println("map", "m is nil", m)
|
|
||||||
}
|
|
||||||
//m[0] = "1" // 这句引发panic异常, 映射的零值为 nil 。nil映射既没有键,也不能添加键。
|
|
||||||
```
|
|
||||||
|
|
||||||
### 元素读取
|
|
||||||
|
|
||||||
使用语法:`vaule= m[key]` 获取键 key 对应的元素 vaule 。
|
|
||||||
|
|
||||||
上面我们只用了一个变量来获取元素,其实这个操作会返回两个值,第一个返回值代表读书的元素,第二个返回值是代表键是否存在的 bool 类型,举例说明:
|
|
||||||
|
|
||||||
```go
|
|
||||||
v, st := m1[0] // v是元素值,下标对应的元素存在st=true 否则st=false
|
|
||||||
_, st1 := m1[0] // _ 符号表示忽略第一个元素
|
|
||||||
v1, _ := m1[0] // _ 符号表示忽略第二个元素
|
|
||||||
fmt.Println(v, st, v1, st1, m1[2]) // m1[2]不存在,返回元素string的零值「空字符」
|
|
||||||
```
|
|
||||||
|
|
||||||
### 删除元素
|
|
||||||
|
|
||||||
内置函数 `delete` 可以删除 map 元素,举例:
|
|
||||||
|
|
||||||
```
|
|
||||||
delete(m1, 1) // 删除键是 1 的元素
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## range 遍历
|
|
||||||
|
|
||||||
range 用于遍历 切片 或 映射。
|
|
||||||
|
|
||||||
### 数组或切片遍历
|
|
||||||
|
|
||||||
当使用` for` 循环和 `range` 遍历数组或切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
|
|
||||||
|
|
||||||
```go
|
|
||||||
s1 := []int{1, 2, 3, 4, 5, 6}
|
|
||||||
for key, vaule := range s1 {
|
|
||||||
fmt.Println("range", key, vaule)
|
|
||||||
}
|
|
||||||
|
|
||||||
for key := range s1 { // 只需要索引,忽略第二个变量即可
|
|
||||||
fmt.Println("range", key)
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, vaule := range s1 { // 只需要元素值,用'_'忽略索引
|
|
||||||
fmt.Println("range", vaule)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### map 遍历
|
|
||||||
|
|
||||||
当使用` for` 循环和 `range` 遍历` map` 时,每次迭代都会返回两个值。第一个值为当前元素 `key` , 第二个值是 `value`。
|
|
||||||
|
|
||||||
```go
|
|
||||||
m0 := map[int]string{
|
|
||||||
0: "0",
|
|
||||||
1: "1",
|
|
||||||
}
|
|
||||||
fmt.Println("map", m0)
|
|
||||||
|
|
||||||
for k, v := range m0 { // range遍历映射,返回key 和 vaule
|
|
||||||
fmt.Println("map", "m0 key:", k, "vaule:", v)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
通过本文的学习,我们掌握了 Golang 中基本的控制流语句,利用这些控制语句加上一节介绍的变量等基础知识,可以构成丰富的程序逻辑,你就能用 Golang 来做一些有意思的事情了。
|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习.
|
|
||||||
|
|
||||||
今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
-----
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**创作不易,白票不是好习惯,如果在我这有收获,动动手指「点赞」「关注」是对我持续创作的最大支持。**
|
|
||||||
|
|
||||||
> 可以微信搜索公众号「 后端技术学堂 」回复「资料」「1024」有我给你准备的各种编程学习资料。文章每周持续更新,我们下期见!
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
@@ -1,326 +0,0 @@
|
|||||||
> 对于一般的语言使用者来说 ,20% 的语言特性就能够满足 80% 的使用需求,剩下在使用中掌握。基于这一理论,Go 基础系列的文章不会刻意追求面面俱到,但该有知识点都会覆盖,目的是带你快跑赶上 Golang 这趟新车。
|
|
||||||
|
|
||||||
最近工作上和生活上的事情都很多,这篇文章计划是周末发的,但是周末太忙时间不够,同时为了保证文章质量,反复修改到现在才算完成。
|
|
||||||
|
|
||||||
有时候还是很想回到学校,一心只用读书睡觉打游戏的日子,成年人的世界总是被各种中断,有各种各样的事情要处理。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**答应大家要写完的 Go 基础系列可能会迟到,但不会缺席。今天我们来继续学习,Go 中的面向对象编程思想,包括 方法 和 接口 两大部分学习内容。**
|
|
||||||
|
|
||||||
通过学习本文,你将了解:
|
|
||||||
|
|
||||||
- Go 的方法定义
|
|
||||||
- 方法和函数的区别
|
|
||||||
- 方法传值和传指针差异
|
|
||||||
- 什么是接口类型
|
|
||||||
- 如何判断接口底层值类型
|
|
||||||
- 什么是空接口
|
|
||||||
- nil 接口 和nil 底层值
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
如果你使用 C++ 或 Java 这类面向对象的语言,肯定知道类 `class` 和方法 `method` 的概念,Golang 中没有` class `关键字,但有上节介绍的 `struct` 结构体提供类似功能,配合方法和接口的支持,完成面向对象的程序设计完全没有问题,下面我们就来学习下方法和接口。
|
|
||||||
|
|
||||||
## 方法
|
|
||||||
|
|
||||||
### 定义
|
|
||||||
|
|
||||||
方法就是一类带特殊的接收者参数的函数 ,这些特殊的参数可以是结构体也可以是结构体指针,但不能是内置类型。
|
|
||||||
|
|
||||||
为了便于说明,先来定义一个结构体 `Person` 包含` name `和 `age` 属性。
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Person struct {
|
|
||||||
name string
|
|
||||||
age int
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
下面给 `Person` 定义两个方法,分别用于获取` name `和` age ` ,重点看下代码中方法的定义语法。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (p Person) GetName() string {
|
|
||||||
return p.name + "'s age is"
|
|
||||||
}
|
|
||||||
|
|
||||||
func (p Person) GetAge() int {
|
|
||||||
return p.age
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 和函数定义的区别
|
|
||||||
|
|
||||||
看了上面的方法定义是不是觉得和函数定义有点类似,还记得函数的定义吗?为了唤起你的记忆,下面分别定义两个相同功能的函数,大家可以对比一下。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func GetNameF(p Person) string {
|
|
||||||
return p.name + "'s age is"
|
|
||||||
}
|
|
||||||
|
|
||||||
func GetNameF(p Person) int {
|
|
||||||
return p.age
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
除了定义上的区别,还有调用上的区别。下面示例代码演示了两种调用方式的不同,在`fmt.Println` 中前面 2 个是正常函数调用,后面 2 个是方法调用,就是用点号`.` 和括号`()` 的区别。
|
|
||||||
|
|
||||||
```go
|
|
||||||
p := Person{"lemon", 18}
|
|
||||||
fmt.Println(GetNameF(p), GetNameF(p), p.GetName(), p.GetAge())
|
|
||||||
//输出 lemon's age is 18 lemon's age is 18
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 修改接收者的值
|
|
||||||
|
|
||||||
上面我演示的方法 `GetName` 和`GetAge` 的接收者是` Person `值,这种值传递方式是没办法修改接收者内部状态的,比如你没法通过方法调用修改 `Person `的` name` 或`age `。
|
|
||||||
|
|
||||||
假设有个需求要修改用户年龄,我们像下面这样定义方法 `ageWriteable` ,调用该方法之后 `p` 的 `name` 属性并不会变化。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (p *Person) ageWriteable() int {
|
|
||||||
p.age += 10
|
|
||||||
return p.age
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
那要怎么才能实现对 `p` 的修改呢? 没错用 `*Person` 指针类型即可实现修改。类比 `C++` 中用指针或引用来理解。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (p *Person) ageWriteable() int {
|
|
||||||
p.age += 10
|
|
||||||
return p.age
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 隐式值与指针转换
|
|
||||||
|
|
||||||
Golang 非常的聪明,为了不让你麻烦,它能自动识别方法的实际接收者类型(指针或值),并默默的帮你做转换,以便「方法」能正确的工作。
|
|
||||||
|
|
||||||
还是用我们上面定义的方法举例,先来看以「值」作为接收者的方法调用。方便阅读,我把前面的定义再写一遍。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (p Person) GetName() string {
|
|
||||||
return p.name + "'s age is"
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
对于这个定义的方法,按下面的调用方式 `p `和 `pp` 都能调用 `GetName` 方法。
|
|
||||||
|
|
||||||
怎么做到的呢?原来 `pp` 在调用方法时 Go 默默的做了隐式的转换,其实是按照 `(*pp).GetName*()` 去调用方法,怎么实现转换的这点我们不用关心,先用起来就可以。
|
|
||||||
|
|
||||||
```go
|
|
||||||
p := Person{"lemon", 18}
|
|
||||||
pp := &Person{"lemon", 18}
|
|
||||||
fmt.Println(p.GetName(), pp.GetName()) // p 和 pp都能调用 GetName 方法
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**同理,对接收者是指针的方法,也可以按给它传递值的方式来调用,这里不再赘述。**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
对方法的说明,就简单介绍到这里,更多细节不去深究,留给大家在使用中学习。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 接口
|
|
||||||
|
|
||||||
接口我想不到准确的描述语句来说明他,通俗来讲接口类型就是一类预先约定好的方法声明集合。
|
|
||||||
|
|
||||||
接口定义就是把一系列可能实现的方法先声明出来,后面只要哪个类型完全实现了某个接口声明的方法,就可用这个「接口变量」来保存这些方法的值,其实是抽象设计的概念。
|
|
||||||
|
|
||||||
**可以类比 `C++` 中的纯虚函数。**
|
|
||||||
|
|
||||||
### 定义
|
|
||||||
|
|
||||||
为了说明接口如何定义,我们要做一些准备工作。
|
|
||||||
|
|
||||||
1. 先来定义两个类型,代表男人女人,他们都有属性 `name` 和 `age`
|
|
||||||
|
|
||||||
```go
|
|
||||||
type man struct {
|
|
||||||
name string
|
|
||||||
age int
|
|
||||||
}
|
|
||||||
|
|
||||||
type woman struct {
|
|
||||||
name string
|
|
||||||
age int
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
2. 再来分别定义两个类型的方法,`getName` 和 `getAge` 用于获取各自的姓名和年龄。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (m *man) getName() string {
|
|
||||||
return m.name
|
|
||||||
}
|
|
||||||
|
|
||||||
func (m *woman) getName() string {
|
|
||||||
return m.name
|
|
||||||
}
|
|
||||||
|
|
||||||
func (m *man) getAge() int {
|
|
||||||
return m.age
|
|
||||||
}
|
|
||||||
|
|
||||||
func (m *woman) getAge() int {
|
|
||||||
return m.age
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
好了, 下面我们的主角「接口」登场, 我们来实现一个通用的 `humanIf` 接口类型,这个接口包含了 `getName()` 方法声明,注意接口包含的这个方法的声明样式,和前面我们定义的 `man` 与 `women` 的 `getName` 方法一致。同理 `getAge()`样式也一致。
|
|
||||||
|
|
||||||
```go
|
|
||||||
type humanIf interface {
|
|
||||||
getName() string
|
|
||||||
getAge() int
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**现在可以使用这个接口了!不管男人女人反正都是人,是人就可以用我的 `humanIf` 接口获取姓名。**
|
|
||||||
|
|
||||||
```go
|
|
||||||
var m humanIf = &man{"lemon", 18}
|
|
||||||
var w humanIf = &woman{"hanmeimei", 19}
|
|
||||||
fmt.Println(m.getName(), w.getName())
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 接口类型
|
|
||||||
|
|
||||||
当给定一个接口值,我们如何知道他代表的底层值的具体类型呢?还是上面的例子,我们拿到了 `humanIf` 类型的变量 `m ` 和 `w`, 怎么才能知道它们到底是 `man` 还是 `women `类型呢?
|
|
||||||
|
|
||||||
有两种方法可以确定变量 `m ` 和 `w` 的底层值类型。
|
|
||||||
|
|
||||||
- 类型断言
|
|
||||||
|
|
||||||
断言如果不是预期的类型,就会抛出 `panic `异常,程序终止。
|
|
||||||
|
|
||||||
如果断言是符合预期的类型,会把调用者实际的底层值返回。
|
|
||||||
|
|
||||||
```go
|
|
||||||
v0 := w.(man) // w保存的不是 man 类型,程序终止
|
|
||||||
|
|
||||||
v1 := m.(man) // m保存的符合 man 类型,v1被赋值 m 的底层值
|
|
||||||
|
|
||||||
v, right := a.(man) // 两个返回值,第一个是值,第二代表是否断言正确的布尔值
|
|
||||||
fmt.Println(v, right)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- 类型选择
|
|
||||||
|
|
||||||
相比类型断言直接粗暴的让程序终止,「类型选择」语法更加的温和,即使类型不符合也不会让程序挂掉。
|
|
||||||
|
|
||||||
下面示例,`v3` 获得 `w` 的底层类型,在后面 `case` 通过类型比较打印出匹配的类型。注意:`type` 也是关键字。
|
|
||||||
|
|
||||||
```go
|
|
||||||
|
|
||||||
switch v3 := w.(type) {
|
|
||||||
case man:
|
|
||||||
fmt.Println("it is type:man", v3)
|
|
||||||
case women:
|
|
||||||
fmt.Println("it is type:women", v3)
|
|
||||||
default:
|
|
||||||
fmt.Printf("unknow type:%T value:%v", v3, v3)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 空接口
|
|
||||||
|
|
||||||
空接口 `interface{}` 代表包含了 0 个方法的接口,试想一下每个类型都至少实现了零个方法,所以任何类型都可以给空接口类型赋值。
|
|
||||||
|
|
||||||
下面示例,用 `man` 值给空接口赋值。
|
|
||||||
|
|
||||||
```go
|
|
||||||
type nilIf interface{}
|
|
||||||
var ap nilIf = &man{"lemon", 18}
|
|
||||||
|
|
||||||
//等价定义
|
|
||||||
var ap interface{} = &man{"lemon", 18} //等价于上面一句
|
|
||||||
```
|
|
||||||
|
|
||||||
空接口可以接收任何类型的值,包括指针、值甚至是`nil` 值。
|
|
||||||
|
|
||||||
```go
|
|
||||||
// 接收指针
|
|
||||||
var ap nilIf = &man{"lemon", 18}
|
|
||||||
fmt.Println("interface", ap)
|
|
||||||
// 接收值
|
|
||||||
var a nilIf = man{"lemon", 18}
|
|
||||||
fmt.Println("interface", a)
|
|
||||||
// 接收nil值
|
|
||||||
var b nilIf
|
|
||||||
fmt.Println("interface", b)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 处理nil接口调用
|
|
||||||
|
|
||||||
#### nil底层值不会引发异常
|
|
||||||
|
|
||||||
对 C 或 C++ 程序员来说空指针是噩梦,如果对空指针做操作,结果是不可预知的,很大概率会导致程序崩溃,程序莫名其妙挂掉,想想就令人头秃。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
`Golang` 中处理空指针这种情况要优雅的多,**允许用空底层值调用接口**,但是要修改方法定义,正确处理 `nil` 值避免程序崩溃。
|
|
||||||
|
|
||||||
```go
|
|
||||||
func (m *man) getName() string {
|
|
||||||
if m == nil {
|
|
||||||
return "nil"
|
|
||||||
}
|
|
||||||
|
|
||||||
return m.name
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
下面演示了使用处理了 `nil` 值的方法,虽然 `nilMan` 是空指针,但仍然可以调用 `getName` 方法。
|
|
||||||
|
|
||||||
```go
|
|
||||||
var nilMan *man // 定义了一个空指针 nilMan
|
|
||||||
var w humanIf = nilMan
|
|
||||||
fmt.Println(w.getName())
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### nil接口引发程序异常
|
|
||||||
|
|
||||||
但是,如果接口本身是 `nil` 去调用方法,仍然会引发异常。
|
|
||||||
|
|
||||||
```go
|
|
||||||
manIf = nil
|
|
||||||
fmt.Println("interface", manIf.getName())
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
本节学习的接口和方法是 `Golang` 对面向对象程序设计的支持,可以看到实现的非常简洁,并没常用的面向对象语言那么复杂的语法和关键字,简单不代表不够好,实际上也基本够用,一句话概括就是简洁并不简单。
|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。
|
|
||||||
|
|
||||||
今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
-----
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**创作不易,白票不是好习惯,如果有收获,动动手指点个「在看」或给个「转发」是对我持续创作的最大支持**
|
|
||||||
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 44 KiB |
@@ -1 +0,0 @@
|
|||||||
<mxfile host="www.draw.io" modified="2020-04-04T05:12:44.687Z" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36" etag="0QQPTuLyxyjdipbyQvt5" version="12.9.3"><diagram id="xuCw2JCyBRWVYkc-B2Wk" name="Page-1">7VrLkps4FP0alu0CBBgvjdtJFkmqq3pqZjmFQTaqCESE6HbP148EEgaBH3SwnUq1N0ZXb52je48EBlil+880zJNvJIbYsM14b4BHw7Yt33P5n7C81RbX8WvDjqJYFjoYntF/UBpNaS1RDItOQUYIZijvGiOSZTBiHVtIKXntFtsS3O01D3ewZ3iOQty3/oNiltRW354f7F8g2iWqZ8tb1DlpqArLmRRJGJPXlgmsDbCihLD6Kd2vIBaLp9alrvfpSG4zMAozdkmFr/HT6/O/8x0GPwH4O/nrm0m+P8hWXkJcygnLwbI3tQIFo+RHM3nHAEEzE5Mn4rBIYCwTIUa7jD9HfEyQckPCUszTVl0rF02m+52gyiwl0Y8yn1FawRZQib0l2tkijFcEE1oNAWyrn2ijGksrxzQXC+eR5/RXQ00NUgb3LZNcnc+QpJDRN15E5SqkJFWBSr8egHdNaUvaoDvSGEqy7Zq2D3jwBwnJCHjsAXg8LJZrS/g8Be3VUng/S8GkoFoU04yitsnbyf8wzflDtinyKm1OalrPjWBpBJ/Ew9I3/MBSo+WTrwesBjLIMYUryhJIEdN4cLBy/sSI49zP6XLVujZXTQmEou5cplsE9aqfKidnLLqgsOC1Gt9hDXL45J49T+wWcS3rFHEpxCFDL12fN8Rm2ccTQRX9mp3jdquQ7baArEf/Zmjv3xFg2h3Ro6z9QdnfhrKmez3K2sC6FWXdPmXXvuDcImhodybqTk4LDLcsKBkjWS/0niZHE4p1cmgh2zT96FjIljm3ppN9DTpdnz7KcZ/SaFFJXyo6iEWEWbwUylcwAodFgSKNEn1EPG+16vkiezQgMO6I6ZNwuAPxyJ1ob7tdIdcIO9VEQUoaQVmrLZn1hrxuQ3o7LKQ7yHrt8NUP31rFclGgODHeuTZe0zw9LKdb3u0U5w/1ACZlofdBwpGayJuIhNb8JiS0/HEktNzbkxBc4ArvqctEVP0jVZnMBQqA1hZajD0Q312PgaFLj84Z4kAndWAQGQ9Fhc6SF7Dm+b59mhh9Dq962xw/hoDWMWSj1zt3NOFoajTsKUSBOYpCvJQZKYpjUb1mU7jBipXSbfB23cBwxU1LWDJSSJ5ek2ua//T61PMGqKd7x+muYvyPCDhuS4OpZJhOhStFQDBShoE7yDB7MTYCti9Jfy0G2pPfTQjKvesU+mvBcLQvcjWkh26G/cUkcfChkXs3CIRD18v3c2m/l/dyNafj6Fhe6r1cza0AvaGJ3JerCXhHfx+kl9fcs3J/11Xwx+9vN+8RXl1hNM0VsHNUZw1JsrPaS1dUmn66XJr1pVjbn2ckg70tKI2UlFnceOopHKLOaf/O6gw4F8RFLQpFqIjIrIDcwdFixtcS1s9d+KpVh3T9AuvFt/TAp198As9fzIecofYWs+0MFeZfww3ET5weDImY+LghPDimA6RgJB/iDikZRhnvVL0MnwjvBx3vATU+H8B7cS28lQ89hXdXgFwqW45uP50+9dcF9kz0iAqoImNQfelgzoQ6qT6DcEQ3GWFRdY/gCsbAkCWiM17MGWIK4ALHNMeFzRHvuc/vXWvoNbfrjgaTJw8fONQx5PCZCFj/Dw==</diagram></mxfile>
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 333 KiB |
@@ -1,154 +0,0 @@
|
|||||||
工作5年,资深程序员总结:分析Linux进程的6个方法,我全都告诉你
|
|
||||||
|
|
||||||
> 创作不易,点赞关注支持一下吧,我的更多原创技术分享,关注公众号「**后端技术学堂**」第一时间看!
|
|
||||||
|
|
||||||
操作系统「进程」是学计算机都要接触的基本概念,抛开那些纯理论的操作系统底层实现,在Linux下做软件开发这么多年,每次程序运行出现问题,都要一步一步分析进程各种状态,去排查问题出在哪里,这次lemon带你在Linux环境下实操,一步步探究揭开「Linux进程」的那些秘密。
|
|
||||||
|
|
||||||
## 何为进程
|
|
||||||
|
|
||||||
首先我们说下「程序」的概念,程序是一些保存在磁盘上的指令的有序集合,是静态的。进程是程序执行的过程,包括了动态创建、调度和消亡的整个过程,它是程序资源管理的最小单位。
|
|
||||||
|
|
||||||
线程是操作操作系统能够进行运算调度的最小单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位,一个进程内可以包含多个线程,是资源调度的最小单位。[引用维基百科]
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
> 探究进程第一步,你在吗?还好吗?
|
|
||||||
|
|
||||||
## ps
|
|
||||||
|
|
||||||
`report a snapshot of the current processes.` 列出当前系统进程的快照。
|
|
||||||
|
|
||||||
找到进程PID ( Process IDentity ),pid唯一标识一个进程。用`ps`这个命令,这个命令大家应该都知道吧,对于小白用户,首先他不是Photoshop。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
给大家简单介绍一下,一般用法是`ps -ef`列出系统内经常信息,通常都会带管道`grep`出自己感兴趣的进程,像这样`ps -ef|grep intresting`第一列PID代表进程号,PPID(parent process ID)代表父进程号。
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
> 探究进程第二步,让我看看你都交了哪些朋友(系统调用 & 信号)
|
|
||||||
|
|
||||||
## strace
|
|
||||||
|
|
||||||
`trace system calls and signals` 跟踪进程内部的系统调用和信号
|
|
||||||
|
|
||||||
> 什么是「系统调用」?系统调用(system call),指运行在「用户态」的程序向操作系统「内核态」请求需要更高权限运行的服务,系统调用提供用户程序与操作系统之间的接口。
|
|
||||||
|
|
||||||
`strace`后面跟着启动一个进程,可以跟踪启动后进程的系统调用和信号,这个命令可以看到进程执行时候都调用了哪些系统调用,通过指定不同的选项可以输出系统调用发生的时间,精度可以精确到微秒,甚至还可以统计分析系统「调用的耗时」,这在排查进程假死问题的时候很有用,能帮你发现进程卡在哪个系统调用上。已经在运行的进程也可以指定`-p`参数加`pid`像`gdb attach`那样附着上去跟踪。
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
> 探究进程第三步,让我看看你带的小弟们(线程)。
|
|
||||||
|
|
||||||
## pstack
|
|
||||||
|
|
||||||
`print a stack trace of a running process` 打印出运行中程序的堆栈信息。
|
|
||||||
|
|
||||||
执行命令`pstack pid` 你能看到当前线程运行中的堆栈信息,其中的pid可用之前的`ps`命令获得,`pstack`可以看到进程内启动的线程号,每个进程内线程的「堆栈」内容也能看到。
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
看到上面打印出的LWP了吗,这里是个知识点, LPW是指`Light-weight process` 轻量级线程。引申知识:
|
|
||||||
|
|
||||||
> 1. Linux中没有真正的线程
|
|
||||||
> 2. Linux中没有的线程`Thread`是由进程来模拟实现的所以称作:轻量级进程
|
|
||||||
> 3. 进程是「资源管理」的最小单元,线程是「资源调度」的最小单元(这里不考虑协程)
|
|
||||||
|
|
||||||
|
|
||||||
> 探究进程第四步,让小弟们(线程)出来排个队吧。
|
|
||||||
|
|
||||||
## pstree
|
|
||||||
|
|
||||||
`display a tree of processes` pstree按树形结构打印运行中进程结构信息
|
|
||||||
|
|
||||||
可以直观的查看进程和它启动的线程的关系,并能显示进程标识。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
> 探究进程第五步,是死(进程崩溃)是活(进程运行中)我都要知道你的秘密(堆栈帧 & 上下文)。
|
|
||||||
## gdb
|
|
||||||
|
|
||||||
gdb是GNU开发的gcc套件中Linux下程序调试工具,你可以查看程序的堆栈、设置断点、打印程序运行时信息,甚至还能调试多线程程序,功能十分强大。
|
|
||||||
|
|
||||||
在这里把gdb当成一个命令来讲有点大材小用,要详细说gdb的话,完全可以撑起一篇文章的篇幅,这里长话短说,有机会再开一篇文章详细介绍下它。
|
|
||||||
|
|
||||||
### 使用
|
|
||||||
|
|
||||||
要用gdb调试C/C++程序首先编译的时候要加`-g`选项,`g++ -g test.cpp -o test`这样生成的程序就可以用gdb来调试啦。
|
|
||||||
|
|
||||||
1. 可以直接用gdb启动程序调试,命令:`gdb prog`
|
|
||||||
2. 用gdb附着到一个已经启动的进程上调试也可以。命令:`gdb prog pid`
|
|
||||||
3. 程序崩溃之后参数corefile也可以用gdb调试,看看程序死掉之前留了什么遗言(堆栈信息)给你。命令:`gdb prog corefile`,这里有一点需要注意,有些Linux系统默认程序崩溃不生成`corefile`,这时你需要`ulimit -c unlimited`这样就能生成`corefile`了。
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
> 探究进程第六步,关于你的所有,我都想知道。
|
|
||||||
|
|
||||||
## 更近一步
|
|
||||||
|
|
||||||
通过`/proc/pid`文件了解进程的运行时信息和统计信息。`/proc`系统是一个伪文件系统,它只存在内存当中,而不占用外存空间,以文件系统的方式为内核与进程提供通信的接口。进入系统`/proc`目录:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
/proc目录下有很多以数字命名的目录,每个数字代表进程号PID它们是进程目录。系统中当前运行的每一个进程在/proc下都对应一个以进程号为目录名的目录`/proc/pid `,它们是读取进程信息的接口,我们可以进到这个文件里面,了解进程的运行时信息和统计信息。
|
|
||||||
|
|
||||||
### 高频使用
|
|
||||||
|
|
||||||
`/proc/pid`目录下的有一些重要文件,挑几个使用频率高的讲一讲。
|
|
||||||
`/proc/pid/environ` 包含了进程的可用环境变量的列表 。程序出问题了如果不确定环境变量是否设置生效,可以`cat`这个文件出来查看确认一下。
|
|
||||||
|
|
||||||
`/proc/pid/fd/` 这个目录包含了进程打开的每一个文件的链接。从这里可以查看进程打开的文件描述符信息,包括标准输入、输出、错误流,进程打开的`socket`连接文件描述符也能看到,`lsof`命令也有类似的作用。
|
|
||||||
|
|
||||||
`/proc/pid/stat`包含了进程的所有状态信息,进程号、父进程号、 线程组号、 该任务在用户态运行的时间 、 该任务在用内核态运行的时间、 虚拟地址空间的代码段、 阻塞信号的位图等等信息应有尽有。
|
|
||||||
|
|
||||||
### 其他统计
|
|
||||||
|
|
||||||
`/proc/pid/cmdline` 包含了用于开始进程的命令
|
|
||||||
`/proc/pid/cwd`包含了当前进程工作目录的一个链接
|
|
||||||
`/proc/pid/exe `包含了正在进程中运行的程序链接
|
|
||||||
`/proc/pid/mem `包含了进程在内存中的内容
|
|
||||||
`/proc/pid/statm `包含了进程的内存使用信息
|
|
||||||
|
|
||||||
## 总结一下
|
|
||||||
好了,一顿操作下来,你对进程和它背后的秘密你已经非常了解了,下次我们的好朋友「进程」如果遇到了什么问题(崩溃`coredump`、假死、阻塞、系统调用超时、文件描述符异常),你应该知道如何帮它处理了吧!我们来总结一下:
|
|
||||||
|
|
||||||
- ps查看进程id,看看进程还在不在以及进程状态
|
|
||||||
- 如果在的话`strace`、`psstack`看下进程当前信息,是不卡死在哪个位置,对比各帧最后调用信息找到异常点
|
|
||||||
- 如果进程不再了,如果有`corefile`文件,直接上`gdb`查看`corefile`信息
|
|
||||||
- 其他疑难杂症怀疑进程状态信息的时候,看看`/proc/pid`下面的进程状态信息,可能会给你启发。
|
|
||||||
- 最后,如果以上都不行,闭目祈祷吧!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## 写在最后
|
|
||||||
|
|
||||||
今天的分享希望对你有帮助,祝大家写的服务永不宕机,从不coredump,让上面教你的操作吃灰去吧。
|
|
||||||

|
|
||||||
|
|
||||||
<div align="center"> 图片来源网络|侵删 </div>
|
|
||||||
|
|
||||||
|
|
||||||
最后,感谢各位的阅读。文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## reference
|
|
||||||
|
|
||||||
https://man.linuxde.net/gdb
|
|
||||||
|
|
||||||
https://blog.csdn.net/dan15188387481/article/details/49450491
|
|
||||||
|
|
||||||
https://blog.csdn.net/m0_37925202/article/details/78759408
|
|
||||||
|
|
||||||
https://blog.csdn.net/enweitech/article/details/53391567
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 创作不易,点赞关注支持一下吧
|
|
||||||
我会持续分享软件编程和程序员那些事,欢迎关注。若你对编程感兴趣,我整理了这些年学习编程大约3G的资源汇总,关注公众号「**后端技术学堂**」后发送「**资料**」免费获取。
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 146 KiB |
{kind=link}
|
Before Width: | Height: | Size: 218 KiB |
{kind=link}
|
Before Width: | Height: | Size: 90 KiB |
{kind=link}
|
Before Width: | Height: | Size: 402 KiB |
{kind=link}
|
Before Width: | Height: | Size: 219 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 155 KiB |
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 42 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB |
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
@@ -1,209 +0,0 @@
|
|||||||
今天来带大家研究一下` Linux `内存管理。对于精通 `CURD` 的业务同学,内存管理好像离我们很远,但这个知识点虽然冷门(估计很多人学完根本就没机会用上)但绝对是基础中的基础,这就像武侠中的内功修炼,学完之后看不到立竿见影的效果,但对你日后的开发工作是大有裨益的,因为你站的更高了。
|
|
||||||
|
|
||||||
再功利点的说,面试的时候不经意间透露你懂这方面知识,并且能说出个一二三来,也许能让面试官对你更有兴趣,离升职加薪,走上人生巅峰又近了一步。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
前提约定:本文讨论技术内容前提,操作系统环境都是 `x86`架构的 32 位 ` Linux `系统。
|
|
||||||
|
|
||||||
## 虚拟地址
|
|
||||||
|
|
||||||
即使是现代操作系统中,内存依然是计算机中很宝贵的资源,看看你电脑几个T固态硬盘,再看看内存大小就知道了。为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术,利用虚拟内存技术让每个进程都有`4GB` 互不干涉的虚拟地址空间。
|
|
||||||
|
|
||||||
进程初始化分配和操作的都是基于这个「虚拟地址」,只有当进程需要实际访问内存资源的时候才会建立虚拟地址和物理地址的映射,调入物理内存页。
|
|
||||||
|
|
||||||
打个不是很恰当的比方。这个原理其实和现在的某某网盘一样,假如你的网盘空间是` 1TB `,真以为就一口气给了你这么大空间吗?那还是太年轻,都是在你往里面放东西的时候才给你分配空间,你放多少就分多少实际空间给你,但你和你朋友看起来就像大家都拥有` 1TB `空间一样。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 虚拟地址的好处
|
|
||||||
|
|
||||||
- 避免用户直接访问物理内存地址,防止一些破坏性操作,保护操作系统
|
|
||||||
- 每个进程都被分配了4GB的虚拟内存,用户程序可使用比实际物理内存更大的地址空间
|
|
||||||
|
|
||||||
`4GB` 的进程虚拟地址空间被分成两部分:「用户空间」和「内核空间」
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
## 物理地址
|
|
||||||
|
|
||||||
上面章节我们已经知道不管是用户空间还是内核空间,使用的地址都是虚拟地址,当需进程要实际访问内存的时候,会由内核的「请求分页机制」产生「缺页异常」调入物理内存页。
|
|
||||||
|
|
||||||
把虚拟地址转换成内存的物理地址,这中间涉及利用`MMU` 内存管理单元(Memory Management Unit ) 对虚拟地址分段和分页(段页式)地址转换,关于分段和分页的具体流程,这里不再赘述,可以参考任何一本计算机组成原理教材描述。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
`Linux` 内核会将物理内存分为3个管理区,分别是:
|
|
||||||
|
|
||||||
### ZONE_DMA
|
|
||||||
|
|
||||||
`DMA`内存区域。包含0MB~16MB之间的内存页框,可以由老式基于` ISA `的设备通过` DMA `使用,直接映射到内核的地址空间。
|
|
||||||
|
|
||||||
### ZONE_NORMAL
|
|
||||||
|
|
||||||
普通内存区域。包含16MB~896MB之间的内存页框,常规页框,直接映射到内核的地址空间。
|
|
||||||
|
|
||||||
### ZONE_HIGHMEM
|
|
||||||
|
|
||||||
高端内存区域。包含896MB以上的内存页框,不进行直接映射,可以通过永久映射和临时映射进行这部分内存页框的访问。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 用户空间
|
|
||||||
|
|
||||||
用户进程能访问的是「用户空间」,每个进程都有自己独立的用户空间,虚拟地址范围从从 `0x00000000` 至 `0xBFFFFFFF` 总容量3G 。
|
|
||||||
|
|
||||||
用户进程通常只能访问用户空间的虚拟地址,只有在执行内陷操作或系统调用时才能访问内核空间。
|
|
||||||
|
|
||||||
### 进程与内存
|
|
||||||
|
|
||||||
进程(执行的程序)占用的用户空间按照「 访问属性一致的地址空间存放在一起 」的原则,划分成 `5`个不同的内存区域。 访问属性指的是“可读、可写、可执行等 。
|
|
||||||
|
|
||||||
- 代码段
|
|
||||||
|
|
||||||
代码段是用来存放可执行文件的操作指令,可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,它是不可写的。
|
|
||||||
|
|
||||||
- 数据段
|
|
||||||
|
|
||||||
数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
|
|
||||||
|
|
||||||
- BSS段
|
|
||||||
|
|
||||||
` BSS `段包含了程序中未初始化的全局变量,在内存中 `bss` 段全部置零。
|
|
||||||
|
|
||||||
- 堆 ` heap`
|
|
||||||
|
|
||||||
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
|
|
||||||
|
|
||||||
- 栈 `stack`
|
|
||||||
|
|
||||||
栈是用户存放程序临时创建的局部变量,也就是函数中定义的变量(但不包括 `static` 声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
|
|
||||||
|
|
||||||
上述几种内存区域中数据段、`BSS` 段、堆通常是被连续存储在内存中,在位置上是连续的,而代码段和栈往往会被独立存放。堆和栈两个区域在 `i386` 体系结构中栈向下扩展、堆向上扩展,相对而生。
|
|
||||||

|
|
||||||
|
|
||||||
你也可以再linux下用`size` 命令查看编译后程序的各个内存区域大小:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
[lemon ~]# size /usr/local/sbin/sshd
|
|
||||||
text data bss dec hex filename
|
|
||||||
1924532 12412 426896 2363840 2411c0 /usr/local/sbin/sshd
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 内核空间
|
|
||||||
|
|
||||||
在 `x86 32` 位系统里,Linux 内核地址空间是指虚拟地址从 `0xC0000000` 开始到 `0xFFFFFFFF` 为止的高端内存地址空间,总计 `1G` 的容量, 包括了内核镜像、物理页面表、驱动程序等运行在内核空间 。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 直接映射区
|
|
||||||
|
|
||||||
直接映射区 `Direct Memory Region`:从内核空间起始地址开始,最大`896M`的内核空间地址区间,为直接内存映射区。
|
|
||||||
|
|
||||||
直接映射区的896MB的「线性地址」直接与「物理地址」的前`896MB`进行映射,也就是说线性地址和分配的物理地址都是连续的。内核地址空间的线性地址`0xC0000001`所对应的物理地址为`0x00000001`,它们之间相差一个偏移量`PAGE_OFFSET = 0xC0000000`
|
|
||||||
|
|
||||||
该区域的线性地址和物理地址存在线性转换关系「线性地址 = `PAGE_OFFSET` + 物理地址」也可以用 `virt_to_phys() `函数将内核虚拟空间中的线性地址转化为物理地址。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 高端内存线性地址空间
|
|
||||||
|
|
||||||
内核空间线性地址从 896M 到 1G 的区间,容量 128MB 的地址区间是高端内存线性地址空间,为什么叫高端内存线性地址空间?下面给你解释一下:
|
|
||||||
|
|
||||||
前面已经说过,内核空间的总大小 1GB,从内核空间起始地址开始的 896MB 的线性地址可以直接映射到物理地址大小为 896MB 的地址区间。退一万步,即使内核空间的1GB线性地址都映射到物理地址,那也最多只能寻址 1GB 大小的物理内存地址范围。
|
|
||||||
|
|
||||||
请问你现在你家的内存条多大?快醒醒都 0202 年了,一般 PC 的内存都大于 1GB 了吧!
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
所以,内核空间拿出了最后的 128M 地址区间,划分成下面三个高端内存映射区,以达到对整个物理地址范围的寻址。而 在 64 位的系统上就不存在这样的问题了,因为可用的线性地址空间远大于可安装的内存。
|
|
||||||
|
|
||||||
##### 动态内存映射区
|
|
||||||
|
|
||||||
`vmalloc Region` 该区域由内核函数`vmalloc`来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。 `vmalloc` 分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
|
|
||||||
|
|
||||||
##### 永久内存映射区
|
|
||||||
|
|
||||||
`Persistent Kernel Mapping Region` 该区域可访问高端内存。访问方法是使用 `alloc_page (_GFP_HIGHMEM)` 分配高端内存页或者使用` kmap `函数将分配到的高端内存映射到该区域。
|
|
||||||
|
|
||||||
##### 固定映射区
|
|
||||||
|
|
||||||
`Fixing kernel Mapping Region` 该区域和 4G 的顶端只有 4k 的隔离带,其每个地址项都服务于特定的用途,如 `ACPI_BASE` 等。
|
|
||||||
|
|
||||||
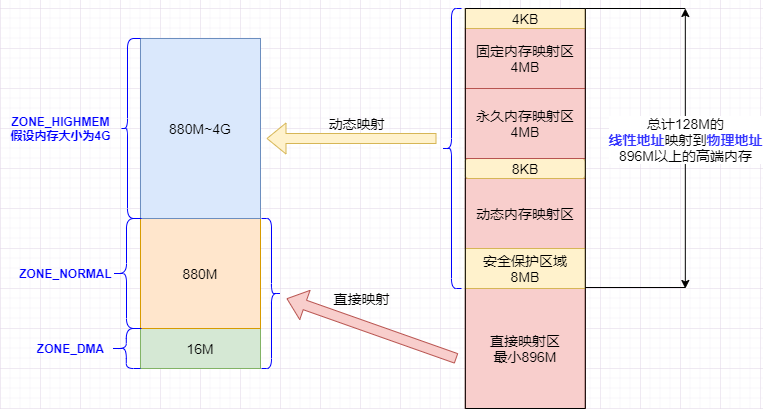
|
|
||||||
|
|
||||||
|
|
||||||
## 回顾一下
|
|
||||||
|
|
||||||
上面讲的有点多,先别着急进入下一节,在这之前我们再来回顾一下上面所讲的内容。如果认真看完上面的章节,我这里再画了一张图,现在你的脑海中应该有这样一个内存管理的全局图。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 内存数据结构
|
|
||||||
|
|
||||||
要让内核管理系统中的虚拟内存,必然要从中抽象出内存管理数据结构,内存管理操作如「分配、释放等」都基于这些数据结构操作,这里列举两个管理虚拟内存区域的数据结构。
|
|
||||||
|
|
||||||
### 用户空间内存数据结构
|
|
||||||
|
|
||||||
在前面「进程与内存」章节我们提到,Linux进程可以划分为 5 个不同的内存区域,分别是:代码段、数据段、` BSS `、堆、栈,内核管理这些区域的方式是,将这些内存区域抽象成` vm_area_struct `的内存管理对象。
|
|
||||||
|
|
||||||
` vm_area_struct `是描述进程地址空间的基本管理单元,一个进程往往需要多个` vm_area_struct `来描述它的用户空间虚拟地址,需要使用「链表」和「红黑树」来组织各个` vm_area_struct `。
|
|
||||||
|
|
||||||
链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
|
|
||||||
|
|
||||||
用户空间进程的地址管理模型:
|
|
||||||
|
|
||||||
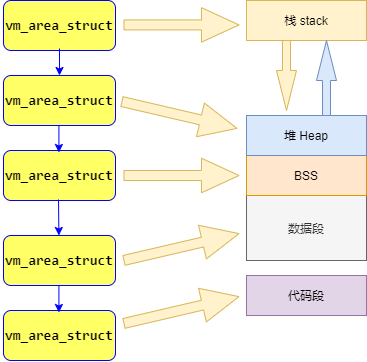
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 内核空间动态分配内存数据结构
|
|
||||||
|
|
||||||
在内核空间章节我们提到过「动态内存映射区」,该区域由内核函数`vmalloc`来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。 `vmalloc` 分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
|
|
||||||
|
|
||||||
`vmalloc` 分配的地址则限于` vmalloc_start `与` vmalloc_end `之间。每一块` vmalloc `分配的内核虚拟内存都对应一个` vm_struct `结构体,不同的内核空间虚拟地址之间有` 4k `大小的防越界空闲区间隔区。与用户空间的虚拟地址特性一样,这些虚拟地址与物理内存没有简单的映射关系,必须通过内核页表才可转换为物理地址或物理页,它们有可能尚未被映射,当发生缺页时才真正分配物理页面。
|
|
||||||
|
|
||||||
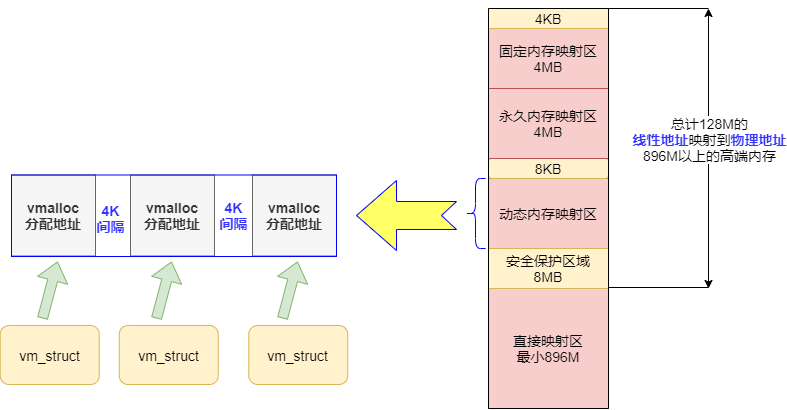
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结一下
|
|
||||||
|
|
||||||
`Linux `内存管理是一个非常复杂的系统,本文所述只是冰山一角,从宏观角度给你展现内存管理的全貌,但一般来说,这些知识在你和面试官聊天的时候还是够用的,当然我也希望大家能够通过读书了解更深层次的原理。
|
|
||||||
|
|
||||||
希望这篇文章可以作为一个索引一样的学习指南,当你想深入某一点学习的时候可以在这些章节里找到切入点,以及这个知识点在内存管理宏观上的位置。
|
|
||||||
|
|
||||||
**本文创作过程我也画了大量的示例图解,可以作为知识索引,个人感觉看图还是比看文字更清晰明了,你可以在我公众号「后端技术学堂」后台回复「内存管理」获取这些图片的高清原图。**
|
|
||||||
|
|
||||||
老规矩,感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
**我是 lemon 一线互联网大厂程序员,热爱技术,乐于分享。欢迎扫码关注公众号「后端技术学堂」带你一起学编程,回复「资源」送你 3GB 的编程学习大礼包,包括Linux、数据库、C++、Python、数据结构与算法、设计模式、程序员面试指南等资源,欢迎关注,交流学习。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Reference
|
|
||||||
|
|
||||||
Linux内存管理(最透彻的一篇) https://cloud.tencent.com/developer/article/1515762
|
|
||||||
|
|
||||||
linux 内存管理初探 https://cloud.tencent.com/developer/article/1005671
|
|
||||||
|
|
||||||
linux内存管理源码分析 - 页框分配器 https://www.cnblogs.com/tolimit/p/4551428.html
|
|
||||||
|
|
||||||
Linux内核--内核地址空间分布和进程地址空间 https://my.oschina.net/wuqingyi/blog/854382
|
|
||||||
|
|
||||||
Linux内存管理 http://gityuan.com/2015/10/30/kernel-memory/
|
|
||||||
|
|
||||||
Linux Used内存到底哪里去了? http://blog.yufeng.info/archives/2456
|
|
||||||
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 259 KiB |
@@ -1,260 +0,0 @@
|
|||||||
今天继续来学习Linux内存管理,什么?你更想学时间管理,我不配,抱个西瓜去微博学吧。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
言归正传,上一篇文章 [别再说你不懂Linux内存管理了,10张图给你安排的明明白白!](https://mp.weixin.qq.com/s?__biz=MzIwMjM4NDE1Nw==&mid=2247483865&idx=1&sn=dfa63a467b620b6131acaef9ea6874a3&chksm=96de37aba1a9bebdcc097314f40ae633bd393253759ecd970ac84cdb41f18994da9405dbf356&token=1178579599&lang=zh_CN#rd) 分析了 Linux 内存管理机制,如果已经忘了的同学还可以回头看下,并且也强烈建议先阅读那一篇再来看这一篇。限于篇幅,上一篇没有深入学习物理内存管理和虚拟内存分配,今天就来学习一下。
|
|
||||||
|
|
||||||
通过前面的学习我们知道,程序可没这么好骗,任你内存管理把虚拟地址空间玩出花来,到最后还是要给程序实实在在的物理内存,不然程序就要罢工了,所以物理内存这么重要的资源一定要好好管理起来使用(物理内存,就是你实实在在的内存条),那么内核是如何管理物理内存的呢?
|
|
||||||
|
|
||||||
## 物理内存管理
|
|
||||||
|
|
||||||
在`Linux `系统中通过分段和分页机制,把物理内存划分 4K 大小的内存页 `Page`(也称作页框`Page Frame`),物理内存的分配和回收都是基于内存页进行,把物理内存分页管理的好处大大的。
|
|
||||||
|
|
||||||
假如系统请求小块内存,可以预先分配一页给它,避免了反复的申请和释放小块内存带来频繁的系统开销。
|
|
||||||
|
|
||||||
假如系统需要大块内存,则可以用多页内存拼凑,而不必要求大块连续内存。你看不管内存大小都能收放自如,分页机制多么完美的解决方案!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
But,理想很丰满,现实很骨感。如果就直接这样把内存分页使用,不再加额外的管理还是存在一些问题,下面我们来看下,系统在多次分配和释放物理页的时候会遇到哪些问题。
|
|
||||||
|
|
||||||
### 物理页管理面临问题
|
|
||||||
|
|
||||||
物理内存页分配会出现外部碎片和内部碎片问题,所谓的「内部」和「外部」是针对「页框内外」而言,一个页框内的内存碎片是内部碎片,多个页框间的碎片是外部碎片。
|
|
||||||
|
|
||||||
#### 外部碎片
|
|
||||||
|
|
||||||
当需要分配大块内存的时候,要用好几页组合起来才够,而系统分配物理内存页的时候会尽量分配连续的内存页面,频繁的分配与回收物理页导致大量的小块内存夹杂在已分配页面中间,形成外部碎片,举个例子:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
#### 内部碎片
|
|
||||||
|
|
||||||
物理内存是按页来分配的,这样当实际只需要很小内存的时候,也会分配至少是 4K 大小的页面,而内核中有很多需要以字节为单位分配内存的场景,这样本来只想要几个字节而已却不得不分配一页内存,除去用掉的字节剩下的就形成了内部碎片。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
### 页面管理算法
|
|
||||||
|
|
||||||
方法总比困难多,因为存在上面的这些问题,聪明的程序员灵机一动,引入了页面管理算法来解决上述的碎片问题。
|
|
||||||
|
|
||||||
#### Buddy(伙伴)分配算法
|
|
||||||
|
|
||||||
`Linux` 内核引入了伙伴系统算法(Buddy system),什么意思呢?就是把相同大小的页框块用链表串起来,页框块就像手拉手的好伙伴,也是这个算法名字的由来。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
具体的,所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
因为任何正整数都可以由 `2^n` 的和组成,所以总能找到合适大小的内存块分配出去,减少了外部碎片产生 。
|
|
||||||
|
|
||||||
##### 分配实例
|
|
||||||
|
|
||||||
比如:我需要申请4个页框,但是长度为4个连续页框块链表没有空闲的页框块,伙伴系统会从连续8个页框块的链表获取一个,并将其拆分为两个连续4个页框块,取其中一个,另外一个放入连续4个页框块的空闲链表中。释放的时候会检查,释放的这几个页框前后的页框是否空闲,能否组成下一级长度的块。
|
|
||||||
|
|
||||||
##### 命令查看
|
|
||||||
|
|
||||||
```
|
|
||||||
[lemon]]# cat /proc/buddyinfo
|
|
||||||
Node 0, zone DMA 1 0 0 0 2 1 1 0 1 1 3
|
|
||||||
Node 0, zone DMA32 3198 4108 4940 4773 4030 2184 891 180 67 32 330
|
|
||||||
Node 0, zone Normal 42438 37404 16035 4386 610 121 22 3 0 0 1
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### slab分配器
|
|
||||||
|
|
||||||
看到这里你可能会想,有了伙伴系统这下总可以管理好物理内存了吧?不,还不够,否则就没有slab分配器什么事了。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
那什么是slab分配器呢?
|
|
||||||
|
|
||||||
一般来说,内核对象的生命周期是这样的:分配内存-初始化-释放内存,内核中有大量的小对象,比如文件描述结构对象、任务描述结构对象,如果按照伙伴系统按页分配和释放内存,对小对象频繁的执行「分配内存-初始化-释放内存」会非常消耗性能。
|
|
||||||
|
|
||||||
伙伴系统分配出去的内存还是以页框为单位,而对于内核的很多场景都是分配小片内存,远用不到一页内存大小的空间。` slab `分配器,**通过将内存按使用对象不同再划分成不同大小的空间**,应用于内核对象的缓存。
|
|
||||||
|
|
||||||
伙伴系统和slab不是二选一的关系,`slab` 内存分配器是对伙伴分配算法的补充。
|
|
||||||
|
|
||||||
##### 大白话说原理
|
|
||||||
|
|
||||||
对于每个内核中的相同类型的对象,如:`task_struct、file_struct` 等需要重复使用的小型内核数据对象,都会有个 slab 缓存池,缓存住大量常用的「已经初始化」的对象,每当要申请这种类型的对象时,就从缓存池的`slab` 列表中分配一个出去;而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片,同时也大大提高了内存分配性能。
|
|
||||||
|
|
||||||
##### 主要优点
|
|
||||||
|
|
||||||
- `slab` 内存管理基于内核小对象,不用每次都分配一页内存,充分利用内存空间,避免内部碎片。
|
|
||||||
- `slab` 对内核中频繁创建和释放的小对象做缓存,重复利用一些相同的对象,减少内存分配次数。
|
|
||||||
|
|
||||||
##### 数据结构
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
`kmem_cache` 是一个`cache_chain` 的链表组成节点,代表的是一个内核中的相同类型的「对象高速缓存」,每个`kmem_cache` 通常是一段连续的内存块,包含了三种类型的 `slabs` 链表:
|
|
||||||
|
|
||||||
- `slabs_full` (完全分配的 `slab` 链表)
|
|
||||||
- ` slabs_partial` (部分分配的`slab` 链表)
|
|
||||||
- `slabs_empty` ( 没有被分配对象的`slab` 链表)
|
|
||||||
|
|
||||||
`kmem_cache` 中有个重要的结构体 `kmem_list3` 包含了以上三个数据结构的声明。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
`slab` 是` slab` 分配器的最小单位,在实现上一个 `slab` 有一个或多个连续的物理页组成(通常只有一页)。单个slab可以在 `slab` 链表之间移动,例如如果一个「半满` slabs_partial`链表」被分配了对象后变满了,就要从 `slabs_partial` 中删除,同时插入到「全满`slabs_full`链表」中去。内核` slab `对象的分配过程是这样的:
|
|
||||||
|
|
||||||
1. 如果` slabs_partial`链表还有未分配的空间,分配对象,若分配之后变满,移动 `slab` 到`slabs_full` 链表
|
|
||||||
2. 如果` slabs_partial`链表没有未分配的空间,进入下一步
|
|
||||||
3. 如果`slabs_empty` 链表还有未分配的空间,分配对象,同时移动` slab `进入` slabs_partial`链表
|
|
||||||
4. 如果`slabs_empty`为空,请求伙伴系统分页,创建一个新的空闲`slab`, 按步骤 3 分配对象
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
##### 命令查看
|
|
||||||
|
|
||||||
上面说的都是理论,比较抽象,动动手来康康系统中的 slab 吧!你可以通过 `cat /proc/slabinfo` 命令,实际查看系统中` slab` 信息。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
`slabtop` 实时显示内核 slab 内存缓存信息。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### slab高速缓存的分类
|
|
||||||
|
|
||||||
slab高速缓存分为两大类,「通用高速缓存」和「专用高速缓存」。
|
|
||||||
|
|
||||||
##### 通用高速缓存
|
|
||||||
|
|
||||||
slab分配器中用 `kmem_cache` 来描述高速缓存的结构,它本身也需要 slab 分配器对其进行高速缓存。cache_cache 保存着对「高速缓存描述符的高速缓存」,是一种通用高速缓存,保存在`cache_chain` 链表中的第一个元素。
|
|
||||||
|
|
||||||
|
|
||||||
另外,slab 分配器所提供的小块连续内存的分配,也是通用高速缓存实现的。通用高速缓存所提供的对象具有几何分布的大小,范围为32到131072字节。内核中提供了 `kmalloc()` 和 `kfree()` 两个接口分别进行内存的申请和释放。
|
|
||||||
|
|
||||||
##### 专用高速缓存
|
|
||||||
|
|
||||||
内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为制定的对象分配slab缓存。
|
|
||||||
|
|
||||||
###### 专用高速缓存的申请和释放
|
|
||||||
|
|
||||||
kmem_cache_create() 用于对一个指定的对象创建高速缓存。它从 cache_cache 普通高速缓存中为新的专有缓存分配一个高速缓存描述符,并把这个描述符插入到高速缓存描述符形成的 cache_chain 链表中。kmem_cache_destory() 用于撤消和从 cache_chain 链表上删除高速缓存。
|
|
||||||
|
|
||||||
##### slab的申请和释放
|
|
||||||
|
|
||||||
`slab` 数据结构在内核中的定义,如下:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
kmem_cache_alloc() 在其参数所指定的高速缓存中分配一个slab,对应的 kmem_cache_free() 在其参数所指定的高速缓存中释放一个slab。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 虚拟内存分配
|
|
||||||
|
|
||||||
前面讨论的都是对物理内存的管理,Linux 通过虚拟内存管理,欺骗了用户程序假装每个程序都有 4G 的虚拟内存寻址空间(如果这里不懂我说啥,建议回头看下 [别再说你不懂Linux内存管理了,10张图给你安排的明明白白!](https://mp.weixin.qq.com/s?__biz=MzIwMjM4NDE1Nw==&mid=2247483865&idx=1&sn=dfa63a467b620b6131acaef9ea6874a3&chksm=96de37aba1a9bebdcc097314f40ae633bd393253759ecd970ac84cdb41f18994da9405dbf356&token=1178579599&lang=zh_CN#rd))。
|
|
||||||
|
|
||||||
所以我们来研究下虚拟内存的分配,这里包括用户空间虚拟内存和内核空间虚拟内存。
|
|
||||||
|
|
||||||
**注意,分配的虚拟内存还没有映射到物理内存,只有当访问申请的虚拟内存时,才会发生缺页异常,再通过上面介绍的伙伴系统和 slab 分配器申请物理内存。**
|
|
||||||
|
|
||||||
### 用户空间内存分配
|
|
||||||
|
|
||||||
#### malloc
|
|
||||||
|
|
||||||
`malloc` 用于申请用户空间的虚拟内存,当申请小于 `128KB` 小内存的时,` malloc `使用 `sbrk或brk` 分配内存;当申请大于 `128KB` 的内存时,使用 `mmap` 函数申请内存;
|
|
||||||
|
|
||||||
##### 存在问题
|
|
||||||
|
|
||||||
由于 `brk/sbrk/mmap` 属于系统调用,如果每次申请内存都要产生系统调用开销,`cpu` 在用户态和内核态之间频繁切换,非常影响性能。
|
|
||||||
|
|
||||||
而且,堆是从低地址往高地址增长,如果低地址的内存没有被释放,高地址的内存就不能被回收,容易产生内存碎片。
|
|
||||||
|
|
||||||
##### 解决
|
|
||||||
|
|
||||||
因此,` malloc `采用的是内存池的实现方式,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块分配出去。
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 内核空间内存分配
|
|
||||||
|
|
||||||
在讲内核空间内存分配之前,先来回顾一下内核地址空间。`kmalloc` 和 `vmalloc` 分别用于分配不同映射区的虚拟内存。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### kmalloc
|
|
||||||
|
|
||||||
`kmalloc()` 分配的虚拟地址范围在内核空间的「直接内存映射区」。
|
|
||||||
|
|
||||||
按字节为单位虚拟内存,一般用于分配小块内存,释放内存对应于 `kfree` ,可以分配连续的物理内存。函数原型在 `<linux/kmalloc.h>` 中声明,一般情况下在驱动程序中都是调用 `kmalloc()` 来给数据结构分配内存 。
|
|
||||||
|
|
||||||
还记得前面说的 slab 吗?`kmalloc` 是基于slab 分配器的 ,同样可以用`cat /proc/slabinfo` 命令,查看 `kmalloc` 相关 `slab` 对象信息,下面的 kmalloc-8、kmalloc-16 等等就是基于slab分配的 kmalloc 高速缓存。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
#### vmalloc
|
|
||||||
|
|
||||||
`vmalloc` 分配的虚拟地址区间,位于 `vmalloc_start` 与 ` vmalloc_end` 之间的「动态内存映射区」。
|
|
||||||
|
|
||||||
一般用分配大块内存,释放内存对应于 `vfree`,分配的虚拟内存地址连续,物理地址上不一定连续。函数原型在 `<linux/vmalloc.h>` 中声明。一般用在为活动的交换区分配数据结构,为某些 `I/O` 驱动程序分配缓冲区,或为内核模块分配空间。
|
|
||||||
|
|
||||||
下面的图总结了上述两种内核空间虚拟内存分配方式。
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结一下
|
|
||||||
|
|
||||||
这是`Linux `内存管理系列文章的下篇,强烈建议阅读过程中有不清楚的同学,先去看看我之前写的 [别再说你不懂Linux内存管理了,10张图给你安排的明明白白!](https://mp.weixin.qq.com/s?__biz=MzIwMjM4NDE1Nw==&mid=2247483865&idx=1&sn=dfa63a467b620b6131acaef9ea6874a3&chksm=96de37aba1a9bebdcc097314f40ae633bd393253759ecd970ac84cdb41f18994da9405dbf356&token=1178579599&lang=zh_CN#rd),写到这里Linux 内存管理专题告一段落,我分享的这些知识很基础,基础到日常开发工作几乎用不上,但我认为每个在Linux下开发人员都应该了解。
|
|
||||||
|
|
||||||
我知道有些面试官喜欢在面试的时候考察一下,或多或少反应候选人基础素养,这两篇文章的内容也足够应付面试。还是那句话,Linxu 内存管理太复杂,不是一两篇文章能讲的清楚,但至少要有宏观意识,不至于一问三不知,如果你想深入了解原理,强烈建议从书中并结合内核源码学习,每天进步一点点,我们的目标是星辰大海。
|
|
||||||
|
|
||||||
**本文创作过程我也画了大量的示例图解,可以作为知识索引,个人感觉看图还是比看文字更清晰明了,你可以在我公众号「后端技术学堂」后台回复「内存管理」获取这些图片的高清原图。**
|
|
||||||
|
|
||||||
老规矩,感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。今天的技术分享就到这里,我们下期再见。
|
|
||||||
|
|
||||||
**原创不易,看到这里,如果在我这有一点点收获,就动动手指「转发」和「在看」是对我持续创作的最大支持。**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Reference
|
|
||||||
|
|
||||||
《Linux内核设计与实现(原书第3版)》
|
|
||||||
|
|
||||||
linux内核slab机制分析 https://www.jianshu.com/p/95d68389fbd1
|
|
||||||
|
|
||||||
Linux内存管理中的slab分配器 http://edsionte.com/techblog/archives/4019
|
|
||||||
|
|
||||||
Linux slab 分配器剖析 https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/index.html#table2
|
|
||||||
|
|
||||||
Linux内核内存管理算法Buddy和Slab https://zhuanlan.zhihu.com/p/36140017
|
|
||||||
|
|
||||||
Linux内存之Slab https://fivezh.github.io/2017/06/25/Linux-slab-info/
|
|
||||||
|
|
||||||
malloc 的实现原理 内存池 mmap sbrk 链表 https://zhuanlan.zhihu.com/p/57863097
|
|
||||||
|
|
||||||
malloc实现原理 http://luodw.cc/2016/02/17/malloc/
|
|
||||||
|
|
||||||
glibc内存管理那些事儿 https://www.jianshu.com/p/2fedeacfa797
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 174 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
@@ -1,29 +0,0 @@
|
|||||||
## top
|
|
||||||
|
|
||||||
`top`命令这个大家都非常的熟悉,他也是很多`LInux`发行版自带的系统工具,几乎每一个Linux程序员都会用过这个命令。`top` 可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理。
|
|
||||||
|
|
||||||
vmstat
|
|
||||||
|
|
||||||
iostat
|
|
||||||
|
|
||||||
ifstat
|
|
||||||
|
|
||||||
dstat
|
|
||||||
|
|
||||||
netstat
|
|
||||||
|
|
||||||
perf
|
|
||||||
|
|
||||||
tcpdump
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Reference
|
|
||||||
|
|
||||||
https://www.open-open.com/lib/view/open1418970861542.html#articleHeader1
|
|
||||||
|
|
||||||
https://www.open-open.com/news/view/62d559
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 278 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB |
{kind=link}
|
Before Width: | Height: | Size: 57 KiB |
{kind=link}
|
Before Width: | Height: | Size: 206 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 48 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 57 KiB |
@@ -1,268 +0,0 @@
|
|||||||
很早之前就在构思这个主题,进程线程可以说是操作系统基础,看过很多关于这方面知识的文章都是纯理论讲述,编程新手有些难以下咽。于是写下这篇文章,用图解的形式带你学习和掌握进程、线程、协程,文字力求简单明了,对于复杂概念做到一个概念一张图解,即使你是编程小白也能看的明明白白,妈妈再也不用担心你的学习。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
这周暂时不更新 Go 基础教程系列,教程更新已接近尾声,对 Go 语言学习感兴趣但还没看过的的同学,可以在公众号历史文章查看。Go 基础教程接下来会进入并发编程和 Go 协程部分,为了更好的理解这部分内容,带大家先了解 Linux 系统基础和进程、线程以及协程的差异与特点。
|
|
||||||
|
|
||||||
在操作系统课程的学习中,很多人对进程线程有大体的认识,但操作系统教材更偏向于理论叙述,本文会结合 Linux 系统实现分析,更加印象深刻。
|
|
||||||
|
|
||||||
同时,大部分人都接触进程和线程比较多,对协程知之甚少,然而最近协程并发编程技术火热起来,希望读完本文你对协程也有一个基本的了解。
|
|
||||||
|
|
||||||
话不多说,我们马上进入本文的学习。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 进程
|
|
||||||
|
|
||||||
关于进程和内存管理我之前有一篇文章单独讲解过,这里再挑选一部分和本文相关的内容学习,温故而知新。
|
|
||||||
|
|
||||||
首先还是说下「程序」的概念,程序是一些保存在磁盘上的指令的有序集合,是静态的。**进程是程序执行的过程**,包括了动态创建、调度和消亡的整个过程,**进程是程序资源管理的最小单位**。
|
|
||||||
|
|
||||||
### 进程与资源
|
|
||||||
|
|
||||||
那么进程都管理哪些资源呢? 通常包括内存资源、IO资源、信号处理等部分。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
篇幅有限着重说一下内存管理,进程运行起来必然会涉及到对内存资源的管理。内存资源有限,**操作系统采用虚拟内存技术,把进程虚拟地址空间划分成用户空间和内核空间。**
|
|
||||||
|
|
||||||
### 地址空间
|
|
||||||
|
|
||||||
`4GB` 的进程虚拟地址空间被分成两部分:用户空间和内核空间
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### 用户空间
|
|
||||||
|
|
||||||
用户空间按照**访问属性一致的地址空间存放在一起的原则**,划分成 `5`个不同的内存区域。 访问属性指的是“可读、可写、可执行等 。
|
|
||||||
|
|
||||||
- 代码段
|
|
||||||
|
|
||||||
代码段是用来存放可执行文件的操作指令,可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,它是不可写的。
|
|
||||||
|
|
||||||
- 数据段
|
|
||||||
|
|
||||||
数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
|
|
||||||
|
|
||||||
- BSS段
|
|
||||||
|
|
||||||
` BSS `段包含了程序中未初始化的全局变量,在内存中 `bss` 段全部置零。
|
|
||||||
|
|
||||||
- 堆 ` heap`
|
|
||||||
|
|
||||||
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
|
|
||||||
|
|
||||||
- 栈 `stack`
|
|
||||||
|
|
||||||
栈是用户存放程序临时创建的局部变量,也就是函数中定义的变量(但不包括 `static` 声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
|
|
||||||
|
|
||||||
上述几种内存区域中数据段、`BSS` 段、堆通常是被连续存储在内存中,在位置上是连续的,而代码段和栈往往会被独立存放。堆和栈两个区域在 `i386` 体系结构中栈向下扩展、堆向上扩展,相对而生。
|
|
||||||

|
|
||||||
|
|
||||||
你也可以再 linux 下用`size` 命令查看编译后程序的各个内存区域大小:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
[lemon ~]# size /usr/local/sbin/sshd
|
|
||||||
text data bss dec hex filename
|
|
||||||
1924532 12412 426896 2363840 2411c0 /usr/local/sbin/sshd
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 内核空间
|
|
||||||
|
|
||||||
在 `x86 32` 位系统里,Linux 内核地址空间是指虚拟地址从 `0xC0000000` 开始到 `0xFFFFFFFF` 为止的高端内存地址空间,总计 `1G` 的容量, 包括了内核镜像、物理页面表、驱动程序等运行在内核空间 。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## 线程
|
|
||||||
|
|
||||||
线程是操作操作系统能够进行运算调度的最小单位。线程被包含在进程之中,是进程中的实际运作单位,一个进程内可以包含多个线程,**线程是资源调度的最小单位。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 线程资源和开销
|
|
||||||
|
|
||||||
同一进程中的多条线程共享该进程中的全部系统资源,如虚拟地址空间,文件描述符文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈、寄存器环境、线程本地存储等信息。
|
|
||||||
|
|
||||||
线程创建的开销主要是线程堆栈的建立,分配内存的开销。这些开销并不大,最大的开销发生在线程上下文切换的时候。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 线程分类
|
|
||||||
|
|
||||||
还记得刚开始我们讲的内核空间和用户空间概念吗?线程按照实现位置和方式的不同,也分为用户级线程和内核线程,下面一起来看下这两类线程的差异和特点。
|
|
||||||
|
|
||||||
#### 用户级线程
|
|
||||||
|
|
||||||
实现在用户空间的线程称为用户级线程。用户线程是完全建立在用户空间的线程库,用户线程的创建、调度、同步和销毁全由用户空间的库函数完成,不需要内核的参与,因此这种线程的系统资源消耗非常低,且非常的高效。
|
|
||||||
|
|
||||||
##### 特点
|
|
||||||
|
|
||||||
- 用户线级线程只能参与竞争该进程的处理器资源,不能参与全局处理器资源的竞争。
|
|
||||||
- 用户级线程切换都在用户空间进行,开销极低。
|
|
||||||
- 用户级线程调度器在用户空间的线程库实现,内核的调度对象是进程本身,内核并不知道用户线程的存在。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
##### 缺点
|
|
||||||
|
|
||||||
- 如果触发了引起阻塞的系统调用的调用,会立即阻塞该线程所属的整个进程。
|
|
||||||
- 系统只看到进程看不到用户线程,所以只有一个处理器内核会被分配给该进程 ,也就不能发挥多核 CPU 的优势 。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 内核级线程
|
|
||||||
|
|
||||||
内核级线程是指,内核线程建立和销毁都是由操作系统负责、通过系统调用完成的,内核维护进程及线程的上下文信息以及线程切换。
|
|
||||||
|
|
||||||
##### 特点
|
|
||||||
|
|
||||||
- 内核级线级能参与全局的多核处理器资源分配,充分利用多核 CPU 优势。
|
|
||||||
- 每个内核线程都可被内核调度,因为线程的创建、撤销和切换都是对内核管理的。
|
|
||||||
- 一个内核线程阻塞与他同属一个进程的线程仍然能继续运行。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
##### 缺点
|
|
||||||
|
|
||||||
- 内核级线程调度开销较大。调度内核线程的代价可能和调度进程差不多昂贵,代价要比用户级线程大很多。
|
|
||||||
- 线程表是存放在操作系统固定的表格空间或者堆栈空间里,所以内核级线程的数量是有限的。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Linux 线程实现
|
|
||||||
|
|
||||||
`Linux` 并没有为线程准备特定的数据结构,因为 Linux只有` task_struct`这一种描述进程的结构体。在内核看来只有进程而没有线程,线程调度时也是当做进程来调度的。Linux所谓的线程其实是与其他进程共享资源的**轻量级进程**。
|
|
||||||
|
|
||||||
为什么说是轻量级呢?在于它只有一个最小的执行上下文和调度程序所需的统计信息,它只带有进程执行相关的信息,与父进程共享进程地址空间 。
|
|
||||||
|
|
||||||
#### 轻量级进程
|
|
||||||
|
|
||||||
轻量级线程 `Light-weight Process `简称` LWP ` ,是一种由内核支持的用户线程,每一个轻量级进程都与一个特定的内核线程关联。
|
|
||||||
|
|
||||||
它是基于内核线程的高级抽象,系统只有先支持内核线程才能有 `LWP`。每一个进程有一个或多个 `LWPs` ,每个` LWP ` 由一个内核线程支持,在这种实现的操作系统中 `LWP` 就是用户线程。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
轻量级进程最早在`Linux` 内核 `2.0.x` 版本就已实现,应用程序通过一个统一的 `clone()` 系统调用接口,用不同的参数指定创建的进程是轻量进程还是普通进程。
|
|
||||||
|
|
||||||
#### 特点和缺点
|
|
||||||
|
|
||||||
由于轻量轻量级进程基于内核线程实现,因此它的特点和缺点就是内核线程的缺点,这里不再赘述。
|
|
||||||
|
|
||||||
#### 查看 LWP 信息
|
|
||||||
|
|
||||||
轻量级线程也没什么神秘的,还记得我在这篇文章《资深程序员总结:分析Linux进程的6个方法,我全都告诉你》教你的方法吗?我们用 Linux 的 `pstack` 命令可以查看进程的轻量级线程 LWP 信息。下图的黄色字体就是打印出的轻量级线程 ID ,以及该线程的调用堆栈信息,从最新的栈帧开始往下排列。
|
|
||||||
|
|
||||||
用法示例: `pstack pid `
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 协程
|
|
||||||
|
|
||||||
协程的知名度好像不是很高,在以前我们谈论高并发,大部分人都知道利用多线程和多进程部署服务,提高服务性能,但一般不会提到协程。其实协程的概念出来的比线程还早,只不过最近才被人们更多的提起。
|
|
||||||
|
|
||||||
协程之所以最近被大家熟知,个人觉得是 `Python` 和 `Go` 从语言层面提供了对协程更好的支持,尤其是以 `Goroutine` 为代表的 Go 协程实现,很大程度上降低了协程使用门槛,可以说是后起之秀了!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### why 协程
|
|
||||||
|
|
||||||
当今无数的 Web 服务和互联网服务,本质上大部分都是 IO 密集型服务,什么是 IO 密集型服务?意思是处理的任务大多是和网络连接或读写相关的高耗时任务,高耗时是相对 CPU 计算逻辑处理型任务来说,两者的处理时间差距不是一个数量级的。
|
|
||||||
|
|
||||||
**IO 密集型服务的瓶颈不在 CPU 处理速度,而在于尽可能快速的完成高并发、多连接下的数据读写。**
|
|
||||||
|
|
||||||
**以前有两种解决方案:**
|
|
||||||
|
|
||||||
- 如果用多线程,高并发场景的大量 IO 等待会导致多线程被频繁挂起和切换,非常消耗系统资源,同时多线程访问共享资源存在竞争问题。
|
|
||||||
|
|
||||||
- 如果用多进程,不仅存在频繁调度切换问题,同时还会存在每个进程资源不共享的问题,需要额外引入进程间通信机制来解决。
|
|
||||||
|
|
||||||
**协程出现给高并发和 IO 密集型服务开发提供了另一种选择。**
|
|
||||||
|
|
||||||
当然,世界上没有技术银弹,在这里我想把协程这把钥匙交到你手中,但是它也不是万能钥匙,最好的解决方案是贴合自身业务类型做出最优选择,不一定就选择一种模型,有时候是几种模型的组合,比如多线程搭配协程是常见的组合。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 什么是协程
|
|
||||||
|
|
||||||
**那什么是协程呢?协程 `Coroutines` 是一种比线程更加轻量级的微线程。**类比一个进程可以拥有多个线程,一个线程也可以拥有多个协程,因此协程又称微线程和纤程。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**可以粗略的把协程理解成子程序调用,每个子程序都可以在一个单独的协程内执行。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 调度开销
|
|
||||||
|
|
||||||
线程是被内核所调度,线程被调度切换到另一个线程上下文的时候,需要保存一个用户线程的状态到内存,恢复另一个线程状态到寄存器,然后更新调度器的数据结构,这几步操作设计用户态到内核态转换,开销比较多。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
协程的调度完全由用户控制,协程拥有自己的寄存器上下文和栈,协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作用户空间栈,完全没有内核切换的开销。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 动态协程栈
|
|
||||||
|
|
||||||
协程拥有自己的寄存器上下文和栈,协程调度切换时将寄存器上下文和栈保存下来,在切回来的时候,恢复先前保存的寄存器的上下文和栈。
|
|
||||||
|
|
||||||
Goroutine 是 Golang 的协程实现。Goroutine 的栈只有 2KB大小,而且是动态伸缩的,可以按需调整大小,最大可达 1G 相比线程来说既不浪费又灵活了很多,可以说是相当的nice了!
|
|
||||||
|
|
||||||
线程也都有一个固定大小的内存块来做栈,一般会是 2MB 大小,线程栈会用来存储线程上下文信息。2MB 的线程栈和协程栈相比大了很多。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 协程实现
|
|
||||||
|
|
||||||
#### Python协程实现
|
|
||||||
|
|
||||||
正如刚才所写的代码示例,`python 2.5` 中引入 `yield/send` 表达式用于实现协程,但这种通过生成器的方式使用协程不够优雅。
|
|
||||||
|
|
||||||
`python 3.5` 之后引入` async/await` ,简化了协程的使用并且更加便于理解。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### Go语言协程实现
|
|
||||||
|
|
||||||
Golang 在语言层面实现了对协程的支持,`Goroutine` 是协程在 Go 语言中的实现, 在 Go 语言中每一个并发的执行单元叫作一个 `Goroutine` ,Go 程序可以轻松创建成百上千个协程并发执行。
|
|
||||||
|
|
||||||
Go 协程调度器有三个重要数据结构:
|
|
||||||
|
|
||||||
- G 表示 `Goroutine` ,它是一个待执行的任务;
|
|
||||||
|
|
||||||
- M 表示操作系统的线程,它由操作系统的调度器调度和管理;
|
|
||||||
|
|
||||||
- P 表示处理器 ` Processor `,它可以被看做运行在线程上的本地调度器;
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Go 调度器最多可以创建 10000 个线程,但可以通过设置 `GOMAXPROCS` 变量指能够正常运行的运行, 这个变量的默认值 等于 CPU 个数,也就是线程数等于 CPU 核数,这样不会触发操作系统的线程调度和上下文切换,所有的调度由 Go 语言调度器触发,都是在用户态,减少了非常多的调用开销。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
这篇文章讲解和对比了进程、线程的概念,同时通过进程窥探到操作系统内存管理的冰山一角,另外还讲解了具体到 Linux 系统下线程的实现现状,顺势引出了轻量级进程的概念。最后着重说明了大部分同学不太了解的协程,通过对比不同的服务模型,带你了解协程的特点。
|
|
||||||
|
|
||||||
说明一下,文中的图片都是我手绘的,原图我没打水印方便阅读,不过微信发出去之后会对图片压缩和打上水印,如果你想要下载高清原图,留着时不时温故知新,我也乐意无偿提供原图给你下载,在公众号「后端技术学堂」回复「进程」即可获取,对知识的理解有时候真的是一图胜千言,也是我文章的价值所在。
|
|
||||||
|
|
||||||
## 再聊两句
|
|
||||||
|
|
||||||
最近公众号改版了,我发的文章可能不能出现在你的消息列表中,不敢称自己是小号主,对于我这种 mini 号主影响还是很大的,写公众号文章的都知道,发出去的文章都想让更多人看到,才有机会得到持续的正向反馈,激励我持续创作和分享。
|
|
||||||
|
|
||||||
**所以,如果觉得文章写的还行,对你有点帮助,就动动手指点个「在看」顺手加个「星标」让我们还能及时再见。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
感谢各位的阅读,文章的目的是分享对知识的理解,技术类文章我都会反复求证以求最大程度保证准确性,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。今天的技术分享就到这里,我们下期再见。
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |